
热门标签
热门文章
- 1乐信季报图解:乐信营收35亿同比增15%将派发现金分红
- 2前端传来的图片并保存_java实现图片上传功能,并返回图片保存路径
- 3Scalar, Vector, Matrix, Tensor, Array 傻傻分不清楚,看完这篇可视化你就明白!_scalar vector
- 4autodl运行ollama报错Failed to connect to bus: Host i&Error, pkgProblemResolver::Resolve generated breaks_autodl中报错failed to connect to bus: host is down
- 5校园志愿者服务管理系统-计算机毕设Java|springboot实战项目
- 6【计算机视觉】小目标检测研究进展:小目标定义及难点分析(详细讲解)
- 7uml建模工具对比分析_protobuf和其它几种序列化工具的性能对比分析
- 8【产品经理修炼之道】- 如何从0到1搭建B端产品_b2b产品管理:从0到1的实践之路
- 92019年秋招面试总结(一)(中兴、大疆)_大疆为什么笔试挂
- 10nuxt3搭建和部署_nuxt3 部署
当前位置: article > 正文
【无标题】Excel转Word,分享一个测试用例转换脚本(已开源)_excel转doc测试用例(1)_测试点转化为测试用例脚本
作者:爱喝兽奶帝天荒 | 2024-08-19 23:56:22
赞
踩
测试点转化为测试用例脚本
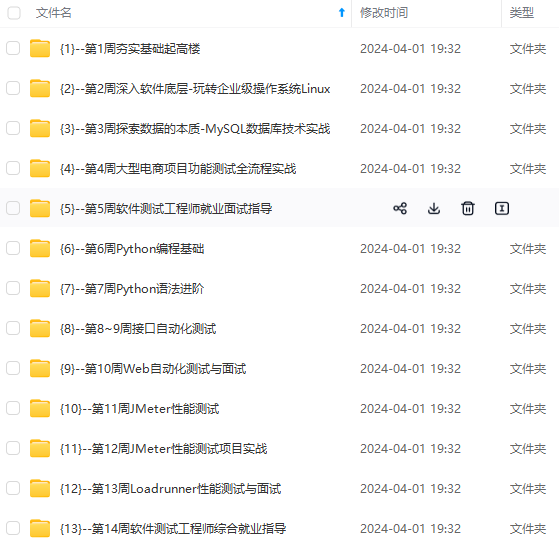
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
exword.py 文件即为所用脚本,整个代码共分为六个可执行函数,分别为:get_sheet、generate_word_file、add_table_to_document_up、add_table_to_document_center、add_table_to_document_down、excel_to_docx,下面分别介绍6个函数的功能以及部分主要代码展示:
- get_sheet:通过输入 excel 工作表名称,获取工作表内容,返回 datas,数据结构为列表嵌套字典
def get_sheet(sheet_name): sheet = book.sheet_by_name(sheet_name) nrows = sheet.nrows # 行数 ncols = sheet.ncols # 列数 datas = [] # 存放数据 keys = sheet.row_values(0) # 第一行标题 for row in range(1, nrows): data = {} # 每一行数据 for col in range(0, ncols): value = str(sheet.cell_value(row, col)) # 取出每一个单元格的数据 # 替换特殊字符 value = value.replace('<', '').replace('>', '').replace('$', '') data[keys[col]] = value # 截取第一行元素 arrs = [value for value in data.values()] # 通过测试用例编号分组,用的很少 first = arrs[0] # 通过二级模块分组,常用 second = arrs[2] # 通过功能点名称分组,常用 third = arrs[4] data['first'] = first data['second'] = second data['third'] = third datas.append(data) logger.info('excel文件内容获取成功!!') return datas

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- generate_word_file:初始化 word 文档,返回一个 word 对象
- add_table_to_document_up:在 word 对象中组装列表的上部分,这里所说的上部分指的是需求编号到前置条件这六部分,这六部分是固定不变的,因此单独拿出来作为列表的上部分,此方法需要依赖于 word 对象和填充的数据,传入 doc 和 data_table,返回 doc, doc_table, data_table
