
- 1网络协议之UDP数据包_udp包
- 2Oracle重启卡在mounted,Oracle下启动与关闭详解
- 3深度学习入门2:自制框架DeZero_深度学习入门2:自制框架 pdf
- 4模型运行报 RuntimeError: CUDA out of memory. Tried to allocate 384.00 MiB (GPU 0; 31.75 GiB
- 5超详细!Opencv手势控制音量!附源码!
- 6JAVAEE---javaweb和SpringBoot_java spring boot javaee
- 7Maven配置仓库_maven仓库配置
- 8Nginx管理配置中多种变量学习
- 9【硬币计数】基于matlab形态学硬币计数【含Matlab源码 393期】_采用形态学方法对硬币图进行进一步处理,得到正确的统计结果,
- 10网页3D编辑器Stone教程:如何实现路径动画_drawstone3
HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convolutions
赞
踩
论文:https://arxiv.org/abs/2207.14284
代码:https://github.com/raoyongming/HorNet
HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convolutions
摘要
近年来,vision transformer在基于点积自注意(dot-product self-attention)的空间建模机制驱动下,在各种任务中取得了巨大的成功。在本文中,我们展示了vision transformer背后的关键成分,即输入自适应(input-adaptive)、远程(long-range)和高阶空间交互(high-order spatial interactions),也可以通过基于卷积的框架有效地实现。我们提出了递归门控卷积(gnConv),它执行与门控卷积和递归设计的高阶空间交互。新的运算具有高度的灵活性和可定制性,它兼容各种卷积的变体,并将自注意的二阶相互作用扩展到任意阶,而不增加大量的计算量。gnConv可以作为即插即用模块来改进各种vision transformer和基于卷积的模型。在此基础上,我们构建了一个新的通用视觉骨干家族,命名为HorNet。在ImageNet分类、COCO对象检测和ADE20K语义分割方面的大量实验表明,在总体架构和训练配置相似的情况下,HorNet的表现明显优于Swin transformer和ConvNeXt。对于更多的训练数据和更大的模型尺寸,HorNet也显示出良好的可扩展性。除了在视觉编码器中的有效性,我们还表明gnConv可以应用于任务特定的解码器,并不断提高密集预测性能,以更少的计算。我们的结果表明,gnConv可以是一个新的基本模块的视觉建模,有效地结合了vision transformer和cnn的优点。代码可从https://github.com/raoyongming/HorNet获得。
总结摘要:
本文总结了vision transformer成功的关键因素是通过自注意力操作实现输入自适应、远程和高阶空间交互的空间建模新方法,也可以通过基于卷积的框架有效地实现,前人工作已经尝试过输入自适应、远程的方法迁移至CNN中,目前对高阶空间交互的方法没有尝试过,为此本文展示了所有三个关键成分都可以使用基于卷积的框架有效地实现。故而提出了gnconv这个即插即用的模块。该模块通过门控卷积和递归设计实现高阶空间相互作用。而不是简单地模仿成功的设计在自注意力。
1 introduction
自AlexNet[29]在过去十年中引入以来,卷积神经网络(CNN)推动了深度学习和计算视觉领域的显著进步。cnn有许多很好的特性,使它们自然适合广泛的视觉应用。翻译等方差为主要视觉任务引入了有用的归纳偏差,并使不同输入分辨率之间的可转移性。高度优化的实现使得它在高性能gpu和边缘设备上都非常高效。架构的演变[30,29,46,47,22,23,48]进一步增加了它在各种视觉任务中的受欢迎程度。
