
- 1C语言基础知识理论版(很详细)_c语言的理论
- 2最新 | Ask Me Anything 一种提示(Prompt)语言模型的简单策略(斯坦福大学 & 含源码)_llm prompt
- 3聚类篇——(二)K-means聚类_kmeans聚类问题描述
- 4【C/C++】【学生成绩管理系统】深度剖析
- 5TTS 语音合成技术学习
- 6独立开发变现周刊(第119期):一个自学开发者创建一个月收入12.5万美元的软件公司...
- 7Python_tkinter(按钮,文本框,多行文本组件)_tkinter button边上加字
- 8Redis进阶 - 朝生暮死之Redis过期策略_redis 定时 过期
- 9Git -- reset 详解_git reset 文件
- 10李宏毅2023机器学习作业HW06解析和代码分享
Apache SeaTunnel在VIP 中的使用_seatunnel 翻译
赞
踩
简介
SeaTunnel这款产品的中文翻译个人觉得非常契合产品定位,大多数翻译软件都会翻译成(海底隧道),SeaTunnel作为源 - 目的地的数据传输工具,其性能超越了市面上绝大多数的同步工具,后面会详细介绍性能
功能特点
-
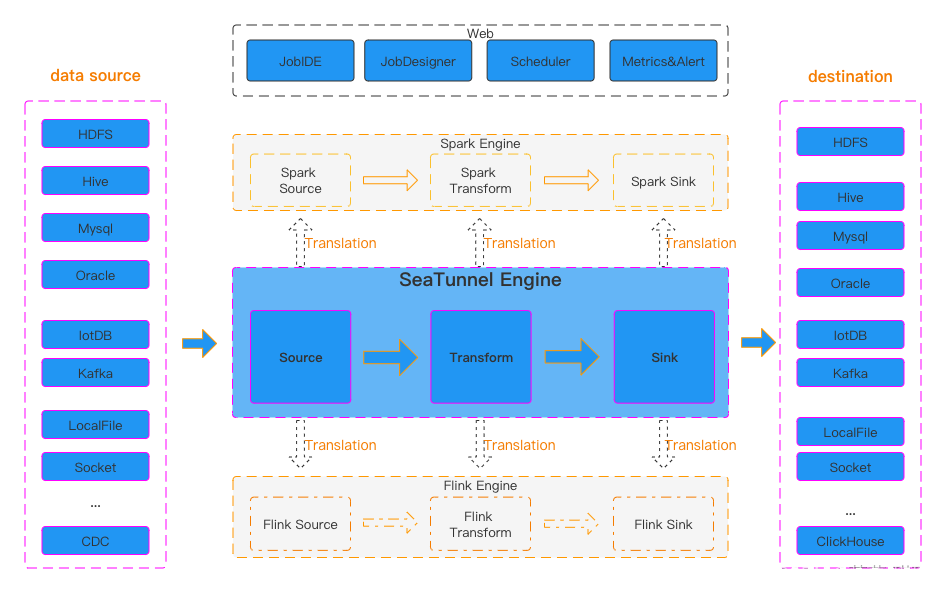
丰富且可扩展的Connector:SeaTunnel提供了不依赖于特定执行引擎的Connector API。基于该API开发的Connector(Source、Transform、Sink)可以运行在很多不同的引擎上,例如目前支持的SeaTunnel Engine、Flink、Spark等。
-
Connector插件:插件式设计让用户可以轻松开发自己的Connector并将其集成到SeaTunnel项目中。目前,SeaTunnel 支持超过 100 个连接器,并且数量正在激增。
-
批流集成:基于SeaTunnel Connector API开发的Connector完美兼容离线同步、实时同步、全量同步、增量同步等场景。它们大大降低了管理数据集成任务的难度。
-
支持分布式快照算法,保证数据一致性。
-
多引擎支持:SeaTunnel默认使用SeaTunnel引擎进行数据同步。SeaTunnel还支持使用Flink或Spark作为Connector的执行引擎,以适应企业现有的技术组件。SeaTunnel 支持 Spark 和 Flink 的多个版本。
-
JDBC复用、数据库日志多表解析:SeaTunnel支持多表或全库同步,解决了过度JDBC连接的问题;支持多表或全库日志读取解析,解决了CDC多表同步场景下需要处理日志重复读取解析的问题。
-
高吞吐量、低延迟:SeaTunnel支持并行读写,提供稳定可靠的高吞吐量、低延迟的数据同步能力。
-
完善的实时监控:SeaTunnel支持数据同步过程中每一步的详细监控信息,让用户轻松了解同步任务读写的数据数量、数据大小、QPS等信息。
-
支持两种作业开发方法:编码和画布设计。SeaTunnel Web 项目提供作业、调度、运行和监控功能的可视化管理。
整体架构
当前稳定版本2.3.4
大厂使用案例
SeaTunnel在 VIP 中的使用
唯品会OLAP架构
底层数据仓库分为离线数据仓库、实时数据仓库、湖库。对于计算引擎,使用 Presto、Kylin 和 Clickhouse。基于OLAP组件,提供SQL数据服务以及唯品会的非SQL独立分析,服务于不同的智能。例如,非 SQL 服务是为 BI 和商业提供更贴近业务的数据分析的服务。多个数据应用被抽象在数据服务之上。

