
- 1一文搞懂什么是鸿蒙?OpenHarmony与HarmonyOS有什么区别?_harmonyos和openharmony区别
- 2服务器信息安全,服务器信息安全
- 3微信外包公司—北京动点软件:微信公众平台案例介绍_北京动点飞扬软件公司
- 4论文浅海矢量声场及其信号处理的学习_浅海波导如何通过截止频率判断有几个模态
- 5Windows环境搭建React Native Android的开发环境_android reactnative l leaked window
- 6AIGC最近很火,给大家推荐一个已经有1000位开发者使用的中文aigc开源模型,包括ai画图、ai聊天_aigc 开源模型
- 7vscode 默认初始化_VSCode中使用Pylint检查python代码
- 8JVM调优总结 -Xms -Xmx -Xmn -Xss
- 9localhost:8080打不开原因解决方法
- 10爆肝整理,接口性能测试总结,一篇直接上高速..._接口性能测试4400qtp
LLM漫谈(一)| LLM可以取代数据分析师吗?
赞
踩

我想,在过去的一年里,我们每个人都不止一次想知道ChatGPT是否(或者更确切地说,何时)能够取代你的工作。
我们有一个共识,即Generative AI最近的突破将极大地影响我们每个人生活和工作。然而,我们的工作将如何随着时间的推移而变化,目前还没有明确的看法。
花一些时间来未来社会的变化及其发生的概率可能会很吸引人,但我建议采取一种完全不同的方法——尝试自己构建原型。首先,它相当具有挑战性和趣味性。其次,它将帮助我们以更有条理的方式看待我们的工作。第三,这将使我们有机会在实践中尝试最前沿的方法之一——LLM代理。
在本文中,我们将从简单的开始,学习LLM如何利用工具并完成简单的任务。但在接下来的文章中,我们将深入探讨LLM代理的不同方法和最佳实践。
所以,让旅程开始吧。
一、什么是数据分析?
在讨论LLM之前,让我们尝试定义什么是分析以及我们作为分析师所做的任务。
个人认为分析团队的目标是帮助产品团队在可用时间内根据数据做出正确的决策。这是一个很好的任务,但要定义LLM支持的分析师的范围,我们应该进一步分解分析工作。
Gartner提出了四种不同的数据和分析技术的框架(https://www.gartner.com/en/topics/data-and-analytics):
- 描述性分析:可以回答诸如“发生了什么?”之类的问题。例如,12月份的收入是多少?这种方法包括报告任务和使用BI工具;
- 诊断分析:更进一步,提出了诸如“为什么会发生一些事情?”之类的问题。例如,为什么收入与前一年相比下降了10%?这种技术需要对数据进行更多的深入研究和切片;
- 预测分析:使我们能够获得诸如“会发生什么?”之类的问题的答案。这种方法的两个基石是预测(预测正常情况下的未来)和模拟(模拟不同的可能结果);
- 规定性分析:影响最终决策。常见的问题是“我们应该关注什么?”或“我们如何将销量提高10%?”。
通常,公司会逐步地经历所有这些阶段。如果你的公司还没有掌握描述性分析(你没有数据仓库、BI工具或指标定义),那么几乎不可能开始研究预测和不同的情景分析。因此,这个框架也可以显示公司的数据成熟度。
同样,当分析师从初级成长为高级时,也可能会经历所有这些阶段,从定义明确的报告任务开始,到模糊的战略问题。因此,这个框架在个人层面上也是相关的。
如果我们回到LLM支持的分析师,我们应该专注于描述性分析和报告任务。最好从基础开始。因此,我们将重点学习LLM,以了解有关数据的基本问题。
二、LLM代理和工具
以前我们使用LLM时(例如,主题建模(https://towardsdatascience.com/topic-modelling-in-production-e3b3e99e4fca)),我们需要在代码中详细描述建模的步骤。首先,我们要求模型确定客户评价的情绪。然后,根据情绪,从评论中提取文本中提到的优点或缺点。
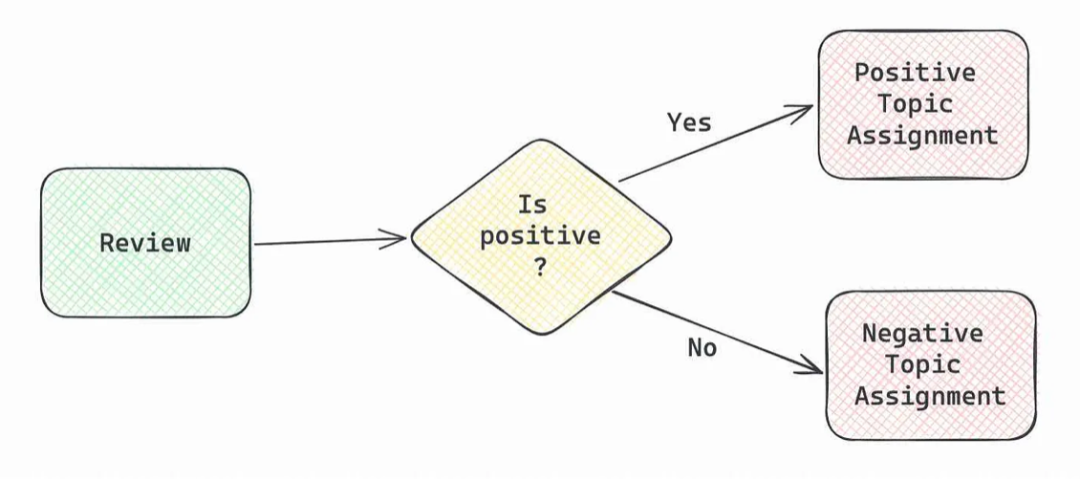
在这个例子中,我们清楚地定义了LLM的行为,LLM很好地解决了这个任务。然而,如果我们构建更高级、更模糊的东西,比如LLM支持的分析师,这种方法就不会奏效。
