参考链接:https://www.jianshu.com/p/f01f5f0309a9
一、旧版本Scala消费者客户端的缺陷
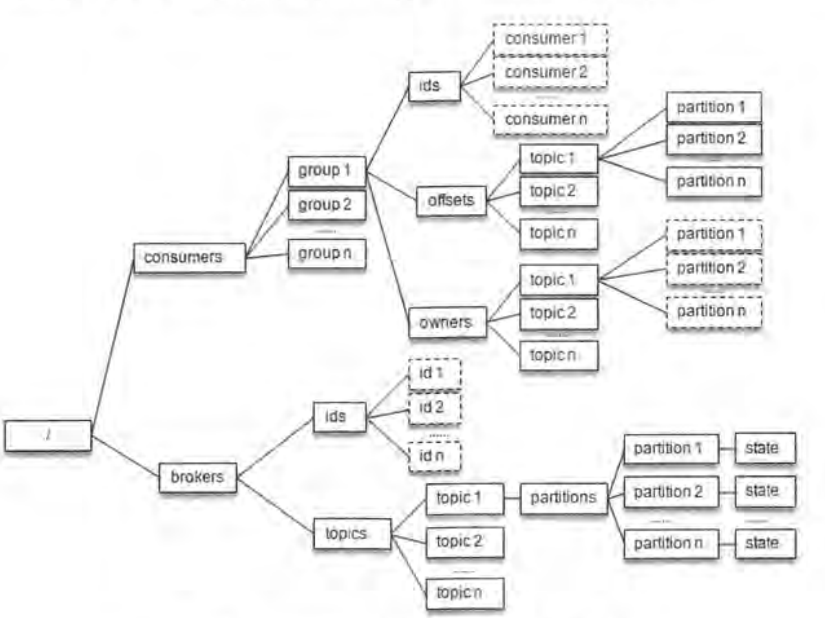
在kafka0.9及以前版本的consumer会在zookeeper上/consumers/groupId/ids、/consumers/groupId/topics、/consumers/groupId/owners下注册watch。一旦有变化,所有的consumer都得到通知,都进行rebanlace操作。
这种方式有几种缺陷:
- 1、zk压力很大
- 2、羊群效应,就是大量watch需要通知,可能会导致其他任务阻塞
- 3、脑裂效应,所有consumer都接收到通知,进行rebanlance,相互之间没法控制。
所以在kafka0.9版本引入了协调器Coordinator
二、协调器分类及功能
每个broker启动的时候都会创建一个GroupCoordinator,每个客户端都有一个ConsumerCoordinator协调器。 ConsumerCoordinator每间隔3S中就会和GroupCoordinator保持心跳,如果超时没有发送,并且再过Zookeeper.time.out = 10S中则会触发rebanlance
1、GroupCoordinator
- 1、接受ConsumerCoordinator的JoinGroupRequest请求
- 2、选择一个consumer作为leader,一般第一个会作为leader
- 3、和consumer保持心跳,默认3S中,参数是:heartbeat.interval.ms
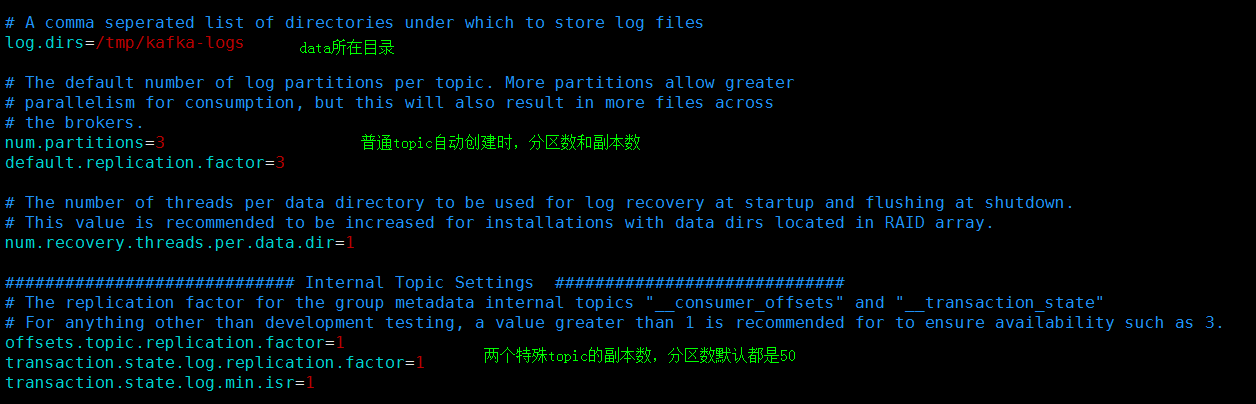
- 4、将consumer commit过来的offset保存在__consumer_offsets中
- 这是内部topic,还有一个是:__transaction_state
- 这个topic默认50个分区,1个副本。副本数一般要修改为3,增加高可用性
2、ConsumerCoordinator
- 1、向GroupCoordinator发送JoinGroupRequest请求加入group
- 2、定时发送心跳给GroupCoordinator,默认是3s钟
- 3、发送SyncGroup请求(携带自己的分配策略),得到自己所分配到的partition
- 3、向GroupCoordinator定时发送offset偏移量,默认5Scommit一次
- 4、如果是leader Consumer,还要负责分区分配工作,两种分配算法:range和RoundRobin。
3、consumer如何找到GroupCoordinator在哪里?
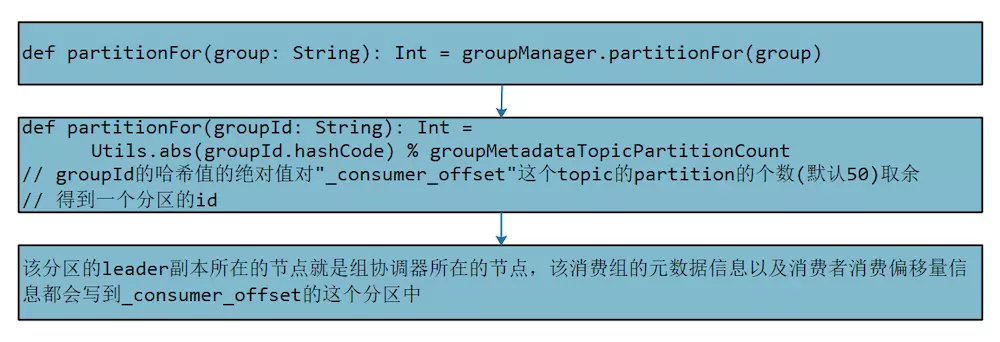
- 1、consumer向任何一个broker发送groupCoordinator发现请求,并携带上groupID
- 2、broker通过groupId.hash % __consumer_offsets的partitions数量(默认50个分区)得到分区id、
- 此分区leader所在broker就是此groupCoordinator所在broker。
- 3、consumerCoordinator找到GroupCoordinator之后,发送JoinGroupRequest请求加入group。
- 3、GroupCoordinator调用handleJoinGroup方法处理请求。
4、topic ==> consumeroffsets不可用导致没法找到分区对应leader,也就找不到GroupCoordinator异常
主要是__consumer_offsets默认副本数是1,一旦集群上有broker失效,则此broker上__consumer_offsets对应的分区都没法选择leader,因为没有其他副本,导致就找不到对应的GroupCoordinator异常
- util.AlterKafkaConsumerOffset$: 元信息topic:t_swt,partition:1,0
- Could not fetch offset for [t_table,23] due to org.apache.kafka.common.errors.NotCoordinatorForGroupException:
- This is not the correct coordinator for this group.
5、分区再均衡rebanlance和groupCoordinator重新发现
首先consumer是单线程的,发送joinGroup加入组,成功后发送SyncGroup请求获取自己分配到的partition。最后通过dealyqueue来实现3S钟的定时心跳。
-
1、rebanlance的条件
- 新consumer加入
- topic 分区增加
- consumer失联
这里面比较复杂的是consumer失联,consumer挂掉或者consumer负载太高导致他不能正常和groupCoordinator保持3S中心跳,在等待session.time.out=10S还没有心跳,则会触发rebanlance。
此时其他正常的consumer在heartbeat时就会收到GroupCoordinator的response illegal_generation(非法代),此时consumer就知道groupCoordinator正在进行renalancing,则会重新发送JoinGroup请求加入集群,加入成功后发送SyncGroup获取自己负责的partition信息。
同时会打印日志:attempt to hearbeat failed since group is rebalancing
所以:要注意consumer的负载,如果GC太频繁就很容易出现这个问题
-
2、日志中频繁打印发现Groupcoordinator的分析

