
- 1添加作者_投稿后,你要临时加“作者”?别逗了……
- 2利用LSTM+CNN+glove词向量预训练模型进行微博评论情感分析(二分类)_glove lstm 情感分类
- 3鸿蒙Harmony应用开发—ArkTS声明式开发(容器组件:Grid)_arkts grid
- 4安装pyrender和OSMesa(非常详细)从零基础入门到精通,看完这一篇就够了
- 5国内外各ChatGPT类语言大模型API价格汇总, 对比,ChatGPT/Gmini/PaLM/Clude/Ernie/ChatGLM/千问/混元/星火/Minimax/百川
- 6three-sum(3个数的和)_three sum
- 7神经网络:GRU基础学习
- 8NLP自然语言处理的基本语言任务介绍_nlp基础任务
- 9前端学习笔记____基础篇HTML&CSS_前端学习时,一个盒子上边时ul加li,下边是img,为社么给ul加padding-bottom没有效
- 10Pygame —— 一个好玩的游戏 Python 库_pygame库
自然语言处理(NLP)语义分析--文本分类、情感分析、意图识别_nlp语义识别
赞
踩
文章目录
转载来源:https://blog.csdn.net/weixin_41657760/article/details/93163519
第一部分:文本分类
训练文本分类器过程见下图: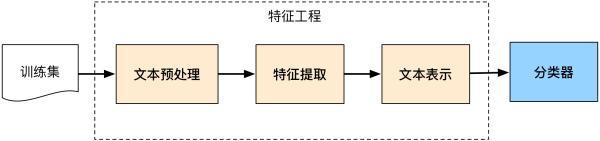
文本分类问题: 给定文档p(可能含有标题t),将文档分类为n个类别中的一个或多个
文本分类应用: 常见的有垃圾邮件识别,情感分析
文本分类方向: 主要有二分类,多分类,多标签分类
文本分类方法: 传统机器学习方法(贝叶斯,svm等),深度学习方法(fastText,TextCNN等)
文本分类的处理大致分为文本预处理、文本特征提取、分类模型构建等。和英文文本处理分类相比,中文文本的预处理是关键技术。
一、文本预处理(解决特征空间高维性、语义相关性和特征分布稀疏)
