
- 1Sklearn的Tf-Idf的向量计算_td idf idf可能为负
- 2流水作业调度(dp)_作业调度的dp
- 3Android开发之隐示意图跳转_android 隐式意图 action打开activity
- 4shardingsphere 出现 Cannot support database type ‘MySQL‘_unsupportedoperationexception: cannot support data
- 5软件项目管理第4版课后习题-期末复习题型分册版-带答案_软件项目管理第四版课后答案
- 6数据中台架构
- 7使用Termux安装黑客工具箱---Lazymux_termux黑客命令包
- 8华为鸿蒙开发——Stage/FA模型在ArkTs语言、JS语言 实现页面互转_arkts和js
- 9HarmonyOS开发16:Image组件_ohos image 填充方式
- 10写一条sql,查询数据库中phone字段是否有重复值_sql查下手机号重复记录
【CV论文阅读】【计算机视觉中的Transformer应用综述】(1)
赞
踩

0.论文摘要
摘要——自然语言任务的Transformer model模型的惊人结果引起了视觉社区的兴趣,以研究它们在计算机视觉问题中的应用。在它们的显著优点中,与递归网络例如长短期记忆(LSTM)相比,Transformer能够模拟输入序列元素之间的长依赖性,并支持序列的并行处理。与卷积网络不同,Transformer的设计需要最小的偏差,自然适合作为集函数。此外,Transformer的简单设计允许使用类似的处理块处理多种形式(例如,图像、视频、文本和语音),并表现出对超大容量网络和巨大数据集的出色可扩展性。这些优势已经导致使用Transformer model网络的许多视觉任务取得了令人兴奋的进展。本调查旨在提供计算机视觉学科中Transformer model模型的全面概述。我们首先介绍Transformer成功背后的基本概念,即自我关注、大规模预训练和双向特征编码。然后,我们将介绍Transformer在视觉中的广泛应用,包括流行的识别任务(例如,图像分类、对象检测、动作识别和分割)、生成建模、多模态任务(例如,视觉问题回答、视觉推理和视觉基础)、视频处理(例如,活动识别、视频预测)、低级视觉(例如,图像超分辨率、图像增强和彩色化)和3D分析(例如,点云分类和分割)。我们从建筑设计和实验价值两个方面比较了流行技术各自的优势和局限性。最后,我们对开放的研究方向和未来可能的工作进行了分析。我们希望这一努力将进一步激发社区的兴趣,以解决当前在计算机视觉中应用Transformer model模型的挑战。
1.研究背景
Transformer模型[1]最近在广泛的语言任务中表现出典型的性能,例如文本分类、机器翻译[2]和问题回答。在这些模型中,最受欢迎的包括BERT(来自Transformer的双向编码器表示)[3],GPT(生成式预训练Transformer model)v1-3[4]-[6],RoBERTa(鲁棒优化的BERT预训练)[7]和T5(文本到文本传输Transformer model)[8]。Transformer model模型的深远影响已经变得更加明显,因为它们可以扩展到非常大容量的模型[9],[10]。例如,拥有3.4亿个参数的BERT-large[3]模型明显优于拥有1750亿个参数的GPT-3[6]模型,而最新的专家混合开关Transformer model[10]可扩展到高达1.6万亿个参数!Transformer model网络在自然语言处理(NLP)领域的突破引发了计算机视觉社区对将这些模型用于视觉和多模态学习任务的极大兴趣(图1)。
