
- 1API网关工具Kong或nginx ingress实现对客户端IP的白名单限制,提高对外服务的访问安全
- 2Centos7下安装、配置Redis5.0.3以及redis详解_redis: host: 192.168.247.129 port: 6379 database:
- 3牛客选择题错题集
- 4【君正T31学习教程】002Toolchain使用说明_gcc version 4.7.2 (ingenic r2.3.3 2016.12)
- 5gitlab简单学习(三)未完待续..._gitlab 三除工成
- 6Hutool中DateUtil工具类时间偏移_dateutil.offsetmonth
- 7C语言--数据结构:单链表
- 8openssh漏洞修复方案
- 9Redis数据类型--布隆过滤器类型详解及应用_redission的布隆过滤器是用什么数据类型实现的
- 10Vue前后端分离的低代码开发框架_前端低代码开发框架
Aurora IP简介
赞
踩
本文主要以Aurora8B/10B 为例,对该IP核做以简单介绍;同时,会对调试过程中遇到的问题给出解释,最后,给出Aurora8/10B以及Aurora64/66B的调试程序及验证结果。
目录
一·Aurora基础知识
Aurora 是一个用于在点对点串行链路间移动数据的可扩展轻量级链路层协议。这为物理层提供透明接口,让专有协议或业界标准协议上层能方便地使用高速收发器。虽然使用的逻辑资源非常少,但 Aurora 能提供低延迟高带宽和高度可配置的特性集。在 Xilinx FPGA 上使用是免费的,而且在 ASIC 上能以名义成本通过单独的许可证协议得到支持。
二.Aurora IP结构
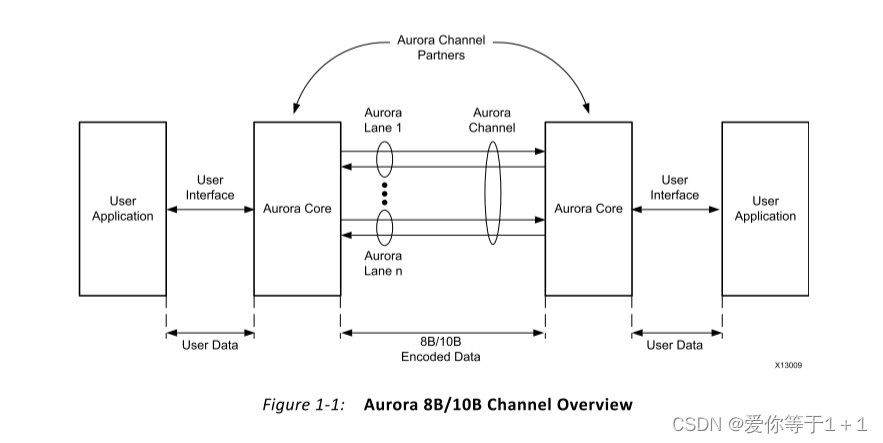
如图,Aurora核引出的用户接口供我们使用,可以使我们在两个Aurora核之间传输数据。两个Aurora核就组成了Aurora Channel Partners。Channel里面有多条lane,这个我们可以在IP核里面配置。每条lane对应一个高速收发器来对数据进行传输。
三.时钟与复位

3.1时钟设计
Aurora的输入时钟有三个,分别是GT Refclk,INT Clk和DRP Clk。
GT Refclk:该时钟是收发器的参考时钟,由外部一对差分输入时钟输入进来,一般取125MHZ。
INT Clk:初始化时钟,作为复位信号的一个时钟,可以由锁相环直接得到,一般取50MHZ
DRP Clk:不用深入理解,一般也是50MHZ,同样可以由锁相环直接得到。
对于Aurora的输出时钟,其实我们只需要关心user_clk_out(user_clk)即可,因为我们传输数据是工作在该时钟下的。user_clk就等于线速率除以单条lane编码后的数据位数,假如线速率为3.125Gbps,通道宽度为4字节,与上图对应,那么单个通道的数据宽度为32bit,采用8B/10B编码,也就是有20%的带宽开销,所以此时编码后应该是40bit,所以此时的用户时钟我们可以得到user_clk=3.125G/40=78.125MHZ。在这里需要强调一下,如果我们采用多通道(比如6通道)和只有一个通道的速率是一样的,只不过是位宽有所差别。
3.2复位设计
复位信号用于将Aurora 8B/10 B内核设置为已知的启动状态。复位时,内核停止任何当前操作并重新初始化新通道。在全双工模块上,复位信号复位通道的TX和RX端。在单工模块上,tx_system_reset复位TX通道,rx_system_reset复位RX通道。gt_reset信号复位收发器,收发器最终复位内核。
gt_reset:用来复位收发器,优先级高于reset;
reset:系统复位
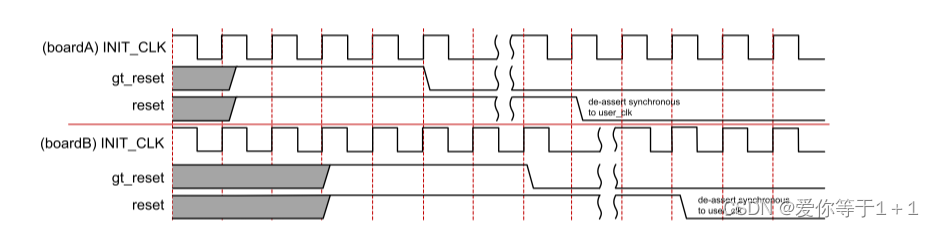
Aurora 8B/10B双工上电顺序:在板上电序列期间,gt_reset和reset信号都必须为高电平。收发器参考时钟(GT_REFCLK)和内核自由运行时钟(INIT_CLK)预计在上电期间保持稳定,以便Aurora 8B/10 B内核正常工作。

Aurora 8B/10B双工复位顺序:在正常操作期间,在gt_reset信号断言之前,预计复位信号被断言至少128 user_clk时间段,以确保可编程逻辑中的内核部分在user_clk信号由于gt_reset的断言而被抑制之前达到已知复位状态。

