
- 1android.os.DeadObjectException的解决办法_android.os.deadobjectexception: transaction failed
- 2java注解实战
- 3C# 读取config文件_c#读取dllconfig
- 4猿创征文|开源监控软件Zabbix6部署实战_zabbix6一键
- 5史上最全因果推断合集-2(阿里大文娱智能营销增益模型)_广告与因果推断
- 6PTA——重排链表_给定一个单链表 l 1 →l 2 → →l n 1 →l n ,请编写程序将链表重新排列为
- 7wr703n刷openwrt智能控制--进入哦penwrt系统_multiple packages (libgcc1 and libgcc1) providing
- 8openwrt 锐捷 单线多拨_openwrt单线多拨
- 9[Intensive Reading]目标检测(object detection)系列(七) R-FCN:位置敏感的Faster R-CNN_位置敏感的目标检测
- 10sudo和apt是什么的缩写_sudo apt是什么意思
rcnn代码实现_Faster-RCNN论文细节原理解读+代码实现gluoncv(MXNet)
赞
踩
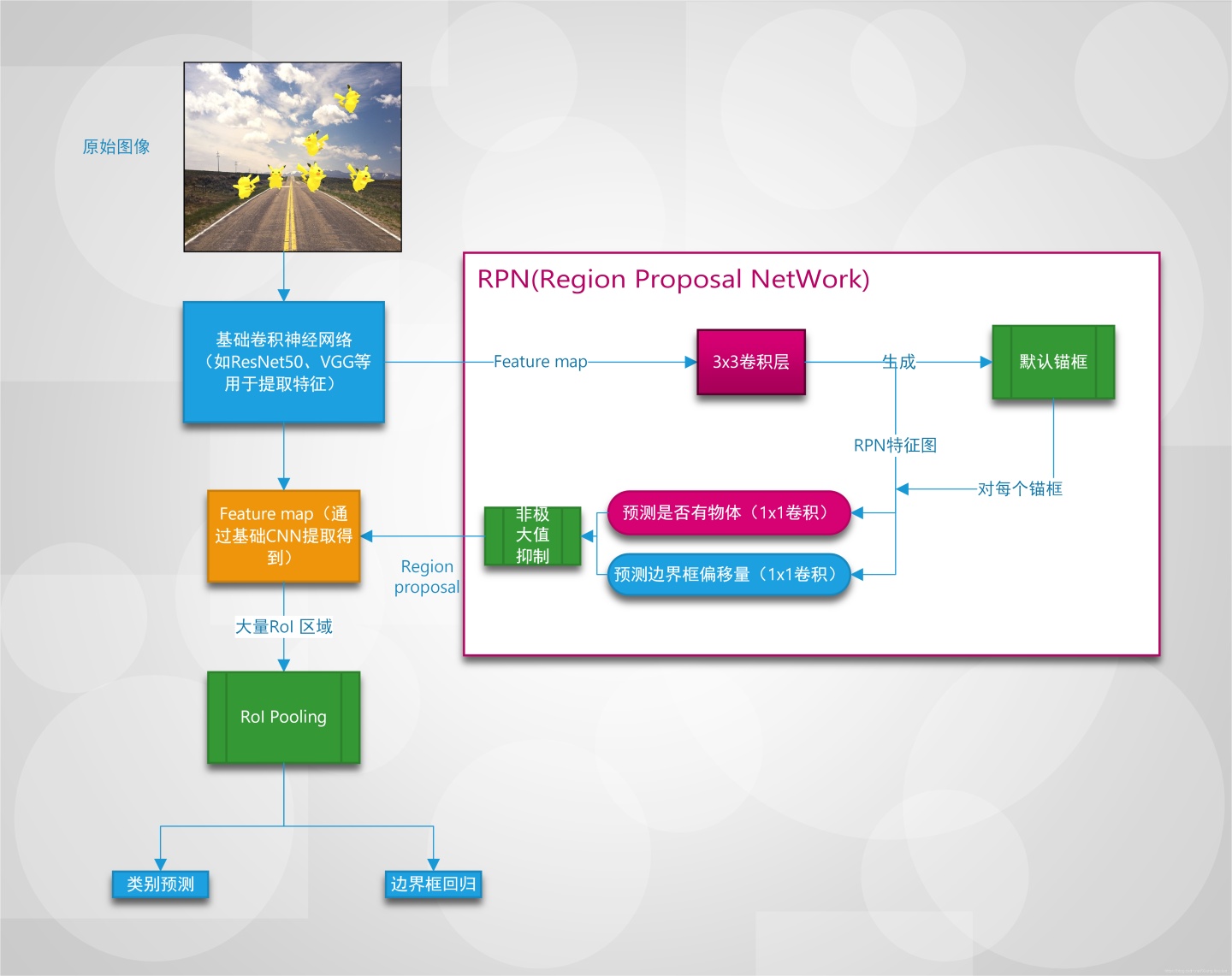
Faster-RCNN开创了基于锚框(anchors)的目标检测框架,并且提出了RPN(Region proposal network),来生成RoI,用来取代之前的selective search方法。Faster-RCNN无论是训练/测试速度,还是物体检测的精度都超过了Fast-RCNN,并且实现了end-to-end训练。
从RCNN到Fast-RCNN再到Faster-RCNN,后者无疑达到了这一系列算法的巅峰,并且后来的YOLO、SSD、Mask-RCNN、RFCN等物体检测框架都是借鉴了Faster-RCNN
Faster-RCNN作为一种two-stage的物体检测框架,流程无疑比SSD这种one-stage物体检测框架要复杂,在阅读论文,以及代码复现的过程中也理解了很多细节,在这里记录一下自己的学习过程和自己的一点体会。
背景介绍
Fast-RCNN通过共享卷积层,极大地提升了整体的运算速度。Selective Search 反倒成为了限制计算效率的瓶颈。Faster-RCNN中使用卷积神经网络取代了Selective Search,这个网络就是Region Proposal Networks(RPN),Faster-RCNN将所有的步骤都包含到一个完整的框架中,真正实现了端对端(end-to-end)的训练。
论文主要贡献
- 提出RPN,实现了端对端的训练
