
- 1MT6771 android13 自定义背光曲线
- 2鸿蒙系统下拉菜单,华为鸿蒙系统官方
- 3EasyConnect虚拟IP地址未分配_easyconnect虚拟ip未分配
- 4HarmonyOS应用开发工具DevEco Studio安装与使用_deveco studio 4.0 beta2
- 5java调用npoi_Npoi 使用总结 回顾 反思
- 6【Flutter学习】页面布局之基础布局组件_flutter widthfactory
- 7视频监控平台 国标GB28181视频平台 liveweb视频汇聚平台方案分析
- 8ASP.NET网络在线考试系统(源代码+论文)ASP.NET网络商店销售管理系统的设计与实现(源代码+论文)_asp.net在线考试网站代码
- 9进程地址空间_进程的地址空间
- 10分析 AGI 纹理数据并提升 GPU 性能
Hello Vector DB|认识一下,这才是真正的向量数据库_vectordb
赞
踩
随着大模型的爆火,向量数据库也越发成为开发者关注的焦点。为了方便大家更好地了解向量数据库,我们特地推出了 Hello VectorDB 系列,本文将从宏观角度、向量数据库与其他算法库的区别、技术难点及如何选择向量数据库等方面,带大家认识真正的向量数据库。
在正式开始前,先来了解一个背景:非结构化数据呈爆炸式增长,而我们可以通过机器学习模型,将非结构化数据转化为 embedding 向量,随后处理分析这些数据。在此过程中,向量数据库应运而生。向量数据库是一种为了高效存储和索引 AI 模型产生的向量嵌入(embedding)数据而专门设计的数据库。
01.宏观解读向量数据库
如今,强大的机器学习模型配合 Milvus 等向量数据库的模式已经为电子商务、推荐系统、语义检索、计算机安全、制药等领域和应用场景带来变革。而对于用户而言,除了足够多的应用场景,向量数据库还需要具备更多重要的特性,包括:
-
可灵活扩展、支持调参:当向量数据库中存储的非结构化数据量增长至数亿或数十亿时,支持跨节点水平扩展这一特性显得至关重要。因为,没有人愿意通过每 3 个月在服务器中手动插入一次 RAM 内存条这种方法来实现扩展。此外,由于数据插入速率、查询速度和基础硬件条件会根据应用场景而有所变化,所以向量数据库还需要支持灵活调参。
-
多租户、数据隔离:为每一个新用户的数据创建一个全新向量数据库,显然不合常理。因此向量数据库需要支持多租户。同时,通过支持数据隔离,只有 collection 所有者允许共享数据时,collection 数据才对其他用户可见。否则,在向量数据库中对任何一个 collection 进行数据插入、删除、查询等操作时,其他用户均不可见。
-
完整的 API:如果没有完整的 API 和 SDK,基本算不上是真正的数据库。Milvus 向量数据库就提供了 Python、Node、Go 和 Java 等语言的 SDK,方便用户轻松连接和管理 Milvus 向量数据库。
-
直观的用户界面或管理控制台:直观的用户界面可以大大降低学习成本。用户可以通过界面来体验向量数据库发布的新功能和工具。
02.向量数据库与 ANN 算法库的区别
我们经常听到一个这样的错误观念——向量数据库只是在 ANN(approximate nearest neighbor,近似最近邻)算法上封装了一层。但这种说法大错特错。
向量数据库可以处理大规模数据,而 ANN 算法库只能处理小型的数据集
从本质上来看,以 Milvus 为代表的向量数据库是一套完整的非结构化数据解决方案,具备诸多功能——云原生、多租户、可扩展性等。但诸如 FAISS 等都是轻量级 ANN 算法库,这些算法库的主要用于构建向量索引(一种数据结构),从而加速多维向量的最近邻检索。这些算法库可以轻松应对小型数据集。但是,随着数据集和用户数量不断增长,这些算法库无法处理大规模数据。
