
- 1Nginx做静态文件服务器,如何进行权限验证呢?_nginx 访问文件添加验证
- 2计算机视觉任务不能或缺的库opencv简单介绍和概述
- 3独家:小程序再添新能力,QQ空间5.62亿月活用户福利来袭
- 4修复Microsoft Edge上“无法到达此页面”错误的5种方法_edge无法访问ip地址
- 5基于Faster-RCNN的目标检测【跑通源码】_faster rcnn权重下载
- 6adb命令中“adb.exe: more than one device/emulator”错误解决
- 7人工智能概述
- 8混淆梯度(Obfuscated Gradients Give a False Sense of Security Circumventing Defense)_梯度混淆
- 9修复在 k8s runtime 为 containerd 时,端口转发不稳定问题_unable to do port forwarding: socat not found
- 10图像去模糊代码 python_python
图灵奖获得者Yann LeCun:未来几十年AI研究的最大挑战是「预测世界模型」
赞
踩

来源:机器学习研究组订阅
LeCun 认为,构造自主 AI 需要预测世界模型,而世界模型必须能够执行多模态预测,对应的解决方案是一种叫做分层 JEPA(联合嵌入预测架构)的架构。该架构可以通过堆叠的方式进行更抽象、更长期的预测。LeCun 和 Meta AI 希望分层 JEPA 可以通过观看视频和与环境交互来了解世界是如何运行的。
深度学习大规模应用之后,人们一直期待真正的通用人工智能出现,能够带来进一步的技术突破。
对此,Meta 首席科学家、图灵奖获得者 Yann LeCun 最近提出了一种新思路:他认为让算法预测世界内在运行规律的「世界模型」将是关键。他的思考引发了人们的关注。
在本周的一次线上活动中,LeCun 用一个小时的时间介绍了自助人工智能的新思路,并提出联合嵌入预测架构(JEPA)是未来的发展方向。

尽管 AI 研究最近取得了显著进展,但我们离创造出像人一样思考和学习的机器还有很长的路要走。正如 Yann LeCun 所说,一个从没有开过车的青少年可以在 20 小时之内学会驾驶,但最好的自动驾驶系统却需要数百万或数十亿的标记数据,或在虚拟环境中进行数百万次强化学习试验。即使费这么大力,它们也无法获得像人类一样可靠的驾驶能力。
