
- 1自然语言处理学习笔记十(文本聚类)_重复二分聚类
- 2【蓝桥杯】阿坤老师的魔方挑战
- 3基础备忘:C++编译期多态与运行期多态_编译器多态可以基于函数的重载解析
- 4微机系统的存储器(一)半导体存储器_内存和外存都是由半导体器件构成的吗
- 5idea maven下载异常,报错 Cannot access alimaven (http://maven.aliyun.com/nexus/content/groups/public/)_has+not+been+downloaded+from+it+before
- 6huggingface无法下载模型的实战代码_无法从huggingface下载baichuan
- 7JDK安装教程详解
- 8Java面向对象浅谈
- 9IntelliJ IDEA 2023和Java的JDK详细安装教程_idea2023 win11安装
- 10Spring Boot 集成 RocketMQ_springboot rocketmq
【数据集合集】最全最新——智能交通和无人驾驶相关数据集_ford campus数据集
赞
踩
【数据集合集】智能交通和无人驾驶相关
- 一、无人驾驶数据集:
- 1. The H3D Dataset:
- 2. nuscenes:
- 3. ApolloCar3D:
- 4. KITTI Vision Benchmark Suite:
- 5. Cityscape Dataset:
- 6. Mapillary Vistas Dataset:
- 7. CamVid:
- 8. Caltech Pedestrian Dataset:
- 9. Comma.ai:
- 10. Oxford's Robotic Car:
- 11. BBD1000K:
- 12. Udacity Dataset:
- 13. NCLT Dataset:
- 14. Ford Campus Vision and Lidar DataSet:
- 15. DIPLECS Autonomous Driving Datasets:
- 16. The SYNTHIA dataset:
- 二、交通标识数据集:
- 三、车辆检测数据集:
- 关注我的公众号:
转载请先联系作者~
作者主页:https://blog.csdn.net/weixin_44936889
一、无人驾驶数据集:
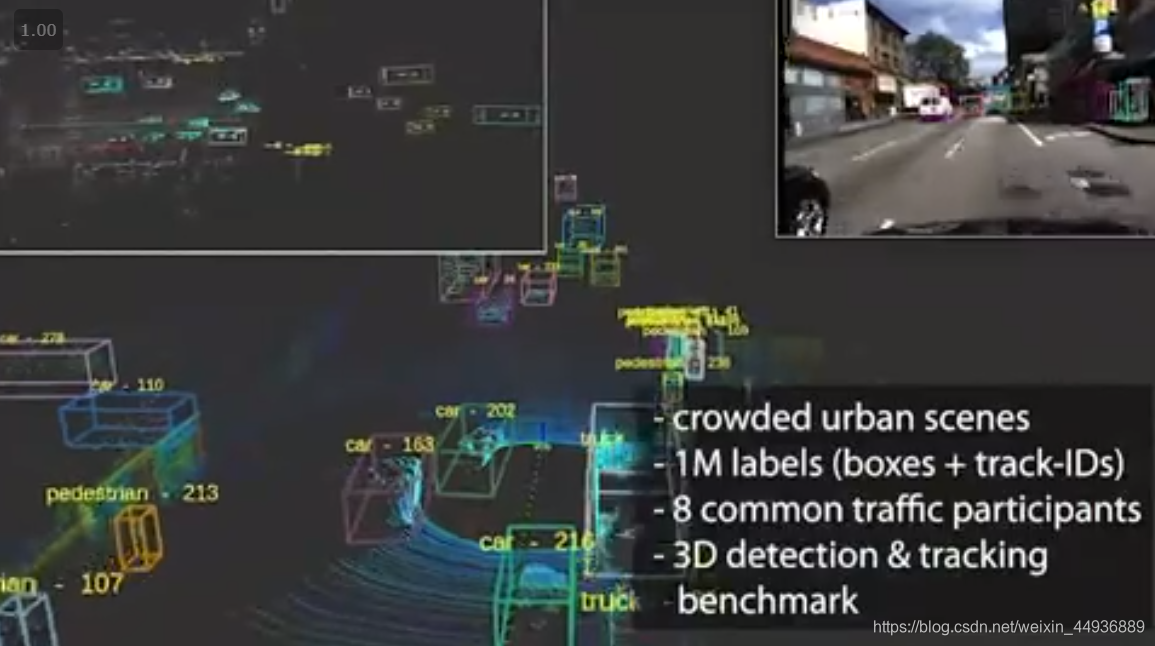
1. The H3D Dataset:
官网:
https://usa.honda-ri.com/h3d
论文地址:
https://arxiv.org/abs/1903.01568
简介:
本田研究所于2019年3月发布其无人驾驶方向数据集。本数据集使用3D LiDAR扫描仪收集的大型全环绕3D多目标检测和跟踪数据集。 其包含160个拥挤且高度互动的交通场景,在27,721帧中共有100万个标记实例。
2. nuscenes:

官网:
论文地址:
https://arxiv.org/abs/1903.11027
简介:
安波福于2019年3月正式公开了其数据集,并已在GitHub公开教程。数据集拥有从波士顿和新加坡收集的1000个“场景”的信息,包含每个城市环境中都有的最复杂的一些驾驶场景。该数据集由140万张图像、39万次激光雷达扫描和140万个3D人工注释边界框组成,是迄今为止公布的最大的多模态3D 无人驾驶数据集。
3. ApolloCar3D:

官网:
http://apolloscape.auto/car_instance.html
论文地址:
https://arxiv.org/abs/1811.12222v1
简介:
该数据集包含5,277个驾驶图像和超过60K的汽车实例,其中每辆汽车都配备了具有绝对模型尺寸和语义标记关键点的行业级3D CAD模型。该数据集比PASCAL3D +和KITTI(现有技术水平)大20倍以上。
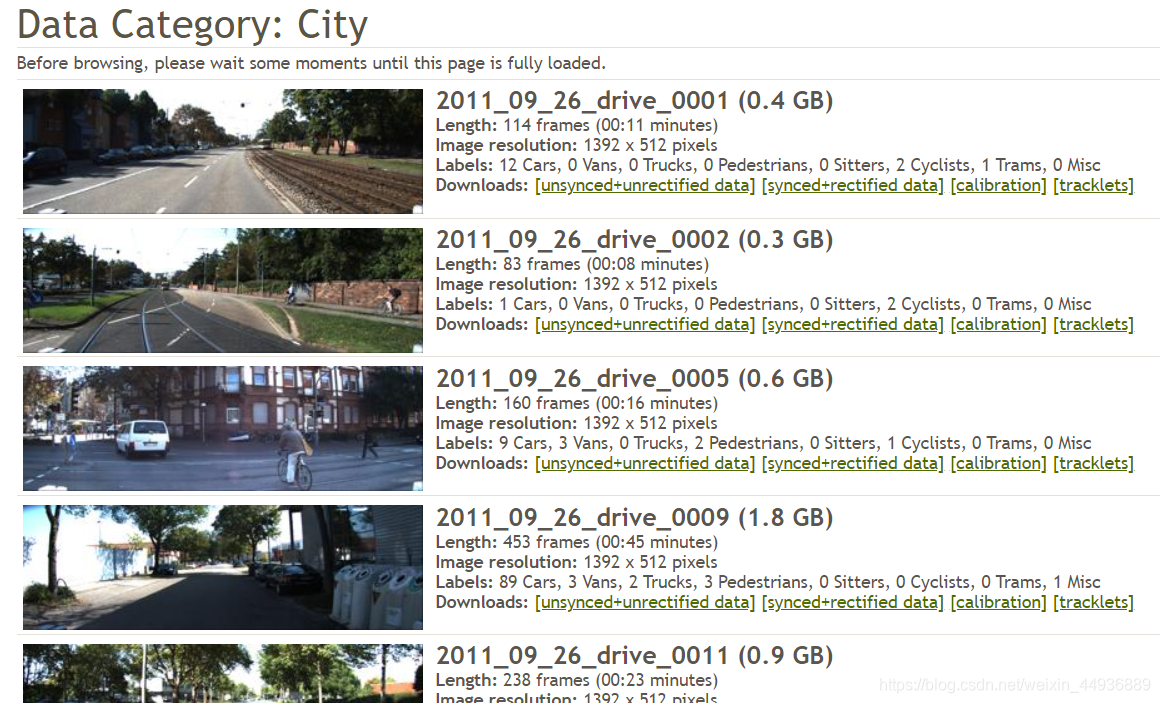
4. KITTI Vision Benchmark Suite:
官网:
http://www.cvlibs.net/datasets/kitti/raw_data.php
论文地址:
http://www.cvlibs.net/publications/Geiger2012CVPR.pdf
简介:
KITTI数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,用于评测立体图像(stereo),光流(optical flow),视觉测距(visual odometry),3D物体检测(object detection)和3D跟踪(tracking)等计算机视觉技术在车载环境下的性能。KITTI包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多达15辆车和30个行人,还有各种程度的遮挡与截断。整个数据集由389对立体图像和光流图,39.2 km视觉测距序列以及超过200k 3D标注物体的图像组成[1] ,以10Hz的频率采样及同步。总体上看,原始数据集被分类为’Road’, ’City’, ’Residential’, ’Campus’ 和 ’Person’。对于3D物体检测,label细分为car, van, truck, pedestrian, pedestrian(sitting), cyclist, tram以及misc组成。
5. Cityscape Dataset:

官网地址:
https://www.cityscapes-dataset.com/
论文地址:
https://arxiv.org/abs/1604.01685
简介:
专注于对城市街景的语义理解。 大型数据集,包含从50个不同城市的街景中记录的各种立体视频序列,高质量的像素级注释为5000帧,另外还有一组较大的20000个弱注释帧。 因此,数据集比先前的类似尝试大一个数量级。 可以使用带注释的类的详细信息和注释示例。
6. Mapillary Vistas Dataset:

官网地址:
https://www.mapillary.com/dataset/vistas?pKey=xyW6a0ZmrJtjLw2iJ71Oqg&lat=20&lng=0&z=1.5
简介:
数据集是一个新颖的大规模街道级图像数据集,包含25,000个高分辨率图像,注释为66个对象类别,另有37个类别的特定于实例的标签。通过使用多边形来描绘单个对象,以精细和细粒度的样式执行注释。
7. CamVid:

官网地址:
http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/
论文地址:
http://www0.cs.ucl.ac.uk/staff/G.Brostow/papers/Brostow_2009-PRL.pdf
简介:
剑桥驾驶标签视频数据库(CamVid)是第一个具有对象类语义标签的视频集合,其中包含元数据。 数据库提供基础事实标签,将每个像素与32个语义类之一相关联。 该数据库解决了对实验数据的需求,以定量评估新兴算法。 虽然大多数视频都使用固定位置的闭路电视风格相机拍摄,但我们的数据是从驾驶汽车的角度拍摄的。 驾驶场景增加了观察对象类的数量和异质性。
8. Caltech Pedestrian Dataset:

官网地址:
http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/
论文地址:
https://pdollar.github.io/files/papers/DollarCVPR09peds.pdf
简介:
加州理工学院行人数据集包括大约10小时的640x480 30Hz视频,这些视频来自在城市环境中通过常规交通的车辆。 大约250,000个帧(137个近似分钟的长段)共有350,000个边界框和2300个独特的行人被注释。 注释包括边界框和详细遮挡标签之间的时间对应。 更多信息可以在我们的PAMI 2012和CVPR 2009基准测试文件中找到。
9. Comma.ai:
官网地址:
https://comma.ai/
论文地址:
https://arxiv.org/abs/1812.05752
简介:
7.25小时的高速公路驾驶。 包含10个可变大小的视频片段,以20 Hz的频率录制,相机安装在Acura ILX 2016的挡风玻璃上。与视频平行,还记录了一些测量值,如汽车的速度、加速度、转向角、GPS坐标,陀螺仪角度。 这些测量结果转换为均匀的100 Hz时基。
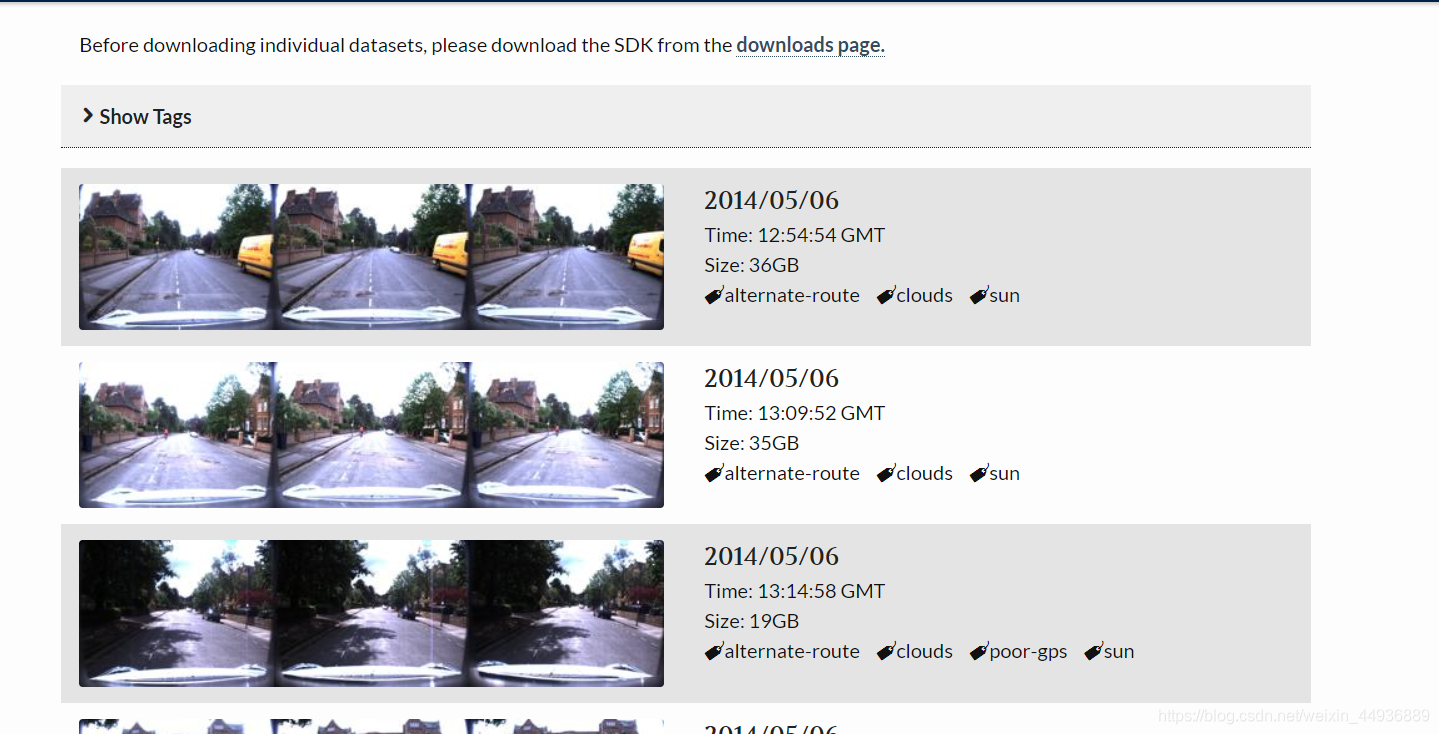
10. Oxford’s Robotic Car:
官网地址:
https://robotcar-dataset.robots.ox.ac.uk/
论文地址:
https://journals.sagepub.com/doi/abs/10.1177/0278364916679498
简介:
超过100次重复对英国牛津的路线进行一年多采集拍摄。 该数据集捕获了许多不同的天气,交通和行人组合,以及建筑和道路工程等长期变化。
11. BBD1000K:

官网地址:
https://bdd-data.berkeley.edu/
论文地址:
https://bair.berkeley.edu/blog/2018/05/30/bdd/
简介:
超过100K的视频和各种注释组成,包括图像级别标记,对象边界框,可行驶区域,车道标记和全帧实例分割,该数据集具有地理,环境和天气多样性。
12. Udacity Dataset:

官网地址:
https://github.com/udacity/self-driving-car
论文地址:
https://ieeexplore.ieee.org/abstract/document/8460913
简介:
Udacity 开放无人驾驶训练数据,为世界上每个希望进入这个行业的人提供学习的机会。现在Udacity开放了源代码和对应的训练模型,主要包含了如下内容:
- Deep Learning Steering Models : 通过多层神经网络预测汽车转向角
- Camera Mount :摄像头及镜头安装的硬件标准
- Annotated Driving Datasets :已经标注过的驾驶数据 3.3G
- Driving Datasets :超过10个小时的驾驶数据(雷达、摄像头等) 290G
- ROS Steering Node : 与ROS节点的对接方式
13. NCLT Dataset:

官网地址:
http://robots.engin.umich.edu/nclt/
论文地址:
http://robots.engin.umich.edu/nclt/nclt.pdf
简介:
包括全方位图像,3D激光雷达,平面激光雷达,GPS和本体感应传感器,用于使用Segway机器人收集的测距。并添加了地面真实姿势估计中关键帧的协方差。这些边缘协方差是从SLAM图中提取的,并以与数据集中其他协方差相同的格式记录。