Aurora 64B/66B双工复位顺序:1.置位reset_pb。最少等待等于128*user_clk的时间周期。2.断言pma_init。使pma_init和reset保持断言状态至少一秒钟,并确保远程代理检测到热插拔事件。3.取消断言pma_init。4.reset_pb置位无效,逻辑在内部等待user_clk稳定,并使sys_reset_out置位无效,之后reset_pb可以置位无效。
总结:我们可以看到,Aurora核里面有两个复位,对于8B/10B来说,分别是gt_reset和reset,对应64/66B来说分别是pma_int和reset_pb,在这里把64/66B拿出来只是对比一下,其实不仅仅是复位,其他地方基本上也都是一样的。对于两个复位之间的关系,以上的顺序就是官方的推荐顺序,具体的理解其实我们不必考虑太多。另外gt_reset是工作在int_clk时钟下的,这点需要注意。
如果我们没有按照官方推荐的复位顺序来做的话,比如直接用vio来提供复位,把gt_reset和reset连接到一起,并不会影响收发数据,只是有时候不能重复测试,测试一次就得掉电重来,这点笔者深有体会。因此把复位程序放在这里给出:
- module initial_rst(
-
- input wire reset1 ,
- input wire init_clk_in ,
- output reg aurora_pma_init
- );
-
- // Aurora init时钟下,AURORA模块复位(64/66B)
- //int_clk为50MHZ
- reg reset_pb;
- reg [29:0] cnt = 30'b0;
- always @ ( posedge init_clk_in ) begin
- case(cnt)
- 30'd200:
- aurora_pma_init <= 1'b0;
- 30'd250:
- reset_pb <= 1'b0;
- 30'd300:
- reset_pb <= 1'b1;
- 30'd500:
- aurora_pma_init <= 1'b1;
- 30'd100_000_000:
- aurora_pma_init <= 1'b0;
- 30'd100_000_100:
- reset_pb <= 1'b0;
- default: begin
- aurora_pma_init <= aurora_pma_init;
- reset_pb <= reset_pb;
- end
- endcase
- end
- always @ ( posedge init_clk_in ) begin
- if( reset1 == 1'b1 )
- cnt <= 30'd0;
- else if( cnt == 30'd100_000_101 )
- cnt <= cnt;
- else
- cnt <= cnt + 1'b1;
- end
- endmodule

四.Aurora IP配置及端口介绍
4.1Aurora IP配置
Core Options:
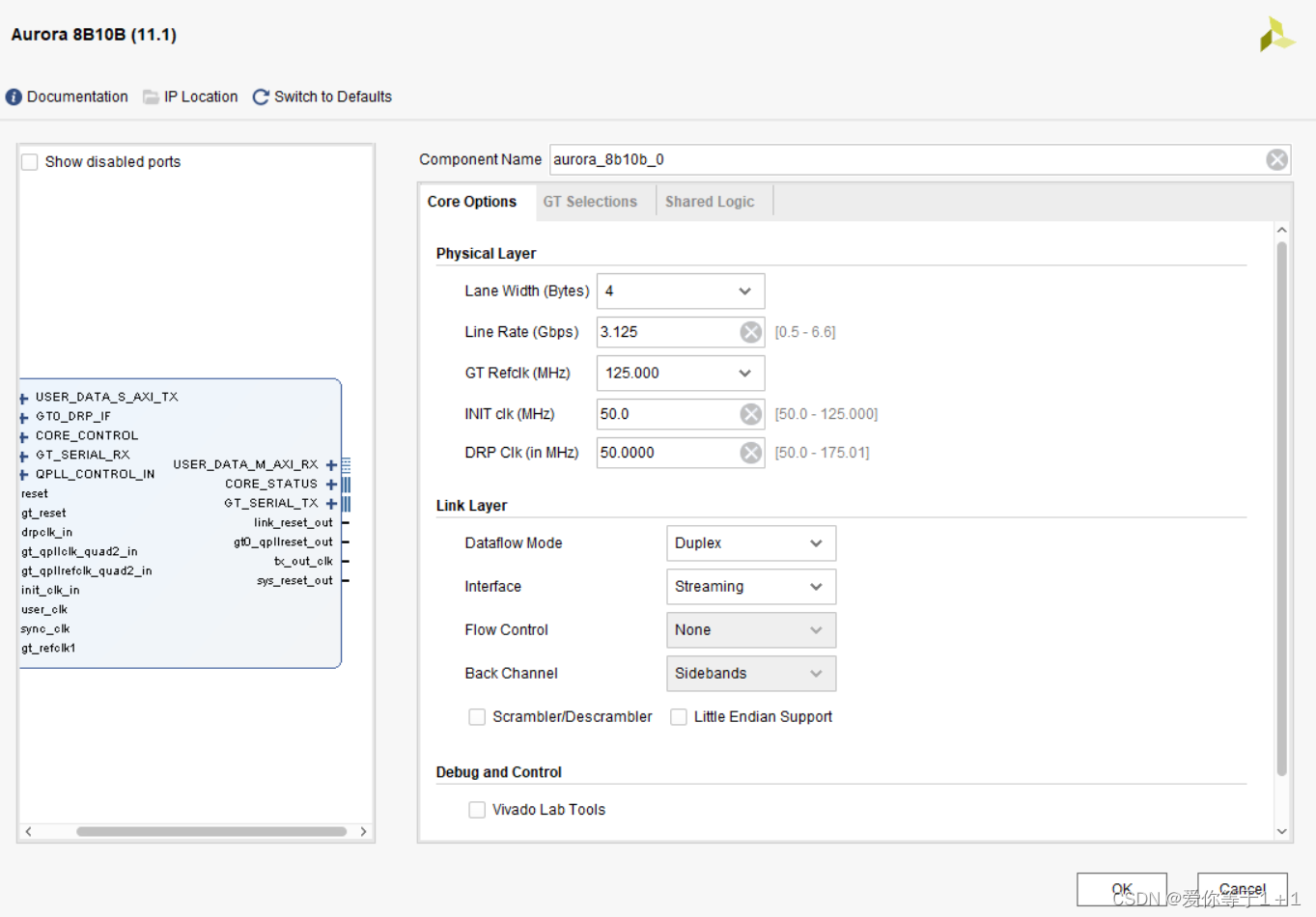
Lane Width:通道宽度,以字节为单位;默认:4
Line Rate:线速率,在时钟的讲解中我们也提到了线速率,除以编码后的数据宽度的到用户时钟速率。默认:3.125Gbps
Dataflow Mode:分为全双工,只接收,只发送。
Interface:Framing/straming;在这里我们选择流模式
flow control:不选
Back Channel:双工Aurora核心不需要此选项。可用选项包括:边带和定时器;默认值:边带
Scrambler/Descrambler:加扰/解扰,它确保长时间内不会出现重复数据。扰码器和解扰器分别基于时钟补偿字符的发送和接收而同步,一般情况下不选。
Little Endian Support:小端字节序的支持;[n-1:0]即为小端。
CRC:不选
Vivado Lab Tools:选择以将Vivado实验室工具添加到Aurora 8B/10B核心。此选项提供了一个调试界面,可在Vivado逻辑分析仪中显示内核状态信号。默认:未选中
Additional Transceiver Control and Status Ports:附加收发器控制和状态端口,默认:未选中
GT Selections