如果你曾经作为分析师或与分析师共事过至少一天,你就会知道分析师会收到各种各样的问题,从基本问题(如“昨天我们的网站上有多少客户?”或“你能为明天的董事会会议做一张图吗?”)到非常高层次的问题(如,“主要的客户痛点是什么?”或《我们下一步应该推出什么市场?》)。不用说,描述所有可能的场景是不可行的。
然而,有一种方法可以帮助我们——agent。代理的核心思想是使用LLM作为推理引擎,可以选择下一步要做什么以及何时将最终答案返回给客户。这听起来很接近我们的行为:我们完成一项任务,定义所需的工具,使用它们,然后在准备好后给出最终答案。
与代理相关的基本概念是工具。工具是LLM可以调用的函数,以获取丢失的信息(例如,执行SQL、使用计算器或调用搜索引擎)。工具至关重要,因为它们可以让你将LLM提升到一个新的水平,并与世界互动。在本文中,我们将主要关注OpenAI 函数提供的工具功能。
OpenAI提供了很多微调后的模型,这些模型可以提供工具功能:
- 可以将带有描述的函数列表传递给模型;
- 如果是查询相关,则模型将返回一个函数调用——函数名称和用于调用它的输入参数。
PS:OpenAI支持的最新模型和函数可以参考(https://platform.openai.com/docs/guides/function-calling)。
下面使用两个用例来说明函数与LLM的使用方法:
- 标记和提取——在这些任务中,函数用于确保模型的输出格式,会得到一个结构化的函数调用,而不是通常的带内容的输出;
- 工具和路由——这是一个更令人兴奋的用例,可以自定义创建代理。
三、用例#1:标记和提取
标记和提取唯一的区别是模型是提取文本中呈现的信息,还是标记文本以提供新信息(即定义语言或情感)。
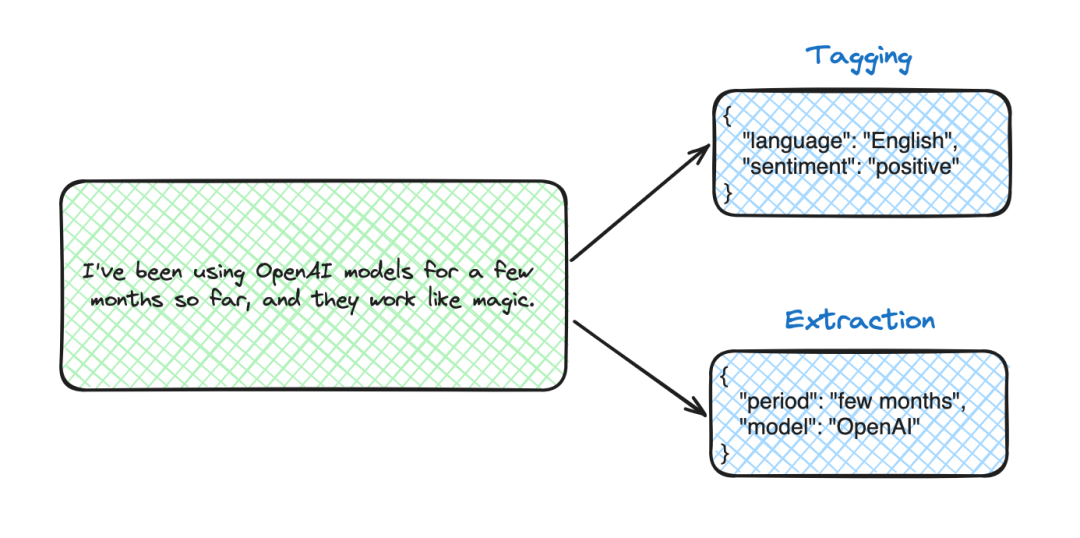
既然我们决定专注于描述性分析和报告任务,那么让我们使用这种方法来构建传入的数据请求,并提取以下组件:度量、维度、过滤器、周期和所需输出。

下面是一个提取的例子,因为我们只需要文本中的信息。
OpenAI Completion API基本示例
首先,我们需要定义函数。OpenAI期望函数描述为JSON。这个JSON将被传递给LLM,所以我们需要告诉它所有的上下文:这个函数做什么以及如何使用它。
下面是一个函数JSON的示例:
- 函数所需要的name和description;
- 每个参数的type和description;
- 函数所需输入参数的列表。
extraction_functions = [ { "name": "extract_information", "description": "extracts information", "parameters": { "type": "object", "properties": { "metric": { "type": "string", "description": "main metric we need to calculate, for example, 'number of users' or 'number of sessions'", }, "filters": { "type": "string", "description": "filters to apply to the calculation (do not include filters on dates here)", }, "dimensions": { "type": "string", "description": "parameters to split your metric by", }, "period_start": { "type": "string", "description": "the start day of the period for a report", }, "period_end": { "type": "string", "description": "the end day of the period for a report", }, "output_type": { "type": "string", "description": "the desired output", "enum": ["number", "visualisation"] } }, "required": ["metric"], }, }]在这个用例中,没有必要实现函数本身,因为我们不会使用它。我们只在函数调用时以结构化的方式获得LLM响应。
