一、准备工作
1.申请机器
1)修改配置:
申请虚拟机下来了,通过xshell连接进入,
主机名还是默认的,修改下,不然看着不习惯
>hostname 查看主机名
>vim /etc/sysconfig/network
按i、 I 、a、 A其中一个,进入输入模式
HOSTNAME=master 改成自己想要的名字
按Esc退出输入模式
:wq 保存并退出
要想改的名字生效,执行reboot,这个过程可能需要几分钟,然后再xshell连接
2、准备软件
1)安装java 1.8
java -version 发现有了,不用安装了,此步省略
2)python 也有了,不用安装了
3)上传文件
rz命令上传文件
bash: rz: command not found
发现rz命令不能用,需要安装
>rpm -qa lrzsz 查看安装版本,发现是空的,没安装
>yum -y install lrzsz 安装上传下载命令工具
>mkdir soft 新建存在文件目录
>cd soft
>rz 命令,执行文件上传,选择要上传的文件 hadoop-2.8.4.tar.gz
>tar -xvf hadoop-2.8.4.tar.gz 解压hadoop文件
在根目录创建hadoop目录,
将解压的hadoop文件夹移动到创建的hadoop目录
>mv hadoop-2.8.4 /hadoop
二、安装配置
1.java环境变量配置
>vim /etc/profile
JAVA_HOME=/opt/java/jdk1.8.0_181
JRE_HOME=/opt/java/jdk1.8.0_181/jre
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=.:$JAVA_HOME/bin:$PATH
>source /etc/profile 使配置生效
2.hadoop环境变量配置
>vim /etc/profile
export HADOOP_HOME=/hadoop/hadoop-2.8.4
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH
>source /etc/profile 使配置生效
3.hadoop配置文件修改
在修改配置文件之前,创建hadoop临时目录
[root@master ~]# mkdir /root/hadoop
[root@master ~]# mkdir /root/hadoop/tmp
[root@master ~]# mkdir /root/hadoop/var
[root@master ~]# mkdir /root/hadoop/dfs
[root@master ~]# mkdir /root/hadoop/dfs/name
[root@master ~]# mkdir /root/hadoop/dfs/data
>cd /hadoop/hadoop-2.8.4/etc/hadoop 切换到hadoop配置文件目录
1)修改core-site.xml文件
- <configuration>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/root/hadoop/tmp</value>
- <description>hadoop tmp dir</description>
- </property>
- <property>
- <name>fs.default.name</name>
- <value>hdfs://master:9000</value>
- </property>
- </configuration>
2)修改 hadoop-env.sh
>vi hadoop-env.sh
将export JAVA_HOME=${JAVA_HOME}中${JAVA_HOME}修改成java具体安装目录
export JAVA_HOME=/opt/java/jdk1.8.0_181
3)修改hdfs-site.xml
>vi hdfs-site.xml
<property> <name>dfs.name.dir</name> <value>/root/hadoop/dfs/name</value> <description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description> </property> <property> <name>dfs.data.dir</name> <value>/root/hadoop/dfs/data</value> <description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.permissions</name> <value>true</value> <description>need not permissions</description> </property>
dfs.permissions配置为false后,可以允许不要检查权限就生成dfs上的文件,方便倒是方便了,但是你需要防止误删除,请将它设置为true,或者直接将该property节点删除,因为默认就是true
4)修改mapred-site.xml
- <property>
- <name>mapred.job.tracker</name>
- <value>master:9001</value>
- </property>
- <property>
- <name>mapred.local.dir</name>
- <value>/root/hadoop/var</value>
- </property>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
配置文件配置完成。
三、启动hadoop
1.首次启动,需要初始化(格式化)
>cd /hadoop/hadoop-2.8.4/bin 切换到安装bin目录
>./hadoop namenode -format
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
提示方法过时了,但不影响
conf.Configuration: error parsing conf mapred-site.xml
org.xml.sax.SAXParseException; systemId: file:/hadoop/hadoop-2.8.4/etc/hadoop/mapred-site.xml; lineNumber: 5; columnNumber: 2; The markup in the document following the root element must be well-formed.
