
- 1RK3399linux交叉编辑器下载,ubuntu下交叉编译X264和FFMPEG到RK3399平台(编译器:aarch64-linux-gcc)...
- 2人工智能为什么可以准确回答问题而不依赖数据库呢?_机器人对答是数据库
- 3有哪些好用不火的软件?_实验楼怎么样csdn
- 4PolarDB 卷来卷去 云原生低延迟强一致性读 1 (SCC READ 译 )
- 5FLASH问题答疑
- 6基于GPT-3.5的AI机器人:源码与脚本详解大数据任务提交和执行_ai3.5在线机器人
- 7无人机摄影测量数据处理、三维建模及在土方量计算中的应用_像空点
- 8【gitlab部署】centos8安装gitlab(搭建属于自己的代码服务器)
- 9【MySQL精通之路】全文搜索-布尔型全文搜索
- 10物联网主干组网之全IP光网络_光传输组网原理
【时序】时序预测任务模型选择如何选择?_时序任务
赞
踩
时间序列是什么
时间序列是一种特殊类型的数据集,其中一个或多个变量随着时间的推移被测量。
在时间序列中,观测值是随着时间的推移而测量的。你的数据集中的每个数据点都对应着一个时间点。这意味着你的数据集的不同数据点之间存在着一种关系。这对可以应用于时间序列数据集的机器学习算法类型有重要影响。
2.1单变量与多变量的时间序列模型
时间序列的第一个特殊性是识别数据的时间戳具有内在的意义。单变量时间序列模型是只使用一个变量(目标变量)及其时间变化来预测未来。单变量模型是针对时间序列的。多变量时间序列模型是经过调整的单变量时间序列模型,以整合外部变量。
单变量时间序列模型 | 多变量时间序列模型 |
只使用一个变量 | 使用多个变量 |
无法使用外部数据 | 可以使用外部数据 |
仅基于过去和现在之间的关系 | 基于过去和现在之间以及变量之间的关系 |
仅基于过去和现在之间的关系 | 基于过去和现在之间的关系,以及变量之间的关系 |
2.2时间序列分解
时间序列分解是一种从数据集中提取多种类型变化的技术。
在时间序列的时间数据中,有三个重要的组成部分:季节性、趋势和噪音。
季节性是存在于你的时间序列变量中的一种重复性运动。例如,一个地方的温度在夏季会比较高,在冬季会比较低。你可以计算出每月的平均温度,并将这种季节性作为预测未来数值的基础。
趋势可以是一个长期的上升或下降的模式。在温度时间序列中,由于全球变暖,可能会出现一个趋势。例如,在夏季/冬季季节性的基础上,你很可能看到平均温度随着时间的推移略有上升。
噪声是时间序列中既不能用季节性也不能用趋势解释的那部分变化。当建立模型时,你最终会把不同的成分结合到一个数学公式中。这样一个公式的两个部分可以是季节性和趋势。一个结合了这两部分的模型将永远不会完美地代表温度值:一个误差将始终存在。这由噪声系数来表示。
看一个简短的例子来了解如何在Python中分解一个时间序列,使用statsmodels库中的二氧化碳数据集[1]。
可以按以下方式导入数据。
- import statsmodels.datasets.co2 as co2
- _data = co2.load().data
- print(co2_data)
数据集看起来如下所示。它有一个时间索引(每周的日期),它记录了CO2的测量值。
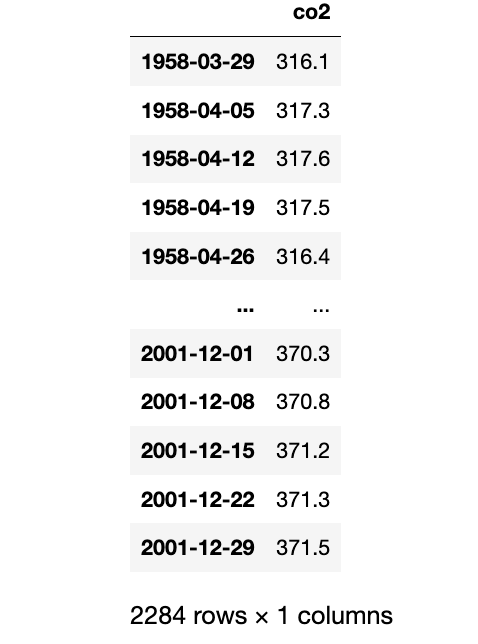
有一些NA值,你可以用插值法去除,如下所示。
co2_data = co2_data.fillna(co2_data.interpolate() )通过以下代码看到CO2数值的时间演变。
co2_data.plot()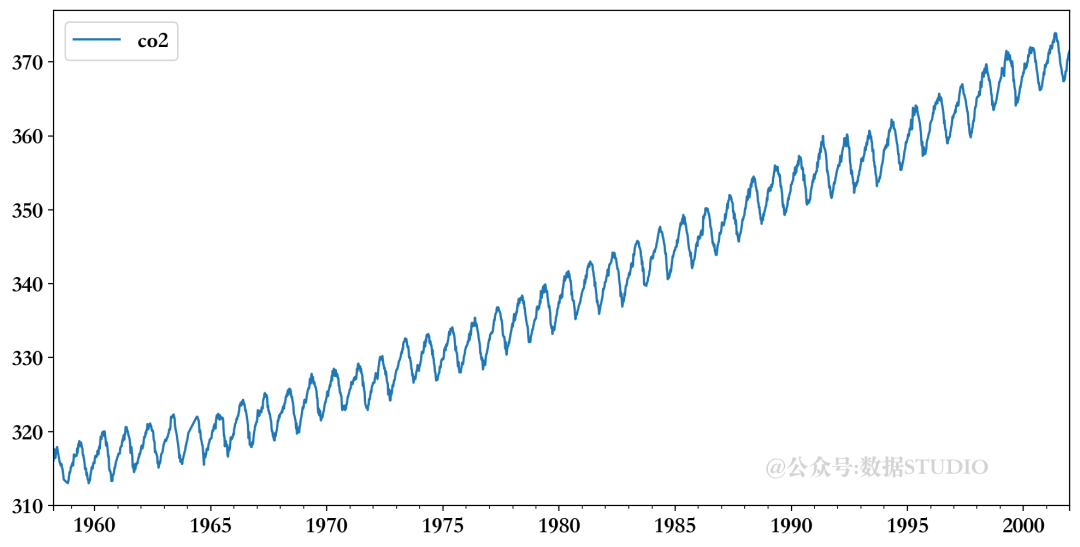
可以使用 statsmodels 的 seasonal_decompose函数进行开箱即用的分解。下面的代码将生成一个图,将时间序列分成趋势、季节性和噪声(这里称为残差)。
- from statsmodels.tsa.seasonal import seasonal_decompose
- result = seasonal_decompose(co2_data)
- result.plot()
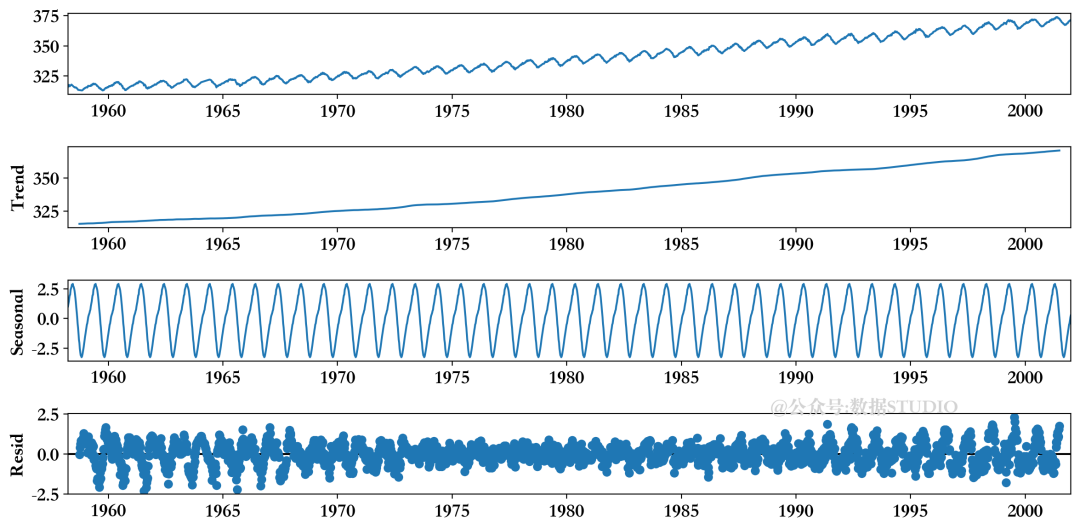
分解后的CO2时间序列图
CO2数据的分解显示了一个上升的趋势和强烈的季节性。
自相关性
自相关是指一个时间序列的当前值与过去值之间的相关性。
自相关可以是正的,也可以是负的。
1. 正的自相关