1、中文分词技术
为什么分词处理?因为研究表明特征粒度为词粒度远远好于字粒度,其大部分分类算法不考虑词序信息,基于字粒度的损失了过多的n-gram信息。
中文分词主要分为两类方法:基于词典的中文分词和基于统计的中文分词。
- 基于词典的中文分词
- 核心是首先建立统一的词典表,当需要对一个句子进行分词时,首先将句子拆分成多个部分,将每一个部分与字典一一对应,如果该词语在词典中,分词成功,否则继续拆分匹配直到成功。所以字典,切分规则和匹配顺序是核心。
- 基于统计的中文分词方法
- 统计学认为分词是一个概率最大化问题,即拆分句子,基于语料库,统计相邻的字组成的词语出现的概率,相邻的词出现的次数多,就出现的概率大,按照概率值进行分词,所以一个完整的语料库很重要。
- 基于理解的分词方法
- 基于理解的分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。这种分词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。
2、去除停用词
建立停用词字典,停用词主要包括一些副词、形容词及其一些连接词。通过维护一个停用词表,实际上是一个特征提取的过程,本质 上是特征选择的一部分。
二、文本特征提取
1、词袋模型
- 思想:
- 建立一个词典库,该词典库包含训练语料库的所有词语,每个词语对应一个唯一识别的编号,利用one-hot文本表示。
-
文档的词向量维度与单词向量的维度相同,每个位置的值是对应位置词语在文档中出现的次数,即词袋模型(BOW))
-
问题:
- (1)容易引起维度灾难问题,语料库太大,字典的大小为每个词的维度,高维度导致计算困难,每个文档包含的词语数少于词典的总词语数,导致文档稀疏。
- (2)仅仅考虑词语出现的次数,没有考虑句子词语之间的顺序信息,即语义信息未考虑
2、TF-IDF文本特征提取
-
利用TF和IDF两个参数来表示词语在文本中的重要程度。
-
TF是词频:
指的是一个词语在一个文档中出现的频率,一般情况下,每一个文档中出现的词语的次数越多词语的重要性更大,例如BOW模型一样用出现次数来表示特征值,即出现文档中的词语次数越多,其权重就越大,问题就是在长文档中 的词语次数普遍比短文档中的次数多,导致特征值偏向差异情况。 -
TF体现的是词语在文档内部的重要性。
-
IDF是体现词语在文档间的重要性
- 即如果某个词语出现在极少数的文档中,说明该词语对于文档的区别性强,对应的特征值高,IDF值高,IDFi=log(|D|/Ni),D指的是文档总数,Ni指的是出现词语i的文档个数,很明显Ni越小,IDF的值越大。
-
最终TF-IDF的特征值的表达式为:TF-IDF(i,j)=TFij*IDFi
3、基于词向量的特征提取模型
-
想基于大量的文本语料库,通过类似神经网络模型训练,将每个词语映射成一个定维度的向量,维度在几十到化百维之间,每个向量就代表着这个词语,词语的语义和语法相似性和通过向量之间的相似度来判断。
-
常用的word2vec主要是CBOW和skip-gram两种模型,由于这两个模型实际上就是一个三层的深度神经网络,其实NNLM的升级,去掉了隐藏层,由输入层、投影层、输出层三层构成,简化了模型和提升了模型的训练速度,其在时间效率上、语法语义表达上效果明显都变好。word2vec通过训练大量的语料最终用定维度的向量来表示每个词语,词语之间语义和语法相似度都可以通过向量的相似度来表示。
三、分类模型
1、传统机器学习方法:
传统机器学习算法中能用来分类的模型都可以用,常见的有:NB模型,随机森林模型(RF),SVM分类模型,KNN分类模型模型。
2、深度学习文本分类模型
-
fastText模型
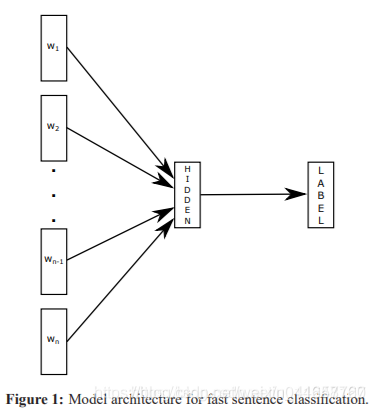
原理: 句子中所有的词向量进行平均(某种意义上可以理解为只有一个avg pooling特殊CNN),然后直接连接一个 softmax 层进行分类。 -
TextCNN:利用CNN来提取句子中类似 n-gram 的关键信息
模型结构[4]:
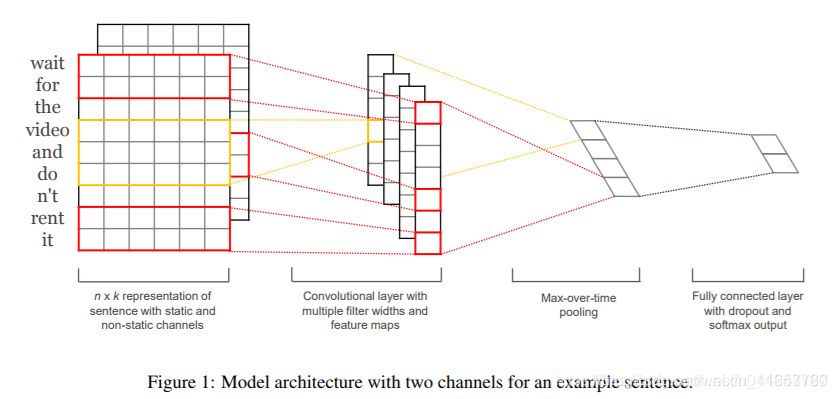
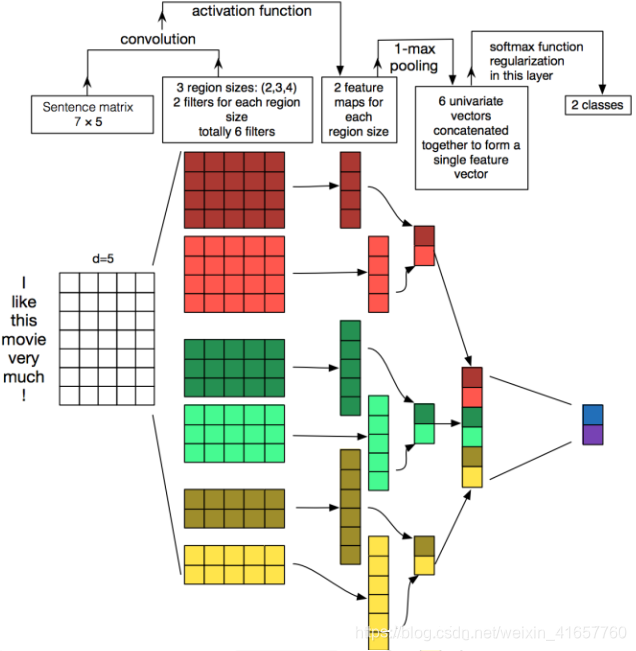
改进: fastText 中的网络结果是完全没有考虑词序信息的,而TextCNN提取句子中类似 n-gram 的关键信息。 -
TextRNN
模型: Bi-directional RNN(实际使用的是双向LSTM)从某种意义上可以理解为可以捕获变长且双向的的 “n-gram” 信息。
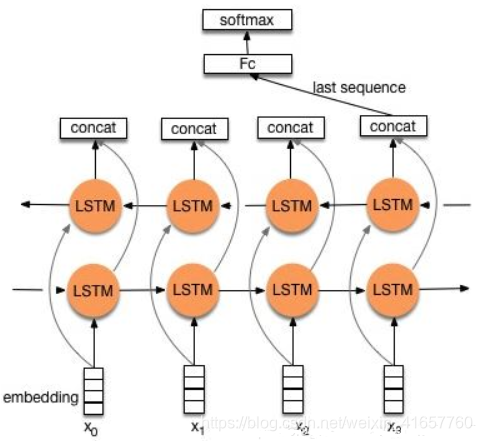
改进: CNN有个最大问题是固定 filter_size 的视野,一方面无法建模更长的序列信息,另一方面 filter_size 的超参调节也很繁琐。 -
TextRNN + Attention
模型结构:
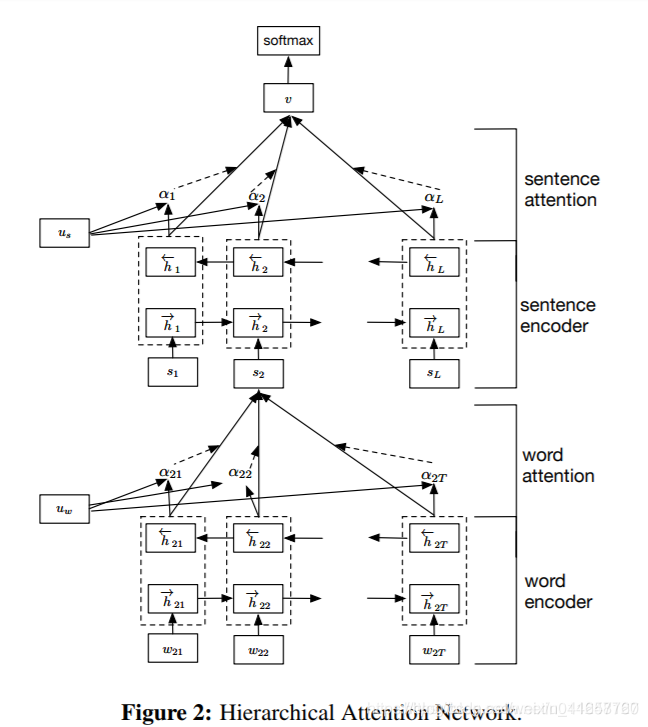
改进:注意力(Attention)机制是自然语言处理领域一个常用的建模长时间记忆机制,能够很直观的给出每个词对结果的贡献,基本成了Seq2Seq模型的标配了。实际上文本分类从某种意义上也可以理解为一种特殊的Seq2Seq,所以考虑把Attention机制引入近来。 -
TextRCNN(TextRNN + CNN)
模型结构:
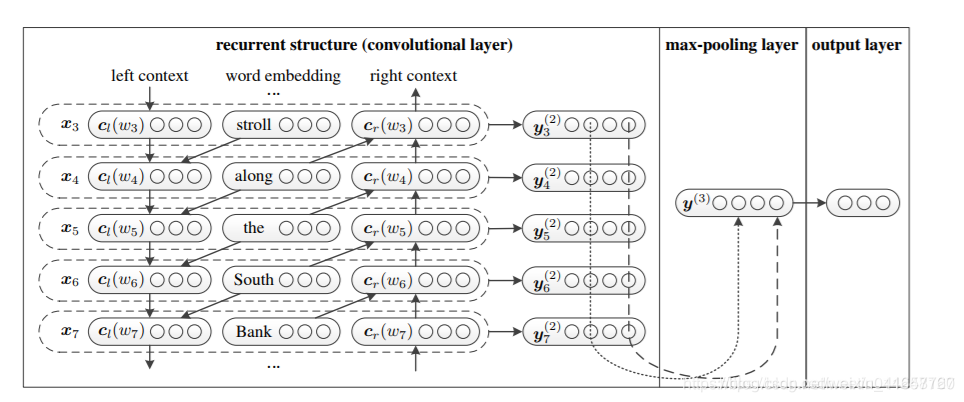
过程:
利用前向和后向RNN得到每个词的前向和后向上下文的表示: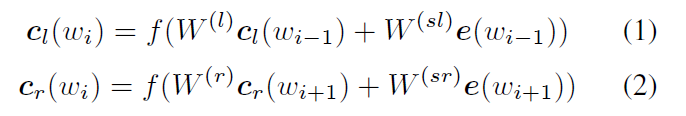
词的表示变成词向量和前向后向上下文向量连接起来的形式: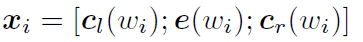
再接跟TextCNN相同卷积层,pooling层即可,唯一不同的是卷积层 filter_size = 1就可以了,不再需要更大 filter_size 获得更大视野。
第二部分:情感分析
一、概述
