
- 1发展低空经济的意义_解决低空经济模式问题的意义
- 2RabbitMQ工作模式
- 3机器学习在网络安全领域的深度探索与实践
- 4Facebook广告投放有哪些比较好的策略?
- 5论文阅读笔记---senet_特征权重标定
- 6sparkSQL的实现原理解析_sparksql 实现原理
- 7c语言 栈和队列的实现_c语言创建栈和队列
- 8深度学习之自然梯度法和线性判别分析
- 9(图文教程)IntelliJ IDEA 导入Eclipse/MyEclipse 项目 配置详解+快捷键分享_idea myeclipse 配置.jar
- 10文生图最新模型体验,能生成与原图风格融为一体的文字,或者对原图中的文字进行修改,并且还能支持中文!_文生图 能嵌入文字
Pytorch之经典神经网络CNN(八) —— ResNet(GAP全局池化层)(bottleneck)(CIFAR-10)_bottleneck 卷积网络
赞
踩
2015年 何恺明在微软亚洲研究院提出的
2015 ImageNet ILSVRC 冠军
ResNet 主要有五种:ResNet18、ResNet34、ResNet50、ResNet101、ResNet152几种。
其中,ResNet-18和ResNet-34的基本结构相同,属于相对浅层的网络;后面3种的基本结构不同于ResNet-18和ResNet-34,属于更深层的网络。
深层网络表现不好的问题
ResNet网络结构主要参考了VGG19网络,在其基础上通过短路连接加上了残差单元
ResNet 有效地解决了深度神经网络难以训练的问题, 可以训练高达 1000 层的卷积网络。 网络之所以难以训练, 是因为存在着梯度消失的问题, 离 loss 函数越远的层, 在反向传播的时候, 梯度越小, 就越难以更新, 随着层数的增加, 这个现象越严重。 之前有两种常见的方案来解决这个问题:
- 按层训练, 先训练比较浅的层, 然后在不断增加层数, 但是这种方法效果不是特别好, 而且比较麻烦
- 使用更宽的层, 或者增加输出通道, 而不加深网络的层数, 这种结构往往得到的效果又不好
ResNet 通过引入了跨层链接解决了梯度回传消失的问题
Residual block
使用普通的连接, 上层的梯度必须要一层一层传回来, 而是用残差连接, 相当于中间有了一条更短的路, 梯度能够从这条更短的路传回来, 避免了梯度过小的情况。
我们的目标是想学H(x), 但是我们看到,当网络层数变深的时候,学到一个好的H(x)是困难的。所以不如把它拆分一下,因为H(x) = F(x)+x, 我们学F(x), 即H(x)-x, 而不是直接学H(x)。F(x)就是所谓的残差。
右边的shortcut叫做identity是取自identity mapping恒等映射
注意这里的shortcut是真的加上去,而不是concat
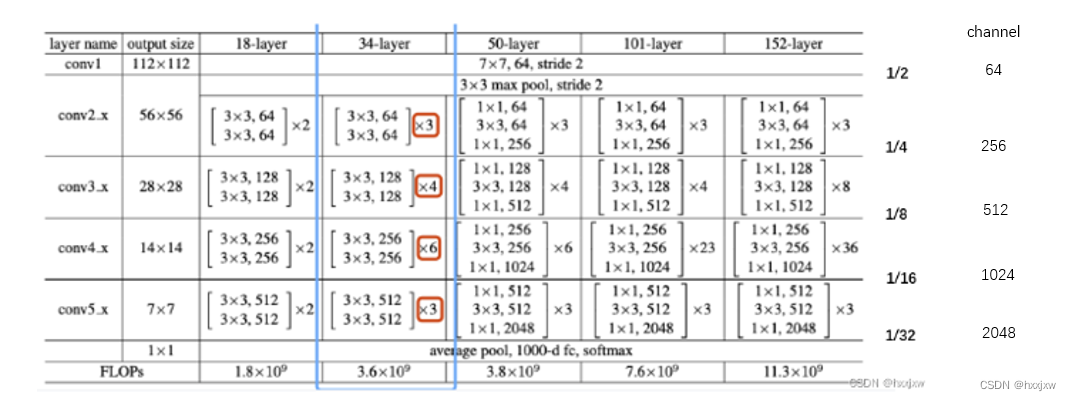
不同深度的ResNet网络的架构参数描述表
输入大小是224*224
可以看到,无论是resnet18还是34还是152,它们的输出size都是一样的
即resnet都是对原输入的32倍下采样,然后在用avgpooling拍平
resnet50,其C5的输出是对原图size的32倍下采样
resnet101也是,resnet几都是因为不管多少层的resnet都是5个conv块,这个conv块就是按照h,w size划分的
不同层的resnet的区别在于各个conv块的channel数和conv层数不同
对于50层+的Resnet,使用了bottleneck层来提升efficiency(和GoogLeNet)
训练ResNet
- Batch Normalization after every CONV layer
- Xavier/2 initialization from He et al.