基于transformer的体系结构[16,49,39]的出现极大地挑战了cnn的主导地位。通过结合CNN架构中一些成功的设计和新的自我注意机制,视觉transformer在各种视觉任务中表现出领先的性能,如图像分类[12,39,45],目标检测[64,38],语义分割[6,8]和视频理解[58,18]。是什么让视觉transformer比cnn更强大?通过学习视觉上的新设计,对CNN的架构做了一些改进[40]对采用vision Transformer元架构改进CNN进行了深入的研究,提出使用较大的7×7内核构建现代CNN。[43]和[14]建议使用更大的内核来分别学习全局过滤器和31×31卷积的长期关系。[20]表明,输入自适应权值在视觉变形器中发挥着关键作用,并在具有动态卷积的Swin变形器中取得了类似的性能[4,26]。然而,尚未从高阶空间交互的角度分析点积自我注意在视觉任务中的有效性。
由于非线性,深度模型中两个空间位置之间存在复杂的高阶相互作用,而自我注意等动态网络的成功表明,建筑设计引入的显式高阶空间相互作用有利于提高视觉模型的建模能力。如图1所示,平面卷积运算没有明确考虑空间位置(即红色特征)与其邻近区域(即浅灰色区域)之间的空间相互作用。增强的卷积运算,如动态卷积[4,26,20],通过生成动态权值引入显式的空间相互作用。变形金刚[51]中的点积自我注意操作由两个连续的空间相互作用组成,通过在查询、键和值之间执行矩阵乘法。视觉建模基本操作的发展趋势表明,提高空间交互的顺序可以提高网络容量。
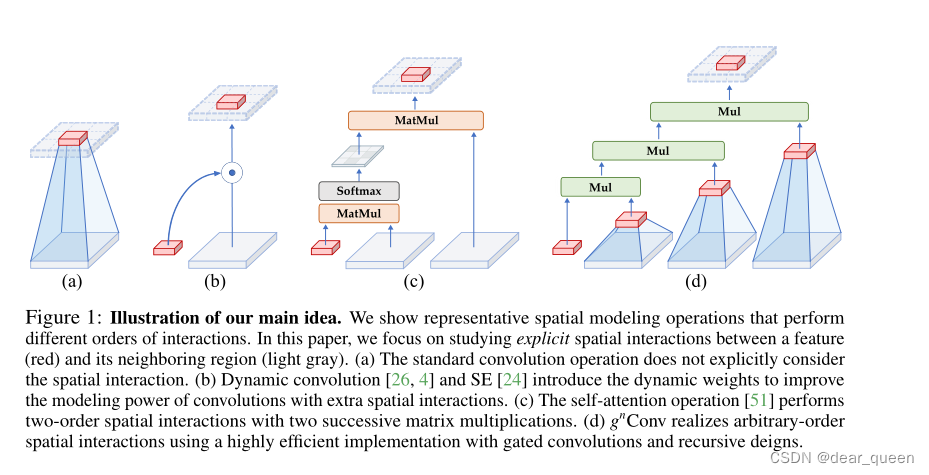
在本文中,我们总结了视觉transformer成功的关键因素是通过自注意力操作实现输入自适应、远程和高阶空间交互的空间建模新方法。虽然之前的工作已经成功地将视觉变形器的元架构[40,20,43,14]、输入自适应权值生成策略[20]和大范围建模能力[43,14]移植到CNN模型中,但尚未研究高阶空间交互机制。我们展示了所有三个关键成分都可以使用基于卷积的框架有效地实现。我们提出了递归门控卷积(gnConv),通过门控卷积和递归设计实现高阶空间相互作用。而不是简单地模仿成功的设计在自我关注,gnConv有几个额外的有利的特性:
1)高效。基于卷积的实现避免了自我注意的二次复杂度。在执行空间交互过程中逐步增加通道宽度的设计也使我们能够实现具有有限复杂性的高阶交互;
2)可扩展。我们将自注意中的二阶相互作用扩展到任意阶,进一步提高了建模能力。
由于我们不对空间卷积的类型做假设,gnConv兼容各种核大小和空间混合策略,如[43,14];
3) Translation-equivariant。gnConv完全继承了标准卷积的平移等方差,在主要视觉任务中引入了有益的诱导偏差,避免了局部注意带来的不对称[39,32]。
总结一下特性
1.具备和卷积一样逐步增加通道宽度的方法,该设计相较于完全使用self-attention式的方法降低了一定的复杂度;
2.self-attention是关注于二阶相互作用,本文所提方法可兼容不同尺寸的核实现高阶空间交互,可具有更好的自适应性。
3.gnconv继承了卷积的平移不变性,具备卷积的平移不变性优势,同时加入了诱导偏差,可平衡transformer和CNN一个关注全局一个关注局部的问题。
在本文中,我们总结了视觉transformer成功的关键因素是通过自我注意操作实现输入自适应、远程和高阶空间交互的空间建模新方法。虽然之前的工作已经成功地将视觉变形器的元架构[40,20,43,14]、输入自适应权值生成策略[20]和大范围建模能力[43,14]移植到CNN模型中,但尚未研究高阶空间交互机制。我们展示了所有三个关键成分都可以使用基于卷积的框架有效地实现。
| 我们提出了递归门控卷积(gnConv),通过门控卷积和递归设计实现高阶空间相互作用。而不是简单地模仿成功的设计在自我关注 |
,gnConv有几个额外的有利的特性:1)高效。基于卷积的实现避免了自我注意的二次复杂度。
在执行空间交互过程中逐步增加通道宽度的设计也使我们能够实现具有有限复杂性的高阶交互;2)可扩展。我们将自注意中的二阶相互作用扩展到任意阶,进一步提高了建模能力。
由于我们不对空间卷积的类型做假设,gnConv兼容各种核大小和空间混合策略,如[43,14];3) Translation-equivariant。gnConv完全继承了标准卷积的平移等方差,在主要视觉任务中引入了有益的诱导偏差,避免了局部注意带来的不对称[39,32]。
