- 1(vue)在ajax获取数据时使用loading组件不起作用_el-button loading效果不显示
- 2windows下查找mysql配置文件my.ini_winmysqladmin.exe my.ini
- 3微信小程序之导航栏样式修改、自定义导航栏及封装_微信小程序状态栏
- 4node.js的国内源
- 5解决 Python 中的 “No module named ‘pyLDAvis.gensim’” 错误
- 6HarmonyOS 鸿蒙应用开发( 八、线程模型及线程间通信 Emitter、Worker和TaskPool介绍)_鸿蒙线程taskpool
- 7cuda runtime error (2) : out of memory解决_program hit out of memory (error 2) on cuda api ca
- 8Android Studio 知识汇总
- 9Ubuntu开启root登录和远程登录_ubuntu开启root远程登录
- 10Mac ADB环境搭建+Android adb forward转发TCP端口连接数试验_夜神模拟器adb端口转发
悟道3.0全面开源!LeCun VS Max 智源大会最新演讲_悟道开源网址
赞
踩
作者 | 小戏
2023 年智源大会如期召开!
这场汇集了 Geoffery Hinton、Yann LeCun、姚期智、Joseph Sifakis、Sam Altman、Russell 等一众几乎是 AI 领域学界业界“半壁江山”的大佬们的学术盛会,聚焦 AI 领域的前沿问题,讨论尤其是大模型出现后 AI 新时代的新风向。

纵观整个开幕式的议程设置,在致辞环节结束后,首先由智源研究院院长黄铁军带来了智源研究院近期进展的报告,报告开宗明义,实现所谓真正的人工智能目前有三条进路,分别是当下 GPT 为代表的自监督深度学习到信息模型的进路,以 DQN 为代表的强化学习到具身模型的进路以及基于第一性原理的生命科学脑科学进路

大模型研究测试传送门
GPT-4能力研究传送门(遇浏览器警告点高级/继续访问即可):
https://gpt4test.com
基于这三条进路按图索骥,黄铁军院长介绍了智源近期的开源工作,其中最重要的当属悟道3.0全面开源,其中比较有趣的工作有:
- 悟道·天鹰(Aquila)”语言大模型系列:首个支持中英双语知识、商用许可,符合国内数据要求的开源大模型;
- “天秤(FlagEval)”大语言评测体系及开放平台:通过能力-任务-指标三维评价体系,构建了一个 30+ 种能力 x 5 种任务 x 4大类指标超过 600+ 维度的全面测评体系;
- FlagOpen飞智大模型技术开源体系:集成了一个完整的大模型算法技术仓库,从零开始也能 Follow 大模型的基础工作;
- 天演-生命模拟工程:通过脑模拟实现生物启发的通用人工智能模型。

当然,整个上午场最吸引眼球的报告,肯定是图灵奖得主,三巨头之一的 Yann LeCun 与未来生命研究所创始人,MIT 教授 Max Tegmark 的演讲,而颇为戏剧性的是两位的观点又恰巧十分之对立,Yann LeCun 教授观点直入主题:“Machine Learning Sucks”,意指当前大模型的技术路径或许根本无法实现对人类有威胁的真正的人工智能,而 Max Tegmark 教授则反复强调“Keep AI Under Control”,如果 AI 失控则会导致“Lights Out for All of Us”,不谈技术进路如果回顾历史,人类的出现导致了智能更低的长毛象的灭绝,面对日新月异发展速度可怕的人工智能体,Keep AI Under Control 异常有必要。

人在法国的 Yann LeCun 教授在法国那边凌晨四点与会场嘉宾与观众直播连线,开头就指出了对比人类或动物智能,当前大模型智能基础监督学习与强化学习的主要问题:
- 有监督学习:要求太多标注数据,人类智能或者动物智能在成长环境中必然不是依赖如此规模的标注工程而形成的智能;
- 强化学习:强化学习要求太多完全不合理的“试错”,真正的智能似乎学习的更快也更鲁棒;
这就造成了当前大模型的技术架构,即自回归大规模语言模型,往往会出现“脆弱”,“不会计划”,“不合理的输出”等等许多问题,表现在应用中将是“事实错误”,“逻辑错误”,“不一致”……等等问题。
而 Yann LeCun 教授指出,大模型为什么会这样?因为它们事实上就根本没有理解现实世界,很精辟的总结在于“ We are easily fooled by their fluency. But they don’t kown how the world works”
归根结底, Yann LeCun 教授认为当前 AI 只靠语言模型必然走不远,那么未来是什么呢?

答案就是 Yann LeCun 教授最近反复强调的“世界模型”,教授构想的可以支持推理与规划的真正的“智能体”应该包含以上六个组件,分别是配置器(Configurator)模块,感知模块(Perception module),世界模型(World model),成本模块(Cost module),Actor 模块,短期记忆模块(Short-term memory module)。
而其中最重要的部件,就是世界模型,而如何训练一个不是用于简单分类回归,而是表征多种预测的世界模型呢?Yann LeCun 教授提出了联合嵌入预测架构(Joint-Embedding Predictive Architecture,JEPA),并对架构做出了细致的阐述。这些思想被总结发表在《A path towards autonomous machine intelligence》之中,我们之前也有过报道(传送门:LeCun最新演讲,痛批GPT类模型没前途,称“世界模型”是正途!)