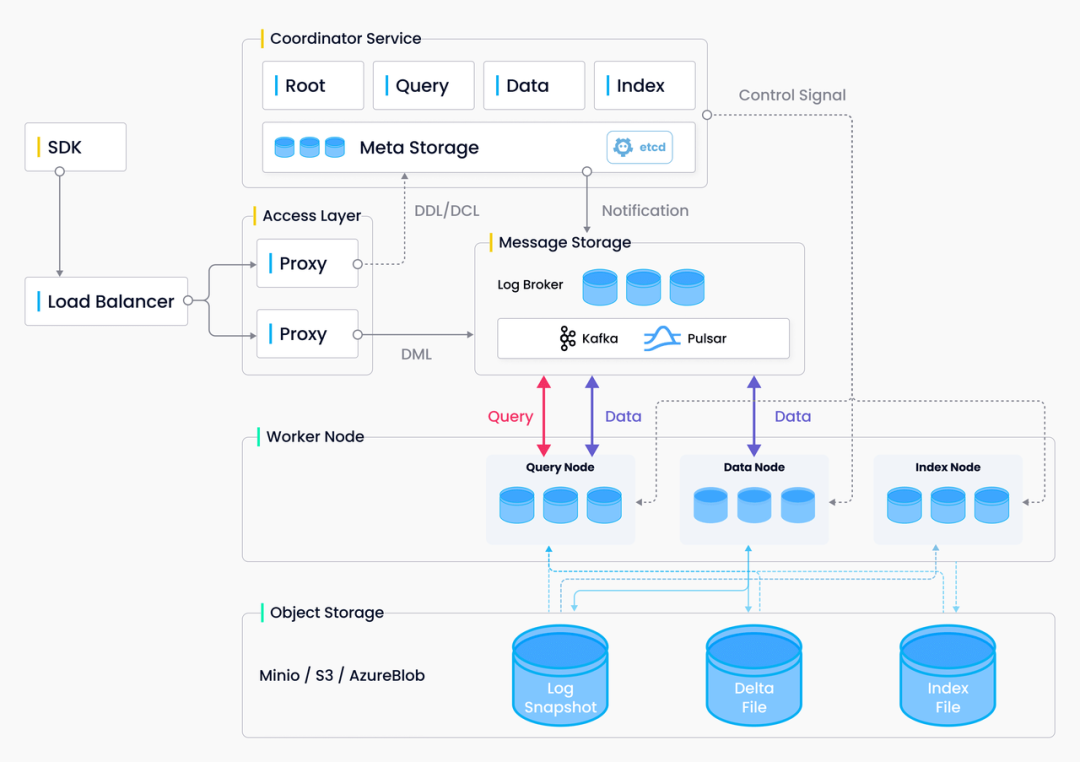 |Milvus 架构图
|Milvus 架构图
向量数据库是一套完整的解决方案,而 ANN 算法库只是其中一部分
以 Milvus 为代表的向量数据库与 ANN 算法库另一大不同之处在于:向量数据库是一套完整的服务,而算法库是需要被集成到应用中去的。因此,从某种意义上而言,算法库是向量数据库的组件之一。这有点类似于 Elasticsearch 是一套基于 Apache Lucene 的搜索引擎解决方案。
为了具体说明这种区别, 我们来举一个例子。
在 Milvus 向量数据库中插入非结构化数据只需要三行代码即可。
from pymilvus import Collection
collection = Collection('book')
mr = collection.insert(data)
- 1
但对于 FAISS 或 ScaNN 这样的算法库,没有这样可以简单插入数据的方法。即使自己通过代码实现插入数据,ANN 算法库仍然缺乏可扩展性和多租户等特性。
算法库距离生产可用的产品,差了一个向量数据库的距离
对于一个想要将向量检索功能集成进生产环境的用户,即使完成了算法库集成的开发,想要让其生产可用,更需要让其能够被运维:
-
动态的可扩展性,在系统的压力较大时能做到扩容,提供多个可读副本
-
高可用性,在发生异常时能够继续提供降级服务
-
正确的快速恢复,在发生异常状态后能够快速恢复到正常的状态,并且保证数据的一致性和完整性
-
多租户,足够的权限控制
-
对于系统状态可监控,能够让运维团队乃至开发者快速发现系统异常并且处理,等等
而这些功能,是算法库本身并不具备的,往往需要成熟的数据库产品/服务来提供。
03.向量数据库与传统数据库向量检索插件的区别
越来越多的传统关系型数据库和检索系统(如 Clickhouse、Elasticsearch等)开始提供内置的向量检索插件。
例如,Elasticsearch 8.0 支持通过 Restful API 来插入向量和开展 ANN 检索。但是,向量检索插件的问题显而易见——无法提供 embedding 向量管理和检索的全栈方法。这些插件仅可在现有的架构基础上用作优化方案,使用场景十分有限。在传统数据库基础上开发非结构化数据应用就如同在汽油车中安装锂电池和电动机一样不合常理。向量检索插件不支持灵活调参,也不提供易用的 API 或 SDK。但这两点是向量数据库的基本特性。
为了展示向量数据库与向量检索插件的区别,文本将以 Elasticsearch ANN 搜索引擎为例,其他向量检索插件运行方式类似,因此不进一步展开。
Elasticsearch 的 dense_vector 字段支持向量数据类型,且可以通过 knnsearch endpoint 进行向量查询。
PUT index
{"mappings": {"properties": {"image-vector": {"type": "dense_vector","dims": 128,"index": true,"similarity": "l2_norm"}}}}
PUT index/_doc
{"image-vector": [0.12, 1.34, ...]}
- 1
- 2
- 3
- 4
- 5
- 6
GET index/_knn_search
{"knn": {"field": "image-vector","query_vector": [-0.5, 9.4, ...],"k": 10,"num_candidates": 100}}