Columns:此选项仅对具有多个列/行的设备可见。从下拉列表中选择所用收发器的相应列/行。使用的列仅对Virtex-7和Kintex-7设备启用,使用的行仅对Artix®-7设备启用。选择收发器所在范围,比如bank111-118选择left,bank211-218选择right,这个根据自己开发板原理图来定。
Lanes:通道的个数。可以看到。IP里面最多允许我们选16个通道。之前我们介绍了通道宽度,它是以字节为单位的。那么,传输数据的宽度=Lanes*Lane Width*8。我们以4通道为例,通道宽度为4字节,那么传输数据宽度就为128bit,实际情况根据自己的需求来选。
GT Refclk1 and GT Refclk2:从下拉列表中选择GTP、GTX或GTH四通道的参考时钟源。可以看到一个QUAD对应一个bank,同样对应4个GT收发器。如果我们通道个数选择6,此时最少需要两个BANK,我们可以选择相邻的bank,因为相邻bank时钟可以路由,两个bank共用一个参考时钟源。这里还是要对应到开发板的原理图来看。
Share Logic

Include Shared Logic in core:共享逻辑包含在核里,一般默认此选项,IP已经做好封装,我们直接拿来用就行。
Include Shared Logic in example design:共享逻辑在例程设计里。
4.2Framing接口简介
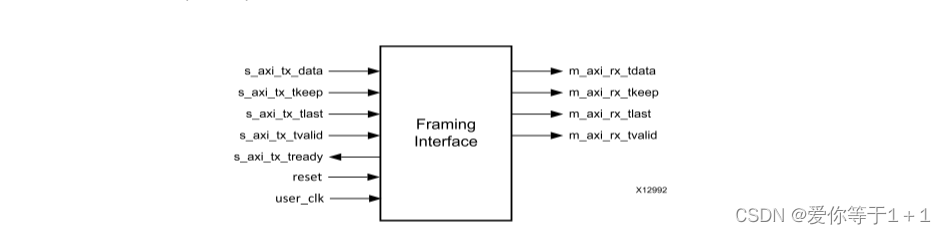
| 端口 | 方向 | 说明 |
| s_axi_tx_tdata | in | 我们需要发送的数据,数据到该信号线上之后,通过差分线txp,txn发出去,连接到另一个aurora核的rxp,rxn,然后数据就到m_axi_rx_tdata,完成板间或板内传输。 |
| s_axi_tx_tkeep | in | 指定最后一个数据节拍中的有效字节数;仅当s_axi_tx_tlast被断言时有效。s_axi_tx_tkeep是字节限定符,其指示s_axi_tx_tdata的相关联字节的内容是否有效。 |
| s_axi_tx_tlast | in | 表示帧的结束。 |
| s_axi_tx_tvalid | in | 发送有效时置位 |
| reset | in | 复位信号 |
| m_axi_rx_tdata | out | 接收到的数据 |
| m_axi_rx_tkeep | out | 指定最后一个数据节拍中的有效字节数。 |
| m_axi_rx_tlast | out | 表示输入帧结束(在单个用户时钟周期内置位)。 |
| m_axi_rx_tvalid | out | 接收有效 |
| s_axi_tx_tready | out | 当来自源的信号被接受且输出数据准备发送时置位。(注意是输出信号) |
| 注: | s开头代表发送端,m开头代表接收端。 |
发送数据:TX子模块将通过TX接口接收到的每个用户帧转换为Aurora 8B/10 B帧。帧的开始(SOF)通过在帧的开始处添加2字节SCP码组来指示。帧结束(EOF)通过在帧结束处添加2字节的信道协议结束(ECP)代码组来指示。当数据不可用时,将插入空闲代码组。代码组是8B/10 B编码的字节对所有数据都作为代码组发送,因此具有奇数字节的用户帧会在帧的末尾附加一个称为PAD的控制字符,以填充最终的代码组。表2-3显示了一个典型的Aurora 8B/10B帧,数据字节数为偶数。

其实我们也不必理解的那么深刻,直接把数据拿过来用就行,帧头和帧尾IP核已经做好了。下面直接看几个例子的时序图来理解端口信号。
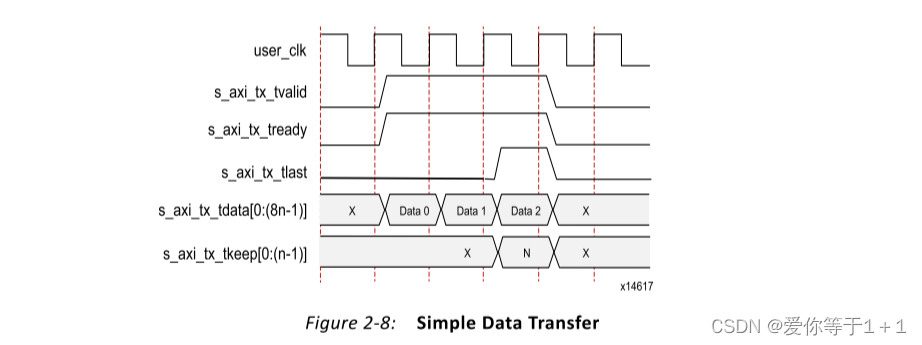
图2-8显示了在n字节宽的AXI4-Stream接口上进行简单数据传输的示例。在这种情况下,发送的数据量是3n字节,因此需要三个数据节拍。s_axi_tx_tready置位,表示AXI4-Stream接口已准备好发送数据。此时我们可以很清楚的看到,当s_axi_tx_tvalid与s_axi_tx_tready同时置位时,发送数据有效。而s_axi_tx_tlast信号表示帧的结束,也就是传最后一个数据时置位。

图2-9显示需要使用pad的(3n-1)字节数据传输示例。Aurora 8B/10B内核根据协议要求为具有奇数字节的帧附加填充字符。3n-1个数据字节的传输需要两个完整的n字节数据字和一个部分数据字。通俗的来讲,比如数据位宽是32bit,相当于我们一次传4字节,然后总的数据量只有11个字节,那我们传数据的第三个时钟周期就少了一个字节,此时就需要s_axi_tx_tkeep设定为N-1以指示最后数据字中的n-1个有效字节。

