
- 1支付宝对应APPID_支付宝常用appid
- 2llama-factory学习个人记录_raise valueerror("please launch distributed traini
- 3paddleocr:ERROR: Could not build wheels for lanms-neo, which is required to install pyproject
- 4玻利维亚媒体海外发稿:媒体投放报道助力企业在海外扭转战局
- 5PageRank算法与TextRank算法详解
- 6自定义View——画线、矩形、圆形、图像_latex 圆弧矩形
- 7OLLAMA部署qwen:7b,与fastgpt集成_ollama fastgpt
- 8sharding-jdbc 分库分表的 4种分片策略,还蛮简单的_shardingjdbc分库分表策略
- 9FPGA之JESD204B接口——总体概要 实例上_jesd204b接口速率
- 10超GPT-4o,代码能力超强!Claude 3.5 Sonnet正式发布_一句话生成网页,让前端开发瑟瑟发抖的claude3.5 sonnet #人工智能 #aigc #玩
python进阶学习笔记(5)_pool.apply
赞
踩
python进阶学习笔记5
一、多任务-线程
1、介绍
多任务:同一时间,多个任务同时执行
windows是多任务,python默认是单任务
2、线程的基本使用
线程是被系统独立调度和分派的基本单位
主线程:
当一个程序启动时,就有一个进程被操作系统创建,于此同时一个线程也立刻运行,这就叫做程序的主线程。
程序启动就会创建一个主线程
主线程的作用:
1、可以产生其他的子线程
2、它必须最后完成执行,比如执行各种关闭动作
子线程:
可以看做是程序执行的一条分支,当子线程启动后会和主线程一起同时执行
3、使用threading模块创建子进程
1、核心方法
threading.Thread(target=函数名),threading模块的Thread类创建子进程对象
线程对象.start()启动子进程
""" 子线程创建的步骤 1、导入模块 2、使用threading.Thread()创建对象(子进程对象) 3、指定子线程执行的分支 4、启动子线程,线程对象.start() """ import time import threading def SaySorry(): print("sorry,i am wrong") time.sleep(0.5) if __name__ == '__main__': for i in range(5): # 2、使用threading.Thread() # 创建对象(子进程对象) # 3、指定子线程执行的分支 thread_obj = threading.Thread(target=SaySorry) # 4、启动子线程, 线程对象.start() thread_obj.start()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
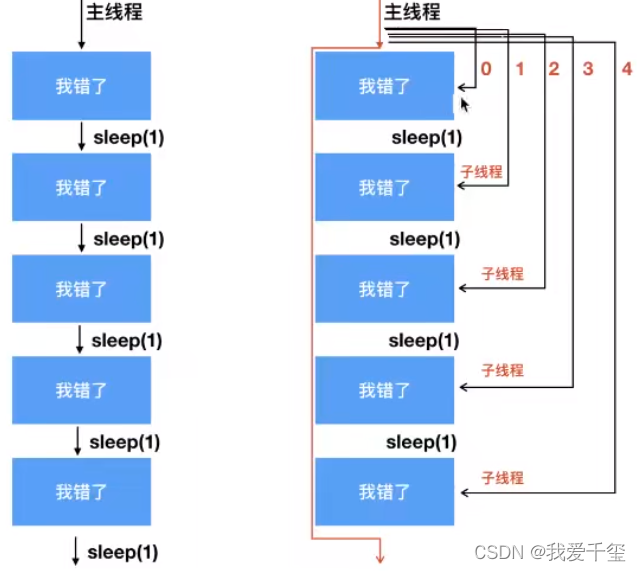
多线程的优点就是更加快了,因为同一个任务有更多的线程在进行
4、线程的名称及总数量
4.1 查看线程数量
threading.enumerate()可以获取当前所有活跃的线程对象列表,使用len()可以看到活跃的线程个数
import threading import time def sing(): for i in range(5): print("正在唱歌...") time.sleep(0.5) def dance(): for i in range(5): print("正在跳舞...") time.sleep(0.5) if __name__ == '__main__': thread_list=threading.enumerate() print("当前线程数量为:",len(thread_list)) thread_sing=threading.Thread(target=sing) thread_dance = threading.Thread(target=dance) thread_sing.start() thread_dance.start() thread_list = threading.enumerate() print("当前线程数量为:",len(thread_list)) 结果为: 当前线程数量为: 1 正在唱歌... 正在跳舞... 当前线程数量为: 3 正在跳舞...正在唱歌... 正在跳舞...正在唱歌... 正在唱歌...正在跳舞... 正在唱歌... 正在跳舞...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
4.2 查看线程名称
threading.current_thread()显示的是当前的线程对象
在上述代码上做如下改动:
...
def sing():
for i in range(5):
print("正在唱歌...",threading.current_thread())
time.sleep(0.5)
def dance():
for i in range(5):
print("正在跳舞...",threading.current_thread())
time.sleep(0.5)
if __name__ == '__main__':
print(threading.current_thread())
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
结果如下,我们可以看到线程的名称,有两个子线程:

5、线参数及顺序
目标:
1、能够向线程函数传递多个参数
2、能够说出多线程执行的顺序特点
传递参数的方式有三种:
1、使用元组–args=(参数1,参数2)
2、使用字典–kwargs={“参数名”:参数值…}
3、混合使用元组和字典
import threading import time def sing(a,b,c): print("参数为:",a,b,c) for i in range(5): print("正在唱歌...") time.sleep(0.5) def dance(): for i in range(5): print("正在跳舞...") time.sleep(0.5) if __name__ == '__main__': #向线程中传递参数 #1、使用元组传递,args=(参数1,参数2,参数3) thread_sing=threading.Thread(target=sing,args=(10,100,1000)) #2、使用字典,kwargs{"参数名":参数值...} thread_sing = threading.Thread(target=sing, kwargs={"a":100,"b":90,"c":40}) #3、混合使用元组和字典 thread_sing = threading.Thread(target=sing, args=(20,),kwargs={"b":90,"c":40}) thread_dance = threading.Thread(target=dance) thread_sing.start() thread_dance.start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
线程的执行顺序是无序的,线程由cpu调度执行,cpu根据系统的运行状态,按照自己的调度算法去调度执行
6、守护线程
目标:
能够使用setDaemon设置子线程守护主线程
什么是守护线程:
如果在程序中将子线程设置为守护线程,则该子线程会在主线程结束时自动退出(主线程挂,子线程也得挂),设置方式为thread.setDaemon(True),要在thread.start()之前设置,默认是False的(也就是主线程结束时,子线程仍然在执行)
默认的情况
import threading
import time
def work():
for i in range(10):
print("正在执行work1...",i)
time.sleep(0.5)
if __name__ == '__main__':
#创建子线程
thread_obj=threading.Thread(target=work)
thread_obj.start()
#让主程序睡眠两秒
time.sleep(2)
print("Game Over")
#让程序退出,主线程就主动结束了
exit()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
结果为:

主线程都已经挂了,子线程还在进行,这是不可取的,所以我们设置守护线程
import threading import time def work(): for i in range(10): print("正在执行work1...",i) time.sleep(0.5) if __name__ == '__main__': #创建子线程 thread_obj=threading.Thread(target=work) #线程守护,子线程守护主线程 thread_obj.setDaemon(True) #启动子线程 thread_obj.start() #让主程序睡眠两秒 time.sleep(2) print("Game Over") #让程序退出,主线程就主动结束了 exit()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
结果为:

7、并行和并发
目标:
能够说出并行和并发的区别
并发:
任务数大于cpu核数,任务1,2,3需要轮询处理
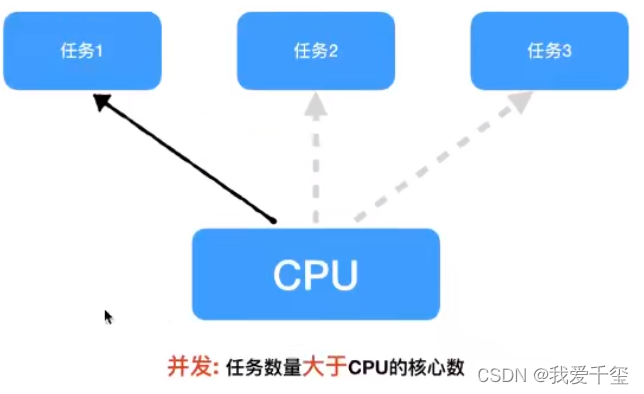
并行:
任务数小于等于cpu核数,任务真的是一起执行的,任务1和任务2不需要轮询