意味着现在的高价值有可能在未来产生高价值,反之亦然。你可以考虑一下股票市场:如果每个人都在购买一只股票,那么价格就会上升。当价格上涨时,人们认为这是一支值得购买的好股票,他们也会购买,从而推动价格进一步上涨。然而,如果价格下降,那么每个人都害怕崩溃,卖掉他们的股票,价格变得更低。
2. 负自相关
今天的高价值意味着明天的低价值,今天的低价值意味着明天的高价值。一个常见的例子是自然环境中的兔子种群。如果某年夏天有大量的野兔,它们会吃掉所有可用的天然资源。到了冬天,就没有什么可吃的了,所以很多兔子就会死去,幸存的兔子数量就会很少。在兔子数量少的这一年里,自然资源会重新增长,使兔子数量在下一年增长。
相关值之间的时间间隔称为 LAG。假设我们想知道今天的股票价格是否与昨天的价格或两天前的价格相关性更好。我们可以通过计算原始时间序列与延迟一个时间间隔的同一序列之间的相关性来测试这一点。因此,原始时间序列的第二个值将与延迟的第一个值进行比较。第三个原始值将与延迟的第二个值进行比较,依此类推。分别对滞后 1 和滞后 2 执行此过程将产生两个相关输出。该输出将告诉哪个滞后更相关。简而言之,这就是自相关。
有两个著名的图表可以帮助你检测数据集中的自相关情况:ACF图和PACF图。
ACF:自相关函数
自相关函数是一个帮助识别你的时间序列中是否存在自相关的工具。
你可以用Python计算一个ACF图,如下所示。
- from statsmodels.graphics.tsaplots import plot_acf
- plot_acf(co2_data)
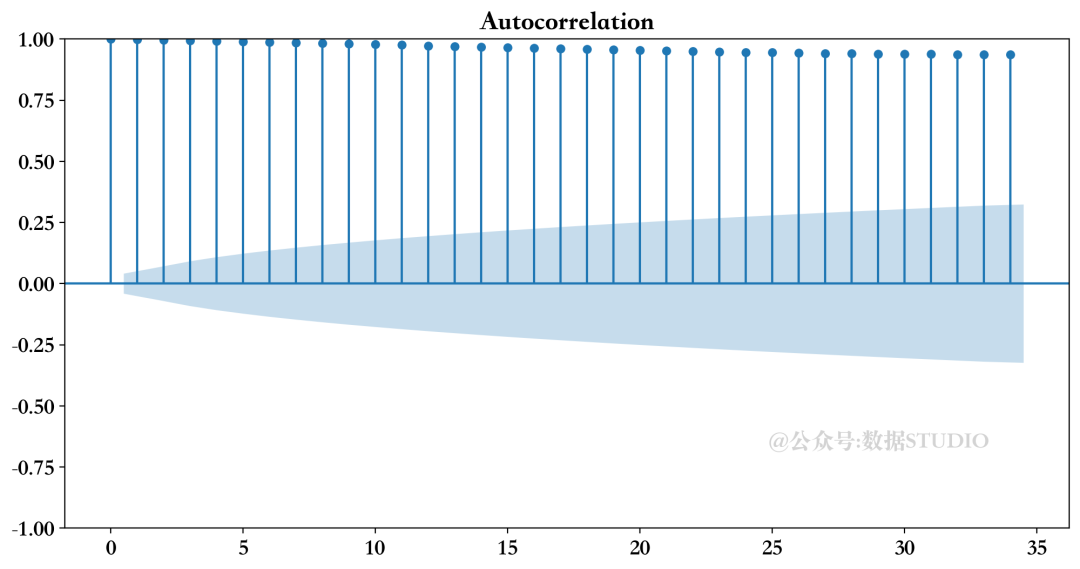
自相关图
在X轴上,可以看到时间步骤,这也被称为滞后期的数量。在Y轴上,可以看到每个时间步长与 "现在" 时间的相关程度。很明显,在这个图表中存在着明显的自相关。
PACF:自相关函数
PACF是ACF的一个替代函数。它不是给出自相关,而是给出局部自相关。这种自相关被称为局部自相关,因为在过去的每一步中,只有额外的自相关被列出。这与ACF不同,因为当变异性可以由多个时间点解释时,ACF包含重复的相关性。
例如,如果今天的值与昨天的值相同,但也与前天的值相同,ACF将显示两个高度相关的步骤。PACF将只显示昨天,而删除前天。
可以用Python计算一个PACF图,如下所示。
- from statsmodels.graphics.tsaplots import plot_pacf
- plot_pacf(co2_data)
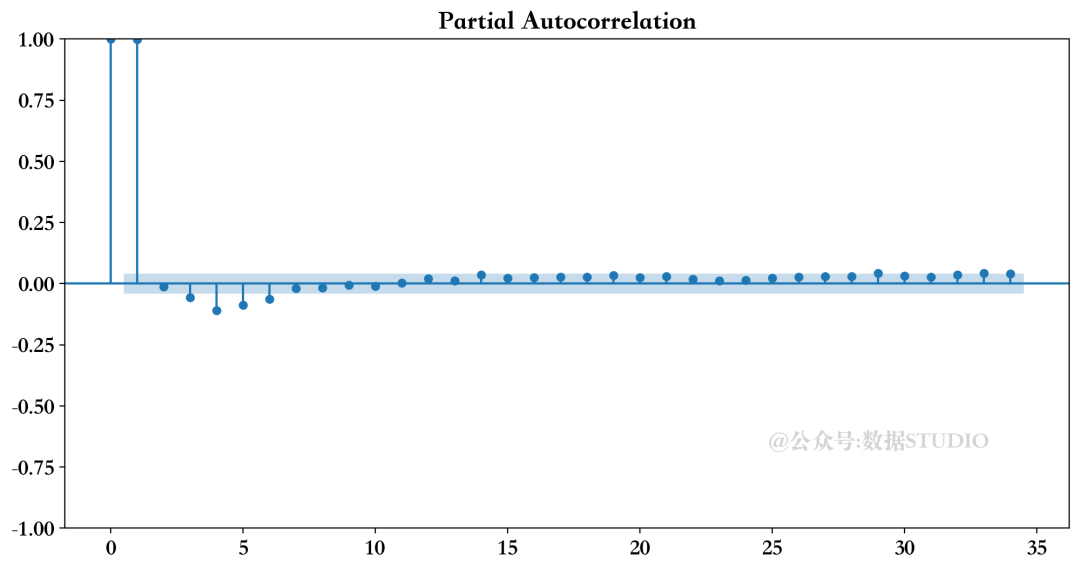
局部自相关图
你可以看到,PACF图更好地表示了CO2数据中的自相关性。与滞后1有很强的正自相关:现在的高值意味着你很可能在下一步观察到一个高值。由于这里显示的自相关是部分的,没有看到任何与早期滞后的重复效应,使PACF图更加整洁和清晰。
平稳性
时间序列的另一个重要定义是平稳性。一个静止的时间序列是一个没有趋势的时间序列。一些时间序列模型不能处理趋势(后面会详细介绍)。可以用Dickey-Fuller检验来检测非平稳性,你可以用差分法来消除非平稳性。
Dickey-Fuller检验
Dickey-Fuller检验是一种统计假设检验,可以检测非平稳性。可以使用下面的Python代码来对CO2数据进行Dickey-Fuller检验。
- from statsmodels.tsa.stattools import adfuller
- adf, pval, usedlag, nobs, crit_vals, icbest = adfuller(co2_data.co2.values)
- print('ADF test statistic:', adf)
- print('ADF p-values:', pval)
- print('ADF used number of lags:', usedlag)
- print('ADF number of observations:', nobs)
- print('ADF critical values:', crit_vals)
- print('ADF best information criterion: ', icbest)
结果如下。
ADF test statistic: 0.03378459745826228
ADF p-values: 0.9612384528286104
ADF used number of lags: 27
ADF number of observations: 2256
ADF critical values: {'1%': -3.4332519309441296,
'5%': -2.8628219967376647,
