
- 1百度AI达人创造营|第一课、拍案叫绝的创意_百度ai创造营
- 2【软件|软考设计师】敏捷开发scrum_敏捷开发方法scrum的步骤不包括
- 3php gd freetype libjpeg support 支持_with libjpeg suppor
- 4家庭版win10和win11修改C:\Users\下用户名为英文的问题_win11更改user
- 5java学习-【转】JVM JSTAT命令的用法和参数讲解_jstat -gccause 参数分析
- 6重磅来袭!阿里P7“青春修炼手册(1),2024年最新android物联网开发简书
- 7nltk下载wordnet等语料库WinError 10061 解决方案
- 8蚁群算法用于航路规划的matlab简单实现_matlab 蚁群算法
- 9Redis客户端工具 支持使用Redis命令行和集群_redis集群客户端工具
- 10【信号去噪-CEEMDAN】基于自适应噪声的完备经验模态分解CEEMDAN算法实现ECG信号去噪SE样本熵计算附matlab代码_信噪比怎么影响ceemdan
transformer模型_Transformer模型细节理解及Tensorflow实现
赞
踩
Transformer模型使用经典的Encoder-Decoder架构,在特征提取方面抛弃了传统的CNN、RNN,而完全基于Attention机制,在Attention机制上也引入了Self-Attention和Context-Attention,下面结合Transformer架构图和Tensorflow实现了解一下Transformer
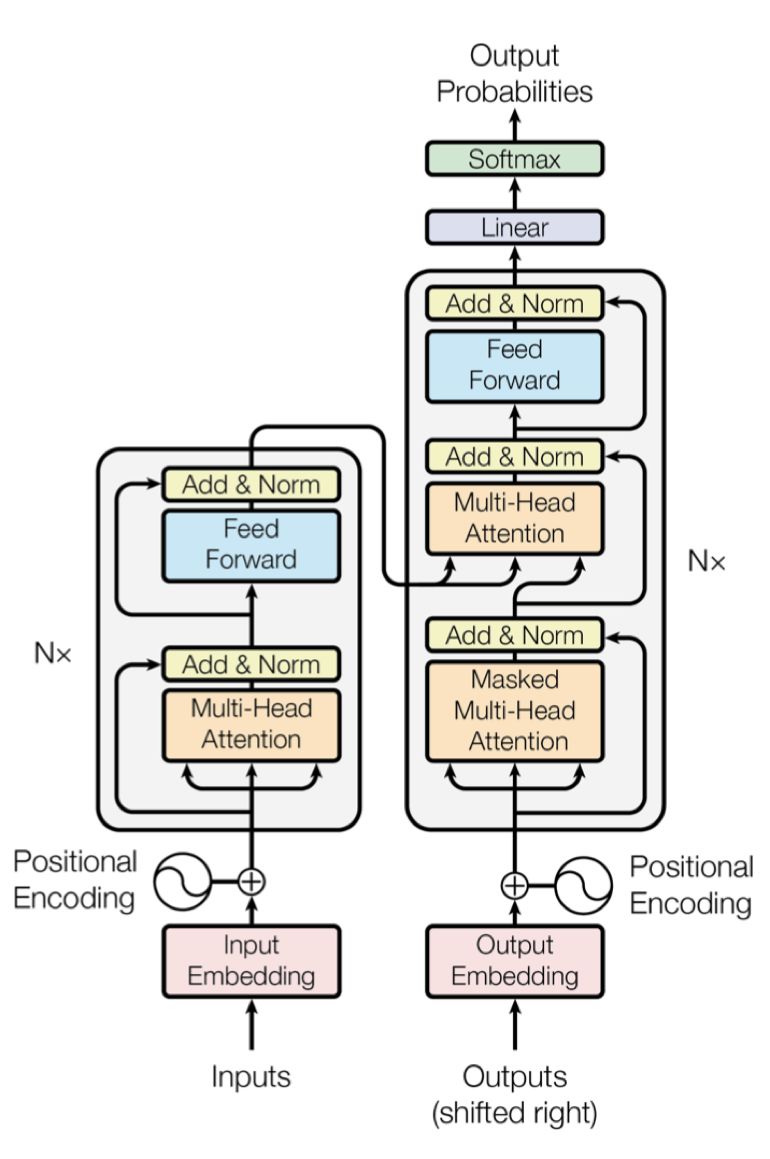
一、Transformer架构简说
Transformer是Encoder-Decoder架构,因此先整体分为Encoder、Decoder两部分
Encoder由6个相同的层组成,每层包含如下两部分:
第一部分:Multi-Head Attention多头注意力层
第二部分:Feed Forward全连接层
以上两部分都包含Residual Connection残差连接、Add&Norm数据归一化
Decoder也有6个相同的层组成,每层包含如下三部分:
