
- 1vscode设置以管理员身份运行_vscode以管理员身份运行
- 2C# | 上位机开发新手指南(十)加密算法——ECC_c# ecc
- 3Hadoop分布式文件系统_使用hadoop命令来操作分布式文件系统。头歌
- 416个Redis常见使用场景总结
- 5*人工智能*_csdn人工智能每天能搜几次
- 6从 Apache RocketMQ 和 Kafka 看 Topic 数量对单机性能的影响
- 7linux下执行sh脚本,提示Command not found解决办法_sh: 1: dkms: not found
- 8汇编语言的寻址模式及示例_汇编语言寻址实例
- 9Java技能点--switch支持的数据类型解释_java 类常量和接口常量 switch
- 10UDP通讯之字节流与protobuf转换(C++版)_protobuf udp
Qwen-audio-chat模型代码学习之模型代码
赞
踩
Qwen-audio-chat模型代码学习之信息融合:
- 很多朋友像我一样对Qwen-audio-chat如何将提示信息与音频结合起来感到好奇。经过我一下午的细致研究,我发现了其信息融合的工作流程。首先,系统会提取音频的特征,然后对文本提示进行嵌入(Embedding)处理。具体来说,它通过将音频特征转换成一个三维向量(如[1,56,4096]),并将这个向量嵌入到文本提示中。例如,考虑到一个文本提示信息,其中包括标记转换为ID的过程,随后是与音频特征的结合,即在文本中通过和标签指明音频的开始与结束位置。在融合过程中,系统通过ID定位到这些标签所代表的位置,并用音频特征向量A替换掉文本提示中的“Audio_path/audio_name.flac”相对应的向量表示。这样,音频特征就被有效地融合到文本提示中,形成了一个语言模型能够理解的向量表示。
// A code block
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
Audio 1:<audio>Audio_path/audio_name.flac</audio>
what does the person say?<|im_end|>
<|im_start|>assistant
- 1
- 2
- 3
- 4
- 5
- 6
- 7
音频处理:
- 模型图如下:
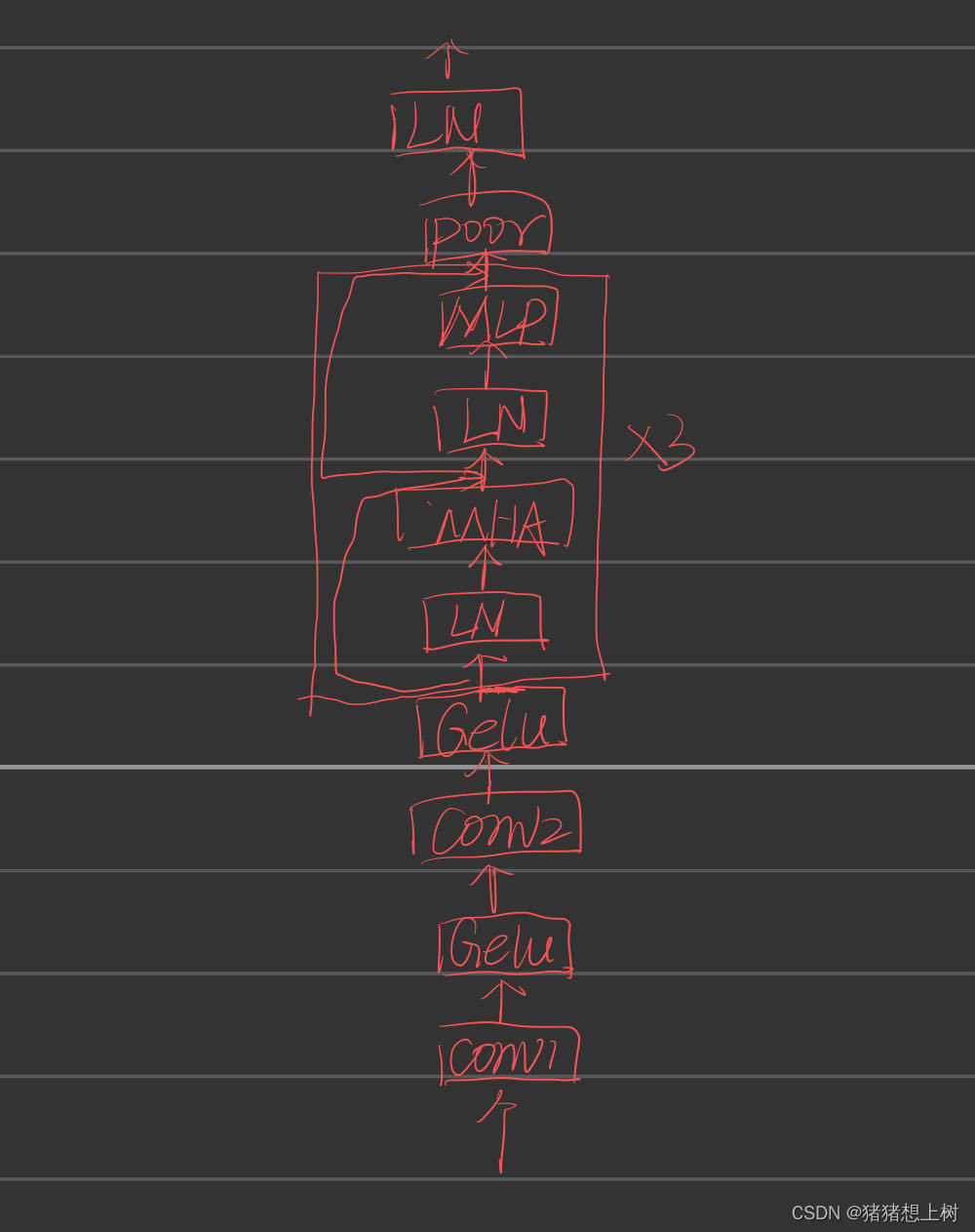
- 模型介绍:途中是32层,误写成了3。在音频数据处理的过程中,该模型先通过卷积层对Mel频谱执行处理,目的是精确提取音频信号内蕴含的局部特征,比如频率的变化规律及节奏的明暗度,从而为深入语音分析打下坚实的基础。紧接着,通过一次关键的转置操作,调整了数据的格式,以满足Transformer模型的输入要求。这一步骤超越了简单的形状调整,实际上它在空间上重新安排了特征与时间步之间的联系,让数据结构更加契合于捕捉时间序列变化的动态性。利用Transformer内置的自注意力机制,模型得以洞察音频信号中的广泛上下文信息,显露出音频特征间的远距离依赖性,这对于把握音频信号的结构模式与语调变化极为关键。此外,模型还融入了位置信息,以增强对序列中元素位置关系的理解。
- 模型代码实现如下:
// An highlighted block def encode(self, input_audios: Tensor, input_audio_lengths: Tensor, audio_span_tokens: List): real_input_audio_lens = input_audio_lengths[:, 0].tolist() max_len_in_batch = max(real_input_audio_lens) padding_mask = torch.ones([input_audios.size(0), max_len_in_batch]).to(dtype=self.conv1.weight.dtype, device=self.conv1.weight.device) for index in range(len(input_audios)): padding_mask[index, :input_audio_lengths[index][0].item()] = 0 x, bos, eos = self(input_audios, padding_mask,input_audio_lengths) output_audios = [] for i in range(len(audio_span_tokens)): audio_span = audio_span_tokens[i] audio = x[i][:audio_span-2] if bos is not None: audio = torch.concat([bos, audio, eos]) assert len(audio) == audio_span output_audios.append(audio) return output_audios

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
def forward(self, x: Tensor, padding_mask: Tensor=None, audio_lengths: Tensor=None): """ x : torch.Tensor, shape = (batch_size, n_mels, n_ctx) the mel spectrogram of the audio """ x = x.to(dtype=self.conv1.weight.dtype, device=self.conv1.weight.device) if audio_lengths is not None: input_mel_len = audio_lengths[:,0] * 2 max_mel_len_in_batch = input_mel_len.max() x = x[:, :, :max_mel_len_in_batch] x = F.gelu(self.conv1(x)) x = F.gelu(self.conv2(x)) x = x.permute(0, 2, 1) # B, L, D bsz = x.size(0) src_len = x.size(1) self.input_positional_embedding = self.positional_embedding[:src_len] assert x.shape[1:] == self.input_positional_embedding.shape, f"incorrect audio shape: {x.shape[1:], self.input_positional_embedding.shape}" x = (x + self.input_positional_embedding).to(x.dtype) if padding_mask is not None: padding_mask = padding_mask.to(dtype=self.conv1.weight.dtype, device=self.conv1.weight.device) batch_src_len = padding_mask.size(1) x = x[:, :batch_src_len, :] padding_mask = padding_mask.view( bsz, -1, batch_src_len ) padding_mask_ = padding_mask.all(1) x[padding_mask_] = 0 key_padding_mask = padding_mask_.view(bsz, 1, 1, batch_src_len). \ expand(-1, self.n_head, -1, -1).reshape(bsz, self.n_head, 1, batch_src_len) new_padding_mask = torch.zeros_like(key_padding_mask, dtype=x.dtype) padding_mask = new_padding_mask.masked_fill(key_padding_mask, float("-inf")) for block in self.blocks: x = block(x, mask=padding_mask) if self.avg_pooler: x = x.permute(0, 2, 1) x = self.avg_pooler(x) x = x.permute(0, 2, 1) x = self.ln_post(x) x = self.proj(x) if self.audio_bos_eos_token is not None: bos = self.audio_bos_eos_token.weight[0][None, :] eos = self.audio_bos_eos_token.weight[1][None, :] else: bos, eos = None, None return x, bos, eos