怎样才能打造出接近人类水平的 AI?仅靠更多的数据和更大的模型能解决吗?
在 Meta AI 近期举办的 Inside the Lab event 中,LeCun 勾勒出了构建人类水平 AI 的另一种愿景。他指出,学习「世界模型」(即世界如何运作的内部模型)的能力可能是关键。
原视频链接:https://www.youtube.com/watch?v=DokLw1tILlw
PPT 链接:https://drive.google.com/file/d/1Txb9ykr03Lda-oTLXbnlQsEe46V8mGzi/view
Yann LeCun 的观点与 Kanai 等人提出的意识信息生成理论非常一致——智能源于能够生成世界复杂表示的能力(包括反事实),不过也有学者对此持消极态度。
卡耐基梅隆大学教授,前苹果 AI 研究主管 Russ Salakhutdinov 对此评价道:Josh Tenenbaum 和其他很多研究者在十年前已经开始研究世界模型,当时我在他的实验室做博士后。因此,当 Facebook 说他们正在研究基于世界模型的 AI 新愿景时,我觉得这听起来有点好笑。
LeCun 提出的方法究竟能否成为通向通用人工智能的道路?让我们结合 Meta AI 前几天的博客来了解一下 LeCun 的想法。
可以建模世界如何运行的 AI
LeCun 说,人和动物似乎能够通过观察和难以理解的少量互动,以一种独立于任务的、无监督的方式,学习大量关于世界如何运行的背景知识。可以假设,这些积累起来的知识可能构成了常识的基础。常识可以被看作是世界模型的集合,可以告诉我们什么是大概率会发生的,什么是可能发生的,以及什么是不可能发生的。

这使得人类即使身处不熟悉的环境也能有效地制定计划。例如,文章开头提到的那个青少年可能以前没有在雪地上开过车,但他知道雪地开车容易打滑,不能开得太猛。
常识不仅能让动物预测未来的结果,还能填补时间或空间上缺失的信息。当司机听到附近金属碰撞的声音时,他立即就能知道发生了事故,即使没有看到涉事车辆。