情感分析是自然语言处理中常见的场景,比如淘宝商品评价,饿了么外卖评价等,对于指导产品更新迭代具有关键性作用。通过情感分析,可以挖掘产品在各个维度的优劣,从而明确如何改进产品。比如对外卖评价,可以分析菜品口味、送达时间、送餐态度、菜品丰富度等多个维度的用户情感指数,从而从各个维度上改进外卖服务。
情感分析可以采用基于情感词典的传统方法,也可以采用基于机器学习的方法。
二、基于情感词典的情感分类方法
1、基于词典的情感分类步骤
基于情感词典的方法,先对文本进行分词和停用词处理等预处理,再利用先构建好的情感词典,对文本进行字符串匹配,从而挖掘正面和负面信息。如图:
2、情感词典
情感词典包含正面词语词典、负面词语词典、否定词语词典、程度副词词典等四部分。一般词典包含两部分,词语和权重。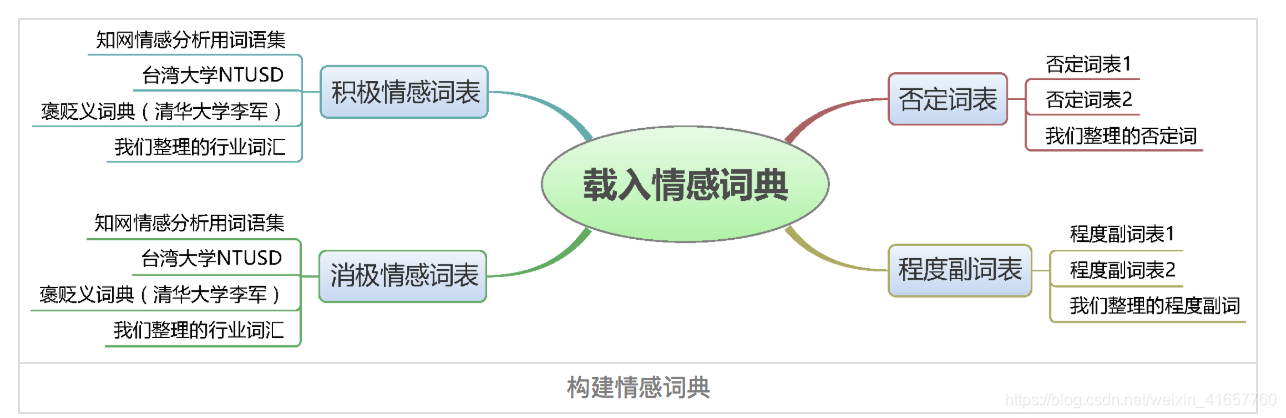
情感词典在整个情感分析中至关重要,所幸现在有很多开源的情感词典,如BosonNLP情感词典,它是基于微博、新闻、论坛等数据来源构建的情感词典,以及知网情感词典等。当然也可以通过语料来自己训练情感词典。
3、情感词典文本匹配算法
基于词典的文本匹配算法相对简单。逐个遍历分词后的语句中的词语,如果词语命中词典,则进行相应权重的处理。正面词权重为加法,负面词权重为减法,否定词权重取相反数,程度副词权重则和它修饰的词语权重相乘。如图: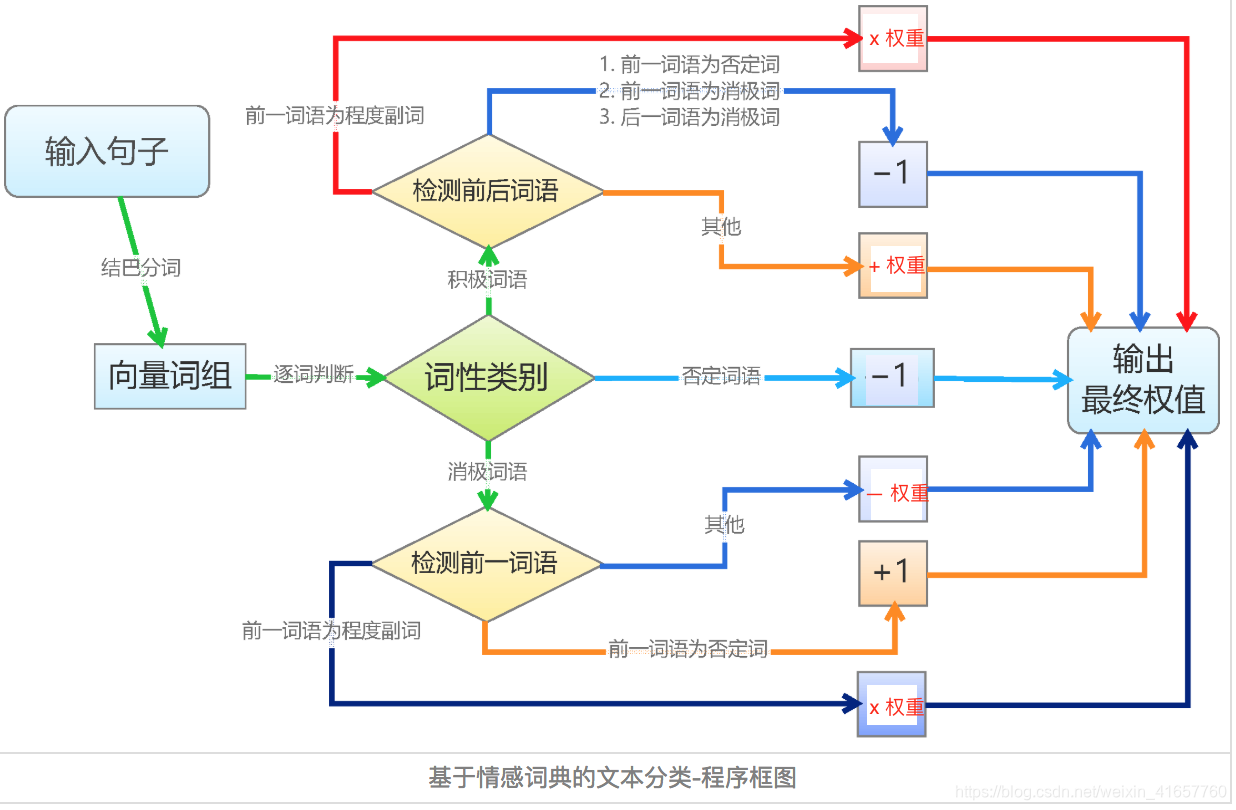
利用最终输出的权重值,就可以区分是正面、负面还是中性情感了。
4、缺点
基于词典的情感分类,简单易行,而且通用性也能够得到保障。但仍然有很多不足:
- 精度不高,语言是一个高度复杂的东西,采用简单的线性叠加显然会造成很大的精度损失。词语权重同样不是一成不变的,而且也难以做到准确。
- 新词发现,对于新的情感词,比如给力,牛逼等等,词典不一定能够覆盖。
- 词典构建难,基于词典的情感分类,核心在于情感词典。而情感词典的构建需要有较强的背景知识,需要对语言有较深刻的理解,在分析外语方面会有很大限制。
三、基于机器学习的情感分类方法
即为分类问题,文本分类中的各方法均可采用。