- 提出了基于anchors的物体检测方法
1、网络框架
Faster-RCNN总体流程框图如下(点击原图查看大图),通过这个框图我们比较一下Faster-RCNN和SSD的不同: SSD中每一阶段生成的特征图,每个cell都会生成锚框,并且进行类别+边界框回归。 Faster-RCNN只对basenet提取出的特征图上生成锚框,并且对该锚框进行二分类(背景 or 有物体)+边界框回归,然后会进行NMS移除相似的结果,这样RPN最后会输出一系列region proposal,将这些region proposal区域从feature map中提取出来即为RoI,之后将会通过RoI pooling,进行真正的类别预测(判断属于哪一类)+边界框回归
可以看出Faster-RCNN之所以被称为two-stage,是由于需要有RPN生成region proposal这一步骤。相比来看SSD可以看做是稠密采样,它对所有生成的锚框进行了预测,而没有进行筛选。
RPN中还有一些细节操作,比如说采样比例的设置,如何进行预测,这个在后面的部分会详细说明。
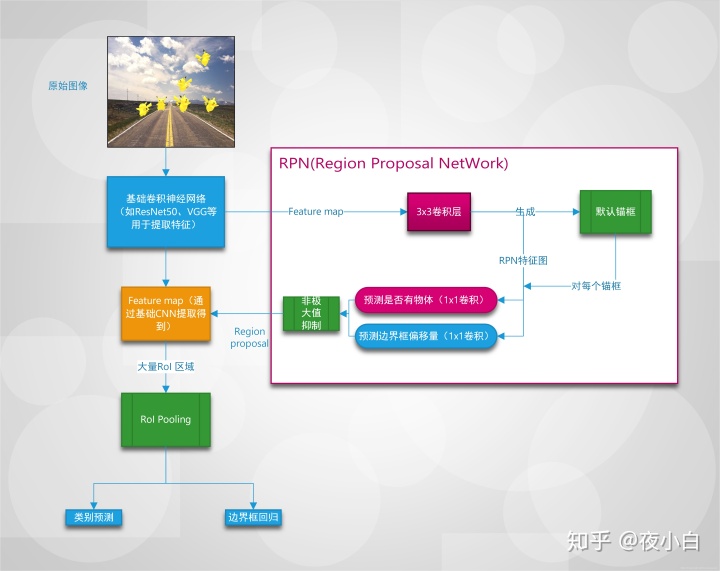
2、RPN(Region Proposal Network)
处理流程
RPN在Faster-RCNN中作用为生成RoI,RPN的处理流程具体如下,一些细节将在之后介绍: 1. 输入为base_net提取出来的feature map,首先在feature map上生成锚框(anchor),其中每个cell有多个锚框。 2. 通过一个conv_3x3,stride=1,padding=1的卷积层,进一步提取特征,输出特征图的大小不变,这里称为rpn_feature。 3. 在rpn_feature上用两个1x1卷积层进行预测输出,分别为每个锚框的二分类分数、每个锚框的坐标偏移量。 4. 利用上面预测的分数以及偏移量,对锚框(anchor)进行非极大值抑制(NMS)操作,最终输出RoI候选区域。
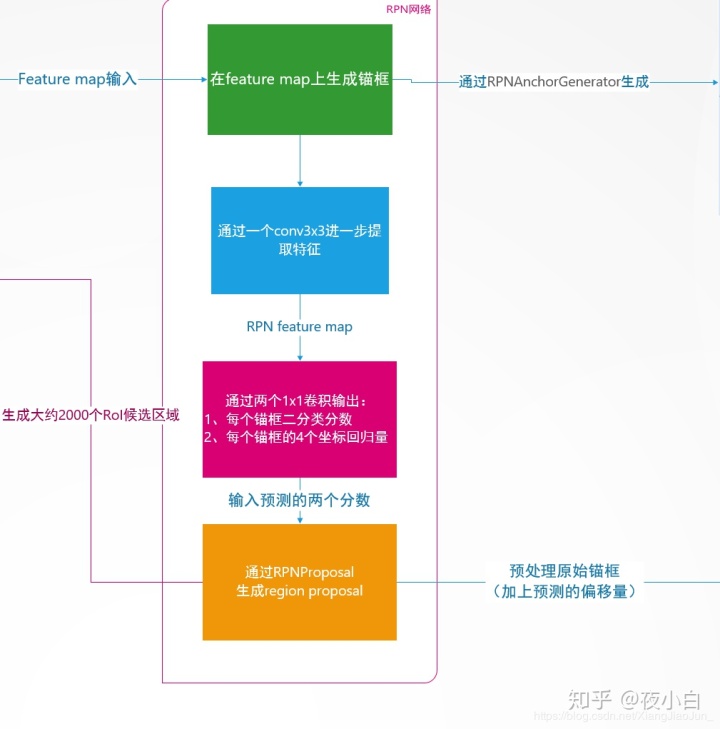
详细步骤及代码
在feature_map上生成锚框
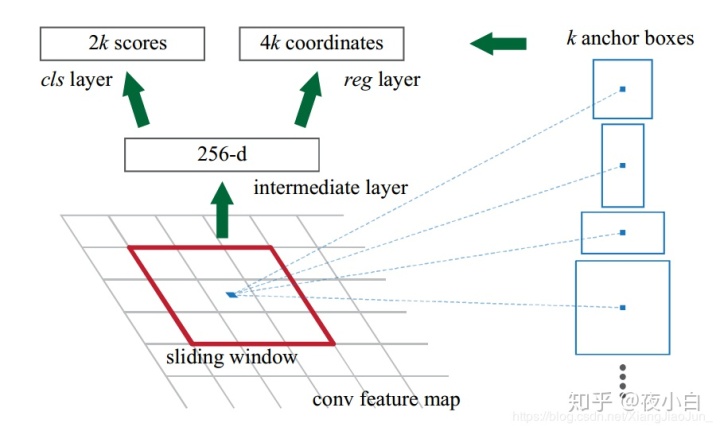
这一步中,会在feature_map每个cell上生成一系列不同大小和宽高比例的锚框。生成锚框的方式如下: 1. 选定一个锚框的基准大小,记为base,比如为16 2. 选定一组宽高比例(aspect ratios),比如为【0.5、1、2】 3. 选定一组大小比例(scales),比如为【16、32、64】 4. 那么每个cell将会生成ratios*scales个锚框,而每个锚框的形状大小的计算公式如下:
MXNet中,生成锚框的类源码如下所示:
- class RPNAnchorGenerator(gluon.Block):
- """
- @输入参数
- stride:int
- 特征图的每个像素感受野大小,通常为原图和特征图尺寸比例
- base_size:int
- 默认大小
- ratios:int
- 宽高比
- scales:int
- 大小比例
- 每个锚框为 width = base_size*size/sqrt(ratio)
- height = base_size*size*sqrt(ratio)
- alloc_size:(int,int)
- 默认的特征图大小(H,W),以后每次生成直接索引切片
- """
-
- def __init__(self, stride, base_size, ratios, scales, alloc_size, **kwargs):
- super(RPNAnchorGenerator, self).__init__(**kwargs)
- if not base_size:
- raise ValueError("Invalid base_size: {}".format(base_size))
- # 防止非法输入
- if not isinstance(ratios, (tuple, list)):
- ratios = [ratios]
- if not isinstance(scales, (tuple, list)):
- scales = [scales]
-
- # 每个像素的锚框数
- self._num_depth = len(ratios) * len(scales)
- # 预生成锚框
- anchors = self._generate_anchors(stride, base_size, ratios, scales, alloc_size)
- self.anchors = self.params.get_constant('anchor_', anchors)
-
- @property
- def num_depth(self):
- return self._num_depth
-
- def _generate_anchors(self, stride, base_size, ratios, scales, alloc_size):
- # 计算中心点坐标
- px, py = (base_size - 1) * 0.5, (base_size - 1) * 0.5
- base_sizes = []
- for r in ratios:
- for s in scales:
- size = base_size * base_size / r
- ws = np.round(np.sqrt(size))
