
- 1【云计算】混合云分类
- 2ESP32使用MicroPython和MicroWebSrv2搭建网站
- 3Windows下Github配置ssh公钥(演示时所用系统为Windows11)_windows ssh key
- 4使用IDEA创建maven工程一定要注意版本的对应_intellij idea 2018.2.8 对应maven版本
- 5python pip实在安装不上包解决方案:如何下载whl文件到本地手动安装_python whl下载
- 6python数据挖掘课程设计,利用Python进行机器学习和数据挖掘概述
- 7navicat64位和ql\sql64位连接oracle11g, 不安装oracle客户端,缺少oci.dll_nivact连oracle需要装客户端吗?
- 8基于SpringBoot的大学生心理健康管理系统的设计与实现
- 9如何在python代码中使用HTTP代理IP_python ip代理
- 10Springboot集成 Spring AI ,深度学习下的与时俱进_springboot ai
Elasticsearch中的语义检索_elastic search 基于语义的查询
赞
踩

一、传统检索的背景痛点
和传统的基于关键词的匹配方式不同,语义检索,利用大模型,将文本内容映射到神经网络空间,最终记忆token做检索。
例如想要搜索中国首都,例如数据集中,只有一篇文章在描述北京,恰好在文章中并没有提到中国首都这四个字。利用传统的关键词匹配技术,搜索“中国首都”,是绝对无法将数据召回的,因为这篇文章中不不包含中国首都这四个字。如果加上语义理解,我们都知道中国首都其实就是北京。其实搜索北京应该也是可以搜索到的。在语义检索下,上述的描述北京的文章,大概率可以别召回。
传统的关键词匹配技术,有很大的弊端,处理上述的问题,在相关性分数计算中,其实也是用的BM25算法,此算法虽然在大多数领域都适用,但是它是基于词频和逆文档率计算的分数,它的效果在我看来也就只有80分,但是想要适用Elasticsearch做到90分的召回效果,就比较困难了。上述的搜索“中国首都”就是一个很好的反例。
虽然在传统搜索中,我们利用同义词可以解决问题,那就是把“中国首都”和“北京”建立一个同义词。问题是我们无法穷举所有的同义词。普遍的做法是,人工收集和构建自己领域内同义词。
语义搜索与关键字搜索
语义搜索和关键字搜索之间的区别在于,关键字搜索会返回单词与单词、单词与同义词或单词与相似单词的匹配结果。语义搜索旨在匹配查询中单词的含义。在某些情况下,语义搜索可能不会生成直接的单词匹配结果,但会符合用户的意图。
关键字搜索引擎使用的是查询扩展或简化工具,如同义词或省略词。它们还会使用自然语言处理和理解工具,如允许拼写错误、词汇切分和规范化。另一方面,语义搜索能够通过使用矢量搜索返回与含义相匹配的查询结果。