人类、动物和智能系统使用世界模型的观点可以追溯到几十年前的心理学以及控制和机器人等工程领域。LeCun 提出,当今 AI 面临的最重要的挑战之一是设计学习范式和架构,让机器以一种自监督的方式学习世界模型,然后利用这些模型进行预测、推理和规划。他的大纲融合了各种学科的观点,如认知科学、系统神经科学、最佳控制、强化学习和「传统」AI,并将它们与机器学习中的新概念相结合,如自监督学习、联合嵌入架构。
一种自主智能体系架构的提出
LeCun 提出了一个由六个独立模块组成的架构。假设每个模块都是可微的,因为它可以很容易地计算某个目标函数相对于自己的输入的梯度估计,并将梯度信息传播到上游模块。
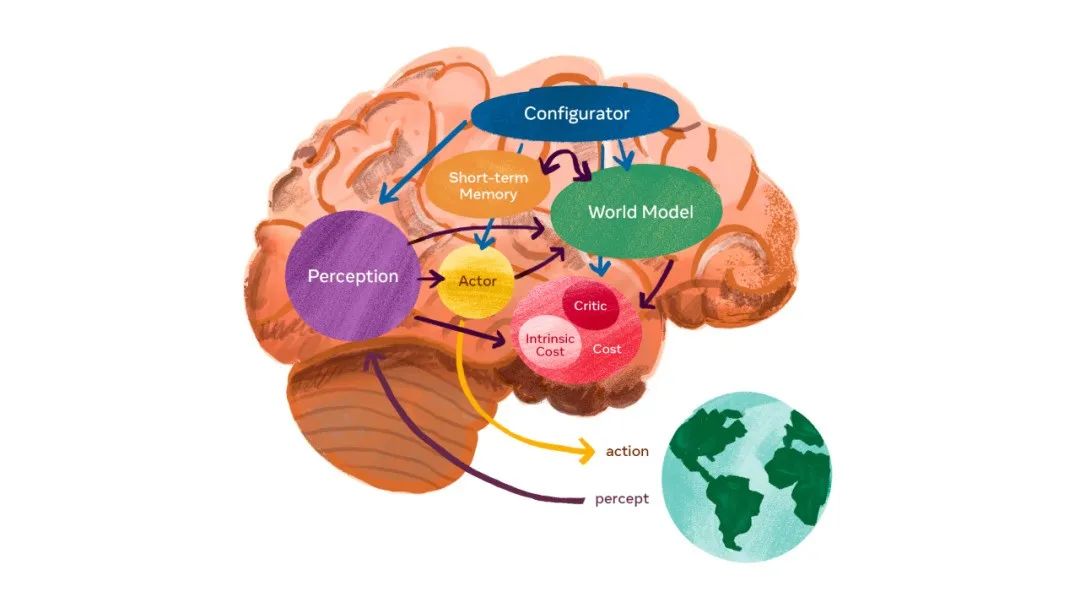
上图是一种自主智能系统的架构,配置器(Configurator)从其他模块获得输入(图中省略了这些箭头)。
配置器(Configurator)模块负责执行控制(executive control):给定要执行的任务,可以通过调整这些模块的参数来预先配置感知模块(perception module)、世界模型(world model)、成本(cost)和当前任务的 actor。
感知模块(Perception module)接收来自传感器的信号并估计当前世界的状态,对于给定的任务,只有一小部分感知到的世界状态是相关和有用的。配置器模块启动感知系统,从感知中提取相关信息,完成手头的任务。
世界模型(World model)构成了架构中最复杂的部分。它的作用是双重的:(1)估计感知未提供的关于世界状态的缺失信息;(2)预测合理的未来世界状态。
世界模型可以预测世界的自然进化,或预测由 actor 模块提出的一系列动作所导致的未来世界状态。世界模型是一种与当前任务相关的世界部分的模拟器。由于世界充满了不确定性,模型必须能够代表多种可能的预测。比如接近十字路口的司机可能会减速,以防另一辆接近十字路口的车没有在停车标志处停下来。
成本模块(Cost module)计算单个标量的输出,该输出预测智能体的不适(discomfort)程度。它由两个子模块组成:内在成本(intrinsic cost)是硬连接、不可变的(不可训练的),并计算直接的不适(比如对智能体的损害、违反硬编码的行为约束等);批判(critic)是可训练的模块,预测内在成本的未来值。智能体的最终目标是最小化长期的内在成本。