- w = (ws * s - 1) * 0.5
- h = (np.round(ws * r) * s - 1) * 0.5
- base_sizes.append([px - w, py - h, px + w, py + h])
- # 每个像素的锚框
- base_sizes = np.array(base_sizes)
-
- # 下面进行偏移量的生成
- width, height = alloc_size
- offset_x = np.arange(0, width * stride, stride)
- offset_y = np.arange(0, height * stride, stride)
- offset_x, offset_y = np.meshgrid(offset_x, offset_x)
- # 生成(H*W,4)
- offset = np.stack((offset_x.ravel(), offset_y.ravel(),
- offset_x.ravel(), offset_y.ravel()), axis=1)
-
- # 下面广播到每一个anchor中 (1,N,4) + (M,1,4)
- anchors = base_sizes.reshape((1, -1, 4)) + offset.reshape((-1, 1, 4))
- anchors = anchors.reshape((1, 1, width, height, -1)).astype(np.float32)
- return anchors
-
- # 对原始生成的锚框进行切片操作
- def forward(self, x):
- # 切片索引
- anchors = self.anchors.value
- a = nd.slice_like(anchors, x * 0, axes=(2, 3))
- return a.reshape((1, -1, 4))

用conv3x3卷积进一步提取特征图
这一步中就是RPN进一步抽取特征,生成的RPN-feature map提供给之后的类别预测和回归预测。该步骤中使用的是kernel_size=3x3,strides=1,padding=1,Activation='relu'的卷积层,不改变特征图的尺寸,这也是为了之后的1x1卷积层预测时,空间位置能够一一对应,而用通道数来表示预测的类别分数和偏移量。这一步的代码很简单,就是单独的构建了一个3x3 Conv2D的卷积层。
- # 第一个提取特征的3x3卷积
- self.conv1 = nn.Sequential()
- self.conv1.add(nn.Conv2D(channels, kernel_size=3, strides=1, padding&#