以“chocolate milk”(巧克力牛奶)为例。 语义搜索引擎会区分“chocolate milk”(巧克力牛奶)和“milk chocolate”(牛奶巧克力)。 尽管查询中的关键字相同,但它们的书写顺序会影响含义。作为人类,我们知道“milk chocolate”(牛奶巧克力)是指各种巧克力,而“chocolate milk”(巧克力牛奶)是巧克力口味的牛奶。
二、语义检索
基于上述的背景,这篇文章给大家带来的是全新的东西——语义检索。顾名思义,可以根据意思去做搜索,而并非是根据关键词做匹配。
语义检索是如何做到的?
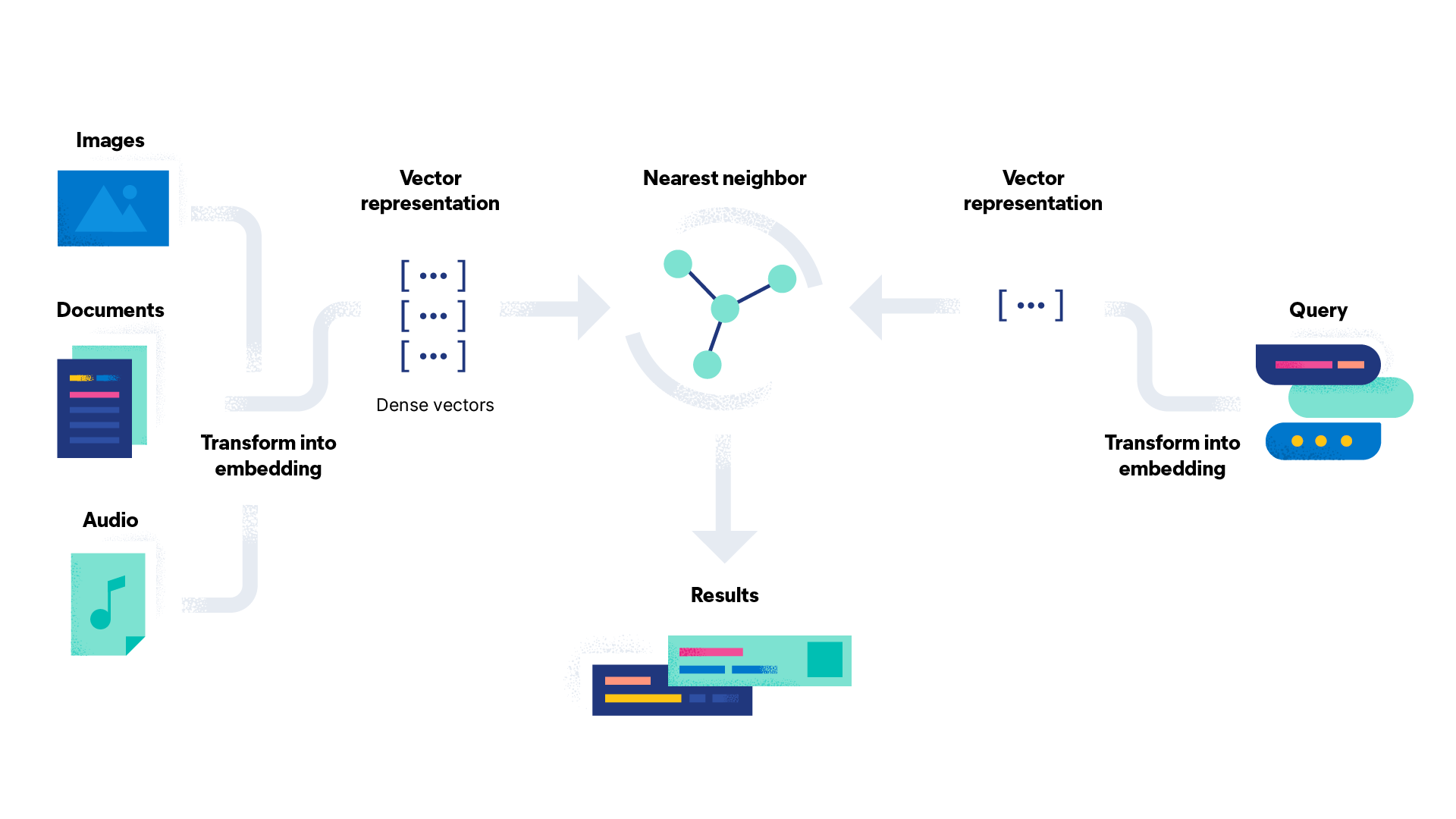
第一步,先是依靠深度学习大模型,将文本内容(这里并不局限于文本,还可以是不同模态的数据,例如图片和声音)到更多维度的空间。通常512维度,甚至是1024维度的空间中。映射的基本原则是,越相近的内容,空间距离越近。这里举个例子,苹果和橘子的空间距离是1,苹果和猫咪的空间距离应该是大于1的,而猫咪和cat的空间距离是小于1的。利用维度空间的距离,来算事物的相似性,或者说问题和答案的相似度。
第二步,将映射后的数据存储在向量数据库(数据在多维度的空间位置,使用多位浮点类型的数组维护的,把它称为向量)。
第三步,将问题使用相同的模型,也映射成向量。
第四步,计算问题和答案的空间距离。这里比较普遍的做法是计算cosin值。即向量检索。
三、Elasticsearch中的语义检索
在上述语义检索中,已经说了语义检索是如何做的。作为优秀的搜索引擎,elasticsearch也在努力的实现上述的这个过程。
1.先来看看es官方对语义检索的定义
语义搜索是一种解读单词和短语含义的搜索引擎技术。语义搜索的结果将返回与查询含义相匹配的内容,而不是与查询字面意思相匹配的内容。
语义搜索是一系列的搜索引擎功能,包括从搜索者的意图及其搜索上下文中理解单词。
这种类型的搜索旨在根据上下文更准确地解读自然语言来提高搜索结果的质量。语义搜索借助 Machine Learning 和人工智能等技术,将搜索意图与语义相匹配,从而实现这一目标。
2.利用 Elasticsearch 进行语义搜索
Elasticsearch 平台配备了 Machine Learning 和 AI 解决方案,包括一个语义搜索模型:Elastic Learned Sparse EncodeR (ELSER)。这个 NLP 模型由 Elastic 训练而成,可在易于部署的工具中实现语义搜索。
Elasticsearch 可以安全地存储您的数据,以实现快速搜索、微调相关性和高效扩展的强大分析功能。Elasticsearch 是 Elastic Stack(一套用于数据采集、扩充、存储、分析和可视化的免费开放工具)的核心组件。
3.语义检索效果如何
以下部分提供有关 ELSER 如何在不同硬件上执行的信息,并将模型性能与 Elasticsearch BM25 和其他强大的基准(例如 Splade 或 OpenAI)进行比较。
硬件测试
使用两个数据集来评估 ELSER 在不同硬件配置中的性能:msmarco-long-light和arguana。