8、自定义线程类(*)
目标
知道通过threading.Thread可以实现自定义线程
为了让每个线程的封装性更完美,所以使用threading模块时,往往会定义一个新的子类class,只要
1、让自定义类继承threading.Thread
2、让自定义类重写run方法
3、通过实例化自定义对象.start()方法启动自定义线程
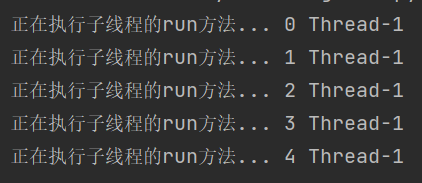
""" 1、让自定义类继承threading.Thread 2、重写父类(threading.Thread)的run方法 3、通过创建子类对象,让子类对象.start()就可以启动子线程 """ import threading import time #自定义线程类MyThread class MyThread(threading.Thread): #重写父类的run方法 def run(self): for i in range(5): #self.name是从父类里继承的属性 print("正在执行子线程的run方法...",i,self.name) time.sleep(0.5) if __name__ == '__main__': #创建线程对象 mythread=MyThread() #线程对象.start()启动线程 mythread.start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
结果为:
9、多线程共享全局变量
目标
知道多线程能够共享全局变量数据
多个线程方法中可以共用全局变量
创建两个函数,在work1函数中对全局变量g_num的值做修改,于此同时在work2函数中获取g_num的值
主要目的:work1线程对全局变量的修改,在work2中能否查看修改后的结果
import threading #定义全局变量 g_num=0 def work1(): #声明g_num是全局变量 global g_num for i in range(10): g_num+=1 print("work1-----------",g_num) def work2(): print("work2-----------",g_num) #创建两个子线程 if __name__ == '__main__': t1=threading.Thread(target=work1) t2=threading.Thread(target=work2) #启动线程 t1.start() t2.start() #在t1和t2线程执行完毕后再打印g_num if len(threading.enumerate())==1: print("main---------",g_num)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
结果为:
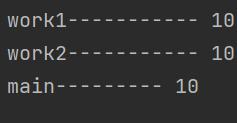
说明了全局变量可以在多个线程之间可以共享全局变量
10、多线程-共享全局变量的资源竞争问题
目标
知道多线程共享全局变量数据会导致资源竞争问题
如果我们把work2也修改成和work1一样的代码,让其对全局变量进行修改操作,将值循环100万次,得到的结果如下:
g_num=0
def work1():
#声明g_num是全局变量
global g_num
for i in range(1000000):
g_num+=1
print("work1-----------",g_num)
def work2():
#声明g_num是全局变量
global g_num
for i in range(1000000):
g_num+=1
print("work2-----------",g_num)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

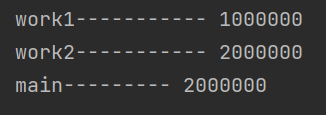
当多个线程去修改同一个资源的时候,会出现资源竞争,导致计算结果有误
解决方案:线程对象.join()
g_num=0 def work1(): #声明g_num是全局变量 global g_num for i in range(1000000): g_num+=1 print("work1-----------",g_num) def work2(): #声明g_num是全局变量 global g_num for i in range(1000000): g_num+=1 print("work2-----------",g_num) if __name__ == '__main__': t1=threading.Thread(target=work1) t2=threading.Thread(target=work2) #启动线程 t1.start() #让t1线程优先执行,t1执行完毕后,t2才能执行 t1.join() t2.start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
结果为:

缺点:
把多线程变成了单线程,影响整体性能
11、同步和异步以及线程的锁机制
同步:
多个任务之间执行的时候要求有先后顺序,必须一个先执行完之后,另一个才能继续执行。比如你先说完,我再说
异步:
多个任务之间执行没有先后顺序,可以同时运行。比如发微信不用等待对方回复,继续发
线程的锁机制:
当线程获取资源后,立刻进行锁定,资源使用完毕后再解锁,保证同一时间,只有一个线程在使用资源
12、互斥锁
目标:
知道什么是互斥锁,以及用互斥锁去解决资源竞争的问题
互斥锁的概念
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制。线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制就是引入互斥锁。
互斥锁为资源引入一个状态:锁定/非锁定
在python中的threading模块中定义了Lock类,可以方便的处理锁定
import threading
#创建锁
mutex=threading.Lock()
#锁定
mutex.acquire()
#释放锁
mutex.release()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
使用互斥锁完成两个线程对同一个全局变量各加100万次的操作
import threading import time g_num=0 def work1(): #声明g_num是全局变量 global g_num # 访问资源之前先上锁 lock1.acquire() for i in range(1000000): g_num+=1 #资源访问之后再解锁 lock1.release() print("work1-----------",g_num) def work2(): global g_num # 访问资源之前先上锁 lock1.acquire() for i in range(1000000): g_num += 1 lock1.release() print("work2-----------",g_num) #创建两个子线程 if __name__ == '__main__': #创建一把互斥锁 lock1 = threading.Lock() t1=threading.Thread(target=work1) t2=threading.Thread(target=work2) #启动线程 t1.start() t2.start() #在t1和t2线程执行完毕后再打印g_num while len(threading.enumerate())!=1: time.sleep(1) print("main---------",g_num)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
结果为:
13、死锁
目标:
知道多线程程序要避免死锁
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁

14、多任务版udp聊天器
改进思路
1、单独开子线程用于接收消息,以达到收发消息可以同时进行
2、接收消息要能够连续接收多次,而不是一次
3、设置子线程守护主线程(解决无法正常退出问题)
有这个骷颅头就代表有子线程还在继续,我们需要设置守护线程
import socket import threading """ 1、发送消息 2、退出功能 """ def send_message(udp_socket): """发送消息""" adress = input("请输入接收方地址:") port = input("请输入接收方端口号:") message = input("请输入要发送的内容:") udp_socket.sendto(message.encode(), (adress, int(port))) def recv_message(udp_socket): """接收多条消息""" while True: recv_data, ip_and_port = udp_socket.recvfrom(1024) recv_text = recv_data.decode() print("{}接收到的消息为{}".format(ip_and_port,recv_text)) def run(): """主要实现函数""" # 创建套接字 udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 绑定端口 udp_socket.bind(("", 8080)) #创建子线程,单独接收用户发送的消息 thread_recvmsg=threading.Thread(target=recv_message,args=(udp_socket,)) #子线程守护主线程 thread_recvmsg.setDaemon(True) thread_recvmsg.start() # 循环打印用户菜单 while True: print("*" * 20) print("*** 1、发送消息 ***") print("*** 2、退出系统 ***") print("*" * 20) menu_num = input("请选择功能:") if menu_num == "1": send_message(udp_socket) elif menu_num == "2": break else: print("请输入数字1-2!") udp_socket.close() if __name__ == "__main__": run()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
结果如下,我们点击红色按钮退出,也不会出现骷颅头了

15、tcp服务端框架
目标
能够使用多线程实现同时接收多个客户端的多条消息
改进思路
1、实现指定端口监听
2、实现服务端地址重用,避免Adress already in use错误
3、能够支持多个客户端连接
4、能够支持不同的客户端同时收发消息(开启子线程)
5、服务器端主动关闭服务后,子线程随之结束
# 1、导入模块 import socket import threading def recv_msg(new_client_socket,ip_and_port): while True: recv_data=new_client_socket.recv(1024) #内容为空就退出 if recv_data: # 8、解码并且作出输出 recv_text=recv_data.decode() print("收到来自{}的信息:{}".format(ip_and_port,recv_text)) else: break # 9、关闭和当前客户端的连接 new_client_socket.close() # 2、创建套接字 tcp_server_socket=socket.socket(socket.AF_INET,socket.SOCK_STREAM) # 3、设置地址可以重用 tcp_server_socket.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,True) # 4、绑定端口 tcp_server_socket.bind(("",8080)) # 5、设置监听,套接字由主动设置为被动 tcp_server_socket.listen(128) # 6、接收多个客户端连接 while True: new_client_socket,ip_and_port=tcp_server_socket.accept() print("新用户上线:{}".format(ip_and_port)) #创建线程 thread_recvmsg=threading.Thread(target=recv_msg,args=(new_client_socket,ip_and_port)) thread_recvmsg.setDaemon(True) thread_recvmsg.start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
实现效果如下:

二、进程
1、进程池pool
目标
知道进程池的作用-自动帮我们创建指定数量的进程,并且管理进程,并且指派工作,工作方式有同步和异步两种
同步和异步的区别
同步:pool.apply()
进程池中的进程,一个执行完毕后另外一个才能执行,多个进程执行由先后顺序
异步:pool.apply_async():
进程池中的进程,多个进程同时执行,没有先后顺序。记得要close以及ioin
进程池概述
当需要创建的子进程数量不多时,可以直接利用multprocessing中的Process动态生成多个进程,但如果是成百上千个目标,手动去创建的工作量巨大,此时就可以用到multprocessing模块提供的Pool方法。