「这就是基本的行为驱动力和内在动机所在,」LeCun 表示。因此它将考虑到内在成本,比如没有浪费能源,以及手头任务的具体成本。因为成本模块是可微的,所以成本梯度可以通过其他模块反向传播,用于规划、推理和学习。
actor 模块计算动作序列的提议。「actor 可以找到一个最优的动作序列,最小化预估的未来成本,并以最优序列输出第一个动作,这种方式类似于传统的最优控制。」LeCun 说。
短期记忆模块(Short-term memory module)跟踪当前和预测的世界状态以及相关成本。
世界模型架构和自监督训练
该架构的核心是预测世界模型。构建它的一个关键挑战是如何使它能够表示多个看似合理的预测。现实世界并不是完全可以预测的:特定情况的演变有多种可能的方式,并且情况的许多细节与手头的任务无关。我可能需要预测开车时周围的汽车会有哪些动作,而不需要思考道路附近树木中单个叶子的详细位置。世界模型到底应该如何学习世界的抽象表示,从而保留重要细节,忽略不相关的细节,并且可以在抽象表示的空间中进行预测呢?
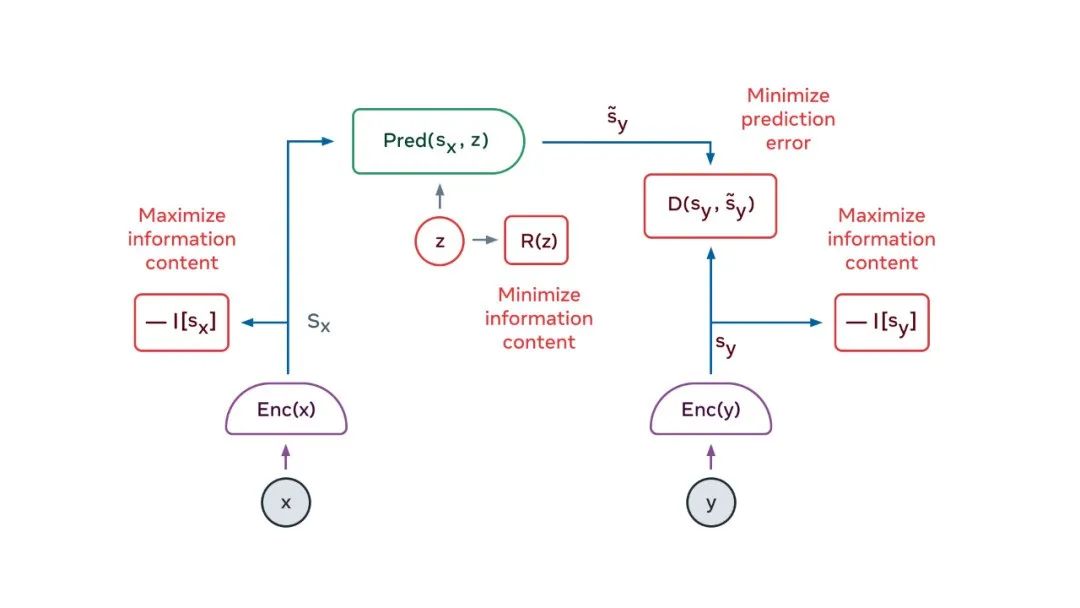
解决方案的一个关键要素是联合嵌入预测架构(JEPA)。JEPA 捕获两个输入 x 和 y 之间的依赖关系。例如 x 可以是一段视频,y 可以是视频的下一段。输入 x 和 y 被馈送到可训练的编码器,这些编码器提取它们的抽象表示,即 s_x 和 s_y。训练预测器模块以从 s_x 预测 s_y。预测器可以使用潜变量 z 来表示 s_y 中存在但 s_x 中不存在的信息。
JEPA 以两种方式处理预测中的不确定性:(1)编码器可能会选择丢弃有关 y 的难以预测的信息,(2)当潜变量 z 在一个集合范围内变化时,预测将在一组看似合理的预测结果范围内变化。
那么 JEPA 是如何训练的呢?之前,唯一的方法是使用对比方法,包括显示相匹配的 x 和 y 的示例,以及许多 x 和不匹配的 y 的示例。但是当表示(representation)是高维的时,这是相当不切实际的。过去两年出现了另一种训练策略:正则化方法。当应用于 JEPA 时,该方法使用四个标准:
使 x 的表示最大限度地提供关于 x 的信息
使 y 的表示最大限度地提供关于 y 的信息
使得从 x 的表示中最大限度地预测 y 的表示成为可能
让预测器使用来自潜变量的、尽可能少的信息来表示预测中的不确定性。