现在,我们可以使用标准的OpenAI聊天完成API来调用该函数。我们传递给API调用:
- 模型——使用最新的ChatGPT 3.5 Turbo,它支持函数调用;
- 消息列表——用于设置上下文的系统消息和一个用户请求;
- 我们前面定义的函数列表。
import openaimessages = [ { "role": "system", "content": "Extract the relevant information from the provided request." }, { "role": "user", "content": "How did number of iOS users change over time?" }]response = openai.ChatCompletion.create( model = "gpt-3.5-turbo-1106", messages = messages, functions = extraction_functions)print(response)结果,我们得到了以下JSON。
{ "id": "chatcmpl-8TqGWvGAXZ7L43gYjPyxsWdOTD2n2", "object": "chat.completion", "created": 1702123112, "model": "gpt-3.5-turbo-1106", "choices": [ { "index": 0, "message": { "role": "assistant", "content": null, "function_call": { "name": "extract_information", "arguments": "{\"metric\":\"number of users\",\"filters\":\"platform='iOS'\",\"dimensions\":\"date\",\"period_start\":\"2021-01-01\",\"period_end\":\"2021-12-31\",\"output_type\":\"visualisation\"}" } }, "finish_reason": "function_call" } ], "usage": { "prompt_tokens": 159, "completion_tokens": 53, "total_tokens": 212 }, "system_fingerprint": "fp_eeff13170a"}该模型返回了一个函数调用,而不是一个常见的响应:我们可以看到内容是空的,finish_reason等于function_call。在响应中,还有用于函数调用的输入参数:
- metric = "number of users",
- filters = "platform = 'iOS'",
- dimensions = "date",
- period_start = "2021-01-01",
- period_start = "2021-12-31",
- output_type = "visualisation"。
这个模型做得很好。唯一的问题是,它不知从哪里推测出了这一时期。我们可以通过在系统消息中添加更明确的指导来修复它,例如,"Extract the relevant information from the provided request. Extract ONLY the information presented in the initial request; don't add anything else. Return partial information if something is missing."