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
文本处理:
在这次的讲解中,我们将简要介绍文本数据的向量化技术,而更深入的探讨关于文本特征的编码方法将留到下一次分享。如link文章中所解释的那样,文本向量化的初步步骤涉及将文本字符串转化为它们对应的唯一标识符ID。随后,这些ID会被转换成代表相应token的向量形式,体现了一种基本观念——几乎一切都可以被向量化以便于计算处理。特别是在Qwen-audio-chat模型里,我们利用了nn.Embedding层来进行文本数据的向量化处理,旨在通过这种方式来增强和细化文本内容的表达。
信息融合:
- 理论基础
在多模态大型语言模型(LLM)的框架内,实现音频数据与文本数据的高效融合是提升模型综合理解与生成能力的关键策略。在Qwen-audio-chat模型融合过程的基础在于准确地识别输入序列中音频片段的起始和终止位置,进而将这些片段与已经经过预处理并通过模型处理的向量形式,然后
嵌入到模型的隐藏状态中。这一步骤的核心思想源自跨模态信息处理的理论,旨在通过统一的表示学习框架,处理并整合不同模态的数据,从而实现信息的互补和增强。
具体到音频与文本的信息融合,这不仅要求模型具备处理单一模态数据的能力,还需掌握如何将不同模态的数据在同一个语义空间内进行有效融合。这种融合增强了模型对于多模态输入数据的处理能力,使模型在执行如自动生成字幕、多模态情绪分析等任务时,能够更全面地理解上下文信息,提高了预测的准确性和生成内容的丰富度。
从理论角度来看,多模态LLM通过学习来自不同模态的共享表示,强调了模态间的交互和互补性。这种方法背后的假设是,不同模态的信息虽然形式各异,但它们在表示同一概念或事件时存在内在的相关性和补充性。因此,通过深度神经网络的强大非线性映射能力,多模态LLM能够理解并整合这些看似不同但实质上相关的信息,实现更为丰富和精准的数据理解和生成。
在实践中,这种跨模态融合策略要求模型不仅要有能力处理单一模态的数据,还要具备跨模态理解和生成的能力,这对模型的设计和训练提出了更高的要求。通过这样的信息融合,多模态LLM在处理复杂、多元化的信息时展现出更高的灵活性和适应性,为人工智能领域的应用开拓了新的可能性。
- 代码实现
// An highlighted block
bos_pos = torch.where(input_ids == self.config.audio['audio_start_id'])
eos_pos = torch.where(input_ids == self.config.audio['audio_start_id'] + 1)
audio_pos = torch.stack((bos_pos[0], bos_pos[1], eos_pos[1]), dim=1)
if audios is not None:
for idx, (i, a, b) in enumerate(audio_pos):
hidden_states[i][a : b+1] = audios[idx]
output_shape = input_shape + (hidden_states.size(-1),)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
总结
Qwen-audio-chat模型通过多模态信息融合技术,有效地结合了音频特征和文本提示信息,从而提升了模型的理解和生成能力。在这一过程中,模型首先提取音频信号的特征,并对文本信息进行向量化处理。接着,利用一个特定的替换机制,将音频特征嵌入到文本的向量表示中,确保两种信息在同一个语义空间内进行有效融合。这种融合策略不仅增强了模型对于多模态输入的处理能力,也使其能够在执行诸如自动生成字幕、多模态情感分析等任务时,更加准确和全面地理解上下文信息。