- AppInfoParser: Kafka version : 0.10.1.2.6.4.0-91
- AppInfoParser: Kafka commitId : ba0af6800a08d2f8
- AbstractCoordinator: Discovered coordinator kafka-rzx2.bigdata.com:6667 (id: 2147482644 rack: null) for group topic_streaming5.
- ConsumerCoordinator: Revoking previously assigned partitions [] for group topic_streaming5
- AbstractCoordinator: (Re-)joining group topic_streaming5
- AbstractCoordinator: Successfully joined group topic_streaming5 with generation 3
- ConsumerCoordinator: Setting newly assigned partitions [wl_002-1, wl_002-0, wl_002-2] for group topic_streaming5
-
2.1、新的consumer加入group,一般是那种有重试机制的框架,比如
spark-streaming重新启动task任务加入group
confluent-connect重新启动task加入group
新的task顶替失败的task,重新加入group,所以他第一步是先发现group协调器,然后join
-
2.2、groupCoordinator挂了
当consumer发送心跳给GroupCoordinator没有响应,则会认为group失败,此时则会重新查找groupCoordinator,然后join。
GroupCoordinator失效是一个很严重的问题,说明某个GroupID对应的consumer非常多,导致太繁忙没法及时反应,或者集群问题导致__consumer_offsets的分区leader重新选举也会有这样的。比如spark-streaming有很多任务,每个任务的groupID都是一样的,每个任务搞了几个executor。这种情况需要拆分为几个groupID,自己负责自己的就行了
注意:会先打印组协调器失败了coordinator deal, 然后再打印