这些标准可以以各种方式转化为可微的成本函数。一种方法是 VICReg(方差 - 不变性 - 协方差正则化)方法。在 VICReg 中,x 和 y 的表示的信息内容通过将它们的分量的方差保持在阈值之上,并使这些分量尽可能地相互独立来实现最大化。同时,该模型试图使 y 的表示可以从 x 的表示中预测。此外,潜变量信息内容的最小化是通过使其离散、低维、稀疏或有噪声来实现的。
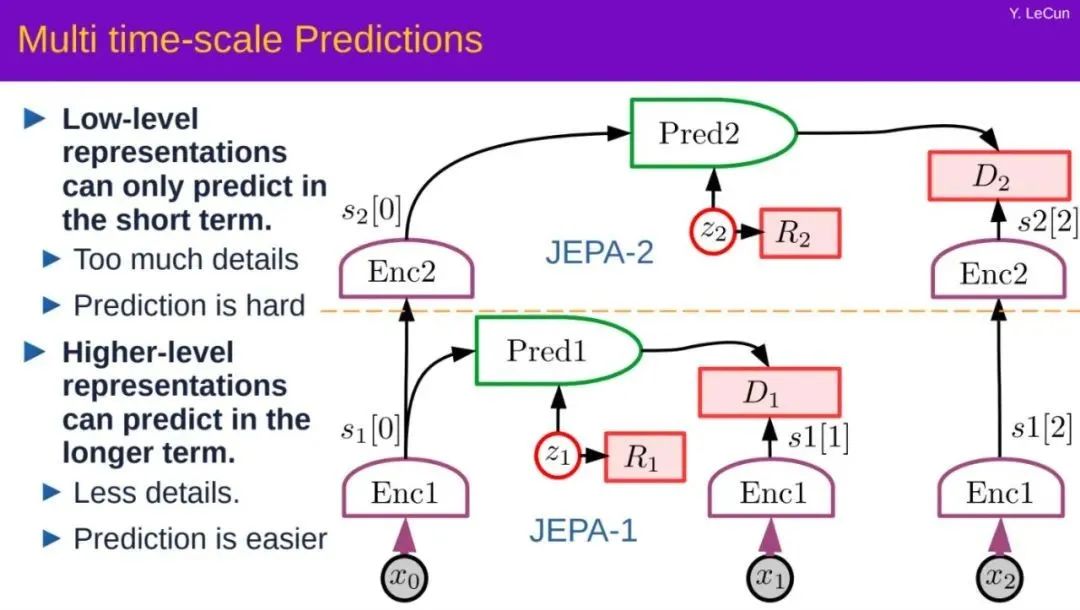
JEPA 的精妙之处在于它自然地产生了输入的充满信息量的抽象表示,消除了不相关的细节,这些表示可以用来执行预测。这使得 JEPA 可以相互堆叠,以便学习具有更高抽象级别的表示,可以执行长期预测。
例如,一个场景可以在高层次上描述为「厨师正在制作可丽饼」。可以预测的是,厨师会去取面粉、牛奶和鸡蛋,把材料混合,把面糊舀进锅里,用油炸面糊,翻转可丽饼并重复上述过程。
在较低的层次上,倾倒面糊(pouring a ladle)又可以分解为舀面糊(scooping some batter )和将其倒在平底锅上(spreading it around the pan)。这些过程可以一直分解下去,具体到厨师手上每一毫秒的精确轨迹。在这种低层次的手部轨迹预测上,我们的世界模型只能在较短的时间范围内给出准确的预测。但在更高的抽象层次上,它可以做出长期预测。
分层 JEPA 可用于在多个抽象层次和多个时间尺度上执行预测。训练分层 JEPA 主要通过被动观察,很少借助交互。
婴儿在出生后的头几个月主要通过观察来了解世界是如何运行的。她了解到世界是三维的;有些物体在其他物体的前面;当一个物体被遮挡时,它仍然存在。最终,在大约 9 个月大的时候,婴儿学会了直观物理,例如不受支撑的物体会因重力而落下。
LeCun 和 Meta AI 希望分层 JEPA 可以通过观看视频和与环境交互来了解世界是如何运行的。通过训练自己预测视频中会发生什么,JEPA 将产生世界的分层表示。通过做出一些动作并观察结果,世界模型将学会预测其动作的后果,这将使其能够进行推理和规划。
感知 - 动作 episode
通过将分层 JEPA 训练为世界模型,智能体能够执行复杂动作的分层规划,将复杂任务分解为一系列不太复杂和不太抽象的子任务,直到分解为效应器上的低层次动作。