def add_table_to_document_up(doc, data_table): # 表格上段 # 新增表格 7行4列 doc_table = doc.add_table(rows=7, cols=4) doc_table.style = "Table Grid" doc_table.style.font.size = Pt(12) doc_table.style.font.name = '宋体' # 合并单元格 赋值 merge_cells = [ (0, 1, 0, 3), (1, 1, 1, 3), (2, 1, 2, 3), (3, 1, 3, 3), (4, 1, 4, 3), (5, 1, 5, 3) ] cell_texts = [ ('需求编号', '暂无'), ('用例编号', data_table[0]['用例编号']), ('用例名称', f"对{data_table[0]['一级模块']}所有功能点进行用例编写"), ('用例说明', data_table[0]['用例描述']), ('测试内容', f"验证{data_table[0]['一级模块']}模块中所有功能"), ('前置条件', data_table[0]['前置条件']) ] for row_start, col_start, row_end, col_end in merge_cells: doc_table.cell(row_start, col_start).merge(doc_table.cell(row_end, col_end)) for i, (label, text) in enumerate(cell_texts): doc_table.rows[i].cells[0].text = label doc_table.rows[i].cells[1].text = text return doc, doc_table, data_table
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- add_table_to_document_center:在 word 对象中组装列表的中部,这里所说的中部指的是用例体部分,因为这部分不确定每个功能有多少用例,所以这部分是活动的,将这部分单独拿出来作为表格的中部,此方法需要依赖于 word 对象、表格对象和填充的数据,传入 doc, doc_table, data_table,返回 doc, doc_table, data_table
def add_table_to_document_center(doc, doc_table, data_table): # 表格中段 # 设置标题 head_cells = doc_table.rows[6].cells head_cells[0].text = '序号' head_cells[1].text = '测试步骤' head_cells[2].text = '预期结果' head_cells[3].text = '实际结果' # 第1 列水平居中,并设置行高,所有单元格内容垂直居中 for i in range(0, 7): # 水平居中 p = doc_table.rows[i].cells[0].paragraphs[0] p.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER doc_table.rows[i].height = Cm(0.6) # 行高 # 垂直居中 for j in range(0, 4): doc_table.rows[i].cells[j].vertical_alignment = WD_CELL_VERTICAL_ALIGNMENT.CENTER # 生成表格并填充内容 row_num = 0 for data in data_table: row = doc_table.add_row() row_cells = row.cells row_cells[0].text = str(row_num + 1) # 序号,需要转换成字符串 row_cells[1].text = data['测试步骤'] row_cells[2].text = data['预期结果'] row_cells[3].text = data['预期结果'] # 水平居中 p = row_cells[0].paragraphs[0] p.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER row.height = Cm(0.6) # 行高 # 垂直居中 for j in range(0, 4): row_cells[j].vertical_alignment = WD_CELL_VERTICAL_ALIGNMENT.CENTER row_num = row_num + 1 doc.add_paragraph(text='', style=None) # 换行 return doc, doc_table, data_table