- 1
- 2
- 3
Elasticsearch 的 ANN 插件仅支持 HNSW 一种索引和 L2(欧式距离)一种距离计算方法。但下面,让我们来使用向量数据库 Milvus(以 pymilvus 为例)。
>>> field1 = FieldSchema(name='id', dtype=DataType.INT64, description='int64', is_primary=True)
>>> field2 = FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, description='embedding', dim=128, is_primary=False)
>>> schema = CollectionSchema(fields=[field1, field2], description='hello world collection')
>>> collection = Collection(name='my_collection', data=None, schema=schema)
>>> index_params = {
'index_type': 'IVF_FLAT',
'params': {'nlist': 1024},
"metric_type": 'L2'}
>>> collection.create_index('embedding', index_params)
- 1
>>> search_param = {
'data': vector,
'anns_field': 'embedding',
'param': {'metric_type': 'L2', 'params': {'nprobe': 16}},
'limit': 10,
'expr': 'id_field > 0'
}
>>> results = collection.search(**search_param)
- 1
虽然 Elasticsearch 和 Milvus 都支持创建索引、插入 embedding 向量、执行 ANN 向量检索,但从以上示例中可以明显看出,Milvus 具备更直观的向量检索 API(可更好服务用户),支持更多样的向量索引类型和距离计算公式(方便用户灵活调参)。Milvus 还计划在未来支持更多的索引类型,并允许用户通过类似 SQL 语句进行查询,从而进一步提升向量数据库的可用性。
简而言之,诸如 Milvus 的向量数据库比向量检索插件更好用。因为 Milvus 是从零开始构建的向量数据库,相较而言,具备更丰富的功能和更适合非结构化数据的系统架构。
04.一些技术难点
在文章的前半部分,我们列举了一些向量数据库应该具备的特性,然后比较了向量数据库和 ANN 算法库、向量检索插件的不同之处。现在让我来看看构建向量数据库过程中会遇到的一些技术难点。在后续的文章中,我们会着重介绍 Milvus 向量数据库是如何克服这些难点,以及哪些技术决策成功帮助 Milvus 在性能方面超过其他开源向量数据库。
就好像一架飞机一样,内部每个零部件和系统相互连通,共同协作为我们提供愉悦的飞行之旅,向量数据库也是同样的道理。其中包含一系列的组件,可粗略分为存储、索引和服务。虽然这三部分组件相辅相成,但是诸如 Snowflake 之类的公司已经向存储行业证明了 “Shared Nothing” 的数据库架构可能更优于传统云数据库的“共享存储(Shared Storage)”模式。
那么,构建向量数据库的第一个难点来了:如何设计一个灵活、可扩展的数据模型?有了数据模型之后,我们需要考虑第二个问题。将数据存储在向量数据库后,如何检索、查询这些数据并构建索引?