需求
-
Hive 和 Clickhouse 之间有很多工作来实现导入和导出。数据导入导出需求是提高导入导出效率
-
需要使用Clickhouse进行离线OLAP计算加速

痛点
-
Hive表的粒度是5分钟。有没有一个组件可以支持较短的ETL流程,并在五分钟内将ETL结果导入Clickhouse
-
我们要保证数据的质量,数据的准确性需要保证。Hive和Clickhouse中的数据条目数量需要保持一致。如果数据质量出现问题,能否通过重跑等机制修复数据
-
数据导入需要支持的数据类型是否齐全?不同数据库之间的数据类型和一些机制是不同的。我们有 HiperLogLog、BitMap 等数据类型,广泛应用于某个存储引擎。是否能正确传输、识别,并能正常使用。
根据数据业务的痛点,对数据仓库和仓库工具进行了对比和选择。主要比较DataX、SeaTunnel,并在三个选项中编写Spark程序并使用jdbc插入ClickHouse。SeaTunnel和Spark依托唯品会自有的Yarn集群,可以直接实现分布式读写。DataX是非分布式的,Reader和Writer之间的启动过程耗时较长,性能一般。SeaTunnel和Spark对于数据处理的性能可以达到DataX的数倍。超过10亿的数据可以在SeaTunnel和Spark中流畅运行。DataX在数据量大后性能压力很大,处理10亿以上的数据比较困难。在读写插件扩展性方面,SeaTunnel支持多种数据源,支持用户开发插件。SeaTunnel支持将数据导入到Redis中。稳定性方面,由于SeaTunnel和DataX都是自带工具,所以稳定性会更好。Spark 的稳定性方面需要关注代码质量。

数据导入导出
Hive 数据导入 Clickhouse
下图是一个Hive表,三级产品维度表,包括品类产品、维度类别、用户人群信息。该表的主键是一个三级类别ct_third_id,后面的值是两个uid的bitmap,即用户id的bitmap类型。需要将此 Hive 表导入 Clickhouse。

下图显示了SeaTunnel的配置。配置中,env、source、sink必不可少。env部分,图中的例子是Spark的配置。配置包括并发数等,这些参数是可以调整的。源部分是数据源。这里配置了Hive数据源,包括Hive Select语句。Spark运行源配置中的SQL来读取数据。这里支持UDF,用于简单的ETL;Sink部分配置ClickHouse,可以看到output_type=rowbinary,rowbinary是唯品会自研的加速方案;pre_sql和check_sql是自研函数,用于数据校验,后面会详细介绍;clickhouse.socket_timeout和bulk_size可以根据实际情况调整。

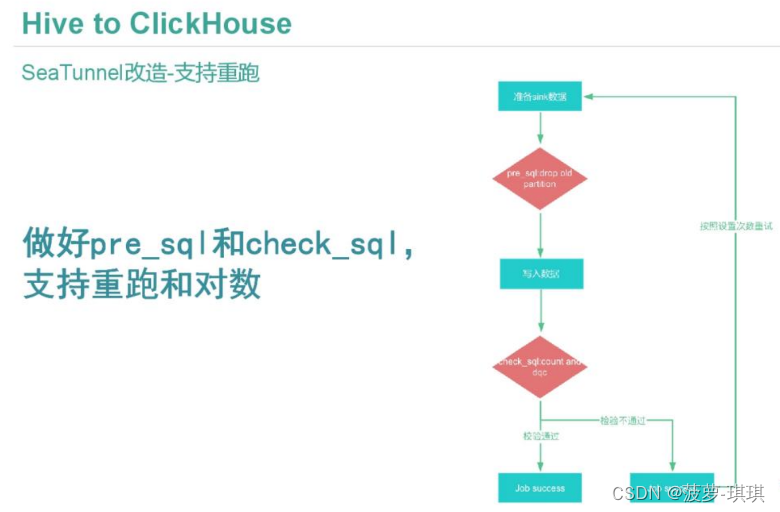
为了更好的契合业务,唯品会对SeaTunnel进行了一些改进。支持pre_sql和check_sql来实现数据重跑和对数。主要流程是数据准备好后执行pre_sql进行预处理,删除Clickhouse中旧的分区数据,存放到一个目录中,失败时恢复分区并重命名。check_sql会进行检查,检查通过后整个流程结束;如果检查失败,则根据配置重新运行,如果重新运行失败,则会提醒相应的负责人。
在SeaTunnel 1.0版本的基础上,唯品会增加了RowBinary进行加速,同时也让Hive中HeperLogLog和BinaryBitmap的二进制文件导入到Clickhouse中变得更加容易。对ClickHouse-jdbc、bulk_size、Hive-source 进行了更改。使用CK-jdbc的扩展api以rowbinary方式向CK写入数据。Bulk_size引入了rowbinary模式下写入CK的控制逻辑。Hive源RDD通过HashPartitioner进行分区,对数据进行打散,防止数据倾斜。还让 SeaTunnel 支持多种类型。为了圈住人群,需要在Clickhouse、Preso、Spark中实现相应的方法。我们在Clickhouse-jdbc中添加了支持Batch功能的Callback、HttpEntity和RowBinaryStream,在Clickhouse-jdbc和Clickhouse-sink代码中添加了位图类型映射,并在Presto和Spark中实现了Clickhouse的Hyperloglog和Bitmap功能的UDF。前面的配置中,clickhouse-sink部分可以指定表名,这里就是写入本地表和分布式表的区别。写入分布式表的性能比写入本地表的性能差,这会给Clickhouse集群带来更大的压力。但在曝光计、流量计、ABTest等场景下,需要两张表进行Join,而且两张表都是数十亿量级。。这时候我们希望Join key落在本机,Join代价更小。我们建表的时候,在Clickhouse的分布式表分发规则中配置了murmurHash64规则,然后直接在Seatunnel的sink中配置分布式表,将写入规则交给Clickhouse,利用分布式表的特性来进行写入。写入本地表会给Clickhouse带来较小的压力,写入的性能会更好。在Seatunnel中,我们根据sink的本地表去Clickhouse的System.cluster表中获取表分布信息以及机器分布主机。然后根据均衡规则写入这些主机。将数据的分布式写入放入Seatunnel中。对于本地表和分布式表的写入,我们未来的改造方向是在Seatunnel中实现一致性哈希,直接按照一定的规则写入,比如Clickhouse,而不依赖Clickhouse本身进行数据分发,改善Clickhouse的CPU负载高的问题。
调度系统整合
SeaTunnel与唯品会数据平台整合,每个公司都有自己的调度系统,比如Beluga、Zeus。 唯品会的调度工具是数方,调度工具集成了数据传输工具。 下面是调度系统的架构图,包括各类数据的进入和退出。

