
热门标签
热门文章
- 1Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】_uie模型的训练数据集
- 2从区块链到DAG(五)--DAG项目介绍IOTA和Obyte_the tangle popov, serguei
- 3【云计算与虚拟化】第二章 实验二 Vmware Workstation 15的使用
- 4解决文件传输难题:如何绕过Gitee的100MB上传限制_gitee在线上传单个文件最大 10m,本地推送单个文件最大 100m
- 5kafka消费信息时,产生重复消费的情况 - 20190121
- 6【AI大模型】在测试中的深度应用与实践案例_ai大模型在测试中的应用
- 7Python3.0学习笔记2_“*”可用于字符串的重复,下面选项正确的有
- 8spark中的cache和checkpoint_spark cache checkpoint
- 9C# list 成员对象是int型存在堆区还是栈区
- 10区块链技术之身份认证_区块链中的身份认证
当前位置: article > 正文
Ollama本地部署大模型_ollama 接口
作者:喵喵爱编程 | 2024-06-19 11:45:31
赞
踩
ollama 接口
一、Ollama介绍
1. Ollama
Ollama 是一个开源框架,旨在为用户提供在本地运行大型语言模型的能力。
Ollama 支持多种主流模型的下载,也允许用户通过自定义导入的方式来使用自训练的模型。
Ollama 的优势在于其强大的功能和便捷的 API,能够为用户提供灵活的语言模型使用体验。
官网:https://ollama.com
支持的开源大模型:https://ollama.com/library
2. Open-webui
Open WebUI是一个可扩展的、功能丰富的、用户友好的WebUI。
支持各种LLM运行器,包括Ollama和与OpenAI兼容的APIs。
官网:https://github.com/open-webui/open-webui?tab=readme-ov-file