在gnConv的基础上,我们构建了一个新的通用视觉骨干家族——HorNet。为了验证我们模型的有效性,我们在ImageNet分类[13]、COCO对象检测[36]和ADE20K语义分割上进行了大量的实验[65]。使用相同的7×7内核/窗口和类似的整体架构和训练配置,HorNet比Swin表现更好。
和ConvNeXt在所有不同复杂程度的任务中都有很大的优势。使用全局内核大小[43]可以进一步扩大这个差距。在训练数据较多、模型尺寸较大的情况下,大黄蜂也表现出良好的可扩展性,ImageNet- 22k预训练时,在ImageNet上top-1准确率达到87.7%,在ADE20K值上mIoU达到54.6%,在COCO值上边框AP达到55.8%。除了在视觉编码器中应用gnConv之外,我们还进一步测试了我们设计在特定任务解码器上的通用性。
我们将gConv加入到广泛应用的特征融合模型FPN[34]中,开发出HorFPN来建模不同层次特征的高阶空间关系。我们观察到,HorFPN还可以以较低的计算成本持续改进各种密集预测模型。我们的结果表明,gnConv可以是一个有前途的替代自我注意的视觉建模,并有效地结合了视觉变形器和cnn的优点。
2. related work
vision transformer Transformer架构[51]最初是为自然语言处理任务设计的。Dosovitskiy等人[16]表明,仅由Transformer块和一个补丁嵌入层构建的视觉模型也可以达到与CNNs竞争的性能,许多新的模型被提出来修改基于Transformer的架构,使其更适合各种视觉任务[39,53,54,9,60]。与[16]的原始设计不同,最先进的视觉变形器通常采用类似cnn的层次结构,将所有patch之间的全局自注意变为局部自注意,以避免二次元复杂度。
在本文中,我们遵循了之前分层vision transformer[39]的整体架构,并将self-attention子层替换为我们提出的gnConv,以便与之前基于变压器的模型进行公平的比较。
convolution-based models 受到近期vision transformer成功的启发,多篇论文提出采用transformer风格的架构和大内核尺寸的空间卷积来提高cnn的性能。**Han等人[20]**用大内核动态卷积替换了Swin变形金刚中的窗口自注意,取得了更好的性能。**GFNet[43]**建议执行全局空间交互,就像在频域使用全局滤波器的视觉变形器一样,这相当于使用全局内核大小和圆形填充的深度卷积。**ConvNeXt[40]**深入分析了最近的视觉变形金刚的设计,并提出了一个具有7×7深度卷积的强卷积模型。**RepLKNet[14]**使用非常大的内核(到31×31)探索CNN模型,表现出良好的可扩展性。
VAN[19]和FocalNet[59]采用门控卷积进行输入自适应注意,分别采用大核扩张卷积和多次连续3×3卷积产生权值。以前的工作主要集中在元架构[61]、大核设计和输入自适应权值,通过学习视觉变形器来改进cnn。本文提出了一种新的高阶空间注意的视角来分析视觉变形器的优点。我们表明,提出的HorNet结合了cnn和vision transformer的优势,是各种视觉任务的更好的架构。
小结一下:
这些论文最好都去研读下,可以更好的理解本文并找到新的论文创新点思路;
混合模型。将视觉变压器与cnn相结合开发混合架构是解决各种视觉识别问题的新方向。最近,人们做出了一些努力,将这两种类型的块体整合成一个统一的模型,采用顺序[12,27,62,57]或并行[42,11]设计。许多增强视觉变形器还在基本构造块中使用轻量级卷积来有效地捕获相邻模式[15,54,17]或放松自我注意的二次复杂度[9,53,18]。与这些混合模型不同的是,我们的目标是开发一个无自我注意的模型,同时结合视觉变形器和cnn的有利特性。
3. method
3.1 gnConv: Recursive Gated Convolutions
在本节中,我们将介绍gnConv,一个实现长期和高阶空间相互作用的高效操作。gnConv是用标准的卷积、线性投影和elementwise乘法构建的,但具有与自我注意类似的输入自适应空间混合功能。