图2-10 显示了用户界面如何在帧传输期间暂停数据传输。在本例中,用户应用程序通过取消声明s_axi_tx_tvalid并改为发送空闲来暂停前n个字节之后的数据流。暂停持续到s_axi_tx_tvalid被取消断言。简而言之,只有s_axi_tx_tvalid和s_axi_tx_tready同时置位,才能完成数据的传输。
带时钟补偿的传输,一般情况下我们用不到,在这里就不说了,有需要的朋友可以查看官方手册。
接收数据:在Aurora核接收数据的时候,并没有m_axi_rx_tready信号,可以简单理解为它时刻都在准备接收,所以不需要这样的一个信号。此时,只有m_axi_rx_tvalid信号置位,即代表接收有效。下面给出一个例子:
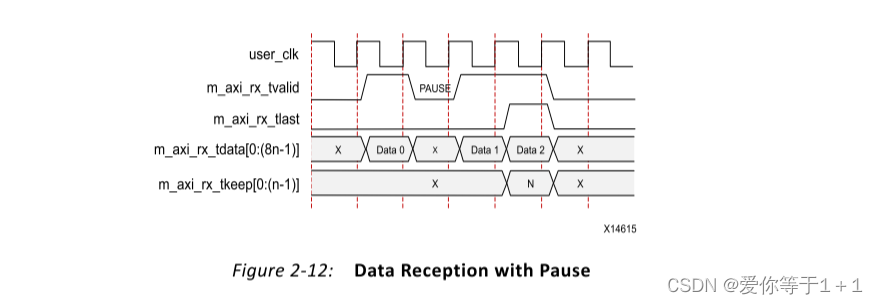
可以看到 m_axi_rx_tvalid信号置位,代表接收有效。m_axi_rx_tlast信号在接收最后一个数据时拉高。内核还计算m_axi_rx_tkeep总线的值,并根据帧最后一个字中的有效字节总数将其提供给用户应用。
4.3.Streaming接口简介
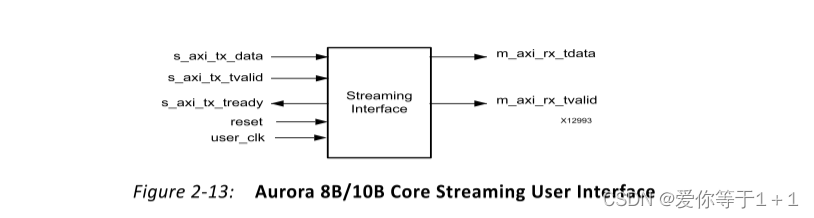
我们对比Framing接口,可以发现,Streaming接口相比Framing接口,少了s_axi_tx_tkeep,s_axi_tx_tlast,m_axi_rx_tkeep,m_axi_rx_tlast。这是因为Streaming接口中没有帧的概念。
但是它的发送和接收时序,都是基于axi_stream接口的。对于发送数据,当s_axi_tx_tvalid与s_axi_tx_tready同时置位时,发送有效;对于接收数据,当m_axi_rx_tvalid置位时,接收有效。
下面给出接收和发送数据的时序图:
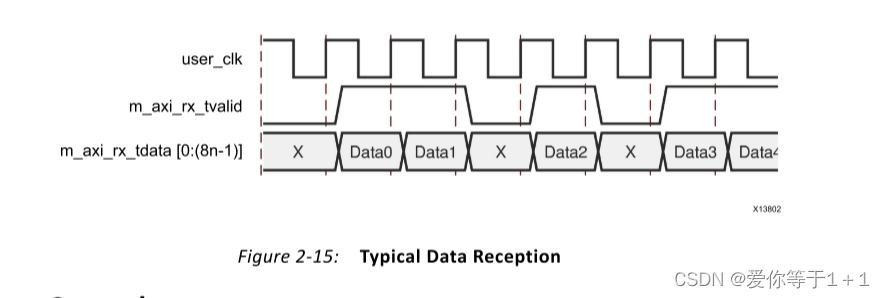
比较简单,就不再赘述。
五.Aurora收发实测
5.1Aurora 8B/10B收发测试
在这里我们同样采用上面介绍Aurora8B/10B配置时所选的选项:即4通道,通道宽度4字节,线速率3.125Gbps,来对128bit数据做板间传输。

程序设计时主要分为4个模块,分别是顶层,时钟配置与产生模块,复位模块,以及数据产生模块。
时钟配置与产生模块:对于我们用的开发板,需要配置cdcm6208来驱动时钟信号,这里不作过多说明。时钟产生模块,主要是通过锁相环产生50MHZ的时钟,来给DRP CLk和Int Clk提供时钟。