第一部分:Masked Multi-Head Attention 经Sequence Mask处理的多头注意力层
第二部分:Multi-Head Attention
第三部分:Feed Forward全连接层
以上两部分都包含Residual Connection残差连接、Add&Norm数据归一化
二、Transformer模型细节理解
1、Encoder部分的输入是Input Embedding + Positional Embedding,Decoder部分的输入是Output Embedding + Positional Embedding,在MachineTranslation任务中,Input Embedding对应了输入的待翻译文本,Output Embedding对应了翻译后的文本
2、Encoder部分的Multi-Head Attention是self attention,对应输入的Q,k,V均相同是Input Embedding + Positional Embwedding,Decoder部分的Masked Multi-Head
Attention是self attention,对应的Q,K,V相同都是Output Embedding + Positional
Embedding,Decoder部分的Multi-Head Attention是Context attention,其中K,V相同来自于Encoder的输出memory,Q来自于Docoder词层的OutputEmbedding + Positional Embedding
3、Attention区别
self-attention和context-attention划分的区别是Attention衡量的是一个序列对自身的Attention权重还是一个序列对另一个序列的Attention权重,self-attention即计算自身的Attention权重,而Context-attention计算的是Encoder序列对Decoder序列的Attention权重;
ScaledDot-Product Attention和Multi-Head Attention划分是根据Attention权重计算方式,除了这些还有多种Attention权重计算方式,如下图所示