带门控卷积的输入自适应交互。视觉变形器最近的成功主要依赖于对视觉数据中空间相互作用的正确建模。与CNNs简单地使用静态卷积核来聚合相邻特征不同,vision transformer应用多头自我注意来动态生成权重来混合空间标记。然而,自注意输入量的二次元复杂度极大地阻碍了视觉变形器的应用,特别是在需要更高分辨率特征图的分割和检测等下游任务中。在这项工作中,我们不像以前的方法那样降低自我注意的复杂性[39,9,52],而是寻求一种更高效、更有效的方式,通过卷积和全连接层等简单操作来执行空间相互作用。
该方法的基本操作是门控卷积(gConv)。设x∈RHW ×C为输入特征,则门控卷积y =gConv(x)的输出可以写成:
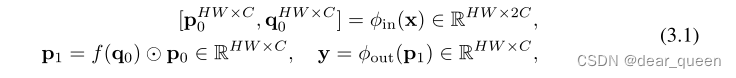
其中φin、φout为进行信道混合的线性投影层,f为深度卷积。注意p(i,c) 1 = p j∈Ωi wci→jq(j,c) 0 p(i,c) 0,其中Ωi是以i为中心的局部窗口,w表示f的卷积权值。因此,上述公式通过元素乘显式引入了相邻特征p(i) 0和q(j) 0之间的相互作用。
当每个p(i) 0与其相邻特征q(j) 0只相互作用一次时,我们认为gConv中的相互作用为一阶相互作用。
递归门控的高阶交互。在与gConv实现高效的一阶空间相互作用后,我们设计了递归门控卷积gnConv,通过引入高阶相互作用进一步增强模型容量。形式上,我们首先用φin得到一组投影特征p0和{qk}n−1 k=0:
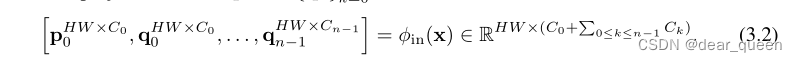
然后递归地执行门控卷积
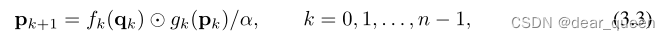
我们将输出放大1/α以稳定训练。{fk}是一组深度卷积层,{gk}用于匹配维度的不同顺序:
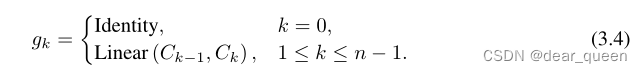
最后,我们将最后一个递归步骤qn的输出输入到投影层φout,得到gnConv的结果。由递归式(3.3)可以看出,pk的相互作用阶数每阶递增1。因此,我们可以看到gnConv实现了n阶空间相互作用。值得注意的是,我们只需要一个f就可以将特征{qk}n−1 k=0拼接在一起进行深度卷积,而不是像式(3.3)那样每递归一步都要计算卷积,这样可以进一步简化实现,提高gpu上的效率。为了保证高阶交互不会引入过多的计算开销,我们将每个阶的通道维数设为:
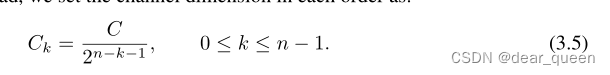
这种设计表明我们以一种从粗到细的方式执行交互,其中较低的阶数用更少的通道计算。此外,φin(x)的通道维数恰好为2C,即使n增加,总失败次数也可严格有界。可以证明(见附录A):
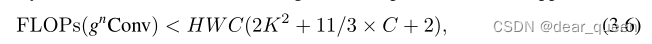
其中K为深度卷积的核大小。因此,我们的gnConv以类似卷积层的计算成本实现了高阶交互。
class gnconv(nn.Module): def __init__(self, dim, order=5, gflayer=None, h=14, w=8, s=1.0): super().__init__() self.order = order self.dims = [dim // 2 ** i for i in range(order)] self.dims.reverse() self.proj_in = nn.Conv2d(dim, 2*dim, 1) if gflayer is None: self.dwconv = get_dwconv(sum(self.dims), 7, True) else: self.dwconv = gflayer(sum(self.dims), h=h, w=w) self.proj_out = nn.Conv2d(dim, dim, 1) self.pws = nn.ModuleList( [nn.Conv2d(self.dims[i], self.dims[i+1], 1) for i in range(order-1)] ) self.scale = s print('[gnconv]', order, 'order with dims=', self.dims, 