复位模块:在介绍时钟与复位的部分我们已经给出了程序,在这里我们直接用VIO来提供复位信号,把reset和gt_reset接在一起即可。
数据产生模块:产生位宽为128bit的递增数,用VIO来控制数据的发送。
- `timescale 1ns / 1ps
- module data_gen(
- input wire user_clk_i ,
- input wire channel_up_r ,
-
- input wire vio_reset ,
- input wire vio_start ,
- input wire s_axi_tx_tready ,
-
- output wire [0:127] s_axi_tx_tdata ,
- output wire s_axi_tx_tvalid
- );
-
- reg [0:127]cnt;
- wire flag;
- reg w_end;
- reg w_end_dly;
-
- assign s_axi_tx_tvalid = flag;
- assign flag = channel_up_r & s_axi_tx_tready & vio_start;
- assign s_axi_tx_tdata = cnt;
-
- always @(posedge user_clk_i) begin
- if(vio_reset) begin
- cnt <= 128'd0;
- end
- else begin
- if(flag && (cnt <= 128'd5000)) begin
- cnt <= cnt + 128'd1;
- end
- else if(s_axi_tx_tready == 1'b0) begin
- cnt <= cnt;
- end
- else begin
- cnt <= 128'd0;
- end
- end
- end
- endmodule
顶层连接:
- `timescale 1ns / 1ps
-
-
-
- module Aurora_AD_top(
- input crystal_clk , //50M
-
- input wire [3:0] rxp ,
- input wire [3:0] rxn ,
- output wire [3:0] txp ,
- output wire [3:0] txn ,
- input wire gt_refclk1_p ,
- input wire gt_refclk1_n
-
- );
-
- wire spi_clk_locked ;
- wire clk_5M_6208 ;
- wire clk_50M ;
-
- clk_wiz_0 clk_wiz_0_inst(
- .clk_out1 (clk_50M ),
- .clk_out2 (clk_5M_6208 ),
- .reset (1'b0 ),
- .locked (spi_clk_locked ),
- .clk_in1 (crystal_clk )
- );
- wire [127:0] s_axi_tx_tdata ;
- wire s_axi_tx_tvalid ;
- wire s_axi_tx_tready ;
- wire [127:0] m_axi_rx_tdata ;
- wire m_axi_rx_tvalid ;
- wire channel_up ;
- wire [3:0] lane_up ;
- wire user_clk_out ;
- wire sys_reset_out ;
- wire sync_clk_out ;
- wire gt_reset_out ;
- wire gt_refclk1_out ;
- wire gt0_qplllock_out ;
- wire gt0_qpllrefclklost_out ;
- wire gt_qpllclk_quad5_out ;
- wire gt_qpllrefclk_quad5_out ;
- Aurora_ad_xc Aurora_ad_xc_inst(
- .reset (vio_reset ),
- .drpclk_in (clk_50M ),
- .init_clk_in (clk_50M ),
-
- .rxp (rxp ),
- .rxn (rxn ),
- .txp (txp ),
- .txn (txn ),
-
- .gt_refclk1_p (gt_refclk1_p ),
- .gt_refclk1_n (gt_refclk1_n ),
-
- .s_axi_tx_tdata (s_axi_tx_tdata ),
- .s_axi_tx_tvalid (s_axi_tx_tvalid ),
- .s_axi_tx_tready (s_axi_tx_tready ),
- .m_axi_rx_tdata (m_axi_rx_tdata ),
- .m_axi_rx_tvalid (m_axi_rx_tvalid ),
-
- .channel_up (channel_up ),
- .lane_up (lane_up ),
-
- .user_clk_out (user_clk_out ),
- .sys_reset_out (sys_reset_out ),
- .sync_clk_out (sync_clk_out ),
- .gt_reset_out (gt_reset_out ),
- .gt_refclk1_out (gt_refclk1_out ),
- .gt0_qplllock_out (gt0_qplllock_out ),
- .gt0_qpllrefclklost_out (gt0_qpllrefclklost_out ),
- .gt_qpllclk_quad5_out (gt_qpllclk_quad5_out ),
- .gt_qpllrefclk_quad5_out (gt_qpllrefclk_quad5_out )
- );
- wire vio_reset; //高复位
- wire vio_start; //高产生数据
- vio_0 vio_0_inst(
- .clk (user_clk_out ), // input wire clk
- .probe_out0 (vio_reset ), // output wire [0 : 0] probe_out0
- .probe_out1 (vio_start ) // output wire [0 : 0] probe_out1
- );
- data_gen data_gen_inst(
- .user_clk_i (user_clk_out ),
- .channel_up_r (channel_up ),
- .vio_reset (vio_reset ),
- .vio_start (vio_start ),
- .s_axi_tx_tdata (s_axi_tx_tdata ),
- .s_axi_tx_tvalid (s_axi_tx_tvalid ),
- .s_axi_tx_tready (s_axi_tx_tready )
- );
-
- endmodule
接下来我们直接上板验证:
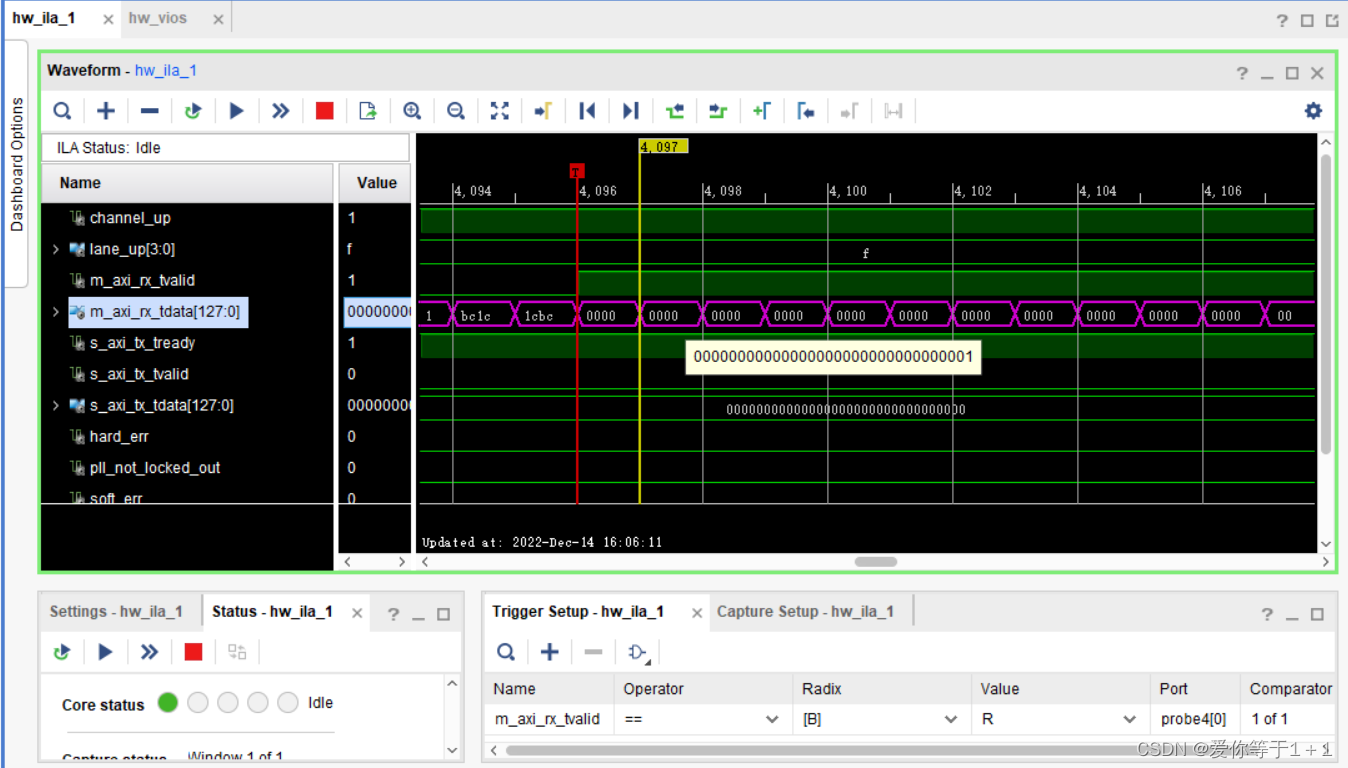
可以看到。m_axi_rx_tvalid信号上升沿触发,接收到的数据为0-5001的递增数,验证成功,并且可以重复测试。
5.2Aurora 64B/66B收发测试
Aurora64B/66B与Aurora8/10B最大的不同就是位宽这里,其他地方都大同小异。
我们简单给出它的配置:

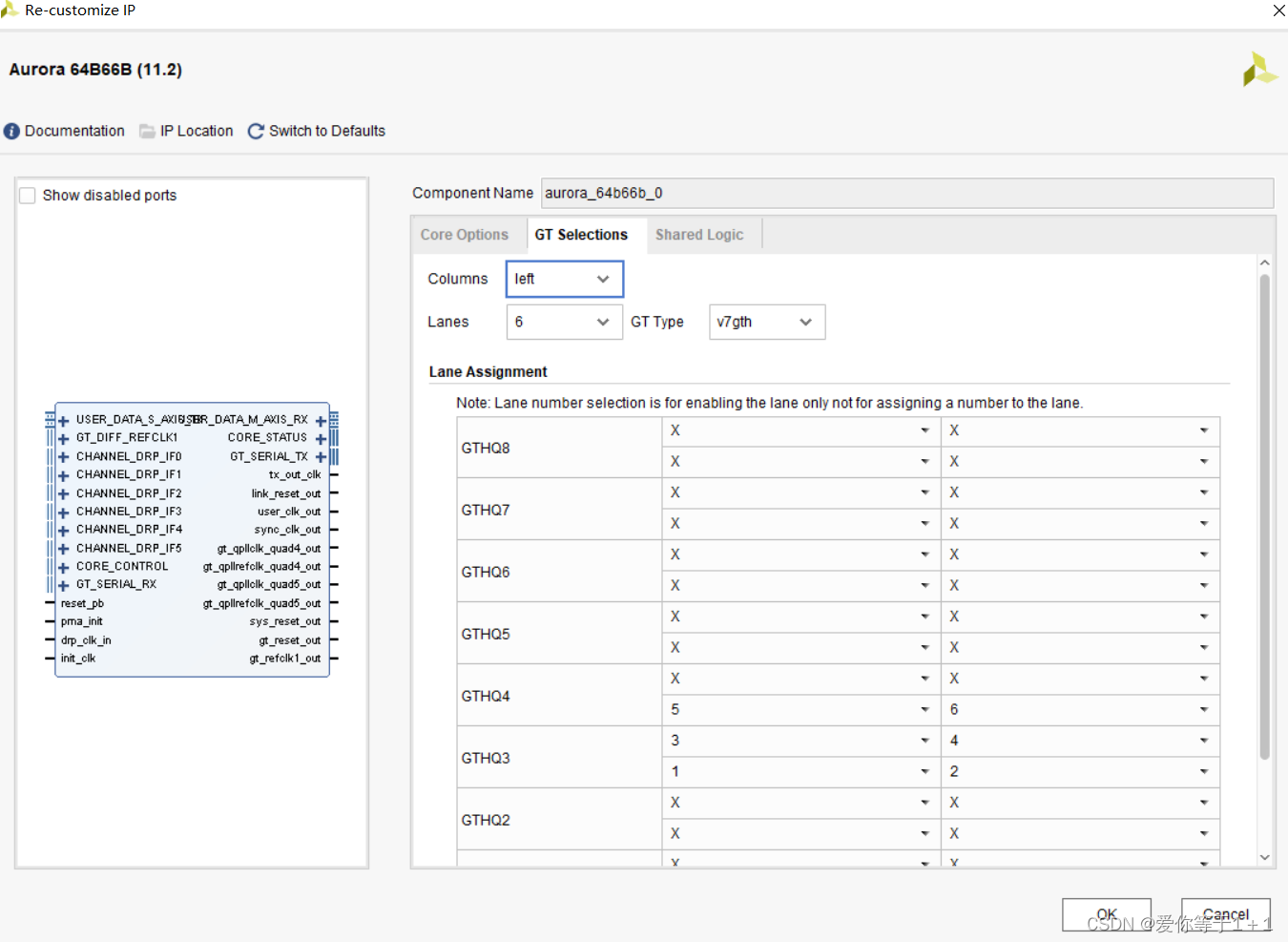 第三页的share logic,我们同样让他包含在核里面。由以上配置,我们采用6通道,此时传输数据的宽度为6*64bit=384bit。这里选择6通道的原因,最后一节会给出详细说明。
第三页的share logic,我们同样让他包含在核里面。由以上配置,我们采用6通道,此时传输数据的宽度为6*64bit=384bit。这里选择6通道的原因,最后一节会给出详细说明。
对于6通道64/66B同样包含以上的模块,不同的是,这里我们的系统复位信号reset_pb是由VIO产生的,另外一个复位信号,pma_int是由系统复位信号产生,满足XIlinx官方推荐的复位时序。

