
- 1【会议征稿,ACM出版】2024年第四届人工智能、自动化与高性能计算国际会议(AIAHPC 2024,7月19-21)
- 2五菱carplay车机固件升级使用教程-嘟嘟桌面版_lingos车机系统升级包
- 3Java:计算地球上两个经纬度坐标之间的距离-geodesy和geotools实现_java geodesy
- 4Spring Boot 监听 Redis Key 失效事件实现定时任务_onmessage(message message, byte[] pattern)
- 5STM32 CubeIDE(七)基本定时器_stm32cubeide 温度定时采集
- 6华为最新提出的时序预测Mixers,取代Transformer实现效果速度双提升
- 7SSL证书验证失败问题解决方法_取消全局验证
- 8【0代码编程】ivx简介_ivx和ih5区别
- 9媒体邀约人物访谈,如何有效提升品牌影响力?
- 10【分布式计算框架】Spark RDD五大属性剖析 | Action 和 Transformations 算子_spark action与
自然语言处理NLP概述_nlp自然语言处理
赞
踩
大家好,自然语言处理(NLP)是计算机科学领域与人工智能领域中的一个重要方向,其研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。本文将从自然语言处理的本质、原理和应用三个方面,对其进行概述。
一、NLP的本质
NLP是一种机器学习技术,使计算机能够解读、处理和理解人类语言,其本质就是人类和机器之间沟通的桥梁。
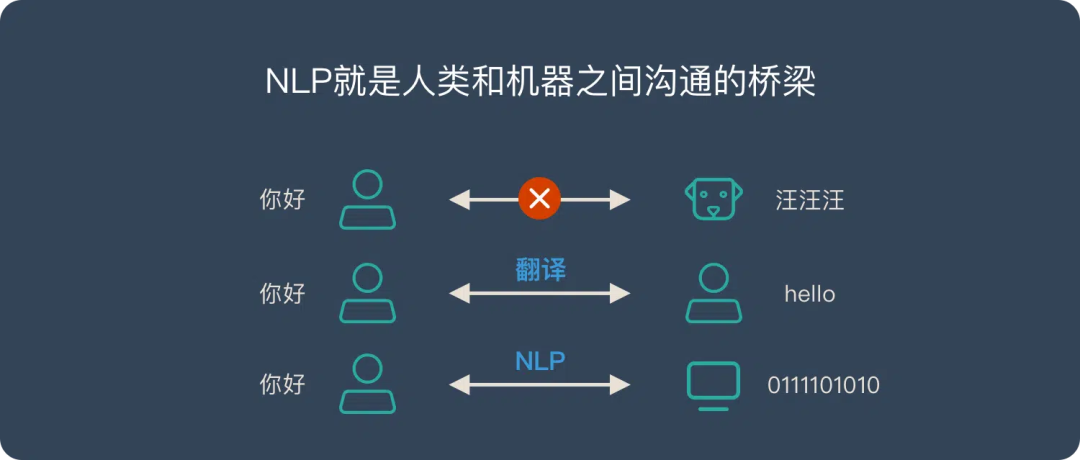
人类使用自然语言交流,如中文、英文等,狗通过叫声和其他身体语言交流,机器使用数字信息进行交流。
人类与机器之间存在交流障碍,因为人类不直接理解数字信息,而机器不直接理解自然语言。自然语言处理NLP就是人类和机器之间沟通的这座“桥梁”,NLP技术允许机器理解和生成人类使用的自然语言。
NLP的价值在于能够解锁非结构化数据的潜力,将文本转化为可分析的信息以支持企业决策,并推动人机交互向更自然、智能的方向发展。

在数字世界中,大部分数据都是非结构化的,其中文本数据尤为丰富。NLP技术能够将这些庞大且复杂的文本数据转化为可分析、可利用的信息,从而为企业决策、市场研究、用户行为分析等领域提供有力的数据支持。
随着智能设备和互联网的普及,人们越来越多地通过自然语言与机器进行交互。NLP技术能够让机器理解和回应人类的语言,从而实现更加自然和智能的人机交互体验。
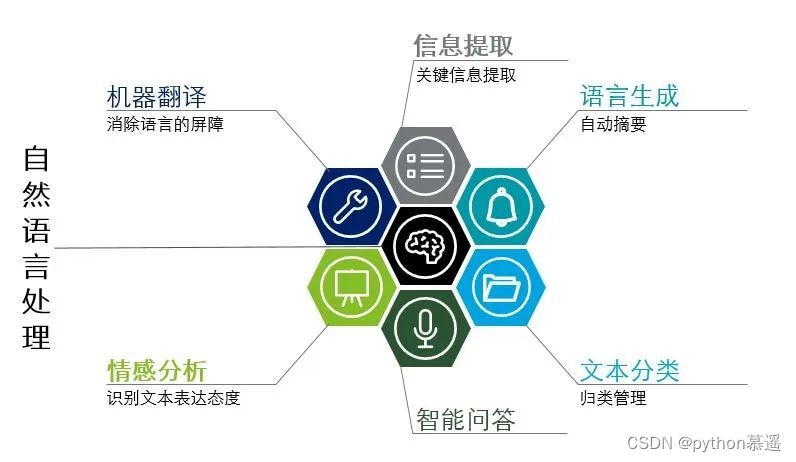
自然语言处理涵盖语义分析、信息检索与抽取、文本分类与挖掘、情感分析、问答系统、机器翻译及自动摘要等核心技术。
其核心技术如下:
-
语义文本相似度分析:分析两段文本之间的意义和本质的相似度。
-
信息检索 (IR):组织信息并通过查找满足用户信息需求的过程和技术。
-
信息抽取:从非结构化/半结构化文本中提取指定类型的信息,并将其转换为结构化信息。
-
文本分类:根据文档内容或主题自动分配预定义的类别标签。
-
文本挖掘:基于文本信息的知识发现,包括文档聚类、分类和摘要抽取等。
-
文本情感分析:使用NLP技术识别文本中的情感倾向,如正面、负面或中性。
-
问答系统 (QA):自动回答用户提出的问题,返回精准的自然语言答案。
-
机器翻译 (MT):利用计算机实现不同自然语言之间的自动翻译。
-
自动摘要:自动分析文档并提炼出要点信息,生成短篇摘要。
二、NLP的原理
NLP核心组成:NLP = NLU + NLG,NLU 负责理解内容,NLG 负责生成内容。
自然语言理解NLU负责将机器变得像人一样,具备正常人的语言理解能力。