'scale=%.4f'%self.scale) def forward(self, x, mask=None, dummy=False): B, C, H, W = x.shape fused_x = self.proj_in(x) pwa, abc = torch.split(fused_x, (self.dims[0], sum(self.dims)), dim=1) dw_abc = self.dwconv(abc) * self.scale dw_list = torch.split(dw_abc, self.dims, dim=1) x = pwa * dw_list[0] for i in range(self.order -1): x = self.pws[i](x) * dw_list[i+1] x = self.proj_out(x) return x

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
与大内核卷积的长期交互。视觉变形器和传统cnn的另一个区别是感受野。传统的CNNs[46,22]通常通过整个网络使用3×3卷积,而视觉变形器则在整个特征图[16,49]或相对较大的局部窗口内(如7×7)计算自我注意。视觉变形金刚的大接受域使其更容易捕获长期依赖关系,这也是公认的视觉变形金刚的关键优势之一。受此设计的启发,最近有一些努力将大核卷积引入到CNNs中[14,40,43]。为了使我们的gnConv能够捕获长期交互,我们采用了两个深度卷积f的实现:
•7×7 Convolution. 7×7是Swin变形金刚[39]和ConvNext[40]的默认窗口/内核大小。对[40]的研究表明,该内核大小在ImageNet分类和各种下游任务上具有良好的性能。我们按照这个配置来公平地与视觉变形金刚和现代cnn的代表作品进行比较。
•全局过滤器(GF)。GF层[43]将频域特征与可学习的全局滤波器相乘,相当于一个具有全局核大小和圆形填充的空间域卷积。我们使用了GF层的改进版本,其中一半的通道使用全局过滤器处理,另一半使用3×3深度卷积处理,并且只在后期使用GF层来保留更多的局部细节。
视觉模型中的空间相互作用。我们从空间相互作用的角度回顾了一些代表性的视觉模型设计,如图1所示。具体来说,我们感兴趣的是特征xi与其相邻特征xj, j∈Ωi之间的相互作用。通过使用[31,1]中用于解释交互效应(IE)的工具,我们在附录b中直观地分析了显式空间交互的顺序。我们的分析从一个新的视角揭示了视觉变形金刚与之前架构的一个关键区别,即视觉变形金刚在每个基本块中都有更高阶的空间交互。这一结果启发我们探索一种能够实现更高效、更有效的两阶以上空间相互作用的建筑。如上所述,我们提出的gnConv可以实现具有有界复杂度的任意阶交互。同样值得注意的是,与宽度[63]和深度[22]等深度模型中的其他缩放因子类似,单纯增加空间相互作用的阶数而不考虑模型的总体容量并不会得到很好的权衡[48]。本文在分析设计良好的模型的空间交互顺序的基础上,重点研究了一种更强的可视化建模体系结构。我们相信对高阶空间相互作用进行更全面、更正式的讨论将是未来的一个重要方向。
与点积自我注意的关系。虽然我们的gnConv的计算很大程度上不同于点积的自我注意,我们将表明,gnConv也完成了输入自适应空间混合的目标。设M为多头自我注意(MHSA)得到的注意矩阵,由于混合权值可能会随着信道的不同而不同,我们将M写成(mcij)。位置i第c个信道的空间混合结果(在最终信道混合投影之前)为
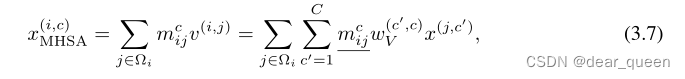
式中wV为V投影层的权值。注意点积运算得到的mij包含一阶相互作用。另一方面,gnConv的输出(在φout之前)可以写成
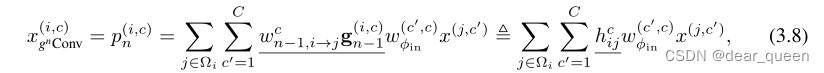
其中wn−1是fn−1的卷积权值,wφin是φin的线性权值,gn−1 = gn−1(pn−1)是pn−1的投影。从式(3.8)的公式中,我们发现我们的gnConv也实现了以{hcij}为权值的输入自适应空间混合。由于hij是由pn−1计算得到的,其中pn−1包含n - 1级相互作用,因此我们可以把gnConv看作是空间混合权的自注意的扩展。因此,我们的gnConv可以更好地模拟更复杂的空间相互作用。