'10%': -2.567452466810334}
ADF best information criterion: 2578.3909092525305
ADF检验的零假设是时间序列中存在一个单位根。另一种假设是数据是静止的。
第二个值是p值。如果这个p值小于0.05,你可以拒绝零假设(拒绝非平稳性),接受另一假设(平稳性)。在这种情况下,我们不能拒绝零假设,将不得不假设数据是非平稳的。由于你已经看到了数据,你知道有一个趋势,所以这也证实了我们得到的结果。
差分
我们可以从时间序列中去除趋势。目标是只有季节性变化:这可以成为使用某些对季节性起作用但对趋势不起作用的模型的方法。
- prev_co2_value = co2_data.co2.shift()
- differenced_co2 = co2_data.co2 - prev_co2_value
- differenced_co2.plot()
差分后的CO2数据看起来如下。

差分化的CO2时间序列
如果你对差分数据重新进行ADF检验,你会确认这个数据现在确实是平稳的。
- adf, pval, usedlag, nobs, crit_vals, icbest = adfuller(differenced_co2.dropna())
- print('ADF test statistic:', adf)
- print('ADF p-values:', pval)
- print('ADF used number of lags: ', usedlag)
- print('ADF number of observations: ', nobs)
- print('ADF critical values: ', crit_vals)
- print('ADF best information criterion: ', icbest)
ADF test statistic: -15.727522408375837
ADF p-values: 1.3013480157810615e-28
ADF used number of lags: 27
ADF number of observations: 2255
ADF critical values: {'1%': -3.4332532193008443,
'5%': -2.862822565622804,
'10%': -2.5674527697012306}
ADF best information criterion: 2556.2779733634547
p值非常小,表明替代假设(平稳性)为真。
单步与多步的时间序列模型
在进入建模之前,最后一个重要的概念是单步模型与多步模型的概念。
有些模型在预测一个时间序列的下一个步骤时效果很好,但没有能力同时预测多个步骤。这些模型是单步模型。你可以通过对你的预测进行窗口化处理来制作多步模型,但有一个风险:当使用预测值进行预测时,你的误差会迅速增加,变得非常大。
多步骤模型是具有同时预测多步骤的内在能力的模型。它们通常是长期预测的更好选择,有时也适用于单步预测。关键是在开始建立模型之前,你要决定你要预测的步骤的数量。这完全取决于你的使用情况。
一步预测
多步预测
只能预测未来的一步
用来预测未来的多个步骤
可以通过窗口预测生成多步预测吗
没有必要对预测进行观察
多步预测的表现会更差吗
更适用于多步预测
该节主要介绍类型,后续章节详解
4.1经典的时间序列模型
经典的时间序列模型是一个模型系列,传统上在许多预测领域被大量使用。它们在很大程度上是基于时间序列内部的时间变化,并且它们在单变量时间序列中运行良好。一些高级选项也可以在模型中加入外部变量。这些模型一般只适用于时间序列,对其他类型的机器学习没有用。
4.2监督学习模型
监督模型是用于许多机器学习任务的模型系列。当一个机器学习模型使用明确定义的输入变量和一个或多个输出(目标)变量时,它就是监督学习模型。
监督学习模型可以用于时间序列,只要有办法提取季节性并将其放入一个变量。例子包括为一年、一个月或一周中的某一天创建一个变量,等等。然后,这些被用作监督学习模型中的X变量,"Y" 是时间序列的实际值。你还可以将y的滞后值(y的过去值)纳入X数据,以增加自相关效应。
4.3深度学习和最近的模型
在过去几年中,深度学习的日益普及也为预测工作打开了新的大门,因为已经发明了特定的深度学习架构,在序列数据上效果非常好。
云计算和人工智能作为一种服务的普及,也为该领域提供了许多新的模型。Facebook、亚马逊和其他大型科技公司正在开源或在其云平台上提供这些产品。新的 "黑匣子" 模型的出现,给算法工程师们提供了新的工具来尝试和测试,甚至可以击败以前的模型。