默认情况下,模型决定是否独立使用函数(function_call='auto')。我们可以要求它每次返回一个特定的函数调用,或者根本不使用函数。
# always calling extract_information functionresponse = openai.ChatCompletion.create( model = "gpt-3.5-turbo-1106", messages = messages, functions = extraction_functions, function_call = {"name": "extract_information"})# no function callsresponse = openai.ChatCompletion.create( model = "gpt-3.5-turbo-1106", messages = messages, functions = extraction_functions, function_call = "none")我们有了第一个使用LLM函数的应用程序。但是,用JSON描述函数不是很方便。让我们讨论一下如何改进。
使用Pydantic定义函数
为了更方便地定义函数,我们可以利用Pydantic。Pydantic是用于数据验证的最流行的Python库。
我们已经使用Pydantic定义了LangChain输出解析器。
首先,我们需要创建一个继承自BaseModel类的类,并定义所有字段(函数的参数)。
from pydantic import BaseModel, Fieldfrom typing import Optionalclass RequestStructure(BaseModel): """extracts information""" metric: str = Field(description = "main metric we need to calculate, for example, 'number of users' or 'number of sessions'") filters: Optional[str] = Field(description = "filters to apply to the calculation (do not include filters on dates here)") dimensions: Optional[str] = Field(description = "parameters to split your metric by") period_start: Optional[str] = Field(description = "the start day of the period for a report") period_end: Optional[str] = Field(description = "the end day of the period for a report") output_type: Optional[str] = Field(description = "the desired output", enum = ["number", "visualisation"])然后,我们可以使用LangChain将Pydantic类转换为OpenAI函数。
from langchain.utils.openai_functions import convert_pydantic_to_openai_functionextract_info_function = convert_pydantic_to_openai_function(RequestStructure, name = 'extract_information')LangChain验证我们提供的类。例如,它确保指定了功能描述,因为LLM需要它才能使用此工具。
因此,我们得到了相同的JSON来传递给LLM,但现在我们将其表示为Pydantic类。
{'name': 'extract_information', 'description': 'extracts information', 'parameters': {'title': 'RequestStructure', 'description': 'extracts information', 'type': 'object', 'properties': {'metric': {'title': 'Metric', 'description': "main metric we need to calculate, for example, 'number of users' or 'number of sessions'", 'type': 'string'}, 'filters': {'title': 'Filters', 'description': 'filters to apply to the calculation (do not include filters on dates here)', 'type': 'string'}, 'dimensions': {'title': 'Dimensions', 'description': 'parameters to split your metric by', 'type': 'string'}, 'period_start': {'title': 'Period Start', 'description': 'the start day of the period for a report', 'type': 'string'}, 'period_end': {'title': 'Period End', 'description': 'the end day of the period for a report', 'type': 'string'}, 'output_type': {'title': 'Output Type', 'description': 'the desired output', 'enum': ['number', 'visualisation'], 'type': 'string'}}, 'required': ['metric']}}现在,我们可以在调用OpenAI时使用它。让我们从OpenAI API切换到LangChain,使我们的API调用更加模块化。
定义LangChain链
让我们定义一个chain来根据请求提取所需的信息。我们的chain很简单,它由一个OpenAI模型和一个request变量(用户消息)的提示组成。
我们还使用了bind函数将函数参数传递给模型。bind函数允许我们为不属于输入的模型(例如,函数或温度)指定常量参数。
from langchain.prompts import ChatPromptTemplatefrom langchain.chat_models import ChatOpenAImodel = ChatOpenAI(temperature=0.1, model = 'gpt-3.5-turbo-1106')\ .bind(functions = [extract_info_function])prompt = ChatPromptTemplate.from_messages([ ("system", "Extract the relevant information from the provided request. \ Extract ONLY the information presented in the initial request. \ Don't add anything else. \ Return partial information if something is missing."), ("human", "{request}")])extraction_chain = prompt | model现在是时候试试我们的功能了。我们需要使用invoke方法并传递一个请求。