图2总结了gnConv和我们的实现的细节。
3.2模型架构
HorNet。gnConv可以代替视觉变形金刚[49,39]或现代CNNs[40]中的空间混合层。我们遵循与[53,39]相同的元架构来构建HorNet,其中基本块包含一个空间混合层和一个前馈网络(FFN)。
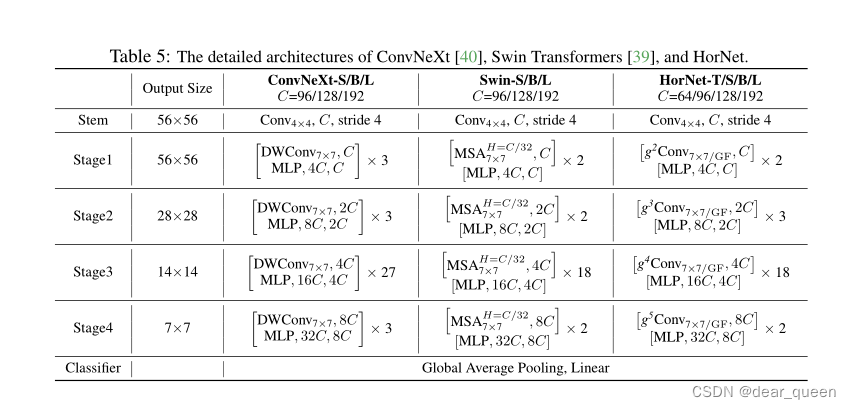
根据模型大小和gnConv中深度卷积fk的实现,我们有两个系列的模型变体,分别是HorNet-T/S/B/L7×7和HorNet-T/S/B/LGF。我们考虑流行的Swin Transformer[39]和ConvNeXt[40]作为视觉变压器和CNN基线,因为我们的模型是基于卷积框架实现的,同时具有像视觉变压器一样的高阶交互。为了与基线进行公平的比较,我们直接跟踪Swin transformer - s /B/L[39]块的数量,但在阶段2中插入一个额外的块,以使整体复杂度接近,导致所有模型变体的每个阶段都有[2,3,18,2]块。我们简单地调整通道的基本数量C来构建不同大小的模型,并按照惯例将4个阶段的通道数量设置为[C, 2C, 4C, 8C]。对于HorNet-T/S/B/L,我们分别使用C = 64、96、128、192。我们将每个阶段的交互顺序(即gnConv中的n)默认设置为2、3、4、5,这样,最粗顺序C0的通道在不同阶段是相同的。
HorFPN。除了在视觉编码器中使用gnConv,我们发现我们的gnConv可以作为标准卷积的一个增强的替代方案,在广泛的基于卷积的模型中考虑高阶空间相互作用。因此,我们用gnConv代替FPN[35]中的空间卷积来进行特征融合,以改善下游任务的空间交互。具体来说,我们将不同金字塔层次的特征融合后,加入我们的gnConv。对于对象检测,我们将自顶向下路径后的3×3卷积替换为每一层的gnConv。对于语义分割,我们只需用gnConv替换多级特征映射拼接后的3×3卷积,因为最终的结果是直接从这个拼接特征预测出来的。
根据fk的选择,我们还有两个实现HorFPN7×7和HorFPNGF。
4 实验
我们进行了大量的实验来验证我们方法的有效性。我们给出了ImageNet[13]上的主要结果,并将它们与各种体系结构进行了比较。我们还在常用的语义分割基准ADE20K[65]和对象检测数据集COCO[36]上对我们的模型在下游密集预测任务上进行了测试。最后,我们对我们的设计进行了烧蚀研究,并分析了gnConv在各种模型上的有效性。
4.1 ImageNet分类
设置。我们在广泛使用的ImageNet[13]数据集上进行图像分类实验。我们使用标准的ImageNet-1K数据集,按照常规做法训练HorNet-T/S/B模型。
为了与之前的工作进行公平的比较,我们直接使用[40,39,49]的训练配置来训练我们的模型。我们用224 × 224输入对模型进行了300次的训练。为了评估我们设计的缩放能力,我们在ImageNet-22K数据集上进一步训练HorNet-L模型,该数据集包含超过10倍的图像和更多的类别。模型经过90个epoch的训练,然后在[40]之后的30个epoch对ImageNet-1K进行微调。更多的细节可以在附录C中找到。
表1:ImageNet分类结果。我们将我们的模型与具有类似失败和参数的最先进的视觉变形器和cnn进行比较。我们报告了ImageNet验证集上排名前1的准确性,以及参数和失败次数。我们还展示了Swin transformer的改进,它具有与我们的模型相似的总体架构和训练配置。“↑384”表示该模型在384×384图像上微调了30个epoch。我们的模型用灰色标出。
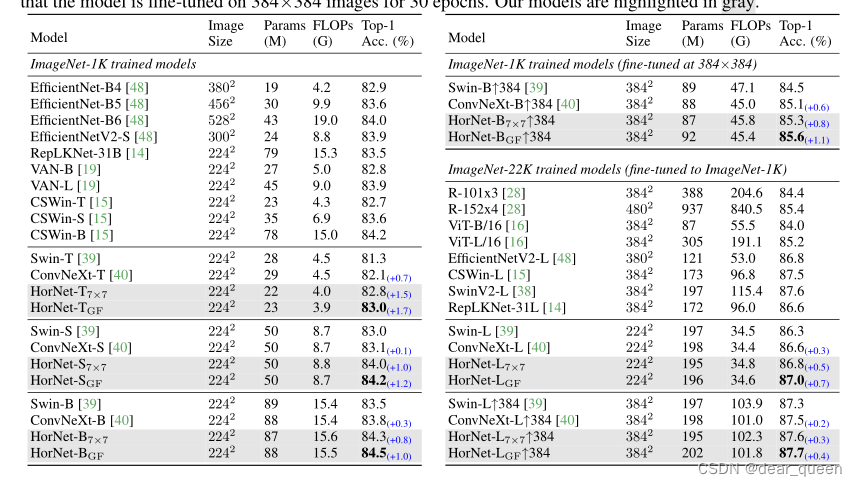
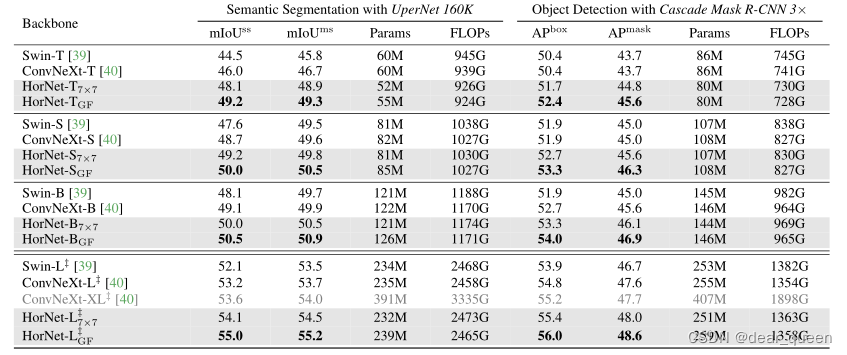
表2:不同主干的目标检测和语义分割结果。我们使用supernet[56]进行语义分割,使用Cascade Mask R-CNN[2]进行目标检测。‡表示模型在ImageNet-22K上进行了预训练。对于语义分割,我们报告了单尺度(SS)和多尺度(MS) mIoU。对于ImageNet-1K预训练模型和ImageNet-22K预训练模型,FLOPs的图像大小分别为(2048,512)和(2560,640)。对于对象检测,我们报告方框AP和掩码AP。失败是根据输入大小(1280,800)来测量的。我们的模型用灰色标出。