另一边,Max TegMark 教授在 Keep AI Under Control 的大观点下,着重叙述了我们应当如何 Keep AI Under Control,教授认为,核心将在于“Align AI 以及 Multiscale Alignment”,即其核心思想在于,如何使得 AI 与人类的价值观、想法保持一致,并且这种一致不是个体化的一致,而是群体性的、广泛性的一致。那么继续深入,如何“对齐”,如何保持多尺度大规模的“对齐”?答案将是或许也只能是对“可解释性”领域的研究。教授着重介绍了几篇工作:
以 Quanta 为概念基础为大模型 Scale Law 与涌现能力做解释的《The Quantization Model of Neural Scaling》

研究 Transformer 中事实知识存储修改与编辑的《Locating and Editing Factual Associations in GPT》,这篇我们做了解读(传送门:MIT发现语言模型内的事实知识可被修改??)

研究模型预测能力本质的《Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task》等等一系列真正相关模型黑盒内部构造的论文。

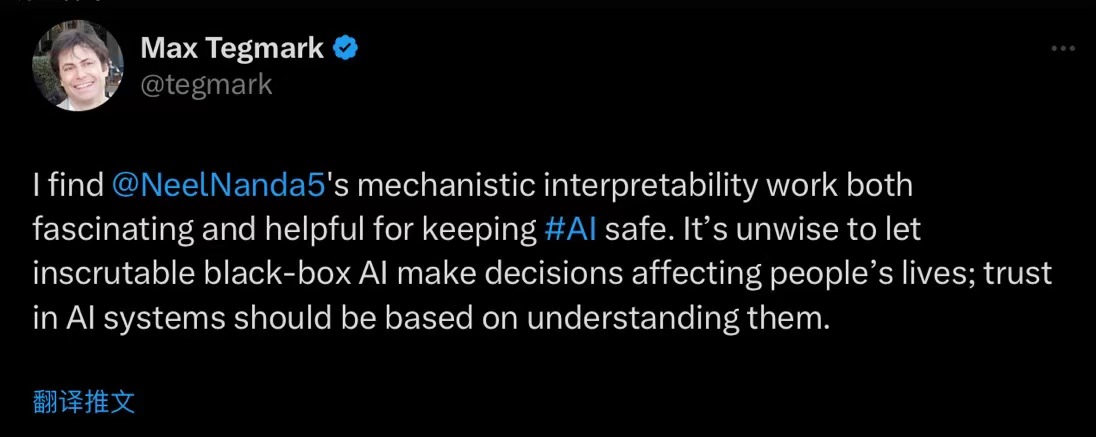
事实上,我们对 AI 可控可靠的要求,可能从低到高分为了 Diagnose Trustworthiness,Improve Trustworthiness 以及 Guarantee Trustworthiness,最开始我们只是确信像脚踩刹车一样踩下去速度就会降低,而不用理解刹车器的原理,而更加 Improved 之后的信任可能来自于部分的理解,理解刹车器的一些操作原理,而真正的 Guarantee Trustworthiness 则在于将那个“黑盒”完全透明化,深度的理解内部全部的知识并且可以复现与移植。
总而言之,在当前这样一个真正的智能 AI 还处在混沌期的时间节点,我们必然不应该“Overtrust AI”,而应该将其限制在一个可控的范围内,而要想使得大模型或者 AI 可靠可控,其必要一步与关键一招就是需要将 AI 的黑盒打开,即对 AI 可解释性研究的关注。
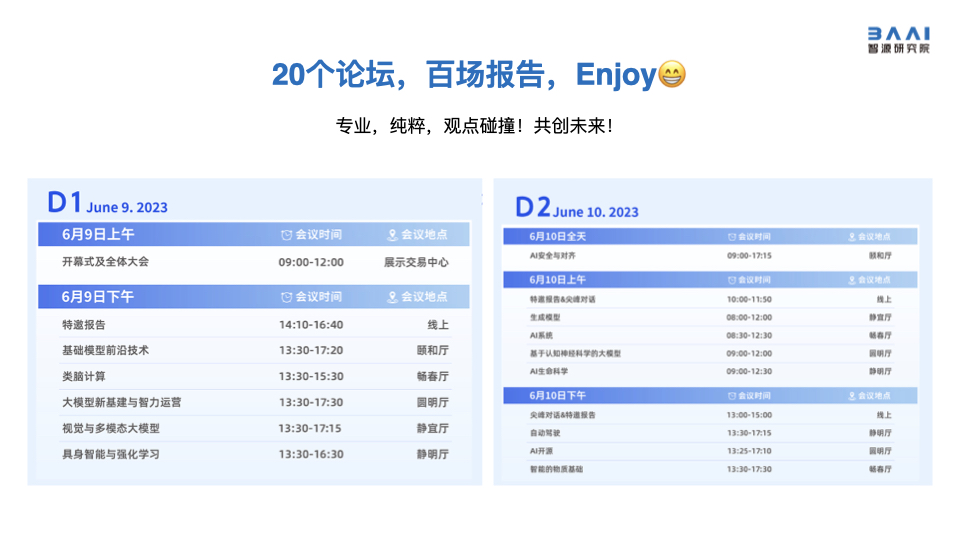
最后,开幕式后,9 号下午与 10 号全天还有 20 个分论坛百场报告,在各个不同的子领域,都有大咖学者亲临现场,精彩还在继续,感兴趣的大家可以关注2023年智源大会的日程安排!