二、CPU运行Ollama
1. 启动
- ollama
docker run -d --restart=always -p 3001:11434 -v /home/ollama:/root/.ollama --name ai-ollama docker.nju.edu.cn/ollama/ollama:0.1.38
- 1
- open-webui
docker run -d --restart=always -p 3002:8080 -e OLLAMA_API_BASE_URL=http://127.0.0.1:3001/api \
-e HF_ENDPOINT=https://hf-mirror.com -v /home/open-webui-ollama:/app/backend/data \
--name open-webui-ollama ghcr.nju.edu.cn/open-webui/open-webui:git-7a556b2-ollama
- 1
- 2
- 3
2. 注册使用
-
open-webui网址
http://ip:3000 -
注册
-
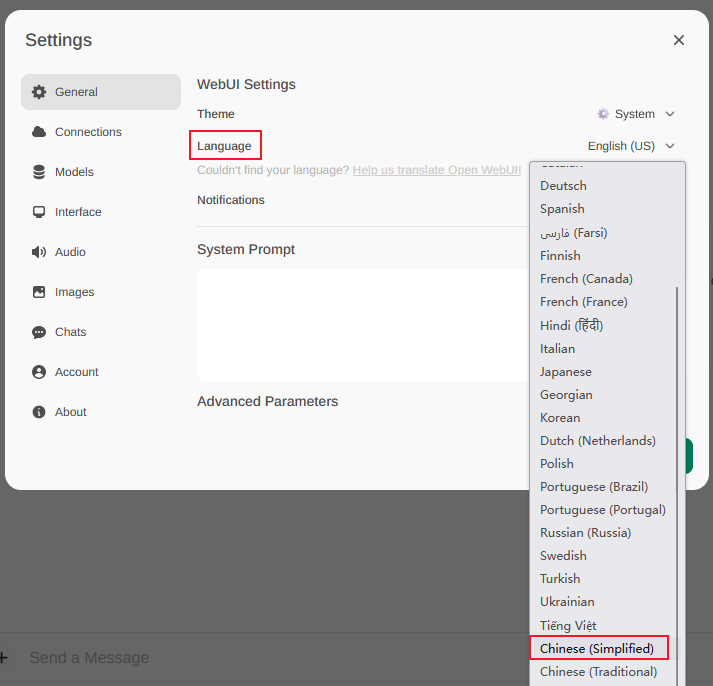
修改语言
右上角 Settings
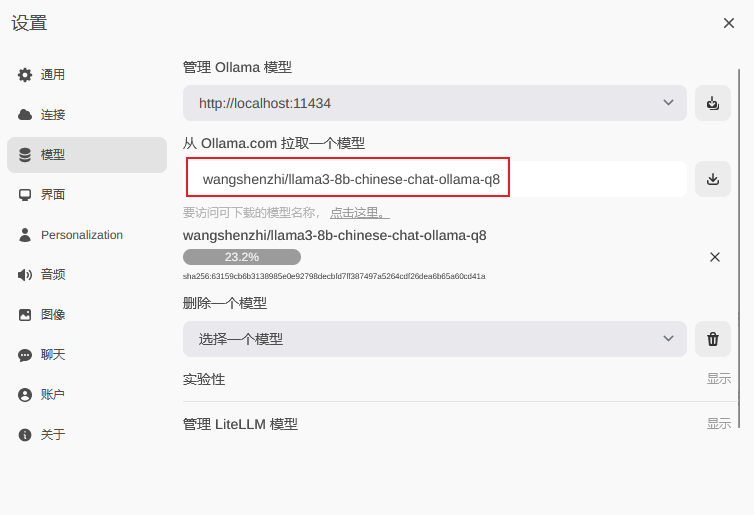
3. 下载模型
例如:wangshenzhi/llama3-8b-chinese-chat-ollama-q8
- 阿里通义千问
https://ollama.com/library/qwen
4. 聊天对话
CPU:E5-2683 v4, 回答用时:110秒,CPU占用:49%

三、GPU运行Ollama
1. GPU安装
- 安装
sudo apt-get install -y cuda-drivers-535
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.0-1_all.deb
sudo dpkg -i cuda-keyring_1.0-1_all.deb
sudo apt-get update