结果。表1总结了我们ImageNet分类实验的结果。我们看到,我们的模型实现了非常有竞争力的性能与最先进的视觉变形金刚和cnn。值得注意的是,大黄蜂超过了Swin变形金刚和ConvNeXt,这有类似的整体架构和训练配置的各种模型大小和设置的健康边缘。
尽管最近一些混合架构的工作[33,37,55]或在模型宽度和深度上更仔细的设计,在ImageNet-1K上取得了比HorNet更好的性能,我们认为我们的模型也将受益于这些技术,获得更好的性能。我们的模型也适用于更大的图像分辨率、更大的模型尺寸和更多的训练数据。这些结果清楚地证明了我们设计的有效性和通用性。
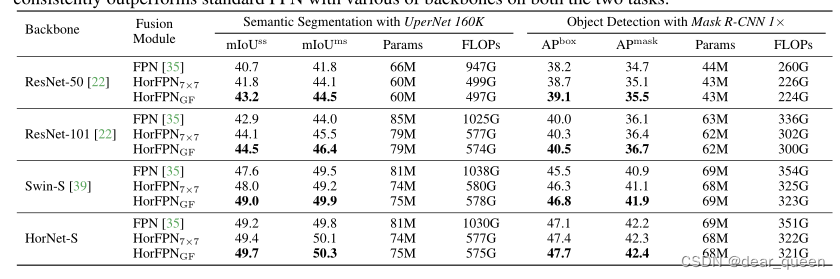
表3:HorFPN与标准FPN在不同骨干上的比较。我们使用supernet 160K和Mask R-CNN 1× schedule分别进行语义分割和目标检测。我们发现,在这两个任务上,我们的HorFPN始终优于具有各种骨干的标准FPN。
4.2 .密集预测任务
大黄蜂用于语义分割。我们使用常用的UperNet[56]框架在ADE20K[65]数据集上评估我们的HorNet用于语义分割任务。使用全局批大小为16的AdamW[41]优化器对所有模型进行160k次迭代训练。ImagNet-1k (HorNet-T/S/B)预训练模型训练时的图像大小为512 × 512, ImageNet-22K预训练模型(HorNet-L)训练时的图像大小为640 × 640。结果总结在表2的左侧,其中我们报告了验证集上的单尺度(SS)和多尺度(MS) mIoU。我们的HorNet7×7和HorNetGF模型都优于Swin[39]和ConvNeXt[40]模型,具有相似的模型大小和失败。具体来说,HorNetGF模型在单尺度mIoU中取得了比HorNet7×7和ConvNeXt系列好很多的结果,这表明由全局过滤器捕获的全局交互有助于语义分割。值得注意的是,我们发现HorNet-L7×7and HorNet-LGF的失败次数甚至比ConvNeXt-XL少25%。这些结果清楚地证明了我们的HorNet在语义分割上的有效性和可扩展性。
大黄蜂用于目标检测。我们还在COCO[36]数据集上评估我们的模型。我们采用cascade Mask R-CNN框架[21,2]使用HorNet-T/S/B/L骨干进行目标检测和实例分割。在Swin[39]和ConvNeXt[40]之后,我们使用3×多尺度训练计划。表2的右边部分比较了我们的大黄蜂模型和Swin/ConvNeXt模型的框AP和掩码AP。同样,我们展示了我们的HorNet模型在盒AP和掩码AP上都取得了比Swin/ConvNeXt同类产品一致且显著更好的性能。与ConvNeXt相比,HorNetGF系列获得了+1.2 ~ 2.0盒AP和+1.0 ~ 1.9掩码AP。
再次,我们的大型模型HorNet-L7×7和HorNetGF可以超过ConvNeXt-XL,这进一步验证了在更大的模型尺寸和更大的预训练数据集下良好的可转移性。
HorFPN用于密集预测。我们现在展示了gnConv的另一个应用,即作为一个更好的融合模块,可以更好地捕捉密集预测任务中不同层次特征之间的高阶相互作用。具体来说,我们直接修改了supernet[56]和Mask R-CNN[21]中3.2节描述的FPN[35],分别用于语义分割和目标检测。我们在表3中展示了结果,其中比较了我们的HorFPN和标准FPN在不同主干网上的性能,包括ResNet-50/101 [22], Swin-S[39]和HorNet-S7×7。
对于语义分割,我们发现我们的HorFPN可以显著减少失败(约50%),同时实现更好的验证mIoU。对于对象检测,我们的HorFPN在不同主干线上的盒AP和掩码AP性能也优于标准FPN,大约减少30G的FLOPs。
此外,我们观察到HorFPNGF始终比HorFPN7×7更好,这表明在融合层次特征时全局交互也很重要。
4.3分析。