然而,视觉数据遵循典型的结构(例如,空间和时间一致性),因此需要新颖的网络设计和训练方案。因此,Transformer model模型及其变体已成功用于图像识别[11]、[12]、对象检测[13]、[14]、分割[15]、图像超分辨率[16]、视频理解[17]、[18]、图像生成[19]、文本——图像合成[20]和视觉问题回答[21]、[22],以及其他几个用例[23]-[26]。本调查旨在涵盖计算机视觉领域最近令人兴奋的努力,为感兴趣的读者提供全面的参考。
Transformer model架构基于自我注意机制,该机制学习序列元素之间的关系。与递归处理序列元素且只能关注短期上下文的递归网络相反,Transformer可以关注完整的序列,从而学习长期关系。尽管注意力模型已广泛用于前馈和递归网络[27],[28],但Transformer仅基于注意力机制,并具有针对并行化优化的独特实现(即多头注意力)。这些模型的一个重要特征是它们对高复杂性模型和大规模数据集的可扩展性,例如,与其他一些替代方案相比,如硬注意力[29],硬注意力本质上是随机的,需要蒙特卡罗采样来采样注意力位置。由于与卷积和递归对应物[30]-[32]相比,Transformer假设关于问题结构的先验知识最少,因此它们通常使用大规模(未标记)数据集上的借口任务进行预训练[1]、[3]。这种预训练避免了昂贵的人工注释,从而编码了高度表达的对给定数据集中存在的实体之间的丰富关系进行建模的概括表示。然后,学习到的表征以监督的方式在下游任务上进行微调,以获得有利的结果。
本文提供了为计算机视觉应用开发的Transformer model模型的整体概述。我们开发了网络设计空间的分类法,并强调了现有方法的主要优点和缺点。其他文献综述主要集中在NLP领域[33],[34]或涵盖一般的基于注意力的方法[27],[33]。通过关注视觉Transformer这一新兴领域,我们根据自我注意的内在特征和所研究的任务全面组织了最近的方法。我们首先介绍了Transformer model网络背后的突出概念,然后详细阐述了最近视觉转换器的细节。在可能的情况下,我们将NLP领域[1]中使用的转换器与为视觉问题开发的转换器进行比较,以展示主要的新奇事物和有趣的特定领域见解。最近的方法表明,卷积运算可以完全被基于注意力的Transformer model模块所取代,并且还在单个设计中联合使用,以鼓励两组互补运算之间的共生。本调查最后详细列出了开放的研究问题,并对未来可能的工作进行了展望。
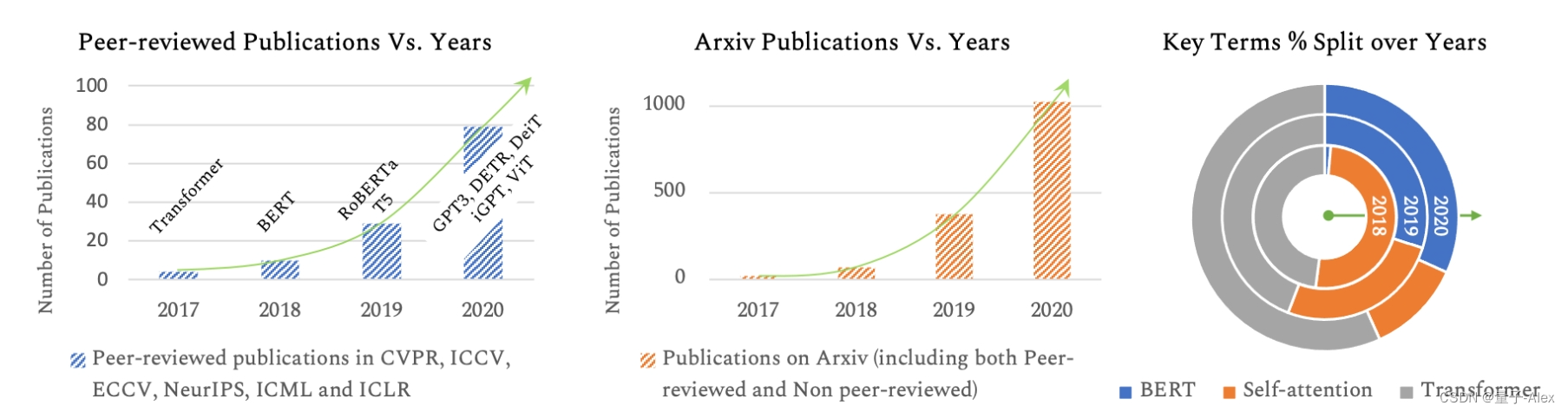
图1:过去几年BERT、自注意力、Transformer等关键词出现在Peer reviewed和arXiv论文标题中的次数统计(在计算机视觉和机器学习中)。这些图在最近的文献中显示出持续的增长。本综述涵盖了计算机视觉领域中Transformer的最新进展。