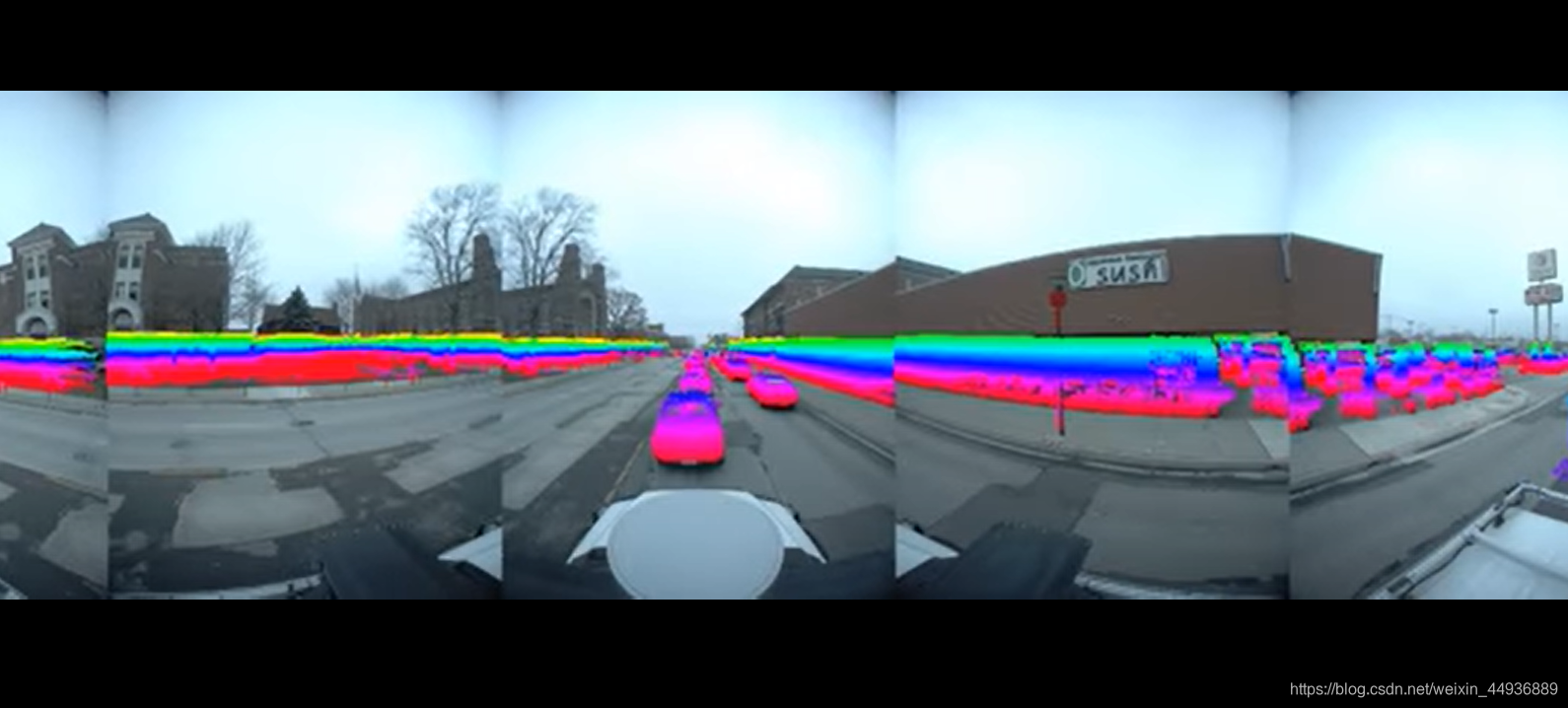
14. Ford Campus Vision and Lidar DataSet:
官网地址:
http://robots.engin.umich.edu/SoftwareData/Ford
论文地址:
http://robots.engin.umich.edu/uploads/SoftwareData/Ford/ijrr2011.pdf
简介:
提供了基于改进的福特F-250皮卡车的自动地面车辆测试台收集的数据集。该车辆配备了专业(Applanix POS LV)和消费者(Xsens MTI-G)惯性测量装置(IMU),Velodyne 3D激光雷达扫描仪,两个推扫式前视Riegl激光雷达和Point Grey Ladybug3全向摄像头系统。在这里,我们提供了这些安装在车辆上的传感器的时间记录数据,这些数据是在2009年11月至12月期间在福特研究园区和密歇根州迪尔伯恩市区附近驾驶车辆时收集的。这些数据集中的车辆路径轨迹包含多个比例尺闭环,对于测试各种最新状态的计算机视觉和SLAM(同时定位和映射)算法应该很有用。
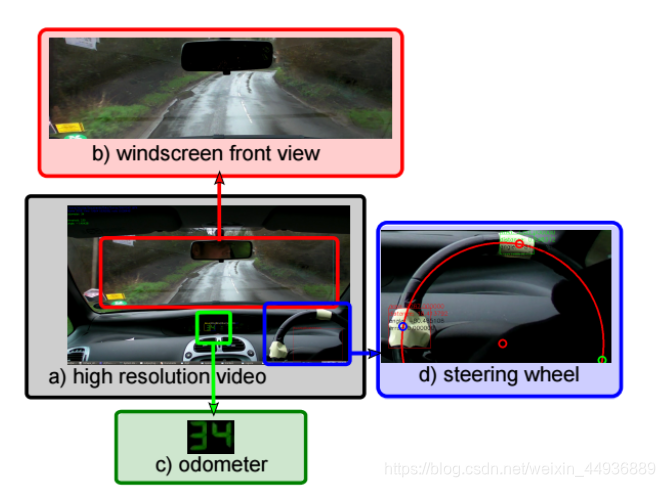
15. DIPLECS Autonomous Driving Datasets:
官网地址:
https://cvssp.org/data/diplecs/
论文地址:
https://www.researchgate.net/publication/331723628
简介:
通过在Surrey乡村周围驾驶的汽车中放置高清摄像头来记录数据集。 该数据集包含大约30分钟的驾驶时间。 视频为1920x1080,采用H.264编解码器编码。 通过跟踪方向盘上的标记来估计转向。 汽车的速度是从汽车的速度表OCR估算的(但不保证方法的准确性)。
16. The SYNTHIA dataset:

官网地址:
http://synthia-dataset.net/
简介:
包括从虚拟城市渲染的照片般逼真的帧集合,并为13个类别提供精确的像素级语义注释:天空,建筑,道路,人行道,围栏,植被,杆,汽车,标志,行人, 骑自行车的人,车道标记。
二、交通标识数据集:
1. LaRA:

官网地址:
http://www.lara.prd.fr/lara
论文地址:
暂无
简介:
巴黎的交通信号灯数据集。
2. KUL Belgium Traffic Sign Dataset:

官网地址:
https://people.ee.ethz.ch/~timofter/traffic_signs/
论文地址:
https://people.ee.ethz.ch/~timofter/publications/Mathias-IJCNN-2013.pdf
简介:
具有10000多个交通标志注释的大型数据集,数千个物理上不同的交通标志。 用8个高分辨率摄像头录制的4个视频序列安装在一辆面包车上,总计超过3个小时,带有交通标志注释,摄像机校准和姿势。 大约16000张背景图片。 这些材料通过GeoAutomation在比利时,佛兰德斯地区的城市环境中捕获。
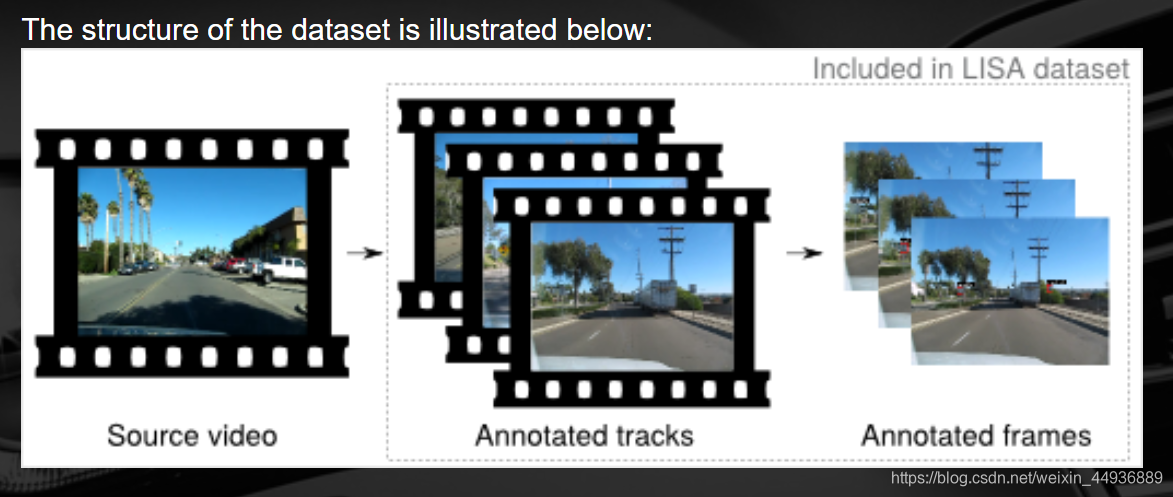
3. LISA Traffic Sign Dataset:
官网地址:
http://cvrr.ucsd.edu/LISA/vehicledetection.html
论文地址:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.926.7532&rep=rep1&type=pdf
简介:
LISA交通标志数据集是一组包含美国交通标志的视频和带注释的帧。它分为两个阶段发布,一个阶段仅包含图片,一个阶段同时包含图片和视频。这些图像现在可用,而完整的数据集正在进行中,并将很快提供。(官网也有车辆和红绿灯检测数据集)
4. Bosch Small Traffic Lights Dataset:

官网地址:
https://hci.iwr.uni-heidelberg.de/content/bosch-small-traffic-lights-dataset
论文地址:
https://ieeexplore.ieee.org/document/7989163/
简介:
该数据集包含13427个分辨率为1280x720像素的摄像机图像,并包含约24000个带注释的交通信号灯。注释包括交通信号灯的边界框以及每个交通信号灯的当前状态。相机图像以原始的12位HDR图像的形式提供,该原始HDR图像是通过红-清晰-蓝色滤镜拍摄的,以及重构的8位RGB彩色图像。RGB图像用于调试,也可以用于训练。
5. CCTSDB:

官网地址:
https://github.com/csust7zhangjm/CCTSDB
论文地址:
https://doi.org/10.3390/a10040127
简介:
CSUST Chinese Traffic Sign Detection Benchmark 中国交通数据集由长沙理工大学综合交通运输大数据智能处理湖南省重点实验室张建明老师团队制作完成。到目前为止,已经上传图像15734张,全部的groundtruth也已经上传。 声明:目前的标注数据只有三大类:指示标志、禁止标志、警告标志。
6. DFG:
官网地址:
https://www.vicos.si/Downloads/DFGTSD
论文地址:
https://arxiv.org/pdf/1904.00649.pdf
简介:
包括 200 个交通标志类别捕获在斯洛文尼亚公路跨越约 7,000 高分辨率图像。图像是由斯洛文尼亚 DFG 咨询公司提供和注释的。RGB 图像是通过安装在一辆汽车上的摄像头获得的,这辆汽车行驶在斯洛文尼亚六个不同的自治市。这些图像数据是在农村和城市地区获得的。从收集的大量数据中,只选择了包含至少一个交通标志的图像。此外,选择是这样进行的,通常有一个显着的场景变化之间的任何一对选定的连续图像。
7. GTSRB:

官网地址:
https://www.kaggle.com/meowmeowmeowmeowmeow/gtsrb-german-traffic-sign
论文地址:
https://www.researchgate.net/publication/224260296_The_German_Traffic_Sign_Recognition_Benchmark_A_multi-class_classification_competition
简介:
德国交通标志基准测试是在2011年国际神经网络联合会议(IJCNN)上举行的多类,单图像分类挑战。具有以下属性:单图像,多类别分类问题;超过40个类别;总共超过50,000张图像;大型逼真的数据库。
8. Mapillary Traffic Sign Dataset:

官网地址:
https://www.mapillary.com/dataset/trafficsign
论文地址:
https://arxiv.org/abs/1909.04422
简介:
10万幅高分辨率图像,其中5.2万幅图像所有交通标志全标注,4.8万幅图像部分标注;
300个交通标志类别,32万+个包围框;
覆盖全球6大洲多个地理位置;
含有天气、季节、时刻、相机和视角等的多样性变化;
该库非常值得做自动驾驶、目标检测等的朋友参考。对于非商业性质的研究是完全免费的,商业应用则需要联系官方获得授权。
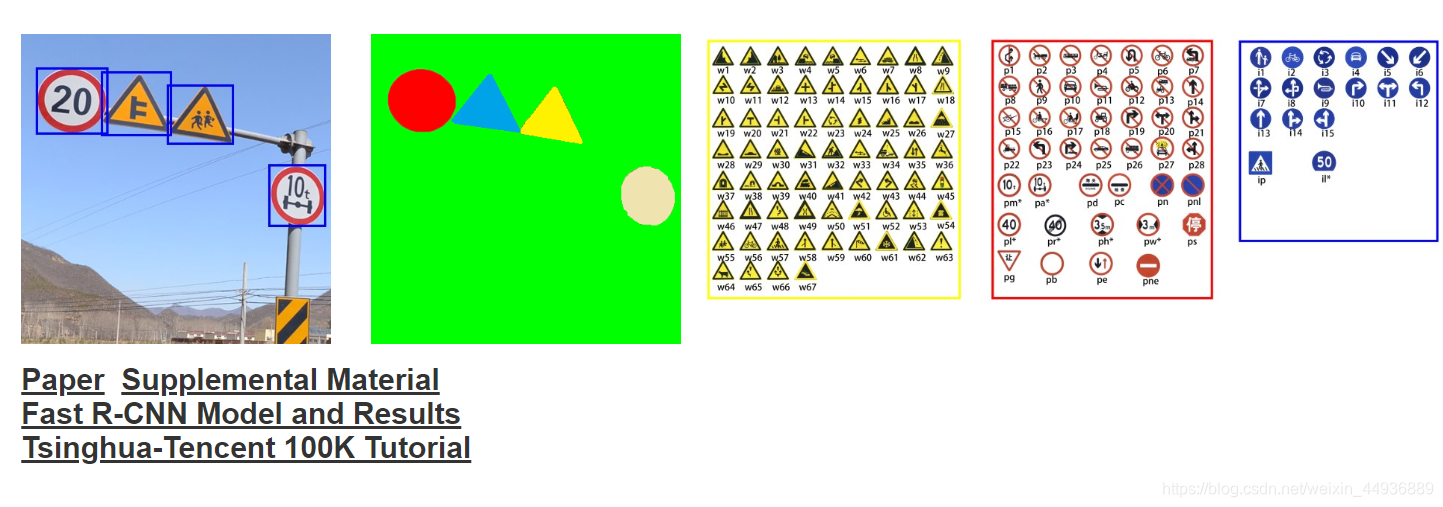
9. Tsinghua-Tencent 100K
官网地址:
https://cg.cs.tsinghua.edu.cn/traffic-sign/tutorial.html
论文地址:
https://cg.cs.tsinghua.edu.cn/traffic-sign/0682.pdf
简介:
清华和腾讯合作,part1 17.8G。号称创建了一个大型交通标志的benchmark,有超过100k的图像数据集,包含了30k的交通标志,这些图像涵盖了照明度和天气变换的差异。源代码和CNN模型都是公开可用的。
三、车辆检测数据集:
1. VOC2012:

官网地址:
https://arleyzhang.github.io/articles/1dc20586/
论文地址:
https://pjreddie.com/media/files/VOC2012_doc.pdf
简介::
PASCAL VOC挑战赛 (The PASCAL Visual Object Classes )是一个世界级的计算机视觉挑战赛, PASCAL全称:Pattern Analysis, Statical Modeling and Computational Learning,是一个由欧盟资助的网络组织。
该挑战的主要目标是从现实场景中的多个视觉对象类别中识别对象(即非预先分割的对象)。从根本上说,这是一个监督学习的问题,因为它提供了一组带有标签的图像的训练。已选择的二十个对象类是:
人:人
动物:鸟,猫,牛,狗,马,绵羊
车辆:飞机,自行车,轮船,公共汽车,汽车,摩托车,火车
室内:瓶子,椅子,餐桌,盆栽,沙发,电视/显示器
有3个主要的对象识别竞赛:分类,检测和分割,动作分类竞赛和ImageNet进行的大规模识别竞赛。此外,在人员布局方面还开展了“品尝”竞赛。
2. MS COCO dataset:
官网地址:
https://cocodataset.org/#home
论文地址:
https://arxiv.org/pdf/1405.0312.pdf
简介::
COCO数据集是一个大型的、丰富的物体检测,分割和字幕数据集。这个数据集以scene understanding为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的segmentation进行位置的标定。图像包括91类目标,328,000影像和2,500,000个label。
COCO数据集有91类,虽然比ImageNet和SUN类别少,但是每一类的图像多,这有利于获得更多的每类中位于某种特定场景的能力,对比PASCAL VOC,其有更多类和图像。
3. UA-DETRAC:

官网地址:
http://detrac-db.rit.albany.edu/
论文地址:
https://arxiv.org/pdf/1511.04136.pdf
简介::
UA-DETRAC是一个具有挑战性的真实世界多目标检测和多目标跟踪基准。该数据集包括在中国北京和天津的24个不同地点使用Cannon EOS 550D相机拍摄的10小时视频。视频以每秒25帧(fps)的速度录制,分辨率为960×540像素。UA-DETRAC数据集中有超过14万个帧,手动注释了8250个车辆,总共有121万个标记的对象边界框。我们还对目标检测和多目标跟踪中的最新方法以及本网站中详述的评估指标进行基准测试。
4. Boxcar:

官网地址:
https://hyper.ai/datasets/9213
论文地址:
https://www.cv-foundation.org/openaccess/content_cvpr_2016/app/S12-56.pdf
简介::
BoxCars116k 数据集由布尔诺理工大学发布,包括 116000 张车辆图像。这些图像皆由多个监控摄像头拍摄,且来自于多个观察点。该数据集可被用作于交通车辆检测等领域的研究。
5. BIT车辆数据集:

官网地址:
http://iitlab.bit.edu.cn/mcislab/vehicledb/
论文地址:
暂无
简介::
数据集包含9,850辆车辆图像。数据集中有16001200和19201080的图像,分别来自于两个不同时间和地点的相机。图像包含光照条件、尺度、车辆表面颜色和视点的变化。由于捕捉延迟和车辆尺寸的原因,一些车辆的顶部或底部没有包含在图像中。在一幅图像中可能有一辆或两辆车,因此每辆车的位置都是预先注释的。该数据集还可用于评价车辆检测的性能。数据集中的所有车辆被分为六类:公共汽车、微型客车、小型货车、轿车、SUV和卡车。每车型车辆数量分别为558、883、476、5922、1392、822辆。
6. Vehicle Image Dataset:

官网地址:
https://www.gti.ssr.upm.es/data/Vehicle_database.html
论文地址:
暂无
简介::
该数据库包含3425 张车辆后方图像从不同的角度拍摄,并从不包含车辆的道路序列中提取了3900张图像。选择图像以使车辆类别的代表性最大化,这自然包括高可变性。
7. Nepalese Vehicles:

官网地址:
https://github.com/sdevkota007/vehicles-nepal-dataset
论文地址:
暂无
简介::
该图像数据集是我最后一年的本科项目“ 使用图像处理进行车辆检测和道路交通拥堵测绘”的一部分。总共30部交通视频,每部约。从加德满都的不同街道拍摄了4分钟,并从视频帧中手动裁剪了车辆的图像。
8. TME Motorway Dataset:

官网地址:
http://cmp.felk.cvut.cz/data/motorway/
论文地址:
http://cmp.felk.cvut.cz/data/motorway/paper/itsc2012.pdf
简介::
由28个视频片段组成,总计27分钟的视频,该数据集包括30,000多个带有车辆注释的帧。
关注我的公众号:
感兴趣的同学关注我的公众号——可达鸭的深度学习教程:


