
- 1postcss安装和使用(详细)
- 25 种常见的 Linux 打包类型:tar、gzip、bzip2、zip 、 7z_linux文件打包
- 3华为鸿蒙javascript,第一个华为鸿蒙app跑起来了
- 4Java -枚举的使用_java枚举的使用
- 5仓库管理系统/课程设计/ASP.NET/_.net 后端 仓库管理模版页面布局
- 6python汽车大数据分析可视化系统【计算机毕业设计】大数据 (含源码)建议收藏_ps d:\毕业设计\车辆大屏可视化> python manage.py startapp myap
- 7计算机开启蓝牙网络,怎么打开电脑蓝牙功能(笔记本电脑蓝牙怎么开)
- 8MLP(多层神经网络)介绍_mlp算法分布式
- 9微信小程序对接微信支付详细教程_微信小程序接入微信支付
- 10华为ensp配置vrrp
【译】NLP——建立一个问答模型_基于题库的问答模型建立
赞
踩
最近在做一些nlp的工作,涉及到问答系统的构建,看到这篇文章觉得不错,遂翻译之,搬运一下。
先奉上原文:NLP — Building a Question Answering model
以下是翻译内容:
我最近完成了斯坦福大学的CS224n关于NLP的课程,很享受这个经历。在课程的final project中,我做了一个基于SQuAD(斯坦福问答数据集)的问答系统。在这篇博客中,我大概介绍一下这个模型的主要模块。
项目全部源码在我的GitHub仓库。
我最近也为这个项目加入了网页Demo,在这里你可以输入任何段落和你想要的相关提问。
SQuAD 数据集
Stanford Question Answering Dataset (SQuAD)是一个新的关于阅读理解任务的数据集,它由维基百科文章中的众包提出的一系列的问题组成,每个问题的答案都是相应阅读段落中的一小段文本。在500篇文章中,有100,000个问答对,SQuAD比以前的阅读理解数据组要大得多。
人们在SQuAD数据集上的研究已经取得了快速的进展,一些最新的模型在回答问题的任务中达到了人类水平的精确性!
该数据集上一组问答的例子:
Context — Apollo ran from 1961 to 1972, and was supported by the two-man Gemini program which ran concurrently with it from 1962 to 1966. Gemini missions developed some of the space travel techniques that were necessary for the success of the Apollo missions. Apollo used Saturn family rockets as launch vehicles. Apollo/Saturn vehicles were also used for an Apollo Applications Program, which consisted of Skylab, a space station that supported three manned missions in 1973–74, and the Apollo–Soyuz Test Project, a joint Earth orbit mission with the Soviet Union in 1975.
Question — What space station supported three manned missions in 1973–1974?
Answer — Skylab
SQuAD的几个关键特点:
- 这是一个封闭的数据集,也就是说,问题的答案始终是原文(context)中上下文的一部分,并且是连续的一段
2)因此,找到答案的问题可以简化为找到与答案相对应的上下文的开始索引和结束索引
3)75%的答案少于4个单词
机器理解模型——主要部分
1. Embedding Layer 嵌入层