extraction_chain.invoke({'request': "How many customers visited our site on iOS in April 2023 from different countries?"})在输出中,我们得到了没有任何内容但带有函数调用的AIMessage。
AIMessage( content='', additional_kwargs={ 'function_call': { 'name': 'extract_information', 'arguments': '''{ "metric":"number of customers", "filters":"device = 'iOS'", "dimensions":"country", "period_start":"2023-04-01", "period_end":"2023-04-30", "output_type":"number"} '''} })因此,我们已经学会了如何在LangChain中使用OpenAI函数来获得结构化输出。现在,让我们转到更有趣的用例——工具和路由。
四、用例2:工具和路由
现在是时候使用工具并赋予我们的模型外部能力了。这种方法中的模型是推理引擎,它们可以决定使用什么工具以及何时使用(这称为路由)。
LangChain有一个工具的概念——代理可以用来与世界交互的接口。工具可以是函数、LangChain链,甚至是其他代理。
我们可以使用format_tool_to_penai_function轻松地将工具转换为OpenAI函数,并不断将functions参数传递给LLM。
定义自定义工具
让我们来教我们的LLM分析师计算两个指标之间的差异。我们知道LLM可能会在数学上出错,所以我们想让模型使用计算器,而不是自己计算。
要定义一个工具,我们需要创建一个函数并使用@tool装饰器。
from langchain.agents import tool@tooldef percentage_difference(metric1: float, metric2: float) -> float: """Calculates the percentage difference between metrics""" return (metric2 - metric1)/metric1*100现在,这个函数具有将传递给LLM的名称和描述参数。
print(percentage_difference.name)# percentage_difference.nameprint(percentage_difference.args)# {'metric1': {'title': 'Metric1', 'type': 'number'},# 'metric2': {'title': 'Metric2', 'type': 'number'}}print(percentage_difference.description)# 'percentage_difference(metric1: float, metric2: float) -> float - Calculates the percentage difference between metrics'这些参数将用于创建OpenAI功能规范。让我们将我们的工具转换为OpenAI函数。
from langchain.tools.render import format_tool_to_openai_functionprint(format_tool_to_openai_function(percentage_difference))结果我们得到了以下JSON。它展示了结构,但缺少字段描述。
{'name': 'percentage_difference', 'description': 'percentage_difference(metric1: float, metric2: float) -> float - Calculates the percentage difference between metrics', 'parameters': {'title': 'percentage_differenceSchemaSchema', 'type': 'object', 'properties': {'metric1': {'title': 'Metric1', 'type': 'number'}, 'metric2': {'title': 'Metric2', 'type': 'number'}}, 'required': ['metric1', 'metric2']}}我们可以使用Pydantic为参数指定一个模式。
class Metrics(BaseModel): metric1: float = Field(description="Base metric value to calculate the difference") metric2: float = Field(description="New metric value that we compare with the baseline")@tool(args_schema=Metrics)def percentage_difference(metric1: float, metric2: float) -> float: """Calculates the percentage difference between metrics""" return (metric2 - metric1)/metric1*100现在,如果我们将新版本转换为OpenAI函数规范,它将包括参数描述。这要好得多,因为我们可以与模型共享所有需要的上下文。
{'name': 'percentage_difference', 'description': 'percentage_difference(metric1: float, metric2: float) -> float - Calculates the percentage difference between metrics', 'parameters': {'title': 'Metrics', 'type': 'object', 'properties': {'metric1': {'title': 'Metric1', 'description': 'Base metric value to calculate the difference', 'type': 'number'}, 'metric2': {'title': 'Metric2', 'description': 'New metric value that we compare with the baseline', 'type': 'number'}}, 'required': ['metric1', 'metric2']}}因此,我们已经定义了LLM将能够使用的工具。让我们练习一下。