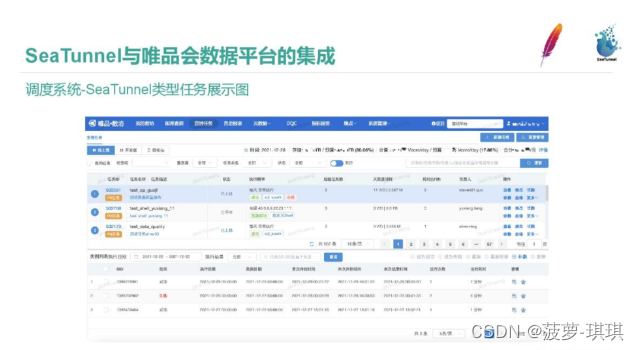
SeaTunnel 任务类型已集成到平台中。 图为书房定时任务截图。 您可以看到所选部分是已配置的 SeaTunnel 任务。 资源信息。 下面显示了历史运行实例信息。
将 SeaTunnel 集成到调度系统中。 数方调度Master会根据任务类型将任务分配给相应的Agent,并根据Agent的负载情况分配到合适的机器上运行。 控制器在前台拉取任务调度配置和信息。 到达后会生成一个SeaTunnel集群,并在类似于k8s pod和cgroup隔离的虚拟环境中执行。 运行结果将通过调度平台的数据质量监控来判断任务是否完成以及操作是否成功,如果失败则重新运行并报警。

SeaTunnel本身是一个基于工具的组件,用于管理和控制数据血缘关系、数据质量、历史记录、高警戒监控、资源分配等。 我们将SeaTunnel集成到平台中,我们可以利用平台来利用SeaTunnel的优势。 SeaTunnel 用于在存款人群中进行处理。 通过管理数据,我们将圈人根据其路径和使用情况划分为不同的人,或者千人千面,标记用户,将某类圈人推送给用户、分析师和供应商。

流量进入Kafka,通过Flink进入仓库,然后通过ETL形成用户标签表。用户标签表生成后,我们使用Presto实现的BitMap方法将数据打入Hive中的宽表中。用户在众包系统页面通过框选条目创建任务,提交至腾群,并生成SQL查询Clickhouse BitMap。Clickhouse的BitMap查询速度非常快。由于其先天的优势,我们需要通过SeaTunnel将Hive的BitMap表导入到Clickhouse中。人群圈完后,我们需要将表落地,形成Clickhouse的分区或者记录,然后将得到的BitMap表通过SeaTunnel存储到Hive中。最后,同步工具会将Hive的BitMap人群结果同步到外部媒体存储库Pika。每天大约有20w人被圈。整个过程中,SeaTunnel负责将Hive中的数据导出到Clickhouse。Clickhouse的ETL过程完成后,SeaTunnel将Clickhouse的数据导出到Hive。为了满足这个需求,我们在Presto和Spark上实现了ClickHouse的Hyperloglog和BitMap功能的UDF;我们还开发了 Seatunnel 接口,使得用户在 ClickHouse 中使用 Bitmap 方式圈出的人群可以通过 Seatunnel 直接写入 Hive 表中,无需中间登陆步骤。用户还可以通过spark调用SeaTunnel接口在Hive中圈出人群或者反转人群位图,这样数据就可以直接传输到ClickHouse结果表中,无需中间登陆