先用同步方式执行(一个一个有顺序的执行)
import time
import multiprocessing
# 1、创建一个函数,用于模拟文件拷贝
def copy_work():
print("正在拷贝文件",multiprocessing.current_process().name)
time.sleep(0.5)
if __name__ == '__main__':
# 2、创建一个进程池,长度为3
pool=multiprocessing.Pool(3)
for i in range(10):
# 3、先用进程池同步方式拷贝文件
#pool.apply(函数名,(传递给函数的参数))
pool.apply(copy_work)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
结果为:

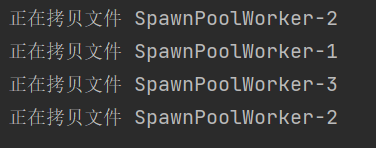
再用进程池异步方式拷贝文件(3个3个运行)
import time import multiprocessing # 1、创建一个函数,用于模拟文件拷贝 def copy_work(): print("正在拷贝文件",multiprocessing.current_process().name) time.sleep(0.5) if __name__ == '__main__': # 2、创建一个进程池,长度为3 pool=multiprocessing.Pool(3) for i in range(10): #用进程池异步方式拷贝文件 #如果使用apply_async要注意两点 #1、必须要close():表示不再接收新的任务了 #2、主进程不再等待进程池执行结束后再退出,需要进程池join一次 #pool.join(),让主进程等待进程池执行结束后再退出 pool.apply_async(copy_work) #表示不再接收新的任务了 pool.close() #让主进程等待进程池执行结束后再退出 pool.join()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
从执行结果可以看出是3个3个运行的,且没有先后顺序
2、进程池中的Queue
目标
知道实现进程池中进程间通信
创建进程池中的队列方法如下,而不是multiprocessing.Queue()(这是进程创建队列的方式)
multiprocessing.Manager().Queue()
- 1
实现代码如下:
import multiprocessing import time def write(queue): """写入数据到队列的函数""" #for循环,向队列写入数据 for i in range(10): #判断队列是否已满 if queue.full(): print("队列已满") break else: #向队列中写值 queue.put(i) print("写入成功,已经写入",i) time.sleep(0.5) def read(queue): """读取队列数据并显示的函数""" while True: if queue.qsize()==0: print("队列已空") break else: #从队列中读取数据 value=queue.get() print("已经读取到",value) if __name__ == '__main__': #创建进程池 pool=multiprocessing.Pool(2) #创建进程池中的队列 queue=multiprocessing.Manager().Queue(5) #使用进程池执行任务-同步 pool.apply(write,(queue,)) pool.apply(read,(queue,)) #使用进程池执行任务-异步 pool.apply_async(write,(queue,)) pool.apply_async(read,(queue,)) #表示不再接收新的任务 pool.close() #主进程会等待进程池执行结束后,再退出 pool.join()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
三、可迭代对象及迭代器
目标
1、知道什么是可迭代对象
2、能够使用isinstance()检测对象是否可迭代
1、可迭代对象及检测方法
可以对list,tuple,str等类型的数据使用for …in…的循环语法从其中依次拿到数据进行使用,这样的过程称为遍历,也叫迭代
实现代码如下:

#isinstance(待检测的对象,Iterable) from collections.abc import Iterable ret=isinstance(5,Iterable) result=isinstance([1,2,3],Iterable) print(ret) print(result) #自定义一个类 class MyClass(object): #增加一个魔术方法,该方法就是一个迭代器 def __iter__(self): pass #创建对象 myclass=MyClass() lei=isinstance(myclass,Iterable) print("类可以迭代嘛",lei)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
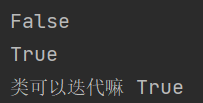
总结:
1、可遍历对象就是可迭代对象
2、 元组,列表,字典都是可迭代对象
3、整数和自定义类默认都是不可迭代的
4、类中如果有_ _iter _ _方法,此时这个类所创建的对象就是可迭代对象
2、迭代器及其使用方法
2.1 迭代器的概念
目标
1、使用iter函数获得可迭代对象的迭代器
2、使用next函数可以获得迭代器数据
什么是迭代器?
列表,元组,字典都可以迭代,说明它们都有迭代器,通过迭代器获取每个数据。如下图所示