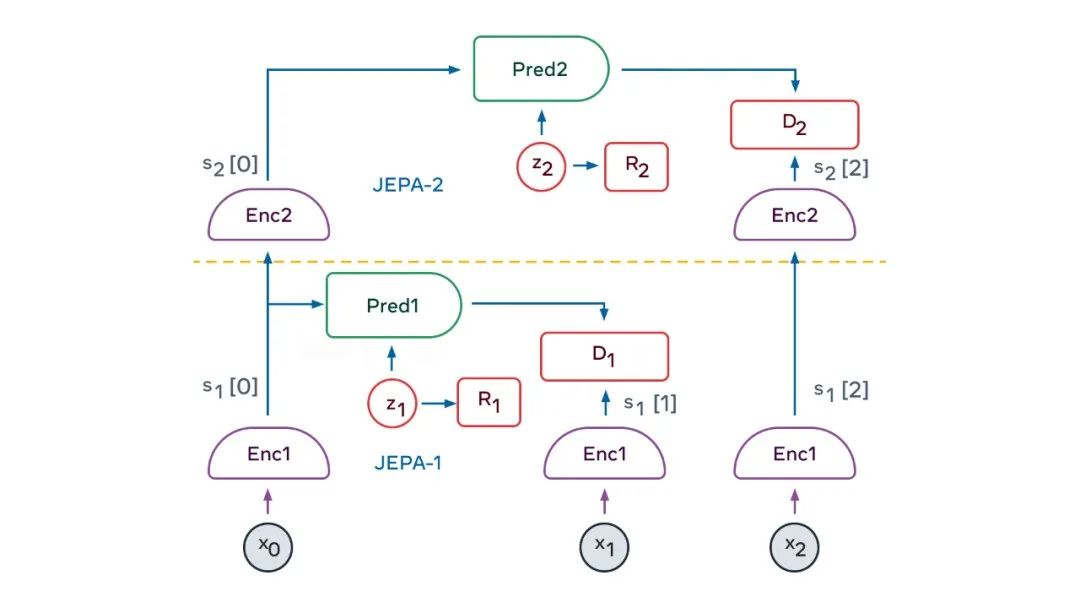
下图是一个典型的感知 - 动作 episode。该图说明了两层层次结构的情况。
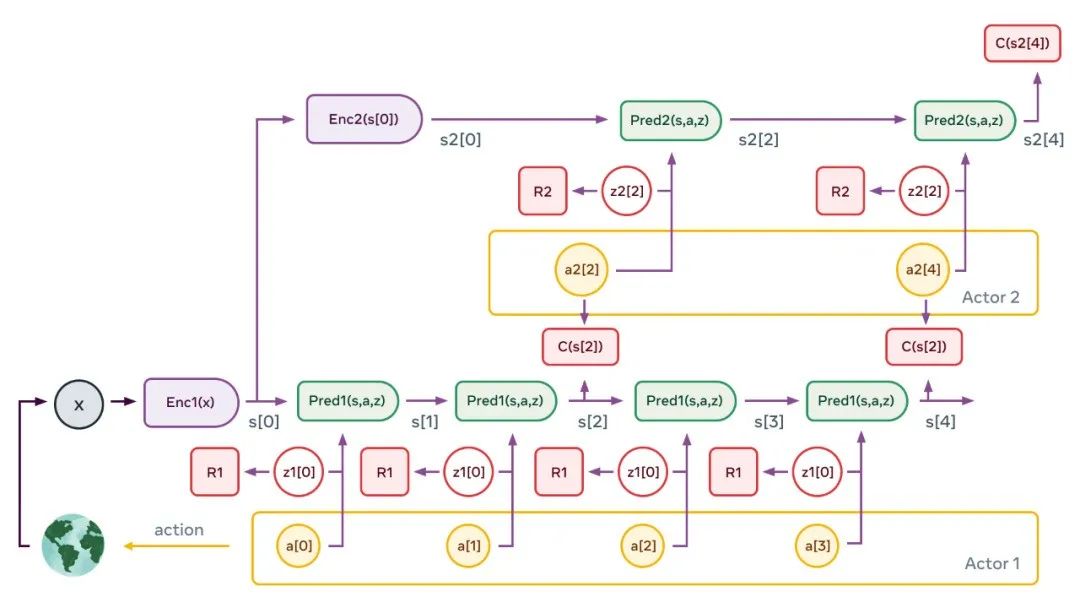
感知模块提取世界状态的分层表征(对应图中 s1[0]=Enc1(x) , s2[0]=Enc2(s[0]))。然后,在给定第二层 actor 提出的一系列抽象动作的情况下,多次应用第二层预测器来预测未来状态。actor 优化第二层的动作序列以最小化总成本(图中的 C(s2 [4]))。
这个过程类似于最优控制中的模型预测控制(Model-Predictive Control)。对第二层潜变量的多个 drawing 重复该过程,可能会产生不同的高级场景。由此产生的高级动作虽然不能构成真正的动作,但是定义了低层次状态序列必须满足的约束。
这也构成了子目标。整个过程在较低的层次重复:运行低层次预测器,优化低层动作序列以最小化来自上一层的中间成本,并对低层潜在变量的多个 drawing 重复该过程。一旦该过程完成,智能体将第一个低层次动作输出到效应器,就可以重复整个 episode。
如果能成功构建这样一个模型,那么所有模块都将是可微的,因此整个动作优化过程可以使用基于梯度的方法来执行。
更接近人类智能水平的 AI
LeCun 的愿景中还存在许多艰巨的挑战。其中最有趣和最困难的挑战之一是实例化(instantiate)世界模型架构和训练过程的细节。一定程度上,训练世界模型将是未来几十年人工智能取得实际进展面临的主要挑战。
然而,世界模型架构的许多方面仍有待定义,包括如何精确地训练 critic、如何构建和训练配置器(configurator)、如何使用短期记忆来跟踪世界状态和存储历史状态等等。
创造像人类一样有效学习和理解的机器是一项长期的科研工作,并且不能保证一定会成功。但基础研究必将继续加深机器对世界的理解,推进整个人工智能领域的发展。
参考内容:
https://ai.facebook.com/blog/yann-lecun-advances-in-ai-research/
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”


