
热门标签
热门文章
- 1SpringFramework核心 - Bean的生命周期_spring framework的bean生命周期是怎样的
- 2java 获取本机cpu占用_java如何获取系统CPU、内存占用
- 3html中添加随机验证码,基于JS实现一个随机生成验证码功能
- 4dell idrac 复位_DELL 服务器 装系统前初始化(恢复出厂、超线程、虚拟化、iDRAC设置)...
- 5玩转Reactjs第三篇-组件(模式&state&props)_js的state图
- 6【小沐学Python】Python实现Web服务器(Flask+Vue+node.js,web单页增删改查)_pythonweb实现修改,如何在原内容上修改
- 7创建并使用shell脚本_shell脚本创建文件并写入内容
- 8react diff 原理_react的diff算法原理
- 9一些英文词的标准缩写_duration可以简写为d吗?
- 10java mongodb spring_Java spring数据mongodb:UUID作为mongodb中的实体ID
当前位置: article > 正文
Apple MLX vs Llama.cpp vs Hugging Face Candle Rust 获得本地LLM
作者:小丑西瓜9 | 2024-02-14 20:22:59
赞
踩
Apple MLX vs Llama.cpp vs Hugging Face Candle Rust 获得本地LLM
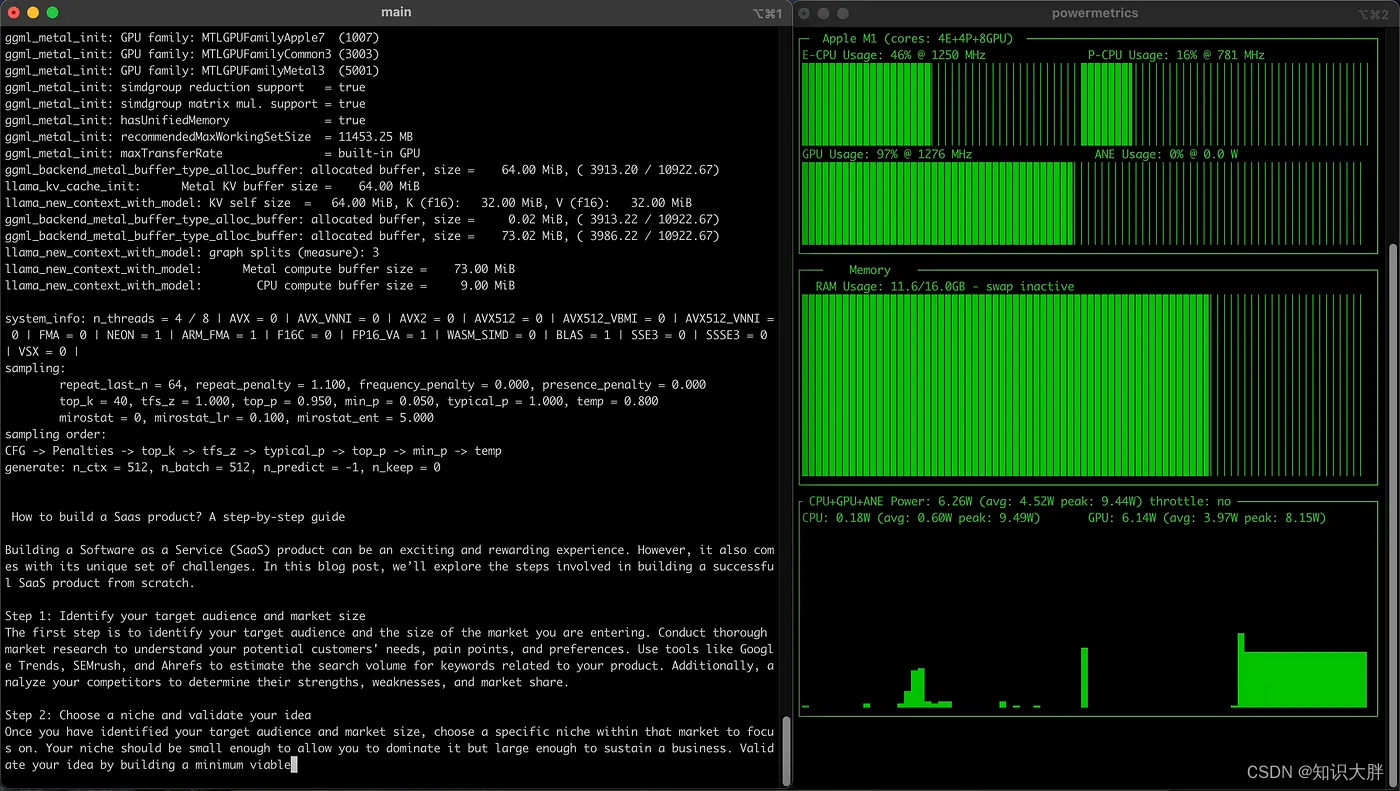
Mistral-7B 和 Phi-2 用于试验跨库最快的推理/生成速度。
介绍
在 NLP 部署方面,推理速度是一个关键因素,尤其是对于那些支持 LLM 的应用程序。随着 Apple M1 芯片等移动架构数量的不断增加,评估法学硕士在这些平台上的性能至关重要。在本文中,我比较了三个流行的 LLM 库 - MLX、Llama.cpp和Hugging Face 的Candle Rust在Apple M1 芯片上的推理/生成速度。旨在帮助开发人员完成任务,他们必须考虑性能、实施的便利性以及与可用工具和框架的兼容性,选择最合适的库在本地计算机上部署 LLM。为了测试推理速度,我使用了两个高级的LLM模型;Microsoft 的 Mistral-7B 和 Phi-2。根据结果,我们为想要提高 LLM 性能的开发人员提供了一些建议,特别是针对 Apple M1 芯片的性能
安装说明
我不会深入讨论安装过程的细节,但每个库的起点已在下面讨论。
骆驼.cpp
主要目标llama.cpp是在 MacBook 上使用 4 位整数量化运行 LLaMA 模型。该库支持除 Llama 之外的多种模型。以下是开始使用Llama.cpp的步骤
获取代码
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
- 1
- 2
在 MacOS 上使用 Make 进行构建
您可以根据您的要求选择多种构建方法(
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/81392
推荐阅读
相关标签