- SGD + Momentum (0.9)
- Learning rate: 0.1, divided by 10 when validation error plateaus
- Mini-batch size 256
- Weight decay of 1e-5
- No dropout usedResNet的特性
①如果我们把residual block中的weight全部置0,那么它就相当于identity。
所以对于残差网络来说,模型可以在不需要的时候,不去使用某一层
②普通的卷积block与深度残差网络的最大区别在于,深度残差网络有很多旁路的支线将输入直接连到后面的层,使得后面的层可以直接学习残差,这些支路就叫做shortcut。
传统的卷积层或全连接层在信息传递时,或多或少会存在信息丢失、损耗等问题。ResNet 在某种程度上解决了这个问题,通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络则只需要学习输入、输出差别的那一部分,简化学习目标和难度。
③在反向传播过程中的梯度flow
当上层的梯度反向传播到一个addition gate的时候,他将会split,会形成两个分支往下走。所以残差连接的存在,相当于给了一条梯度反向传播的高速公路。因为网络能够训练地easier and faster.
残差结构使得梯度反向传播时,更不易出现梯度消失等问题,由于Skip Connection的存在,梯度能畅通无阻地通过各个Res blocks
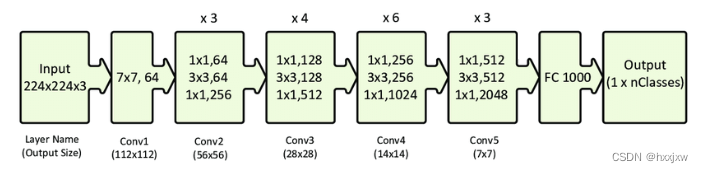
ResNet34
最后也用到了GAP层。除了FC1000外没有其他的fc层
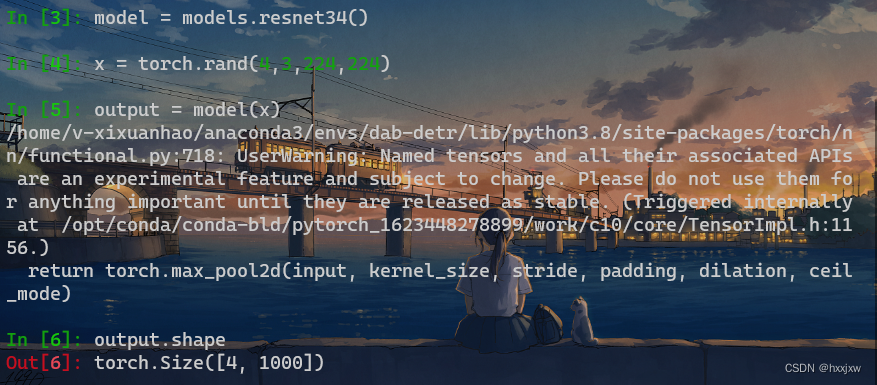
我们的输入图像是224x224,首先通过1个卷积层,接着通过4个残差层,最后通过Softmax之中输出一个1000维的向量,代表ImageNet的1000个分类
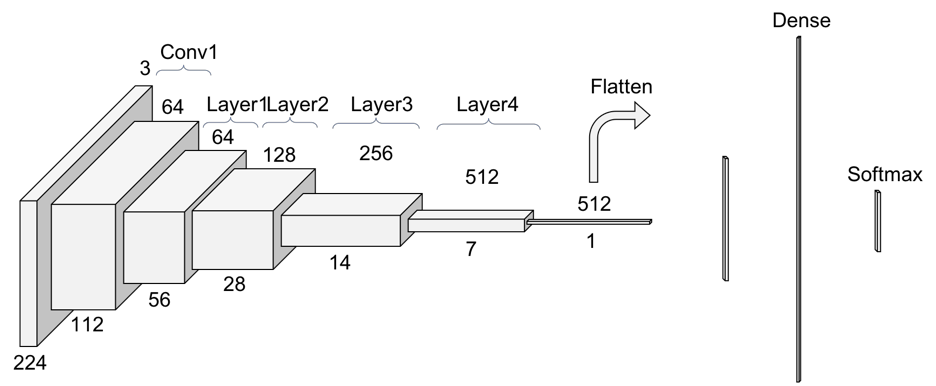
标准的Resnet接受的数据是224*224
ResNet的model在Pytorch中可以直接用
输入是 [bs,3,224,224]









ResNet18
resnet.py
main.py