sudo apt-get -y install nvidia-cuda-toolkit
sudo apt install -y nvidia-container-runtime
- 1
- 2
- 3
- 4
- 5
- 6
- /etc/docker/daemon.json 添加内容
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 重启docker
systemctl daemon-reload && systemctl restart docker
- 1
- 重启后验证
docker run --rm --gpus all nvidia/cuda:11.0.3-base nvidia-smi
- 1
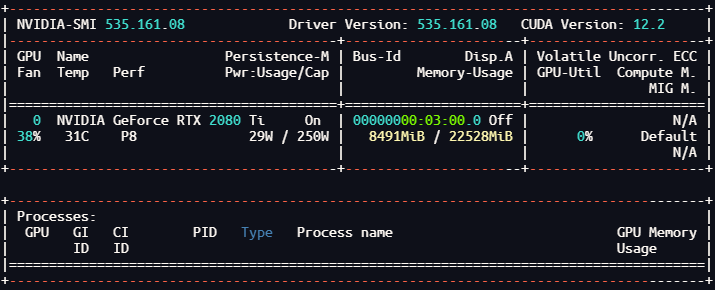
2. 启动
- ollama
docker run -d --restart=always -p 3001:11434 -v /home/ollama:/root/.ollama --gpus all --name ai-ollama docker.nju.edu.cn/ollama/ollama:0.1.38
- 1
- open-webui
docker run -d --restart=always -p 3002:8080 -e OLLAMA_API_BASE_URL=http://127.0.0.1:3001/api \
-e HF_ENDPOINT=https://hf-mirror.com -v /home/open-webui-ollama:/app/backend/data \
--gpus all --name ai-open-webui ghcr.nju.edu.cn/open-webui/open-webui:git-7a556b2-ollama
- 1
- 2
- 3
3. 聊天对话
注册使用流程同上。
GPU:NVIDIA 2080 Ti 22 GB, 回答用时:17秒,GPU占用:80%,显存使用:8.3GB

四、Ollama接口