5.1 ARIMA 系列
ARIMA模型系列是一组可以组合的小型模型。ARMIA模型的每个部分都可以作为一个独立的组件使用,也可以将不同的构件组合起来。当所有的单独组件被组合在一起时,你就得到了SARIMAX模型。
1. 自回归(AR)
自回归是SARIMAX系列的第一个构建模块。你可以把AR模型看作是一个回归模型,用一个变量的过去(滞后)值来解释它的未来值。
AR模型的阶数表示为p,它代表模型中包含的滞后值的数量。最简单的模型是AR(1)模型:它只使用前一个时间段的值来预测当前值。可以使用的最大数值数量是时间序列的总长度(即你使用所有以前的时间步骤)。
2. 移动平均线(MA)
移动平均线是更大的SARIMAX模型的第二个构件。其原理与AR模型类似:它使用过去的数值来预测变量的当前值。
移动平均模型所使用的过去的值并不是变量的值。相反,移动平均数使用以前时间步骤中的预测误差来预测未来。
这听起来有违直觉,但背后是有逻辑的。当一个模型有一些未知但有规律的外部扰动时,你的模型的误差可能具有季节性或其他模式。MA模型是一种捕获这种模式的方法,甚至不需要确定它来自哪里。
MA模型也可以使用多个时间回溯步骤。例如,MA(1)模型的阶数为1,只使用一个时间回溯步骤。
3. 自回归移动平均线(ARMA)
自回归移动平均数,或称ARMA,模型将之前的两个构件组合成一个模型。因此,ARMA可以同时使用过去的价值和预测误差。
ARMA可以有不同的AR和MA过程的滞后值。例如,ARMA(1, 0)模型的AR阶数为1(p=1),MA阶数为0(q=0)。这实际上只是一个AR(1)模型。MA(1)模型与ARMA(0, 1)模型相同。其他组合是可能的。例如,ARMA(3, 1)的AR阶数为3个滞后值,MA使用1个滞后值。
4. 自回归综合移动平均法(ARIMA)
ARMA模型需要一个静止的时间序列。正如前面看到的,平稳性意味着一个时间序列保持稳定。可以使用Augmented Dickey-Fuller测试来测试时间序列是否稳定,反之就应用差分。
ARIMA模型在ARMA模型的基础上增加了自动差分功能。它有一个额外的参数,你可以将其设置为时间序列需要被差分的次数。例如,一个需要进行一次差分的ARMA(1,1)将产生以下符号。ARMA(1,1,1)。第一个1是指AR阶数,第二个1是指差分,第三个1是指MA阶数。ARIMA(1, 0, 1)将与ARMA(1, 1)相同。
5. 季节性自回归综合移动平均数(SARIMA)
SARIMA将季节性效应加入到ARIMA模型中。如果时间序列中存在季节性,则可以在预测中使用该模型。
SARIMA的符号比ARIMA要复杂一些,因为每个成分在常规参数的基础上还会收到一个季节性参数。
例如,让我们考虑之前看到的ARIMA(p, d, q)。在SARIMA的符号中,这变成了SARIMA(p, d, q)(P, D, Q)m。
m是简单的每年的观察数:月度数据有m=12,季度数据有m=4等等。小字母(p, d, q)代表非季节性订单。大写字母(P, D, Q)代表季节性订单。
6. 季节性自回归综合移动平均数与外源性回归者(SARIMAX)
最复杂的变体是SARIMAX模型,它重新组合了AR、MA、差分和季节性效应。在此基础上,它增加了X:外部变量。如果你有任何可以帮助你的模型改进的变量,你可以用SARIMAX添加它们。
使用CO2的Auto Arima的例子
现在我们已经看到了ARIMA系列的所有单个组件,现在使用一个例子实际应用起来。看看我们是否可以用这个模型为CO2数据建立一个预测模型。
ARIMA或SARIMAX模型的困难之处在于,你有许多参数(p, d, q)甚至(p, d, q)(P, D, Q)需要选择。
在某些情况下,可以检查自相关图并确定参数的合理选择。你可以使用statsmodels库的SARIMAX方法实现,并尝试用选择的参数进行演示。
另一种方法是使用一个auto-arima函数,自动优化超参数。Python库Pyramid 原理是尝试不同的组合并选择具有最佳性能的组合。
- import pmdarima as pm
- from pmdarima.model_selection import train_test_split
- import numpy as np
- import matplotlib.pyplot as plt
首先进行训练/测试集的分割。
train, test = train_test_split(co2_data.co2.values, train_size=2200)然后在CO2训练数据上拟合模型,并使用最佳选择的模型进行预测。