报错了,看报错信息是mapred-site.xml文件没配置好,去看下发现没配置<configuration></configuration>根标签,加上根标签,去bin目录,重新执行
>./hadoop namenode -format
没报错就是格式化好了。
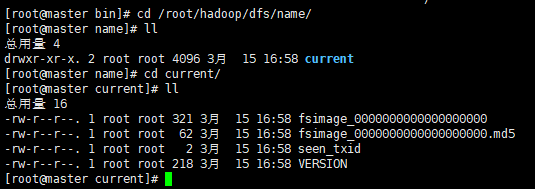
初始化成功后,可以在/root/hadoop/dfs/name 目录下(该路径在hdfs-site.xml文件中进行了相应配置,并新建了该文件夹)新增了一个current 目录以及一些文件。
2.启动hadoop:主要是启动HDFS和YARN
切换到sbin目录
>cd /hadoop/hadoop-2.8.4/sbin/
>start-dfs.sh 启动HDFS
Are you sure you want to continue connecting (yes/no)?
yes
root@master's password: ******

启动过程中,可以看到,先启动namenode服务,再启动datanode服务,最后启动secondarynamenode服务
HDFS启动成功了。
启动YARN
>start-yarn.sh

从打印日志中,可以看到启动yarn实际是启动yarn的daemons守护进程,再启动nodemanager节点管理器
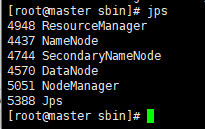
通过 jps命令查看hadoop服务是否启动成功:
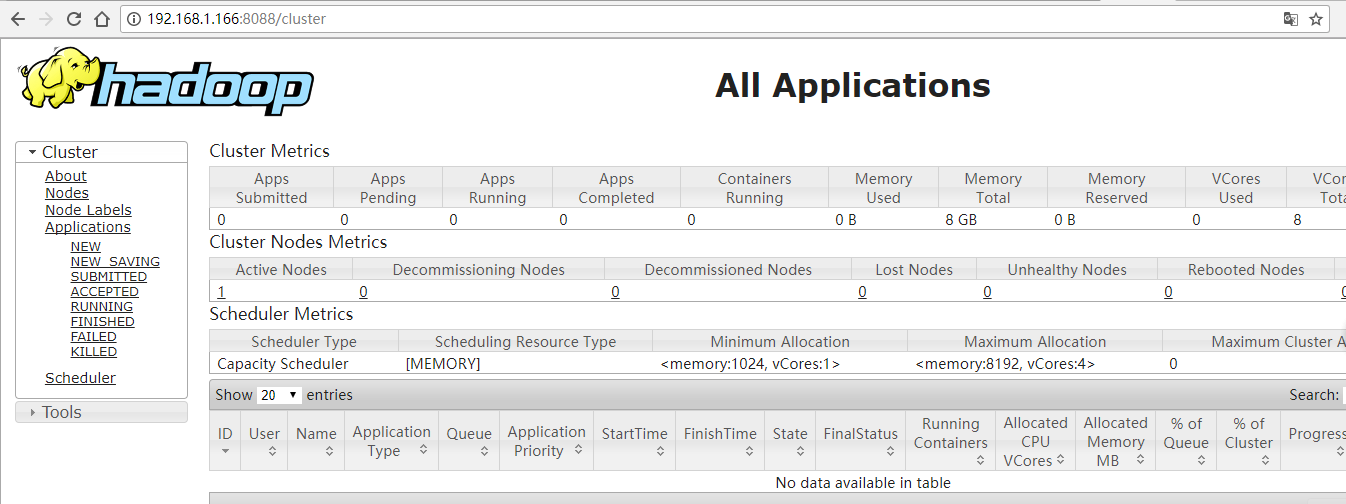
在浏览器中可以访问:
http://192.168.1.1**:8088/cluster
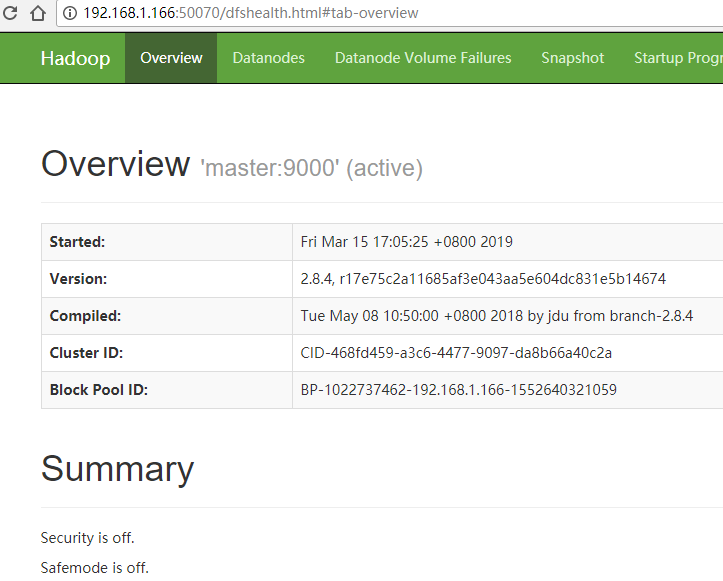
到此部署成功了。
http://192.168.1.1**:50070