在实践中使用工具
让我们定义一个chain,并将我们的工具传递给函数。然后,我们可以根据用户请求对其进行测试。
model = ChatOpenAI(temperature=0.1, model = 'gpt-3.5-turbo-1106')\ .bind(functions = [format_tool_to_openai_function(percentage_difference)])prompt = ChatPromptTemplate.from_messages([ ("system", "You are a product analyst willing to help your product team. You are very strict to the point and accurate. You use only facts, not inventing information."), ("user", "{request}")])analyst_chain = prompt | modelanalyst_chain.invoke({'request': "In April we had 100 users and in May only 95. What is difference in percent?"})我们得到了一个带有正确参数的函数调用,所以它正常工作。
AIMessage(content='', additional_kwargs={ 'function_call': { 'name': 'percentage_difference', 'arguments': '{"metric1":100,"metric2":95}'} })为了有一种更方便的方法来处理输出,我们可以使用OpenAIFunctionsAgentOutputParser。让我们把它添加到我们的chain中。
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParseranalyst_chain = prompt | model | OpenAIFunctionsAgentOutputParser()result = analyst_chain.invoke({'request': "There were 100 users in April and 110 users in May. How did the number of users changed?"})现在,我们以一种更结构化的方式获得了输出,并且我们可以很容易地将工具的参数检索为result.tool_input。
AgentActionMessageLog( tool='percentage_difference', tool_input={'metric1': 100, 'metric2': 110}, log="\nInvoking: `percentage_difference` with `{'metric1': 100, 'metric2': 110}`\n\n\n", message_log=[AIMessage(content='', additional_kwargs={'function_call': {'name': 'percentage_difference', 'arguments': '{"metric1":100,"metric2":110}'}})])因此,我们可以按照LLM的请求执行函数,如下所示。
observation = percentage_difference(result.tool_input)print(observation)# 10如果我们想从模型中得到最终答案,我们需要将函数执行结果传递回来。要做到这一点,我们需要定义一个消息列表来传递给模型观察结果。
from langchain.prompts import MessagesPlaceholdermodel = ChatOpenAI(temperature=0.1, model = 'gpt-3.5-turbo-1106')\ .bind(functions = [format_tool_to_openai_function(percentage_difference)])prompt = ChatPromptTemplate.from_messages([ ("system", "You are a product analyst willing to help your product team. You are very strict to the point and accurate. You use only facts, not inventing information."), ("user", "{request}"), MessagesPlaceholder(variable_name="observations")])analyst_chain = prompt | model | OpenAIFunctionsAgentOutputParser()result1 = analyst_chain.invoke({ 'request': "There were 100 users in April and 110 users in May. How did the number of users changed?", "observations": []})observation = percentage_difference(result1.tool_input)print(observation)# 10然后,我们需要将观测值添加到我们的observations变量中。我们可以使用format_to_openai_functions函数以预期的方式对模型的结果进行格式化。
from langchain.agents.format_scratchpad import format_to_openai_functionsformat_to_openai_functions([(result1, observation), ])因此,我们得到了这样一个LLM可以理解的信息。
[AIMessage(content='', additional_kwargs={'function_call': {'name': 'percentage_difference', 'arguments': '{"metric1":100,"metric2":110}'}}), FunctionMessage(content='10.0', name='percentage_difference')]让我们再次调用我们的链,将函数执行结果作为观测值传递。
result2 = analyst_chain.invoke({ 'request': "There were 100 users in April and 110 users in May. How did the number of users changed?", "observations": format_to_openai_functions([(result1, observation)])})现在,我们从模型中得到了最终结果,这听起来很合理。