机器学习模型和多层神经网络本质上重计算,因此 GPU、 NPU/TPU、FPGA 和其他通用计算机硬件繁荣发展。向量查询和索引构建同样重计算。使用上述硬件加速后,向量查询和索引构建的速度和效率都将大幅提升。多样的计算资源引入了第二个技术难点,如何设计一个支持异构计算的架构?
有了数据模型和架构之后,需要思考最后一个问题。应用系统如何从向量数据库中读取数据?
问题的答案和 API、用户界面息息相关。想要以最低的成本取得最佳的性能,向量数据库作为一种全新的数据库类型催生了一种新的架构。不过,大部分的向量数据库用户还是习惯于传统数据库的 CRUD 操作(例如:SQL 中的 INSERT、SELECT、UPDATE、 DELETE )。因此,最后一个技术难点便在于如何开发一套与传统类似的 API 和 图形用户界面(GUI),但同时要确保与向量数据库的底层架构兼容。
总而言之,三个组件对应了三个技术难点。需要注意的是,世界上不存在什么可以拿来套用的通用型向量数据库架构。最棒的向量数据库应该解决上述几个难点,并同时提供前文中所列举的功能。
05.向量数据库的优势
向量数据库的主要应用领域为相似性检索、机器学习、人工智能等。与传统数据库比较,向量数据库具备以下几点优势:
-
高维向量检索:向量数据库可以高效进行高维向量相似性检索,非常适用于机器学习和人工智能应用中,如:图片识别、自然语言处理、推荐系统等。
-
灵活性:向量数据库可以处理多样的向量数据类型,包括稀疏向量和稠密向量。此外,向量数据库还可以处理其他的数据类型,包括:数字、文本、二进制数据(Binary)。
-
性能:相较于传统数据,使用向量数据库进行相似性检索更高效。
-
支持选择不同索引结构:向量数据库支持用户根据不同的应用场景和数据类型构建不同的索引结构。
总结一下,向量数据库在相似性检索和机器学习场景中具有显著优势,能够快速、高效检索和召回高维向量数据。
06.选择向量数据库时需要考量的点
性能
如上述,查询性能(查询的响应时间,系统的吞吐能力)是在选型向量数据库时的一个重要参考点,市面上现有的向量数据库的 Benchmark 有:
-
ANN-Benchmark 是一种用于评估各种向量数据库和近似最近邻(ANN)算法性能的工具
-
VectorDBBench 是一款开源的对于各种主流向量数据库和云服务的性能对比工具,提供了 QPS/成本/响应延时等多个维度的比较,提供了方便的 Web UI
-
LeaderBoard TL;DR VectorDBBench 的“太长不看”版本
成本
由于 AIGC 浪潮的火热, 大量新的开发者涌入这个领域,因此在选择向量数据库产品时,成本也是用户具体做出决策的重要指标。
在产品初期,数据体量不大的情况下,能够用最少的成本达到应用需求的响应时间和系统吞吐,是开发者最希望达到的目标。
功能和易用性
除了性能之外,一款流行的数据库必然也提供了生产可用的产品特性,如:
-
高可用,快速恢复
-
成熟的指标监测体系及告警系统
-
定期备份及恢复
并且相较于算法库,能够对于用户屏蔽许多底层细节:
-
根据存储/性能考量,自动选择向量索引类型
-
根据需要的召回率(Recall)动态决定搜索参数
这些往往是用户在性能之外,选择向量数据库时考量的点。
07.总结
本文全面介绍了向量数据库,分析了成熟向量数据库提供的特性,探讨了向量数据库与 ANN 算法库、传统数据库向量检索插件的异同,最后本文还阐述了构建向量数据库过程中的技术难点。我们希望通过本文,能够帮助大家真正了解向量数据库。
点击链接查看相关视频:https://www.youtube.com/embed/4yQjsY5iD9Q
-
如果在使用 Milvus 或 Zilliz 产品有任何问题,可添加小助手微信 “zilliz-tech” 加入交流群。 -
欢迎关注微信公众号“Zilliz”,了解最新资讯。
本文由 mdnice 多平台发布