- model = pm.auto_arima(train, seasonal=True, m=52)
- preds = model.predict(test.shape[0])
并创建可视化图表进行展示。
- x = np.range(y.shape[0])
- plt.plot(co2_data.co2.value[:2200], train)
- plt.plot(co2_data.co2.value[2200:], preds)
- plt.show()
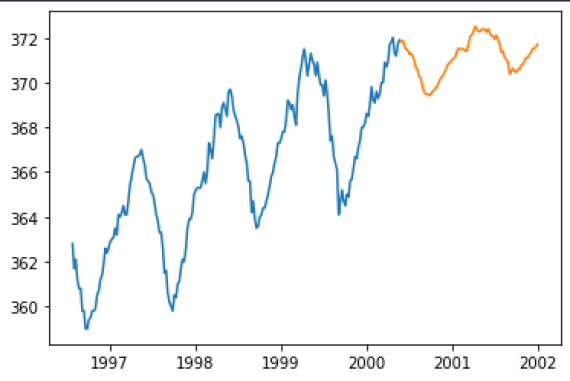
实际数据为蓝色,预测数据为橙色
该图中,蓝色的线是实际情况(训练数据),橙色的线是预测数据。
关于Pyramid的更多信息和例子,你可以查看Pyramid官方文档[2]。
向量自回归(VAR)及其衍生VARMA和VARMAX
我们可以把矢量自回归或VAR看作是ARIMA的多变量替代品。你不是预测一个因变量,而是同时预测多个时间序列。当不同时间序列之间存在强烈的关系时,这或许特别有用。而向量自回归与标准的AR模型一样,只包含一个自回归成分。
VARMA模型对应于ARMA模型的多变量模型。VARMA对ARMA的作用就像VAR对AR的作用一样:它在模型中增加了一个移动平均的成分。
更进一步,我们可以使用VARMAX。X代表外部(外生)变量。外生变量是可以帮助模型做出更好的预测的变量,但它们本身不需要被预测。statsmodels VARMAX可以轻松实现该方法。
有更高级的版本,如季节性VARMAX (SVARMAX),但它们变得如此复杂和特定,很难找到轻松和有效的实现。一旦模型变得如此复杂,就很难理解模型内部发生了什么,通常最好开始研究其他熟悉的模型。
5.2 平滑
平滑是一个过程,通常通过减少噪声的影响来提高我们预测序列的能力。平滑可以改进前瞻性预测的重要工具。
指数平滑法是一种基本的统计技术,可以用来平滑时间序列。时间序列模式往往有很多长期变化,但也有短期(嘈杂)的变化。平滑化可以使你的曲线更加平滑,从而使长期变异性变得更加明显,短期(嘈杂)模式被去除。
平滑后的时间序列可用于分析。
1. 简单移动平均(SMA)
简单移动平均是最简单的平滑技术。它包括用当前值和几个过去值的平均值来代替当前值。要考虑到的过去值的确切数量是一个参数。你使用的数值越多,曲线就会变得越平滑。同时,你也会失去越来越多的变化。
2. 简单指数平滑法(SES)
指数平滑法是对这种简单的移动平均数的一种改编。它不是取平均值,而是取过去数值的加权平均值。一个更远的值会算得更少,而一个更近的值会算得更多。
3. 双指数平滑法(DES)
当时间序列数据中存在趋势时,应该避免使用简单指数平滑法:它在这种情况下效果不好,因为该模型不能正确区分变化和趋势。而可以使用双指数平滑法。
在DES中,有一个指数滤波器的递归应用。这使能够消除趋势问题。这在时间零点时使用以下公式工作。
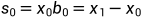
以及后续时间步骤的下列公式。
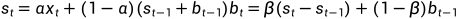
其中  是数据平滑系数,
是数据平滑系数,  是趋势平滑系数。
是趋势平滑系数。
4. 霍尔特-温特的指数平滑法(HWES)
更进一步,可以使用三重指数平滑法,这也被称为霍尔特-温特的指数平滑法。只有当时间序列数据中有三个重要的信号时,才应该使用这个方法。例如,一个信号是趋势,另一个是每周的季节性,第三个可能是每月的季节性。
Python中指数平滑的一个例子
在下面的例子中,可以看到如何对CO2数据应用简单指数平滑法。平滑化水平表明曲线应该变得多平滑。在这个例子中,它被设置得很低,表示一个非常平滑的曲线。请自由发挥这个参数的作用,看看不那么平滑的版本是什么样子。
- from statsmodels.tsa.api import SimpleExpSmoothing
- es = SimpleExpSmoothing(co2_data.co2.values)
- es.fit(smoothing_level=0.01)
- plt.plot(co2_data.co2.values)
- plt.plot(es.predict(es.params, start=0, end=None) )
- plt.show()
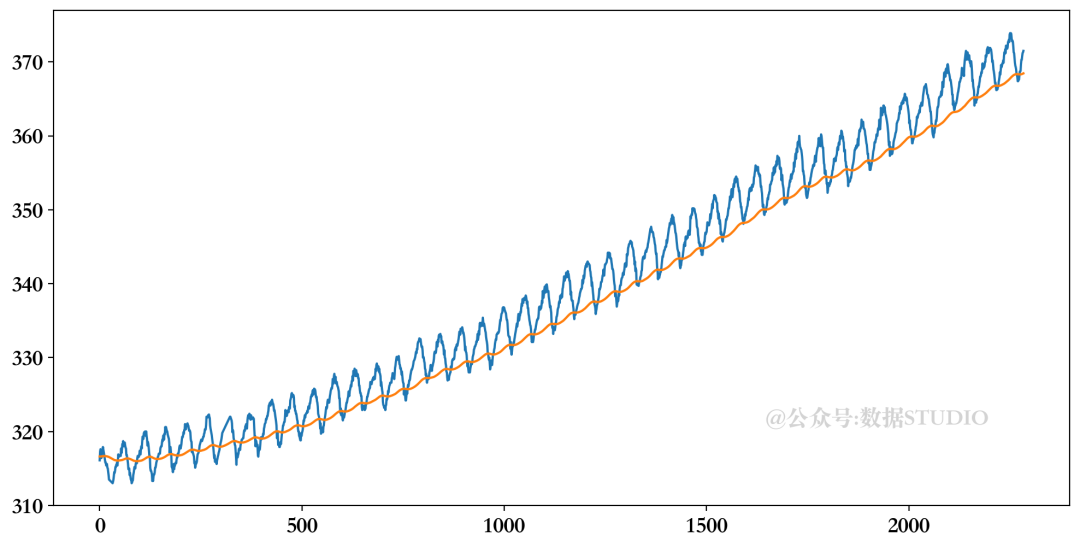
蓝色为原始数据,橙色为平滑图
蓝线代表原始数据,橙线代表平滑后的曲线。由于它是简单指数平滑,它只能捕捉到一个信号:趋势。