AgentFinish( return_values={'output': 'The number of users increased by 10%.'}, log='The number of users increased by 10%.')PS:如果我们使用普通的OpenAI Chat Completion API,我们可以使用role=tool来添加另一条消息。(https://platform.openai.com/docs/guides/function-calling)有一个详细的例子。
如果我们打开debug模式,我们可以看到传递给OpenAI API完整的Prompt。
System: You are a product analyst willing to help your product team. You are very strict to the point and accurate. You use only facts, not inventing information.Human: There were 100 users in April and 110 users in May. How did the number of users changed?AI: {'name': 'percentage_difference', 'arguments': '{"metric1":100,"metric2":110}'}Function: 10.0要打开LangChain调试,可以执行以下代码:
import langchainlangchain.debug = True我们已经尝试使用一个tool,现在来推广到toolkit,看看LLM如何处理它。
路由:使用多个tool
我们在分析师工具包中再添加几个工具:
- 获取月活跃用户;
- 使用维基百科。
首先,让我们定义一个伪函数,以按月份和城市过滤部分受众,我们将再次使用Pydantic来指定函数的输入参数。
import datetimeimport randomclass Filters(BaseModel): month: str = Field(description="Month of customer's activity in the format %Y-%m-%d") city: Optional[str] = Field(description="City of residence for customers (by default no filter)", enum = ["London", "Berlin", "Amsterdam", "Paris"])@tool(args_schema=Filters)def get_monthly_active_users(month: str, city: str = None) -> int: """Returns number of active customers for the specified month""" dt = datetime.datetime.strptime(month, '%Y-%m-%d') total = dt.year + 10*dt.month if city is None: return total else: return int(total*random.random())然后,让我们使用wikipedia Python包来查询wikipedia。
import wikipediaclass Wikipedia(BaseModel): term: str = Field(description="Term to search for")@tool(args_schema=Wikipedia)def get_summary(term: str) -> str: """Returns basic knowledge about the given term provided by Wikipedia""" return wikipedia.summary(term)让我们用我们模型知道的所有函数来定义一个字典。这个字典为后面路由做铺垫。
toolkit = { 'percentage_difference': percentage_difference, 'get_monthly_active_users': get_monthly_active_users, 'get_summary': get_summary}analyst_functions = [format_tool_to_openai_function(f) for f in toolkit.values()]对以前的设置进行了一些更改:
- 稍微调整了一下系统prompt,迫使LLM在需要一些基本知识的情况下查阅维基百科。
- 将模型更改为GPT4,因为它更适合处理需要推理的任务。
from langchain.prompts import MessagesPlaceholdermodel = ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview')\ .bind(functions = analyst_functions)prompt = ChatPromptTemplate.from_messages([ ("system", "You are a product analyst willing to help your product team. You are very strict to the point and accurate. \ You use only information provided in the initial request. \ If you need to determine some information i.e. what is the name of the capital, you can use Wikipedia."), ("user", "{request}"), MessagesPlaceholder(variable_name="observations")])analyst_chain = prompt | model | OpenAIFunctionsAgentOutputParser()我们可以用所有函数调用我们的chain。让我们从一个非常简单的查询开始。
result1 = analyst_chain.invoke({ 'request': "How many users were in April 2023 from Berlin?", "observations": []})print(result1)我们在get_monthly_active_users的结果函数调用中输入了参数-{'month':'2023–04–01','city': 'Berlin'},这看起来是正确的。该模型能够找到正确的工具并解决任务。
让我们试着让任务变得更复杂一点。
result1 = analyst_chain.invoke({ 'request': "How did the number of users from the capital of Germany\ change between April and May 2023?", "observations": []})让我们停下来思考一下我们希望模型如何推理。很明显,没有足够的信息让模型立即回答,因此它需要进行一系列函数调用:
- 调用维基百科获取德国首都;