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- add_table_to_document_down:在 word 对象中组装列表的下部,这里所说的下部指的是用例结束部分,包含测试负责人等信息,这部分通常是固定不变的,将这部分单独拿出来作为表格的下部,此方法需要依赖于表格对象,传入 doc_table,返回 doc_table
def add_table_to_document_down(doc_table): # 表格下段 # 循环五次新增列表用来填写结果和其他信息 for _ in range(5): doc_table.add_row() # 单元格合并 merge_cells = [ (-1, 1, -1, 3), (-2, 1, -2, 3), (-3, 1, -3, 3), (-4, 1, -4, 3), (-5, 1, -5, 3) ] # 单元格文本 cell_texts = [ (('测试责任人', ''), WD_PARAGRAPH_ALIGNMENT.CENTER), (('判定结果', ''), WD_PARAGRAPH_ALIGNMENT.CENTER), (('测试时间', ''), None), (('实测截图', ''), None), (('评判标准', '每一步实际结果与预期结果相符,判定该用例通过;否则为不通过'), None) ] for row_start, col_start, row_end, col_end in merge_cells: doc_table.rows[row_start].cells[col_start].merge(doc_table.rows[row_end].cells[col_end]) for i, ((label, text), alignment) in enumerate(cell_texts[::-1]): doc_table.rows[-i-1].cells[0].text = label doc_table.rows[-i-1].cells[1].text = text if alignment is not None: p = doc_table.rows[-i-1].cells[1].paragraphs[0] p.paragraph_format.alignment = alignment # 设置列宽 col_width_dic = {0: 2, 1: 3, 2: 3, 3: 2} for col_num in range(4): doc_table.cell(0, col_num).width = Inches(col_width_dic[col_num]) return doc_table
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- excel_to_docx:用例转换的主代码,在该函数中,承担对数据的提取、去重、分组,完成数据的处理之后,将表格进行组装,传入处理后的数据,表格会将数据填入指定部分,在表格方法执行完成后,会保存文档到当前文件夹
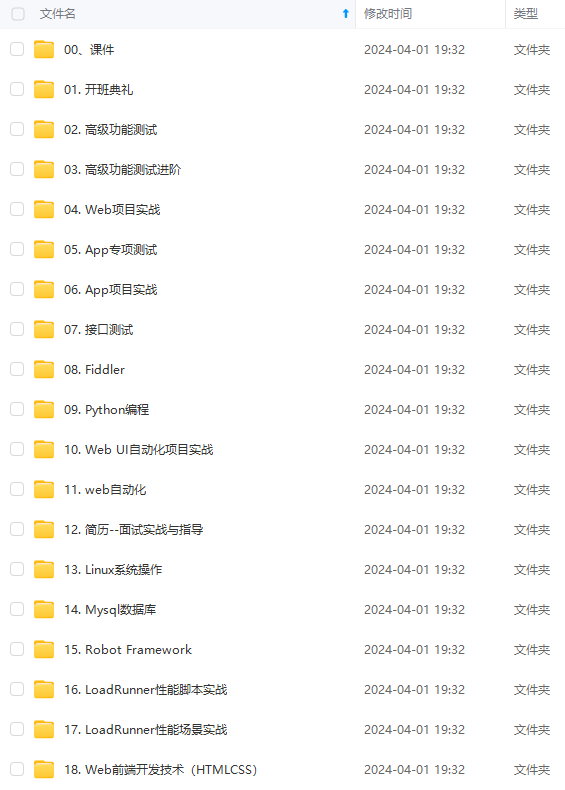
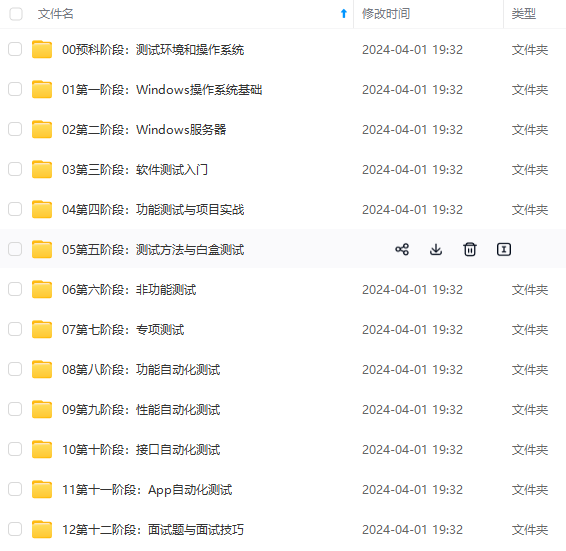
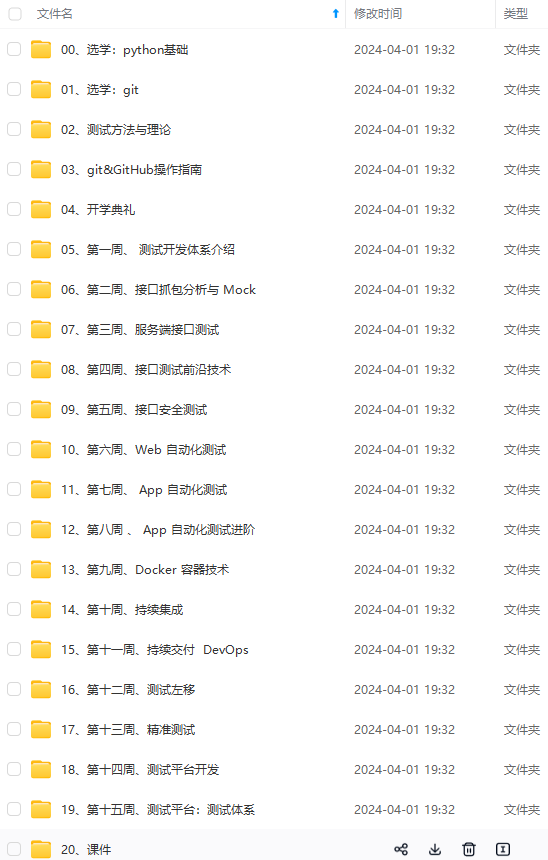
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
了95%以上软件测试知识点,真正体系化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/爱喝兽奶帝天荒/article/detail/1004155
推荐阅读
相关标签