2.2 迭代器的使用方法
怎么样获取迭代器以及迭代器元素呢?
list—>iter(可迭代对象)获取迭代器---->next(迭代器)获取下一个元素
实现代码如下:
#创建一个可迭代对象
list1=[1,3,5,7,9]
#获取迭代器
l1_iterator=iter(list1)
#根据迭代器获取下一个元素
value=next(l1_iterator)
print(value)
value=next(l1_iterator)
print(value)
结果为:
1
3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
迭代器特点,作用:
1、能够记录遍历的位置
2、提供下一个元素的值,配合next()函数
这和for循环有什么区别呢?
1、for循环的本质就是通过iter(可迭代对象)获取要遍历对象的迭代器
2、然后next(迭代器)获取下一个元素
3、帮我们捕获了stopiteration异常(就是获取下一个元素的次数超过了可迭代对象元素的个数)
3、自定义迭代对象及迭代器
3.1 自定义迭代对象
目标
能够自定义一个列表
3.2 自定义迭代器
自定义迭代器必须满足两点
1、必须含有_ _ iter_ _ ()
2、必须含有 _ _ next_ _(),当next(迭代器)时,会自动调用该方法
实现代码如下:
""" 目标:自定义列表 mylist=MyList() for value in mylist: print(value) 1、MyList类:初始化方法,iter方法,additem方法:用来添加数据 2、自定义迭代器类:MyListIterator:初始化方法,iter方法,next方法 """ class MyList(object): def __init__(self): #定义实例属性保存数据 self.items=[] #定义迭代器函数的目的是为了让此类可以遍历(迭代) def __iter__(self): #创建MyListIterator对象 mylist_iterator=MyListIterator(self.items) #返回迭代器 return mylist_iterator def addItem(self,data): #追加保存数据 self.items.append(data) print(self.items) class MyListIterator(object): def __init__(self,items): #自定义实例属性,保存MyList类传递过来的items self.items=items #记录迭代器迭代的位置 self.current_index=0 def __iter__(self): pass def __next__(self): #判断当前下标是否越界,越界就无法访问 if self.current_index < len(self.items): #获取下标对应的元素值 data=self.items[self.current_index] #下标位置+1 self.current_index+=1 #返回下标对应的数据 return data else: #raise用于主动抛出异常,StopIteration:停止迭代 raise StopIteration if __name__ == '__main__': #创建自定义列表对象 mylist=MyList() #给列表添加数据 mylist.addItem("张飞") mylist.addItem("关羽") mylist.addItem("李明") for value in mylist: print("name:",value) #用iter()和next()可以验证 mylist_iterator=iter(mylist) value=next(mylist_iterator) print(value) value = next(mylist_iterator) print(value)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
结果为:

4、迭代器的应用-斐波那契数列

实现代码:
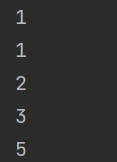
class Fibonacci(object): def __init__(self,num): #定义实例属性,保存生成的列数 self.num=num #定义变量保存斐波那契数列的1,2两列 self.a=1 self.b=1 #记录下标位置的实例属性 self.current_index=0 def __iter__(self): #返回自己 return self def __next__(self): #判断列数是否已经超过生成的总列数 if self.current_index < self.num: #定义变量保存a的值 data=self.a self.a,self.b=self.b,self.a+self.b #当前列数+1 self.current_index+=1 #返回a的值 return data else: raise StopIteration if __name__ == '__main__': #创建迭代器对象 fib_iterator=Fibonacci(5) for value in fib_iterator: print(value)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
结果为:
总结:

四、生成器
目标
能够使用两种方法创建生成器
1、什么是生成器?