- 两次调用get_monthly_active_users函数以获取四月和五月的MAU;
- 调用percentage_difference来计算度量之间的差异。
它看起来相当复杂。让我们看看ChatGPT是否能够处理这个问题。
对于第一个调用,LLM返回了一个对维基百科的函数调用,其中包含以下参数-{“term”:“capital of Germany”。
看看接下来会采取什么步骤。
observation1 = toolkit[result1.tool](result1.tool_input)print(observation1)# The capital of Germany is the city state of Berlin. It is the seat of # the President of Germany, whose official residence is Schloss Bellevue. # The Bundesrat ("federal council") is the representation of the Federal States # (Bundesländer) of Germany and has its seat at the former Prussian Herrenhaus # (House of Lords). Though most of the ministries are seated in Berlin, # some of them, as well as some minor departments, are seated in Bonn, # the former capital of West Germany.# Although Berlin is officially the capital of the Federal Republic of Germany,# 8,000 out of the 18,000 total officials employed at the federal bureaucracy # still work in Bonn, about 600 km (370 mi) away from Berlin.# source: https://en.wikipedia.org/wiki/Capital_of_Germany result2 = analyst_chain.invoke({ 'request': "How did the number of users from the capital of Germany change between April and May 2023?", "observations": format_to_openai_functions([(result1, observation1)])})该模型希望使用参数{“month”:“2023–04–01”,“city”:“Berlin”}执行get_monthly_active_users。让我们执行此操作,并再次将信息返回给模型。
observation2 = toolkit[result2.tool](result2.tool_input)print(observation2)# 168result3 = analyst_chain.invoke({ 'request': "How did the number of users from the capital of Germany change between April and May 2023?", "observations": format_to_openai_functions([(result1, observation1), (result2, observation2)])})然后,模型请求再次调用get_monthly_active_users,参数为{‘month':‘2023–05–01’,‘city’:‘Berlin’}。到目前为止,它做得很好。让我们遵循它的逻辑。
observation3 = toolkit[result3.tool](result3.tool_input)print(observation3)# 1046result4 = analyst_chain.invoke({ 'request': "How did the number of users from the capital of Germany change between April and May 2023?", "observations": format_to_openai_functions( [(result1, observation1), (result2, observation2), (result3, observation3)])})随后的结果是使用以下参数调用percentage_difference{'metric1':168,'metric2':1046}。让我们计算观测值并再次调用我们的chain。希望这将是最后一步。
observation4 = toolkit[result4.tool](result4.tool_input)print(observation4)# 523.27result5 = analyst_chain.invoke({ 'request': "How did the number of users from the capital of Germany change between April and May 2023?", "observations": format_to_openai_functions( [(result1, observation1), (result2, observation2), (result3, observation3), (result4, observation4)])})最终,我们从该模型中得到了以下回应:The number of users from Berlin, the capital of Germany, increased by approximately 523.27% between April and May 2023.。
以下是LLM对这个问题的完整调用方案。

在上面的例子中,我们一个接一个的手动执行调用,其实可以很容易地实现自动化。
这是一个奇妙的结果,我们能够看到LLM如何进行推理并利用多种工具。它采取了模型5的步骤来实现结果,但它遵循了我们最初概述的计划,所以这是一条非常合乎逻辑的道路。但是,如果您计划在生产中使用LLM,请记住它可能会出错,并引入评估和质量保证流程。
总结
这篇文章介绍了如何使用OpenAI 函数调用外部工具来增强LLM。我们研究了两个用例:提取以获得结构化输出,路由以使用外部信息解决问题。最后的结果启发了我,因为LLM可以使用三种不同的工具回答相当复杂的问题。
让我们回到最初的问题,LLM是否可以取代数据分析师。目前的方案比较基础,与初级分析师的能力相去甚远,但这只是一个开始。敬请关注!我们将深入探讨LLM代理的不同方法。下一次,我们将尝试创建一个可以访问数据库并回答基本问题的代理。
参考文献:
[1] https://towardsdatascience.com/can-llms-replace-data-analysts-building-an-llm-powered-analyst-851578fa10ce