该msmarco-long-light数据集包含平均超过 512 个标记的长文档,这可以深入了解长文档的索引和推理时间的性能影响。这是专门为文档检索设计的“msmarco”数据集的子集(不应与用于段落检索的“msmarco”数据集混淆,后者主要由较短的文本范围组成)。
该arguana数据集是BEIR数据集。它由长查询组成,每个查询平均包含 200 个标记。它可以表示查询速度慢的上限。
下表显示了使用各种硬件配置的 ELSER 基准测试结果。

基准测试
用于评估ELSER排名能力的指标是归一化贴现累积增益(NDCG),它可以处理多个相关文档和细粒度的文档评级。该指标应用于固定大小的检索文档列表,在本例中为前 10 个文档 (NDCG@10)。
下表显示了 ELSER 与使用英语分析器的 Elasticsearch BM25 的性能比较,并按用于评估的 12 个数据集细分。ELSER 取得 10 胜 1 平 1 负,NDCG@10 平均进步 17%。

NDCG@10 用于 BM25 和 ELSER 的 BEIR 数据集 - 值越高越好)
下表将 ELSER 的平均性能与其他一些强基线进行了比较。OpenAI 结果被分开,因为它们使用 BEIR 套件的不同子集。

BEIR 数据集与各种高质量基线的平均 NDCG@10(越高 越好)。OpenAI 选择了不同的子集,该集的 ELSER 结果 单独报告。
要了解有关评估详细信息的更多信息,请参阅 此博客文章。
四、为什么语义搜索很重要?
语义搜索之所以重要,是因为它有助于进行范围更广泛的搜索。由于语义搜索由矢量搜索提供支持,因此它可以提供更直观的搜索体验,根据查询的上下文和搜索意图生成匹配结果。
因为语义搜索算法可持续“学习”各种关键绩效指标 (KPI),例如转化率和跳出率,所以语义搜索有助于提高用户满意度。
更易于客户使用
客户可能记不住专业术语,也想不起来具体的产品名称。借助语义搜索,客户输入模糊的搜索查询,便可获得具体的结果。客户还可以使用文字描述进行搜索,以发现相关名称。例如,您可以通过搜索所知道的歌词来发现歌曲并找到歌名。
因为语义搜索会通过考虑意图和上下文来解读搜索含义,所以客户方面的体验更像是人与人之间的互动。
语义比关键字更强大
通过匹配概念而不是关键字,语义搜索可以生成更准确的结果。通过维度嵌入,一个矢量代表一个单词的概念。“Car”(汽车)不再只与“car”(汽车)或“cars”(轿车)匹配,它还与“driver”(司机)、“insurance”(保险)、“tires”(轮胎)、“electric”(电动)、“hybrid”(混合动力)等匹配,因为这些单词都与“car”(汽车)的矢量相关联。
因此,由矢量搜索提供支持的语义搜索扩展了简单匹配由词元表示的关键字的概念。