模型的训练集由上下文(context)和相应的问题组成。二者都可以分解成单独的单词,然后使用预训练模型(如GloVe)将这些单词转换为词嵌入向量。了解更多关于词嵌入的信息,请查看博主的这篇文章。在捕获单词周围的上下文时,词嵌入要比对每个单词使用一个one-hot向量 好得多。这里我使用了100维的词嵌入,并且在训练过程中不对这部分参数进行训练(trainable = False),因为我们没有足够的数据。
2. Encoder Layer
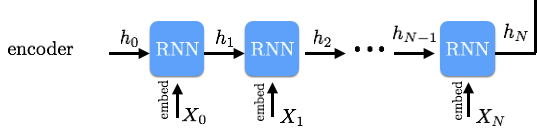
模型第二层是基于RNN的编码层。
- 我们希望context的每一个词都能感受到到它之前和之后的词,于是我们使用了双向GRU/LSTM。RNN的输出是一系列正向和反向的hidden state,并将它们拼接起来。
- 同样,我们使用相同的RNN编码器来生成 question 的hidden state。
3. Attention Layer 注意力层
到目前为止,我们已经有了context的hidden state和question 的hidden state。为了找出答案,我们需要把两者放在一起看,这也就是使用注意力机制的原因。这层也是问答系统的关键部分,因为它帮助我们决定,在给定一个question 时,在context中的哪个词与该question更相关。
让我们从最简单的注意力模型开始:
Dot product attention 点积注意力
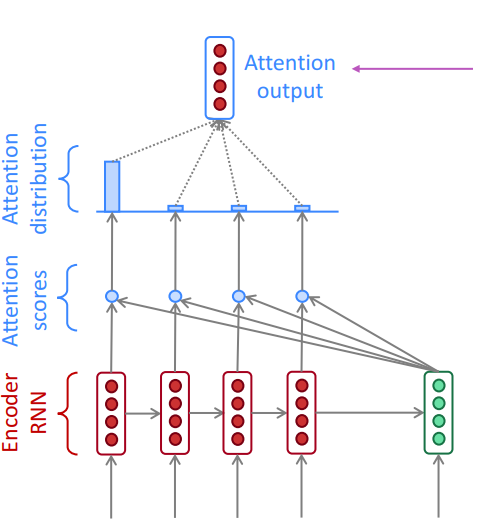
点积注意力是指,对于每个context中的向量 c i c_{i} ci(红色),我们乘以每个question的向量 q j q_j qj,得到向量 e i e_i ei (上图中的注意分数,图中的蓝点,是一个实数)。然后,我们在 e e e 上取一个softmax,得到 α i α_i αi (上图中的注意力分布)。Softmax确保所有 e i e_i ei 之和为1。最后,我们计算注意力分布 α i α_i αi和对应question的向量 q j q_j qj的点积,得到 a i a_i ai 作为注意力层的输出 (图中的注意力输出,红色)。
下面是公式描述:
e
i
=
[
c
i
T
q
1
,
…
,
c
i
T
q
M
]
∈
R
M
α
i
=
softmax
(
e
i
)
∈
R
M
以上注意力机制在GitHub中时有代码实现,并将其作为基准注意力机制。
更复杂的——BiDAF注意力
如果你用刚才提到的基准注意力机制在数据集上跑的话,会发现表现并不好,我们需要更复杂的注意力机制以提高性能。
接下类讲一下 BiDAF paper 中的注意力机制。该论文的主要观点是提出了两条路径的注意力:
- 从 context 到 question 的注意力
- 从 question 到 context 的注意力
-
首先计算相似度矩阵 S ∈ R n × m S\in R^{n×m} S∈Rn×m,其中包含 context 和 question 的隐藏状态的每个对 ( c i , q j c_i,q_j ci,qj) 的相似度评分 S i j S_{ij} Sij,计算公式如下:
S i j = w s i m T [ c i ; q j ; c i ∘ q j ] ∈ R S_{i j}=w_{\mathrm{sim}}^{T}\left [c_i ; q_j ; c_i \circ q_j\right] \in \mathbb{R} Sij=wsimT[ci;qj;ci∘qj]∈R其中, c i ∘ q j c_{i} \circ q_{j} ci∘qj 是逐元素(elementwise)乘积, w s i m ∈ R 6 h w_{\mathrm{sim}} \in R^{6h} wsim∈R6h是权向量。 -
接下来,我们进行 Context-to-Question (C2Q) 的注意力(类似于上面的点积注意力机制)。我们取 S S S的逐行softmax来获得注意分布 α i α_i αi,它用于对question的各个隐状态 q j q_j qj的取加权和,从而得到C2Q的注意力输出 a i a_i ai。公式如下:
α i = softmax ( S i , : ) ∈ R M ∀ i ∈ { 1 , … , N } a i = ∑ j = 1 M α j i q j ∈ R 2 h ∀ i ∈ { 1 , … , N }αiai=softmax(Si,:)∈RM∀i∈{1,…,N}=j=1∑Mαjiqj∈R2h∀i∈{1,…,N}αiaiamp;=softmax(Si,:)∈RM∀i∈{1,…,N}amp;=∑j=1Mαijqj∈R2h∀i∈{1,…,N} -
