
- 1SIM800/SIM900/SIM7000/SIM7600底层操作接口_句柄方式完全分离通信底层_sim900 at cipsr simcom_gprs.c
- 2聊聊自动驾驶和人工智能_自动驾驶与人工智能的关系
- 3微信小程序流浪动物救助领养平台springboot-JAVA【数据库设计、论文、源码、开题报告】_国外关于基于微信小程序宠物救助系统的研究
- 4LLMs之Alpaca:《Alpaca: A Strong, Replicable Instruction-Following Model》翻译与解读_alpaca论文
- 5NLP学习——信息抽取_属性抽取
- 6人工智能翻译之间的对决:谷歌为什么败给了有道?
- 7基于CNNs的图片情感识别(Keras VS Pytorch)
- 8如何使用Excel表格精准分析PT100温度阻值关系?_pt100 曲线
- 9用chatGPT提高程序员工作效率+个人使用体验_gpt具体如何提高了程序员的效率,使用人员的感受如何
- 10[通用]计算机经典面试题基础篇Day3
深度学习八股文自用_深度学习八股文 知乎
赞
踩
一、逻辑回归和线性回归区别
线性回归:解决回归问题
逻辑回归:在线性回归基础上增加了sigmoid函数,将问题变为0-1分类问题。本质上还是线性回归
二、深度学习中为什么模型的参数通常都在0-1之间
三、梯度下降法的正确步骤是什么?
a.用随机值初始化权重和偏差
b.把输入传入网络得到输出值
c.计算预测值与真实值之间的误差
d.对每一个产生误差的神经元,调整相应的权重以减小误差
e.重复迭代,直到取得网络权重的最佳值
四、transfomer
1.结构:由encoder和decoder两个模块组成
2.流程:
a.获取输入句子每一个单词的表示向量X,X由单词的Embedding(原始数据提取出来的feature)和单词位置的Embedding相加得到。
b.将得到的单词表示向量矩阵传入Encoder模块,经过6个Encoder Block后得到所有单词的编码信息矩阵C
c.将C传入到Decoder模块,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
3.输入:
输入的X是由单词Embedding和单词位置Embedding相加而成
a.单词Embedding,通过各种特征提取网络提取(本质上就是一个featrue)。
b.位置Embedding,表示单词出现在句子中的位置。transfomer不采用RNN结构,使用全局信息,不能利用单词的顺序信息。
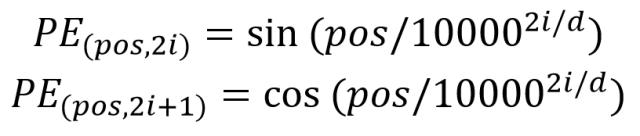
其中,pos 表示单词在句子中的位置,d 表示 PE的维度 (与词 Embedding 一样),2i 表示偶数的维度,2i+1 表示奇数维度 (即 2i≤d, 2i+1≤d)。使用这种公式计算 PE 有以下的好处:
- 使 PE 能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有 20 个单词,突然来了一个长度为 21 的句子,则使用公式计算的方法可以计算出第 21 位的 Embedding。
- 可以让模型容易地计算出相对位置,对于固定长度的间距 k,PE(pos+k) 可以用 PE(pos) 计算得到。因为 Sin(A+B) = Sin(A)Cos(B) + Cos(A)Sin(B), Cos(A+B) = Cos(A)Cos(B) - Sin(A)Sin(B)。
4.self-attention
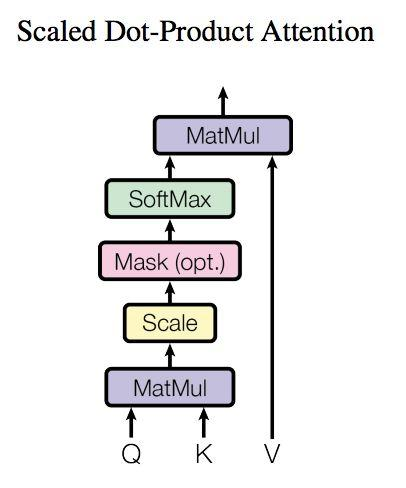
上图是 Self-Attention 的结构,在计算的时候需要用到矩阵Q(查询),K(键值),V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量x组成的矩阵X) 或者上一个 Encoder block 的输出。而Q,K,V正是通过 Self-Attention 的输入进行线性变换得到的。
4.1 Q,K,V的计算
Transformer模型详解(图解最完整版) - 知乎 (zhihu.com)