2、生成器的创建方法
2.1 我们可以在列表推导式的基础上,引出生成器的第一种创建方式
下面是列表推导式
# list1=[i for i in range(5)]
# print(list1)
生成器的创建
list2=(i for i in range(5))
#通过next获取下一个值
print(next(list2))
print(next(list2))
结果为:
0
1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.2 在函数的基础上引出生成器的创建方式2,函数中使用,yield
下面是函数的创建方式
# def test():
# return 10
# m=test()
# print(m)
生成器的创建方式
def test1():
yield 10
n=test1()
print(n)
print(next(n))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
结果为:

3、生成器的案例-斐波那契数列
目标
知道通过yield关键字可以创建生成器
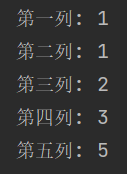
def fibonacci(n): a=1 b=1 current_index=0 while current_index < n: data=a a,b=b,a+b current_index+=1 yield data if __name__ == '__main__': fib=fibonacci(5) print("第一列:",next(fib)) print("第二列:",next(fib)) print("第三列:",next(fib)) print("第四列:",next(fib)) print("第五列:",next(fib)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
结果为:
4、生成器使用注意
目标
1、知道使用send方法能够启动生成器,并传递参数
2、能够说出return的作用
因为生成器无法中途停止下来,所以我们可以使用return让其终止,send可以传递参数
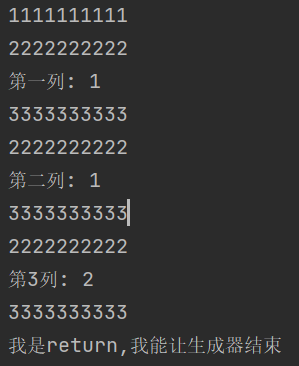
def fibonacci(n): a=1 b=1 current_index=0 print("1"*10) while current_index < n: data=a a,b=b,a+b current_index+=1 print("2"*10) xxx=yield data print("3"*10) if xxx==1: #生成器中能使用return,让生成器结束 return "我是return,我能让生成器结束" if __name__ == '__main__': fib=fibonacci(5) print("第一列:",next(fib)) try: print("第二列:",next(fib)) print("第3列:",next(fib)) value=fib.send(1) #这里send的值就传到了if判断那里 print("第4列",value) except Exception as e: print(e)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
结果为:
五、协程
1、什么是协程
在不开辟新的线程的基础上,可以实现多任务


2、协程和线程的差异

1、协程-yield
目标
知道使用yield关键字可以实现协程
手动实现协程,实现代码如下:
''' 1、创建work1的生成器 2、创建work2的生成器 3、获取生成器,通过next运行生成器 ''' import time def work1(): while True: print("正在执行work1...") yield time.sleep(0.5) def work2(): while True: print("正在执行work2...") yield time.sleep(0.5) if __name__ == '__main__': #获取生成器 w1=work1() w2=work2() while True: #使之运行 next(w1) next(w2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
结果为:
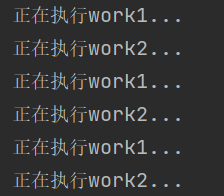
2、协程-greenlet
目标
知道使用greenlet可以实现协程

''' greenlet实现协程的步骤 1、导入模块 2、创建work1,work2两个任务 3、创建greenlet对象 4、手动switch任务 ''' from greenlet import greenlet import time def work1(): while True: print("正在执行work1...") time.sleep(0.5) #切换到第二个任务 g2.switch() def work2(): while True: print("正在执行work2...") time.sleep(0.5) #遇到阻塞,又切换到work1 g1.switch() if __name__ == '__main__': #创建greenlet对象 g1=greenlet(work1) g2=greenlet(work2) #先执行work1这个任务 g1.switch()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
结果为:
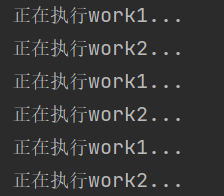
3、协程-gevent
目标
知道使用gevent可以实现协程
能够自动识别程序中的耗时操作,在耗时的时候自动切换到其他的任务

import gevent import time def work1(): while True: print("正在执行work1...") #time.sleep(0.5) gevent.sleep(0.5) def work2(): while True: print("正在执行work2...") #time.sleep(0.5) gevent.sleep(0.5) if __name__ == '__main__': #指派任务 #gevent.spawn(函数名,参数1,参数2...) g1=gevent.spawn(work1) g2=gevent.spawn(work2) #让主线程等待协程执行完毕再退出 g1.join() g2.join()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
结果为:
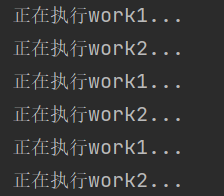
关于gevent.sleep()的知识
打补丁的方式最好放在开头处
猴子补丁的作用:
如果有太多time.sleep()修改麻烦,可以使用猴子补丁