- AppInfoParser: Kafka version : 0.10.1.2.6.4.0-91
- AppInfoParser: Kafka commitId : ba0af6800a08d2f8
- AbstractCoordinator: Discovered coordinator kafka-rzx2.bigdata.com:6667 (id: 2147482644 rack: null) for group topic_streaming5.
- ConsumerCoordinator: Revoking previously assigned partitions [] for group topic_streaming5
- AbstractCoordinator: (Re-)joining group topic_streaming5
- AbstractCoordinator: Successfully joined group topic_streaming5 with generation 3
- ConsumerCoordinator: Setting newly assigned partitions [wl_002-1, wl_002-0, wl_002-2] for group topic_streaming5
三、一些重要日志
-
1、加入group

-
2、如果GroupCoordinator正在进行rebanlance,则consumer打印hearbeat failed

-
3、离开group

-
4、发现groupCoordinator
task刚上来的时候会打印,groupCoordinator失败时所有consumer也会重新发现组协调器,同时会打印coordinator deal

-
5、consumeroffsets分区leader无法找到,一般是由于默认副本为1,broker挂了导致分区leader无法选举,一般集群搭建时就要改为3
- util.AlterKafkaConsumerOffset$: 元信息topic:t_swt,partition:1,0
- Could not fetch offset for [t_table,23] due to
- org.apache.kafka.common.errors.NotCoordinatorForGroupException:
- This is not the correct coordinator for this group.