这里简单说一下Transformer中使用的Scaled Dot-Product Attention和Multi-Head
Attention
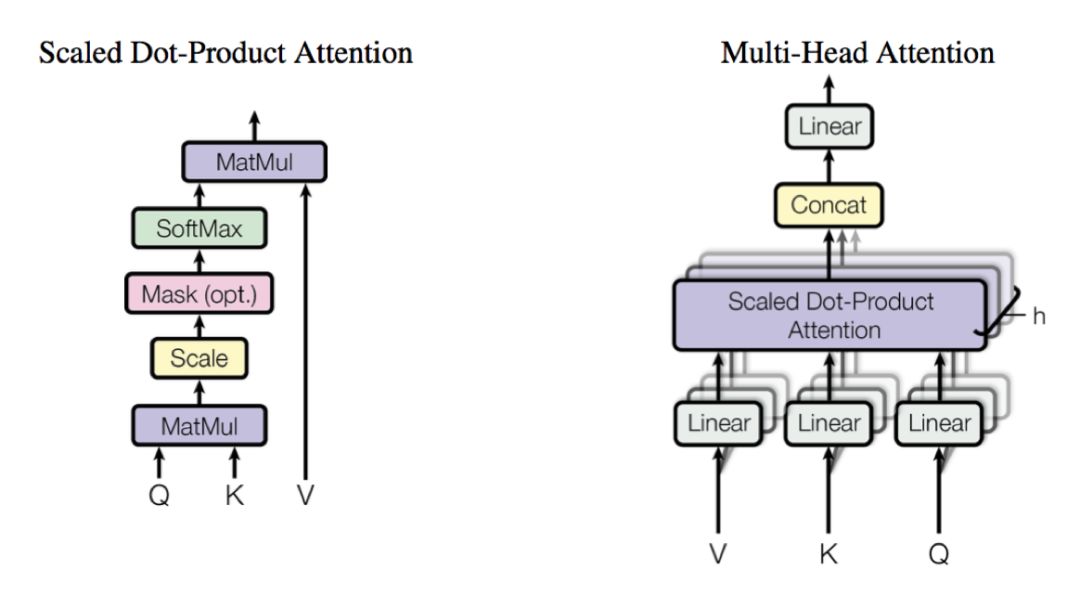
ScaledDot-Product Attention:通过Q,K矩阵计算矩阵V的权重系数
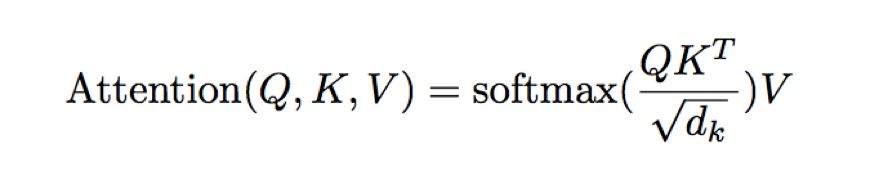
Multi-HeadAttention:多头注意力是将Q,K,V通过一个线性映射成h个Q,K,V,然后每个都计算Scaled Dot-Product Attention,最后再合起来,Multi-HeadAttention目的还是对特征进行更全面的抽取
4、Residual Connection残差连接原理及作用,先通过下图认识一下残差连接
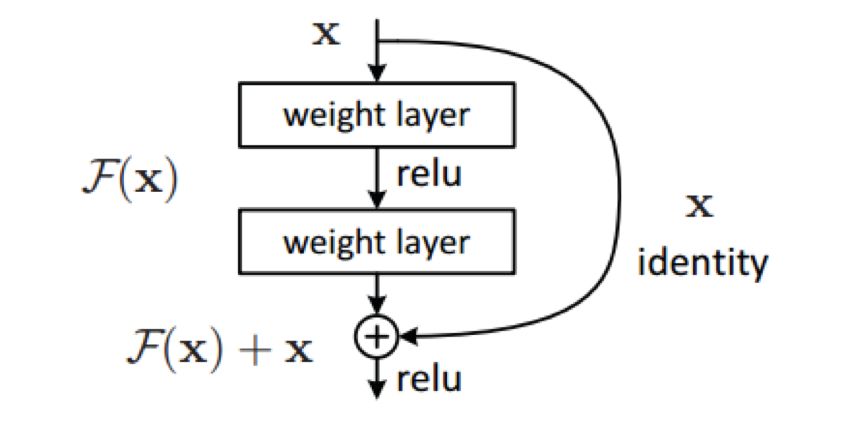
如上图网络某层对输入x作用后输出是F(x),那么增加残差连接即是在原来F(x)上加上x,输出变成了F(x)+x,即+x操作即是残差连接,残差连接的作用是通过+x,在网络反向传播的时候会多出一个常数项1,防止梯度消失
5、masked区别
Transformer中有两种mask,一种是padding mask,一种是sequence mask
(1) Padding mask:每次批次输入序列的长度是不一样的,需要对序列进行对齐操作,具体做法以seq_length为标准,对大于seq_length的序列进行截断,对小于seq_length序列进行填充,但填充部分我们又不希望其被注意,因此填充部分为0,可以在填充位置加上一个负无穷大的数,这样经过softmax后便趋向于0
(2) Sequence mask:sequencemask是为了使得decodeer不能看到未来的解码信息,因为在transformer中,输出序列是训练的时候是全部一下子全部传入网络中的,不似RNN那种递归的形式,因此对于一个序列来说,在t时刻我们解码输出只应该依赖于t时刻之前的输出,而不应该看到t时刻之后的输出,如果看到了那就不需要解码了,因此我们需要将传入的解码数据进行sequence mask操作。具体操作是产生一个矩阵,矩阵的上三角全为1,对角线