我们提供了详细的消融研究gnConv和我们的大黄蜂在表4。我们首先研究了表4a中我们大黄蜂的模型设计。我们的基线([])是通过简单地将self-attention替换为7×7在Swin-T[39]中的深度卷积得到的。我们首先证明**SE[24]和n = 1 (g{1,1,1,1}Conv)的gnConv比基线模型[]更好**,g{1,1,1,1}Conv稍好一些。然后,我们对每个阶段的相互作用阶n进行烧蚀,发现:(1)如果在4个阶段共享n,精度将随着n的增大而增加,但是n = 4时,在82.5处饱和;(2)逐步增加的阶数(g{2,3,4,5}Conv)可以进一步提高精度。通过调整网络的深度和宽度(HorNet-T7×7),并对深度卷积(HorNet-TGF)应用Global Filter[43],我们最终的模型建立在g{2,3,4,5}Conv上。这些结果清楚地表明,我们的gnConv是一个有效的和可扩展的操作,可以更好地捕捉高阶空间相互作用比自我注意和深度卷积。
表4:gnConv应用于其他模型/手术的消融研究及结果。我们在(a)中提供了我们设计的烧蚀研究。[*]表示我们模型的基线。基线和最终模型用灰色突出显示。在(b)和©中,我们将提出的gnConv应用于具有类似复杂程度的各向同性模型,包括ViT/DeiT-S[16,49]和其他空间混合操作,包括3×3深度卷积和3×3池,在[61]中使用。
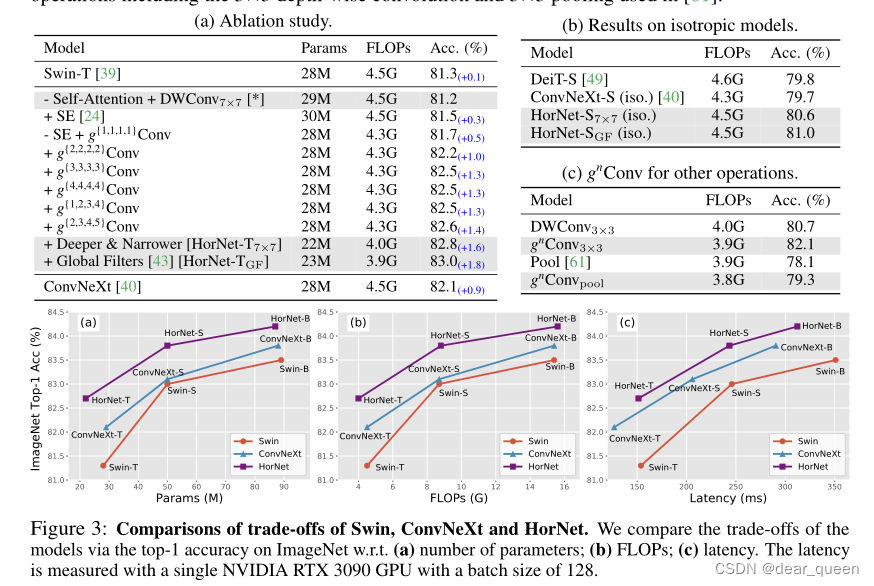
gnConv用于各向同性模型。我们还评估了gnConv在各向同性结构上(具有恒定的空间分辨率)。我们用gnConv替换DeiT-S[49]中的自我注意,并将块数调整为13,得到各向同性HorNet-S7×7和HorNet-SGF。我们在表4b中比较了DeiT-S、各向同性ConvNeXt-S和各向同性HorNet-S。虽然各向同性的ConvNeXt-S不能改善DeiT-S,但我们的各向同性大黄蜂已经大大超过了DeiT-S。这些结果表明,与普通卷积相比,我们的gnConv能够更好地实现自我注意功能,具有更好的模拟复杂空间相互作用的能力。
gnConv用于其他操作。为了进一步证明gnConv的通用性,我们使用3×3深度卷积和3×3池[61]作为gnConv的基本操作。表4c中的结果表明,gnConv还可以大大改善这两个操作,这表明我们的gnConv在配备一些更好的基本操作时可能更强大。
Accuracy-complexity权衡。我们在图3中可视化了Swin、ConvNeXt和HorNet系列的精度-复杂性权衡。为了公平的比较,我们将输入图像的大小固定为224 × 224,并使用HorNet7×7,这样所有的比较模型都是基于7×7本地窗口。我们看到,在模型大小、失败和GPU延迟方面,大黄蜂可以实现比代表性视觉变形金刚和现代cnn更好的权衡。
局限性。虽然HorNet显示了更好的整体延迟-精度权衡,但我们注意到,在GPU上类似的失败情况下,HorNet比ConvNeXt更慢,这可能是由于执行高阶交互的更复杂的设计造成的。我们认为,为高阶空间相互作用开发一种更加硬件友好的操作是一个有趣的未来方向来改进我们的工作。
5. 总结
我们提出了一种递归门控卷积(gnConv),通过门控卷积和递归设计实现高效、可扩展、平移等价的高阶空间相互作用。
gnConv可以在各种视觉变形器和基于卷积的模型中代替空间混合层。在操作的基础上,我们构建了一个新家族的通用视觉大黄蜂骨干。大量的实验证明了gnConv和HorNet在常用的视觉识别基准上的有效性。我们希望我们的尝试可以启发未来进一步探索视觉模型中的高阶空间相互作用。
参考
CNN具有平移不变性和局部性,缺乏全局建模长距离建模的能力,引入自然语言处理领域的框架Transformer来形成CNN+Transformer架构,充分两者的优点,提高目标检测效果,本人经过实验,对小目标以及密集预测任务会有一定的提升效果。视觉 Transformers 的最新进展在基于点积 self-attention 的新空间建模机制驱动的各种任务中取得了巨大成功。递归门控卷积(gnConv),它通过门控卷积和递归设计执行高阶空间交互。新操作具有高度的灵活性和可定制性,它兼容各种卷积变体,并将自注意力中的二阶交互扩展到任意阶,而不会引入大量额外的计算。gnConv 可以作为一个即插即用的模块来改进各种视觉 Transformer 和基于卷积的模型。