1. 运行模型
- 需要8.3G显存
docker exec -it ai-ollama ollama run wangshenzhi/llama3-8b-chinese-chat-ollama-q8:latest
- 1
- 或 需要18G显存
docker exec -it ai-ollama ollama run qwen:32b
- 1
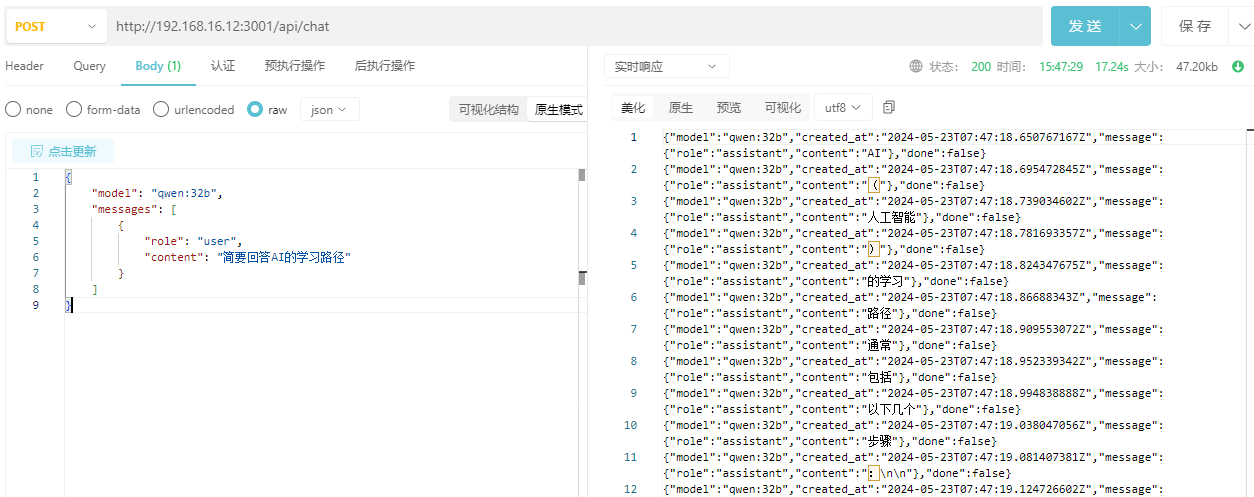
2. 流式对话
http://ip:3001/api/chat
{
"model": "qwen:32b",
"messages": [
{
"role": "user",
"content": "简要回答AI的学习路径"
}
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
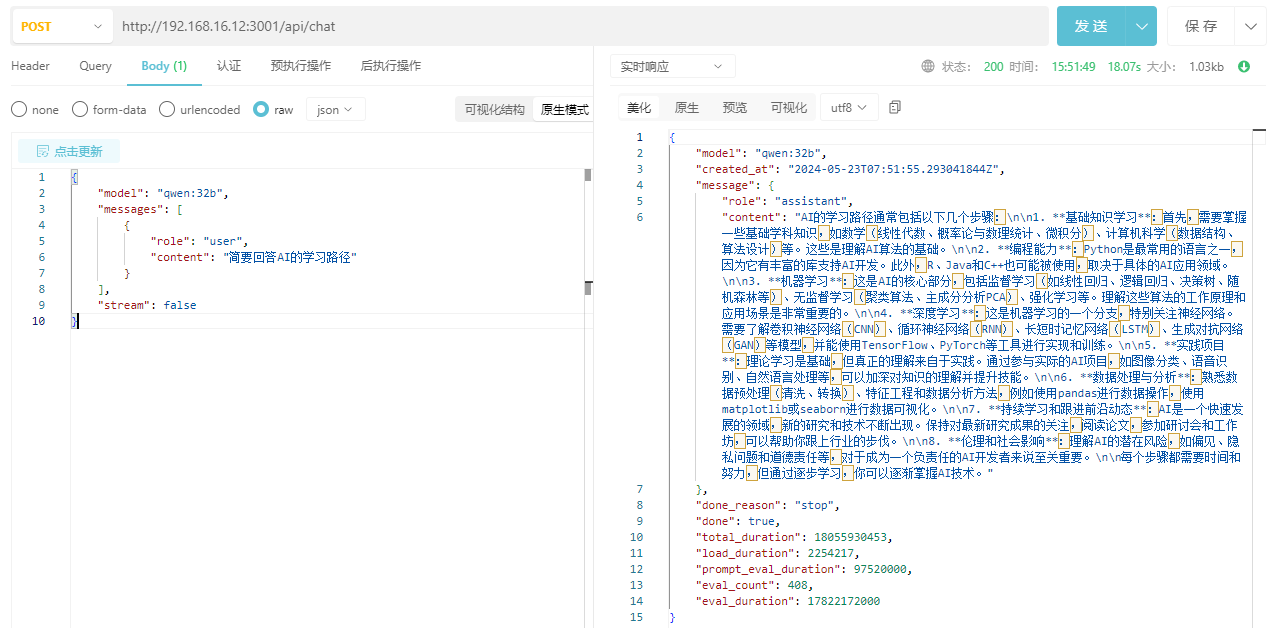
3. 单体对话
http://ip:3001/api/chat
{
"model": "qwen:32b",
"messages": [
{
"role": "user",
"content": "简要回答AI的学习路径"
}
],
"stream": false
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
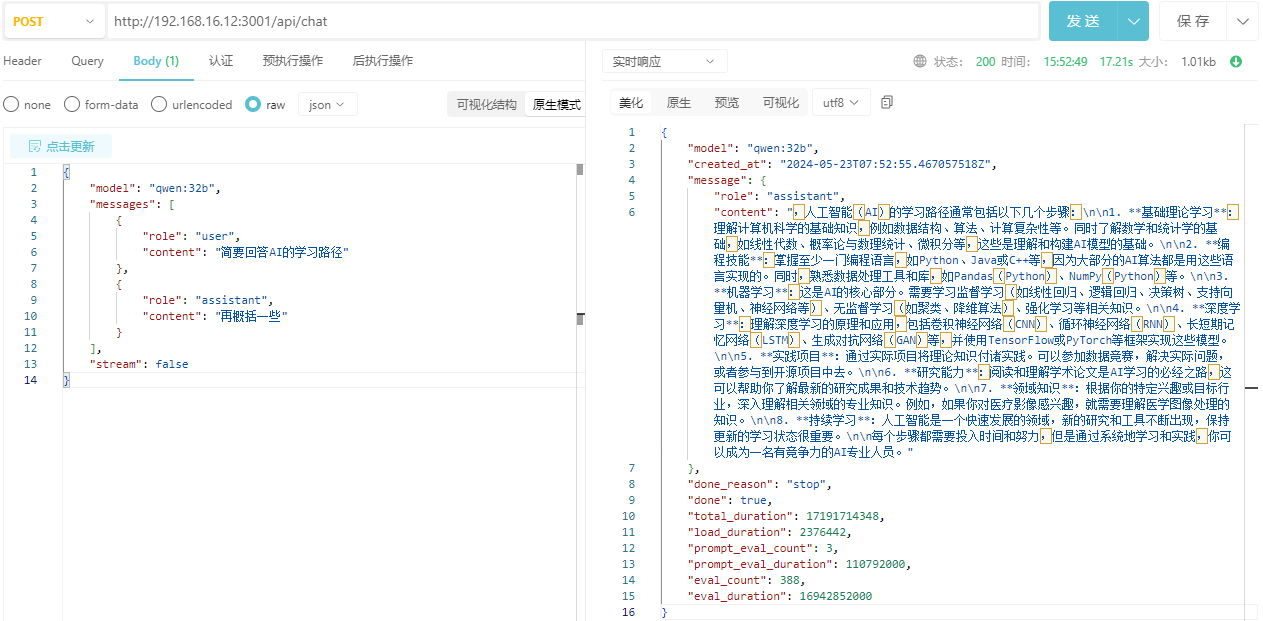
4. 带历史记录对话
http://ip:3001/api/chat
{
"model": "qwen:32b",
"messages": [
{
"role": "user",
"content": "简要回答AI的学习路径"
},
{
"role": "assistant",
"content": "再概括一些"
}
],
"stream": false
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/喵喵爱编程/article/detail/736335
推荐阅读
相关标签