有监督机器学习模型的工作方式与经典的机器学习模型非常不同。主要区别在于,它们认为变量是因变量或自变量。因变量,或目标变量,是想要预测的变量。独立变量是帮助进行预测的变量。
监督机器学习模型不是专门为时间序列数据制作的。毕竟,在时间序列数据中往往没有独立变量。然而,通过将季节性(例如基于你的时间戳)转换为独立变量,使它们适应时间序列是相当简单的。
6.1线性回归
线性回归可以说是最简单的有监督机器学习模型。线性回归估计的是线性关系:每个自变量都有一个系数,表明这个变量如何影响目标变量。
简单线性回归是一种线性回归,其中只有一个自变量。非时间序列数据中的简单线性回归模型的例子如下:热巧克力的销售量取决于外部温度(摄氏度)。
温度越低,热巧克力的销量就越高。从视觉上看,这可能看起来像下面的图表。

在多元线性回归中,不是只使用一个自变量,而是使用多个自变量。
你可以想象一下,将2D图转换成3D图,其中第三轴代表变量 "价格"。在这种情况下,你将建立一个线性模型,用温度和价格来解释销售情况。你可以根据你的需要添加更多的变量。
当然,现在这不是一个时间序列数据集:没有时间变量存在。那么,你怎么能把这种技术用于时间序列呢?答案是相当直接的。在这个数据集中,你可以添加年、月、星期等变量,而不是只使用温度和价格。
如果你在时间序列上建立一个监督模型,你的缺点是你需要做一点特征工程,以某种方式将季节性提取到变量中。然而,一个优点是,添加外生变量变得更加容易。
现在让我们看看如何在CO2数据集上应用线性回归。你可以按以下方式准备CO2数据。
- import numpy as np
-
- #提取季节性数据
- months = [x.month for x in co2_data.index]
- years = [x.year for x in co2_data.index]
- day = [x.day for x in co2_data.index]
-
- # 转换为一个矩阵
- X = np.array([day, months, years]).T
然后有三个自变量:日、月、周。还可以考虑其他的季节性变量,如星期几,周数等。
然后可以用scikit-learn建立一个线性回归模型,并进行预测,看看模型学到了什么
- from sklearn.linear_model import LinearRegression
- # 拟合模型
- my_lr = LinearRegression()
- my_lr.fit(X, co2_data.co2.value)
- # 在同一时期进行预测
- preds = my_lr.predict(X)
- # 绘制已经学到的东西
- plt.plot(co2_data.index, co2_data.co2.value)
- plt.plot(co2_data.index, preds)
当使用这段代码时,你会得到以下的图,显示出与数据相对较好的拟合。
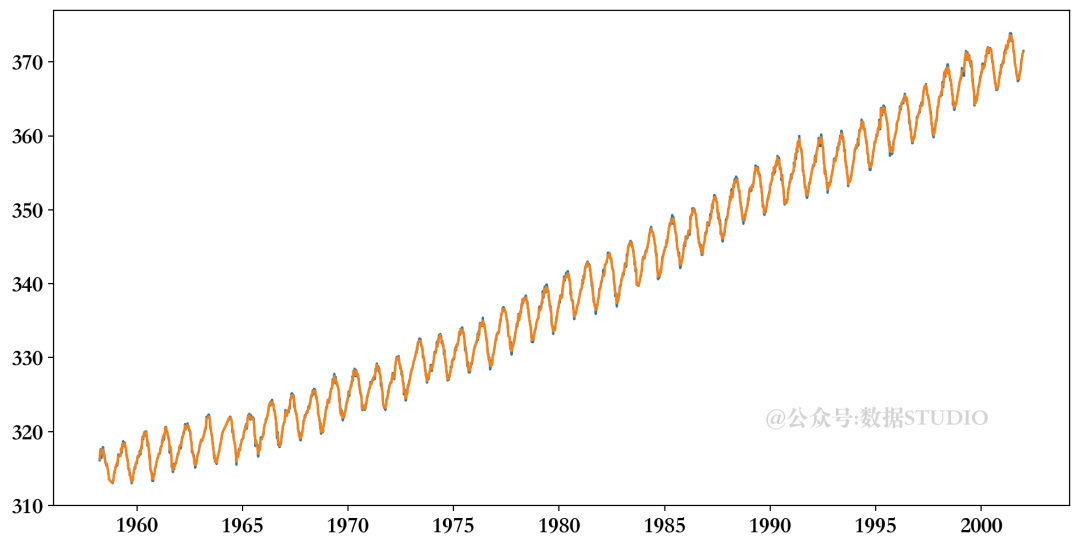
线性回归预测
6.2随机森林模型
线性模型是非常有限的:它只能适应线性关系。有时这就足够了,但在大多数情况下,最好使用性能更强的模型。随机森林是一个广泛使用的模型,它可以拟合非线性关系。它仍然非常容易使用。
- from sklearn.ensemble import RandomForestRegressor
-
- # 拟合模型
- my_rf = RandomForestRegressor()
- my_rf.fit(X, co2_data.co2.values)
-
- # 在同一时期进行预测
- preds = my_rf.predict(X)
-
- # 绘制已经学到的东西
- plt.plot(co2_data.index, co2_data.co2.values)
- plt.plot(co2_data.index, preds)
现在对训练数据的拟合甚至比以前更好。

随机森林预测
现在,只要了解这个随机森林已经能够更好地学习训练数据就足够了。在本文的后面部分,你将看到更多的模型评估的定量方法。
6.3 XGBoost
XGBoost模型是第三个模型。还有许多其他模型,但随机森林和XGBoost被认为是监督机器学习系列中的绝对经典。
XGBoost是一个基于梯度提升框架的机器学习模型。这个模型是一个弱学习者的集合模型,就像随机森林一样,但有一个有趣的优势。在标准的梯度提升中,各个树是依次拟合的,每个连续的决策树都是以这样的方式拟合的,以最小化之前的树的误差。XGBoost获得了同样的结果,但仍然能够进行并行学习。
- import xgboost as xgb
- # 拟合模型
- my_xgb = xgb.XGBRegressor()
- my_xgb.fit(X, co2_data.co2.values)
- # 在同一时期进行预测
- preds = my_xgb.predict(X)
- # 绘制已经学到的东西
- plt.plot(co2_data.index, co2_data.co2.values)
- plt.plot(co2_data.index, preds)

XGBoost预测
如图所示,这个模型也很符合数据。我们将在本文的后面部分学习如何进行模型评估。
7.1GARCH
GARCH代表广义自回归条件异方差。它是一种估计金融市场波动率的方法,通常用于此用例。它很少用于其他用例。
如果假设误差方差采用自回归移动平均模型(ARMA) 模型,则该模型是广义自回归条件异方差 (GARCH) 模型。
在这种情况下,GARCH ( p , q ) 模型(其中p是 GARCH 项的阶 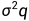 是 ARCH 项的阶
是 ARCH 项的阶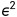 ,按照原始论文的符号,由下式给出
,按照原始论文的符号,由下式给出
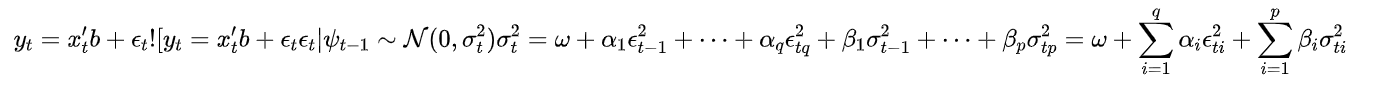
该模型在这方面工作得很好,因为它假设时间序列的误差方差是ARMA模型,而不是实际数据。通过这种方式,可以预测可变性而不是实际值。
GARCH系列模型存在很多变种,例如,请看Autoregressive_conditional_heteroskedasticity[3]。这个模型很值得了解,但只应在需要预测变异性的时候使用,因此它与本文介绍的其他模型相对不同。
7.2 TBATS
TBATS代表了以下成分的组合。
三角形的季节性
Box-Cox转换
ARMA误差
趋势
季节性成分
该模型创建于2011年,是预测具有多个季节性时期的时间序列的解决方案。由于它相对较新,相对较先进,所以它的普及率较低,不像ARIMA系列的模型那样被广泛使用。
TBATS的一个有用的Python实现可以在Pythons sktime[4]包中找到。
目前,我们学习了两个相对不同的模型系列,每一个都有其特定的模型拟合方式。经典的时间序列模型专注于过去和现在之间的关系。有监督的机器学习模型专注于因果关系。
现在你将看到三个更近期的模型,也可用于预测。它们的理解和掌握更加复杂,可能(也可能不会)产生更好的结果,这取决于数据和用例的具体内容。
8.1 LSTM (长短期记忆模型)
LSTM是递归神经网络。神经网络是非常复杂的机器学习模型,通过网络传递输入数据。网络中的每个节点都会学习一个非常简单的操作。神经网络由许多这样的节点组成。该模型可以使用大量的简单节点,这使得整体预测非常复杂。因此,神经网络可以适应非常复杂和非线性的数据集。
RNN是一种特殊类型的神经网络,其中网络可以从序列数据中学习。这对多种用例都很有用,包括理解时间序列(这显然是随时间变化的数值序列),但也包括文本(句子是单词序列)。
LSTM是RNN的一种特殊类型。它们在多个场合被证明对时间序列预测有用。它们需要一些数据,学习起来比监督模型更复杂。一旦你掌握了它们,它们可以被证明是非常强大的,这取决于你的数据和你的具体用例。
要学习LSTM,Python中的Keras[5]库是一个不错的选择。
8.2 Prophet
Prophet是一个时间序列库,由Facebook开源。它是一个黑箱模型,因为它将产生预测,而不需要太多的用户规范。这可能是一个优势,因为你几乎可以自动生成预测模型,而无需太多的知识或努力。
另一方面,这里也有一个风险:如果你没有给予足够的关注,你很可能产生一个在自动模型构建工具看来不错的模型,但实际上却不能很好地工作。
在使用这种黑盒模型时,建议进行广泛的模型验证和评估,然而,如果你发现它在你的特定用例上运行良好,你可能会发现这里有很多附加价值。
你可以在Facebook的GitHub上的prophet[6]上找到很多资源。
8.3 DeepAR
DeepAR是亚马逊开发的另一个黑箱模型。它的功能是不同的,但在用户体验方面,它和Prophet是相对平等的。这个想法还是要有一个Python库来完成所有繁重的工作。
同样,需要谨慎,因为我们永远不能期望任何黑箱模型都是完全可靠的。在下一部分中,我们将看到更多关于模型评估和基准测试的内容,这对于这样复杂的模型来说是非常重要的。模型越复杂,错误就越多!