接下来,我们进行 Question-to-Context (Q2C) 的注意力。对于每个 context 的位置 i ∈ 1 , . . . , n i∈{1,...,n} i∈1,...,n, 我们从相似度矩阵上取对应行的最大值 m i = max j S i j ∈ R ∀ i ∈ { 1 , … , N } \boldsymbol{m}_{\boldsymbol{i}}=\max _{\boldsymbol{j}} \boldsymbol{S}_{i j} \in \mathbb{R} \quad \forall i \in\{1, \ldots, N\} mi=maxjSij∈R∀i∈{1,…,N}。然后对得到的向量 m ∈ R N \boldsymbol{m} \in R^N m∈RN 取Softmax,得到 question 在 context 上的注意力分布 β ∈ R N β \in R^N β∈RN。然后我们用 β β β 取 context 的 hidden state c i c_i ci 的加权和,最终得到 Q2C 注意力 c ′ \boldsymbol{c}^{\prime} c′。公式如下:
m
i
=
max
j
S
i
j
∈
R
∀
i
∈
{
1
,
…
,
N
}
β
=
softmax
(
m
)
∈
R
N
c
′
=
∑
i
=
1
N
β
i
c
i
∈
R
2
h
- 最后,对于每个context位置的
c
i
c_i
ci,我们将 C2Q注意力 和Q2C注意力 组合起来作为输出,如下面的等式:
b i = [ c i ; a i ; c i ∘ a i ; c i ∘ c ′ ] ∈ R 8 h ∀ i ∈ { 1 , … , N } b_{i}=\left[c_{i} ; a_{i} ; c_{i} \circ a_{i} ; c_{i} \circ c^{\prime}\right] \in \mathbb{R}^{8 h} \quad \forall i \in\{1, \dots, N\} bi=[ci;ai;ci∘ai;ci∘c′]∈R8h∀i∈{1,…,N}这里的 o o o 代表 elementwise multiplication。
如果你对这部分感到迷惑,别担心,注意力本身是一个复杂的话题。试着用一杯茶的时间读一下原论文:)
4. Output Layer
快搞定了。模型的最后一层是一个全连接-Softmax的输出层,它帮助我们确定answer在原文context中的的开始index和结束index。我们结合了context的hidden state和前一层的注意向量来得到混合向量。最后呢,我们将这些混合向量输入一个全连接层,激活函数使用Softmax得到 p s t a r t p_{start} pstart 向量和 p e n d p_{end} pend 向量:
- p s t a r t p_{start} pstart 向量:表示原文(context)中每个单词的index作为 answer 开头的概率
- p e n d p_{end} pend 向量:表示原文(context)中每个单词的index作为 answer 结尾的概率
由于我们知道,对于大多数答案,开始和结束索引间最大间隔是15个字,我们可以将能最大化 p s t a r t ∗ p e n d p_{start}*p_{end} pstart∗pend 的开始index和结束index作为最终 answer 在原文中的起止index。
损失函数是起点和终点的交叉熵损失之和,并且使用Adam优化器。
我建立的最终模型比上面描述的要复杂一些,在测试集上获得了75分。还不错!
Futher work
这里有几个改进的思路:
- 我一直在试验一个基于CNN的编码器,以取代文中的RNN编码器,因为CNN比RNN快得多,而且在GPU上更容易并行化
- 改用别的注意力机制,如这篇文章提出的Dynamic Co-attention
参考:
1.9.2[详细] 赞
踩