下面给出Aurora 64B/66B的例化程序即可。
- `timescale 1ns / 1ps
-
- module Aurora_xc_ad(
- input wire reset ,
- input wire drpclk_in ,
- input wire init_clk_in ,
- input wire [5:0] rxp ,
- input wire [5:0] rxn ,
- output wire [5:0] txp ,
- output wire [5:0] txn ,
- input wire gt_refclk1_p ,
- input wire gt_refclk1_n ,
- input wire [383:0] s_axi_tx_tdata ,
- input wire s_axi_tx_tvalid ,
- output wire s_axi_tx_tready ,
- output wire [383:0] m_axi_rx_tdata ,
- output wire m_axi_rx_tvalid ,
- output wire channel_up ,
- output wire [5:0] lane_up ,
- output wire user_clk_out ,
- output wire sys_reset_out ,
- output wire sync_clk_out ,
- output wire gt_reset_out ,
- output wire gt_refclk1_out ,
- output wire gt0_qplllock_out ,
- output wire gt0_qpllrefclklost_out ,
- output wire gt_qpllclk_quad5_out ,
- output wire gt_qpllrefclk_quad5_out ,
- output wire gt_qpllclk_quad4_out ,
- output wire gt_qpllrefclk_quad4_out
- );
- initial_rst initial_rst_inst(
- .init_clk_in(init_clk_in),
- .reset1(reset),
- .aurora_pma_init(pma_init)
-
- );
-
- wire hard_err;
- wire soft_err;
- wire pll_not_locked_out;
-
- aurora_64b66b_0 your_instance_name (
- .rxp(rxp), // input wire [0 : 5] rxp
- .rxn(rxn), // input wire [0 : 5] rxn
- .reset_pb(reset), // input wire reset_pb
- .power_down(0), // input wire power_down
- .pma_init(pma_init), // input wire pma_init
- .loopback(3'b0), // input wire [2 : 0] loopback
- .txp(txp), // output wire [0 : 5] txp
- .txn(txn), // output wire [0 : 5] txn
- .hard_err(hard_err), // output wire hard_err
- .soft_err(soft_err), // output wire soft_err
- .channel_up(channel_up), // output wire channel_up
- .lane_up(lane_up), // output wire [0 : 5] lane_up
- .tx_out_clk(), // output wire tx_out_clk
- .drp_clk_in(drpclk_in), // input wire drp_clk_in
- .gt_pll_lock(gt_pll_lock), // output wire gt_pll_lock
- .s_axi_tx_tdata(s_axi_tx_tdata), // input wire [0 : 383] s_axi_tx_tdata
- .s_axi_tx_tvalid(s_axi_tx_tvalid), // input wire s_axi_tx_tvalid
- .s_axi_tx_tready(s_axi_tx_tready), // output wire s_axi_tx_tready
- .m_axi_rx_tdata(m_axi_rx_tdata), // output wire [0 : 383] m_axi_rx_tdata
- .m_axi_rx_tvalid(m_axi_rx_tvalid), // output wire m_axi_rx_tvalid
- .mmcm_not_locked_out(mmcm_not_locked_out), // output wire mmcm_not_locked_out
- .drpaddr_in(0), // input wire [8 : 0] drpaddr_in
- .drpaddr_in_lane1(0), // input wire [8 : 0] drpaddr_in_lane1
- .drpaddr_in_lane2(0), // input wire [8 : 0] drpaddr_in_lane2
- .drpaddr_in_lane3(0), // input wire [8 : 0] drpaddr_in_lane3
- .drpaddr_in_lane4(0), // input wire [8 : 0] drpaddr_in_lane4
- .drpaddr_in_lane5(0), // input wire [8 : 0] drpaddr_in_lane5
- .drpdi_in(0), // input wire [15 : 0] drpdi_in
- .drpdi_in_lane1(0), // input wire [15 : 0] drpdi_in_lane1
- .drpdi_in_lane2(0), // input wire [15 : 0] drpdi_in_lane2
- .drpdi_in_lane3(0), // input wire [15 : 0] drpdi_in_lane3
- .drpdi_in_lane4(0), // input wire [15 : 0] drpdi_in_lane4
- .drpdi_in_lane5(0), // input wire [15 : 0] drpdi_in_lane5
- .drprdy_out(), // output wire drprdy_out
- .drprdy_out_lane1(), // output wire drprdy_out_lane1
- .drprdy_out_lane2(), // output wire drprdy_out_lane2
- .drprdy_out_lane3(), // output wire drprdy_out_lane3
- .drprdy_out_lane4(), // output wire drprdy_out_lane4
- .drprdy_out_lane5(), // output wire drprdy_out_lane5
- .drpen_in(0), // input wire drpen_in
- .drpen_in_lane1(0), // input wire drpen_in_lane1
- .drpen_in_lane2(0), // input wire drpen_in_lane2
- .drpen_in_lane3(0), // input wire drpen_in_lane3
- .drpen_in_lane4(0), // input wire drpen_in_lane4
- .drpen_in_lane5(0), // input wire drpen_in_lane5
- .drpwe_in(0), // input wire drpwe_in
- .drpwe_in_lane1(0), // input wire drpwe_in_lane1
- .drpwe_in_lane2(0), // input wire drpwe_in_lane2
- .drpwe_in_lane3(0), // input wire drpwe_in_lane3
- .drpwe_in_lane4(0), // input wire drpwe_in_lane4
- .drpwe_in_lane5(0), // input wire drpwe_in_lane5
- .drpdo_out(), // output wire [15 : 0] drpdo_out
- .drpdo_out_lane1(), // output wire [15 : 0] drpdo_out_lane1
- .drpdo_out_lane2(), // output wire [15 : 0] drpdo_out_lane2
- .drpdo_out_lane3(), // output wire [15 : 0] drpdo_out_lane3
- .drpdo_out_lane4(), // output wire [15 : 0] drpdo_out_lane4
- .drpdo_out_lane5(), // output wire [15 : 0] drpdo_out_lane5
- .init_clk(init_clk_in), // input wire init_clk
- .link_reset_out(), // output wire link_reset_out
- .gt_refclk1_p(gt_refclk1_p), // input wire gt_refclk1_p
- .gt_refclk1_n(gt_refclk1_n), // input wire gt_refclk1_n
- .user_clk_out(user_clk_out), // output wire user_clk_out
- .sync_clk_out(), // output wire sync_clk_out
- .gt_qpllclk_quad5_out(), // output wire gt_qpllclk_quad5_out
- .gt_qpllrefclk_quad5_out(), // output wire gt_qpllrefclk_quad5_out
- .gt_qpllclk_quad4_out(), // output wire gt_qpllclk_quad4_out
- .gt_qpllrefclk_quad4_out(), // output wire gt_qpllrefclk_quad4_out
- .gt_rxcdrovrden_in(0), // input wire gt_rxcdrovrden_in
- .sys_reset_out(), // output wire sys_reset_out
- .gt_reset_out(), // output wire gt_reset_out
- .gt_refclk1_out() // output wire gt_refclk1_out
- );
-
- ila_0 your_instaila_0666 (
- .clk(user_clk_out), // input wire clk
- .probe0(soft_err), // input wire [0:0] probe0
- .probe1(channel_up), // input wire [0:0] probe1
- .probe2(m_axi_rx_tvalid), // input wire [0:0] probe2
- .probe3(m_axi_rx_tdata) // input wire [383:0] probe3
- );
- endmodule
上板验证: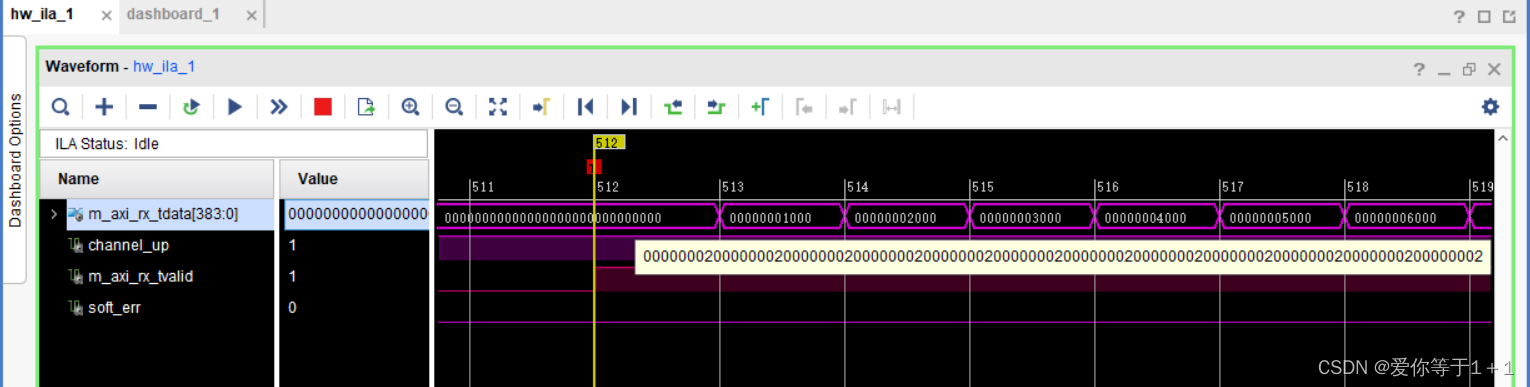
可以看到,接收到的数据是12个32bit数据拼接得到,与我们发送的数据一致(这里没有给出数据产生模块,因为和8B/10B基本类似)。
5.3实测中遇到的问题总结
问题1:在进行6通道Aurora64B/66B数据收发的时候,不能重复测试,需要掉电才行,或者就是需要点很多下VIO复位,才可以第二次触发。
解决:首先说明一下该问题产生的原因,是因为复位的时候,reset_pb和pma_int是通过VIO产生的复位信号连接到了一起,导致点一下vio_reset并不能使IP核复位到已知的初始状态。后来就查阅官方手册,根据官方推荐的复位顺序写了一下复位模块,从而解决该问题
思考:但是对于四通道8B/10B的IP核,我们直接可以把reset和gt_reset连接到一起,并不影响重复测试。因此,我个人的想法,与其碰运气,不如一次弄好,直接根据官方推荐的来即可。
问题2:在6通道Aurora64B/66B中,选择好收发器后,编译一直报错,显示gt_qpllclk_quad5_out is not completely routed,如下图所示:
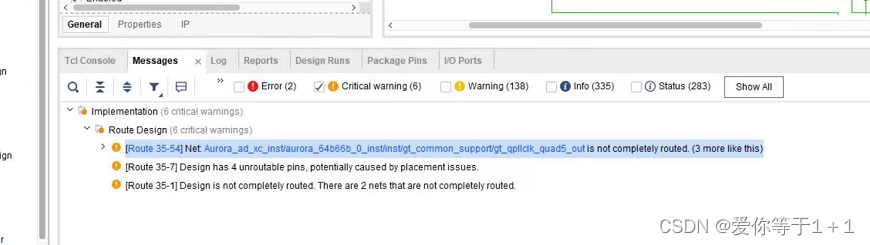
我给的配置如下所示:

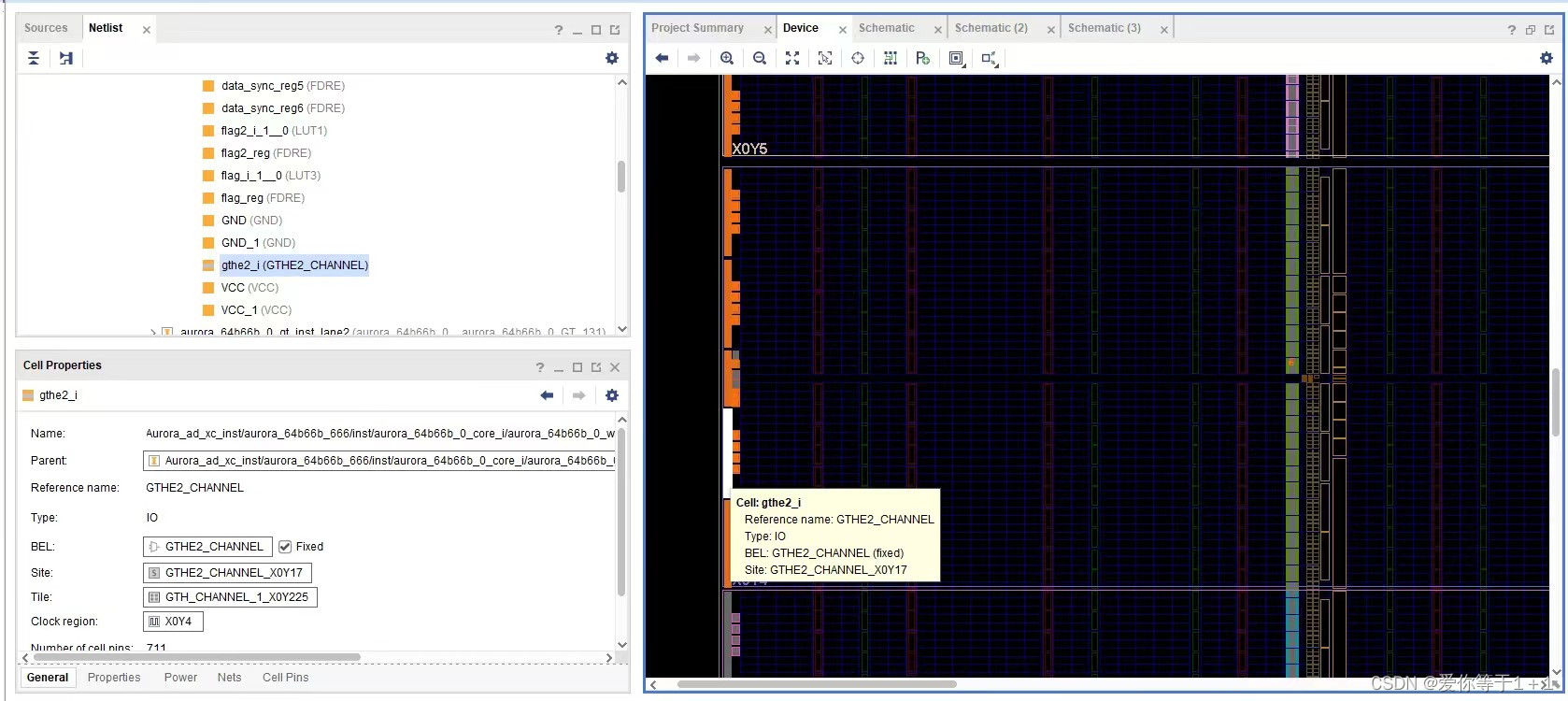
综合后的网表如图:

先解释一下出现这种问题的原因,一个gt_common最多驱动4个serdes,但是必须是同一个quad的serdes;上图我们的配置是让1,2,3,4在同一个quad里,5和6在另外一个quad,结果common驱动的是2,3,4,5(对应配置里面是3,4,5,6,因为网表里面的txn,txp都是0-5),1.最简单的改法就是把上图的配置1-6顺序反着来即可,这样就能保证一个gt_common驱动同一个quad的serdes。2.我们也可以在图形界面直接拖动txp[0-5],把位置换成[5-0],如下图所示:
问题3:同样在64/66B中,编译通过的情况下不能收发数据,channel up,lane up均没有拉高。
解决:通过查阅资料,最终发现是时序约束的问题。
- set_property CLOCK_DEDICATED_ROUTE FALSE [get_nets Aurora_xc_ad_inst/your_instance_name/inst/gt_common_support/gt_qpllclk_quad5_out]
- set_property CLOCK_DEDICATED_ROUTE FALSE [get_nets Aurora_xc_ad_inst/your_instance_name/inst/gt_common_support/gt_qpllclk_quad4_out]
- set_property CLOCK_DEDICATED_ROUTE FALSE [get_nets AD_gt_refclk1_p_IBUF]

