
热门标签
热门文章
- 1全方位解析废柴如何逆袭 1w+?
- 2vue3.0项目实战系列文章 - 登录页面_vue3 登录页面
- 3不压缩、不降质!快速在电脑手机间互传高清文件的秘诀
- 4【FPGA】摄像头模块OV5640
- 5留守在家,如何提升和精进FPGA设计能力?
- 6ETL工具-nifi干货系列 第一讲 揭开nifi神秘面纱_nifi中bulk controller status
- 7Windows下Spark开发环境的搭建_windows搭建spark环境
- 8Python机器翻译包Translate:多语种翻译利器
- 949. 【Android教程】HTTP 使用详解
- 10工业AGV(含AMR)工程师要求汇总220331_agv项目实施工程师需要对哪些硬件了解
当前位置: article > 正文
大数据手册(Spark)--Spark 简介
作者:很楠不爱3 | 2024-05-17 02:54:33
赞
踩
大数据手册(Spark)--Spark 简介
Spark 简介
Apache Spark 是一种用于大数据工作负载的分布式开源处理系统。它使用内存中缓存和优化的查询执行方式,可针对任何规模的数据进行快速分析查询。Apache Spark 提供了简明、一致的 Java、Scala、Python 和 R 应用程序编程接口 (API)。
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark 拥有Hadoop MapReduce所具有的优点,但不同的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 基本架构
一个完整的Spark应用程序(Application),在提交集群运行时,它涉及到如下图所示的组件:
一般包括一个主节点(任务控制节点)和多个从节点(工作节点),每个任务(Job)会被切分成多个阶段(Stage),每个阶段并发多线程执行,结束后返回到主节点。
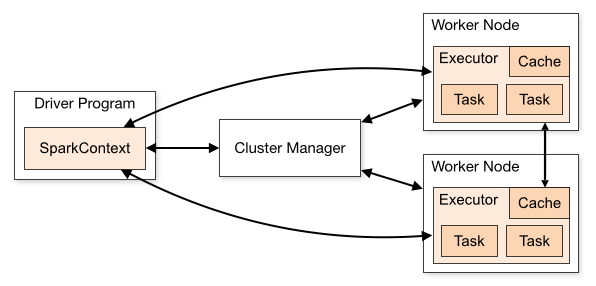
- Driver Program:(主节点或任务控制节点)执行应用程序主函数并创建SparkContext对象,SparkContext配置Spark应用程序的运行环境,并负责与不同种类的集群资源管理器通信,进行资源申请、任务的分配和监控等。当Executor部分运行完毕后,Driver同时负责将SparkContext关闭。
- Cluster Manager:(集群资源管理器)指的是在集群上进行资源(CPU,内存,宽带等)调度和管理。可以使用Spark自身,Hadoop YARN,Mesos等不同的集群管理方式。
- Worker Node:从节点或工作节点。
- Executor:每个工作节点上都会驻留一个Executor进程,每个进程会派生出若干线程,每个线程都会去执行相关任务。
- Task:(任务)运行在Executor上的工作单元。
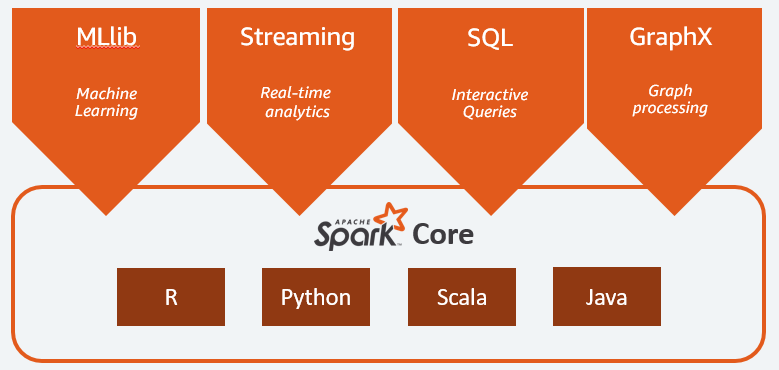
PySpark概述
PySpark是Apache Spark的Python API。它使您能够使用Python在分布式环境中执行实时、大规模的数据处理。PySpark支持Spark的所有功能,如Spark SQL、DataFrames、结构化流、机器学习(MLlib)和Spark Core。
- Spark SQL 是Spark处理结构化数据的模块,它提供了结构化抽象 DataFrame。
- Pandas API on Spark 是分布式 Pandas API。
- Structured Streaming 用于增量计算和流处理
- Spark MLlib 用于分布式环境下的机器学习
- Spark Core 是该平台的基础。它提供RDD(弹性分布式数据集)和内存计算能力。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/很楠不爱3/article/detail/581606
推荐阅读
相关标签

