
- 1git的常用语句_git语句大全
- 2【蓝桥杯】Python自带编辑器IDLE的使用教程_python蓝桥杯编译器
- 3BERT、BART、T5 等LLM大语言模型的比较分析_bart模型和t5
- 48种方案,保证缓存和数据库的最终一致性_缓存和数据库一致性同步解决方案
- 5【Transformer】什么是transformer? transformer输入输出是什么。transformer用于GPT的方法。tranformer的代码。chat-gpt_transformer编码器和解码器两个部分都包含输入该怎么理解呢
- 6RK3588 MIPIRX接收RGB888/RGB565/RGB666调试_rk3588 mipi dcphy dts
- 7C#调用Python程序的两种方法_c# python 相互调用
- 8谈谈程序员在传统企业的转型升级之路_传统公司程序员
- 9VMware vSphere 服务器虚拟化之二十七 桌面虚拟化之View中使用Thinapp软件虚拟化_thinapp的license
- 10【解决】Invalid hash given_fatal: invalid hash
Google最强开源大模型Gemma亮相!笔记本就能跑__笔记_gemma7b d_model
赞
踩
2月21日,Google宣布开源了一个新的模型系列Gemma。这个模型使用了与它最强的Gemini同源的技术,并且在一系列的标准测试上优于几款今天最热门的开源模型。
根据Google官方的介绍,Gemma是一个大型语言模型,而非像Gemini那样是多模态的。它基于与Gemini相同的技术构建,主打开源和轻量级,免费可用、模型权重开源、允许商用,同时笔记本可跑。
1.版本
Gemma有2B和7B两个版本。7B版本参数量约78亿,面向GPU和TPU上的高效部署和开发;2B版本参数量约25亿,用于CPU和端侧应用程序。
两个版本都有预训练和指令微调版,可在Kaggle、Colab Notebook、Google Cloud中访问,而且支持JAX、PyTorch和TensorFlow通过原生Keras 3.0进行推理和监督式微调(SFT),适应多种开发需求和环境。
2.性能
Gemma-7B模型在涵盖通用语言理解、推理、数学和编程的8项基准测试中,性能超过了广泛使用的Llama-2 7B和13B模型。它在数学/科学和编程相关任务上,通常也超过了Mistral 7B模型的性能。
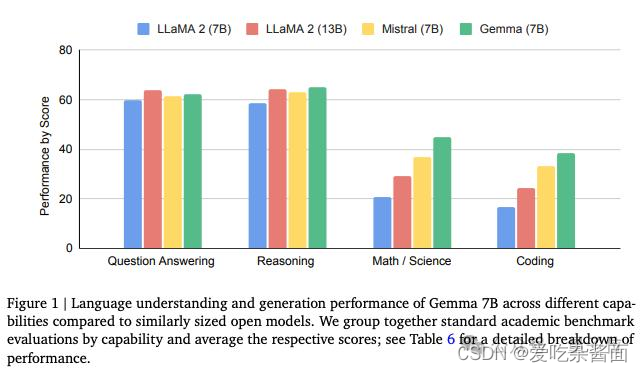
3.架构与参数
它基于Transformer解码器架构。Gemma-2B有18层,d_model为2048,而Gemma-7B有28层,d_model为3072。这些模型还具有不同的前馈隐藏维度、头数和KV头数,以及词汇量。
相比于基础Transformer,Gemma进行了一些升级。
7B版本使用多头注意力机制,2B版本使用多查询注意力机制。
在每一层中使用旋转位置嵌入代替绝对位置嵌入;使用GeGLU激活函数替代标准ReLU非线性。同时对每一个子层的输入和输出都进行归一化。
Gemma 2B/7B分别使用了2T和6T token进行训练,主要来自网络文档、数学和代码,不过这些数据不是多模态的。
为了兼容,谷歌使用了Gemini的SentencePiece tokenizer子集,它可以分割数字,不删除额外的空格,并对未知token进行字节级编码。
4.其他
有意思的是,在Google晒出的成绩对比中,阿里千问背后的模型Qwen系列表现也很亮眼:
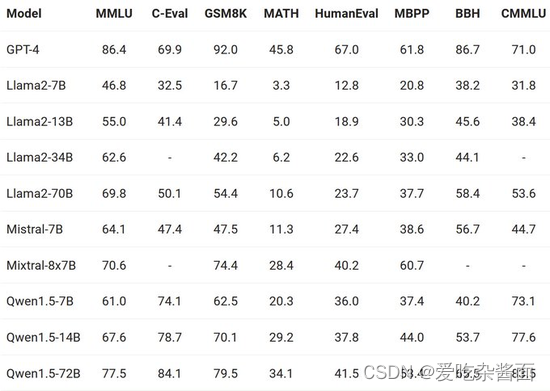
原文:
谷歌最强开源大模型亮相:Gemini技术下放,笔记本就能跑,可商用_澎湃号·湃客_澎湃新闻-The Paper
大动作不停,Google加入开源战局!低配版“Gemini ”Gemma来了!相当于OpenAI把GPT-3开源了|Google_新浪财经_新浪网 (sina.com.cn)