在python包中,有一个很好的、易于使用的DeepAR的实现:Gluon[7]。
- import matplotlib.pyplot as plt
- from gluonts.dataset.util import to_pandas
- from gluonts.dataset.pandas import PandasDataset
- from gluonts.dataset.repository.datasets import get_dataset
- from gluonts.model.deepar import DeepAREstimator
- from gluonts.mx import Trainer
-
- dataset = get_dataset("airpassengers")
-
- deepar = DeepAREstimator(prediction_length=12, freq="M", trainer=Trainer(epochs=5))
- model = deepar.train(dataset.train)
-
- # Make predictions
- true_values = to_pandas(list(dataset.test)[0])
- true_values.to_timestamp().plot(color="k")
-
- prediction_input = PandasDataset([true_values[:-36], true_values[:-24], true_values[:-12]])
- predictions = model.predict(prediction_input)
-
- for color, prediction in zip(["green", "blue", "purple"], predictions):
- prediction.plot(color=f"tab:{color}")
-
- plt.legend(["True values"], loc="upper left", fontsize="xx-large")

9.1时间序列度量
在选择模型时,首先要定义的是我们想看的指标。在前面的部分中,我们已经看到了具有不同质量的多重拟合(想一想线性回归与随机森林的比较)。
为了进一步进行模型选择,将需要定义一个指标来评估你的模型。预测中一个非常常用的模型是平均平方误差。这个指标测量每个时间点的误差并取其平方。这些平方误差的平均值被称为平均平方误差。一个经常使用的替代方法是平均平方误差的根:平均平方误差的平方根。
另一个经常使用的指标是平均绝对误差:它不是取每个误差的平方,而是取这里的绝对值。平均绝对百分比误差是一个变种,其中每个时间点的绝对误差被表示为实际值的一个百分比。这就产生了一个百分比的度量,这很容易解释。
9.2 时间序列训练测试分割
在评估机器学习时要考虑的第二件事是,一个在训练数据上运行良好的模型,不一定在新的、样本外的数据上运行良好。这样的模型被称为过拟合模型。
有两种常见的方法可以帮助我们估计一个模型的归纳是否正确:训练-测试-分割和交叉验证。
训练测试分割意味着在拟合模型之前删除一部分数据。举例来说,可以从CO2数据库中删除最后3年的数据,并使用剩余的40年数据来拟合模型。然后预测三年的测试数据,并在预测和过去三年的实际值之间衡量我们选择的评估指标。
为了确定基准和选择模型,可以在40年的数据上建立多个模型,并对所有的模型做测试集评估。基于这种测试性能,可以选择性能最强的模型。
当然,如果要建立一个短期预测模型,使用三年的数据是没有意义的:我们会选择一个与在现实中预测的时期相当的评估期。
9.3 时间序列交叉验证
训练测试分割的风险在于,只在一个时间点上进行测量。在非时间序列数据中,测试集通常由随机选择的数据点产生。然而,在时间序列中,这在很多情况下是行不通的:当使用序列时,我们不能在序列中删除一个点而仍然期望模型能够工作。
因此,时间序列训练测试分割最好通过选择最后一期作为测试集来应用。这里的风险是,如果最后一期不是很可靠,则可能会出错。在最近的疫情期间,许多商业预测已经完全走样:基本趋势已经改变。
交叉验证是一种进行重复训练测试评估的方法。它不是做一个训练测试分割,而是做多个(具体数量是用户定义的参数)。例如,如果使用3倍交叉验证法,把数据集分成三个相等的部分。然后,在三分之二的数据集上拟合三次相同的模型,并使用另三分之一进行评估。最后,有三个评估分数(每个都在不同的测试集上),可以使用平均值作为最终的衡量标准。
通过这样做,可以避免偶然选择在测试集中工作的模型:现在已经确保了它在多个测试集中工作。
然而,在时间序列中,我们不能应用随机选择来获得多个测试集。如果你这样做,你最终会得到很多数据点缺失的序列。
可以在时间序列交叉验证中找到解决方案。它所做的是创建多个训练测试集,但每个测试集都是周期的结束。例如,第一个列车测试划分可以建立在前10年的数据上(5个训练,5个测试)。第二个模型将基于前15年的数据(10个训练,5个测试)等。这可以很好地工作,但缺点是每个模型在训练数据中使用的年数不相同。
另一种方法是做滚动分割(总是5年训练,5年测试),但缺点是我们永远不能使用超过5年的训练数据。
9.4时间序列模型实验
总之,在做时间序列模型选择时,以下问题是在开始实验前要确定的关键。
使用的是哪种衡量标准?
想预测哪个时期?
如何确保模型在未来的数据点上工作,而这些数据点还没有被模型看到?
一旦你有了上述问题的答案,就可以开始尝试不同的模型,并使用确定的评估策略来选择和改进模型。
参考资料
[1]statsmodels库中的CO2数据集: https://www.statsmodels.org/dev/datasets/generated/co2.html
[2]Pyramid官方文档: https://pypi.org/project/pmdarima/
[3]ARCH: https://en.wikipedia.org/wiki/Autoregressive_conditional_heteroskedasticity
[4]sktime: https://www.sktime.org/en/latest/api_reference/auto_generated/sktime.forecasting.tbats.TBATS.html
[5]Keras: https://keras.io/api/layers/recurrent_layers/lstm/
[6]prophet: https://facebook.github.io/prophet/
[7]Gluon: https://ts.gluon.ai/api/gluonts/gluonts.model.deepar.html
如果本文对您有帮助,希望点赞+收藏支持一下~