第三部分:意图识别
一、概述
意图识别是通过分类的办法将句子或者我们常说的query分到相应的意图种类。
举一个简单的例子,我想听周杰伦的歌,这个query的意图便是属于音乐意图,我想听郭德纲的相声便是属于电台意图。做好了意图识别以后对于很多nlp的应用都有很重要的提升,比如在搜索引擎领域使用意图识别来获取与用户输入的query最相关的信息。举个例子,用户在查询"生化危机"时,我们知道"生化危机"既有游戏还有电影,歌曲等等,如果我们通过意图识别发现该用户是想玩"生化危机"的游戏时,那我们直接将游戏的查询结果返回给用户,就会节省用户的搜索点击次数,缩短搜索时间,大幅提高用户的体验。
再举一个目前最火热的聊天机器人来说明一下意图识别的重要性。目前各式各样的聊天机器人,智能客服,智能音箱所能处理的问题种类都是有限制的。比如某聊天机器人目前只有30个技能,那么用户向聊天机器人发出一个指令,聊天机器人首先得根据意图识别将用户的query分到某一个或者某几个技能上去,然后再进行后续的处理。 做好了意图识别以后,那种类似于电影场景里面人机交互就有了实现的可能,用户向机器发来的每一个query,机器都能准确的理解用户的意图,然后准确的给予回复。人与机器连续,多轮自然的对话就可以借此实现了。
二、意图识别的基本方法
1、基于词典以及模版的规则方法:不同的意图会有的不同的领域词典,比如书名,歌曲名,商品名等等。当一个用户的意图来了以后我们根据意图和词典的匹配程度或者重合程度来进行判断,最简单一个规则是哪个domain的词典重合程度高,就将该query判别给这个领域。
2、基于查询点击日志:如果是搜索引擎等类型业务场景,那么我们可以通过点击日志得到用户的意图。
3、基于分类模型来对用户的意图进行判别:因为意图识别本身也是一个分类问题,其实方法和分类模型的方法大同小异。
三、意图识别的难点
意图识别工作最大的难点其实是在于标注数据的获取。目前标注数据的获取主要来自两方面,一方面是专门的数据标注团队对数据进行标注,一方面是通过半监督的方式自动生成标注数据。