识别意图:NLU的核心能力之一是识别用户的意图。与过去依赖固定关键词的方法不同,NLU能够从用户的自然语言表达中识别出真正的意图,如“订机票”、“查询航班”等,使得机器交互更加自然和智能。
提取关键信息:除了识别意图,NLU还能从用户的语句中提取出关键信息,如目的地、出发时间等。这使得机器能够更准确地理解用户的需求,并提供更精确的服务。
自然语言生成NLG负责将机器生成的非语言格式的数据转换成人类可以理解的语言格式。
文本到文本的生成(Text-to-Text Generation):这一过程涉及将已存在的文本内容转换成另一种形式、风格或语言的文本。例如,摘要生成、机器翻译或文本改写等。
数据到文本的生成(Data-to-Text Generation):这种方式关注的是将结构化或非结构化的数据转换成自然语言文本。例如,基于数据库的报告生成、根据统计数据编写新闻稿件,或是将图表信息转换为描述性文字等。
NLP语言模型用于捕捉语言的统计和结构特性。
- 词的独热表示(One-Hot Representation)
独热编码将每个词表示为一个向量,其中只有一个维度是1(代表该词),其余维度都是0。这种方法简单但稀疏,且无法捕捉词之间的关系。
- Bag of Words(词袋模型)
词袋模型忽略文本的语法和词序,将文本视为词的集合。它通常用于文本分类,其中每个文档被表示为一个词频向量。
- Bi-gram 和 N-gram(双词模型和多词模型)
Bi-gram模型考虑连续的两个词对的统计关系,而N-gram则考虑连续的N个词。这些模型用于捕捉词序信息,但受限于窗口大小。
- 词的分布式表示(Distributed Representation)
分布式表示,如word embeddings,将词编码为固定大小的向量,其中每个维度都捕获了词的某个方面的含义。这些向量是在大量文本上训练的,能够捕捉词之间的语义和语法关系。
-
共现矩阵(Co-occurrence Matrix)
共现矩阵记录词与词在文本中的共现频率。这种表示可以捕捉词之间的统计关系,但通常很稀疏且维度高。
- 神经网络语言模型(Neural Network Language Model, NNLM)
NNLM使用神经网络来预测给定上下文的下一个词。它通过学习词的分布式表示来捕捉语言的结构和语义信息。
- word2vec
word2vec是一种特定的神经网络架构,用于学习词的分布式表示。它有两种主要方法:Skip-gram和Continuous Bag of Words(CBOW)。word2vec能够高效地处理大规模数据集,并生成高质量的词向量。
三、NLP的应用
1.情感分析
情感分析是利用自然语言处理和文本挖掘技术,自动识别和提取文本中的情感倾向和信息。其能够快速地了解用户的舆情情况,对于企业和政府等组织来说具有重要的决策参考价值,应用于社交媒体监测、产品评论分析、市场调研等场景。
情感分析的实战流程:
(1) 数据收集与准备:
收集相关文本数据,这些数据可以是社交媒体评论、产品评价、新闻文章等。
对数据进行清洗和预处理,包括去除无关字符、标点符号、停用词,以及进行文本标准化(如转换为小写)和分词等操作。
(2) 词向量模型构建:
选择合适的词向量模型,如Word2Vec、GloVe或FastText等。使用收集到的文本数据训练词向量模型,或者下载预训练好的词向量模型,将文本中的每个词转换为对应的词向量。
(3) 特征提取:
基于词向量提取文本特征,可以使用简单的词袋模型(Bag of Words)或更复杂的TF-IDF、n-grams等方法,也可以考虑使用深度学习模型自动提取特征,如卷积神经网络(CNN)或循环神经网络(RNN)。
(4) 模型选择与训练:
选择适合情感分析任务的机器学习或深度学习模型,如逻辑回归、支持向量机(SVM)、朴素贝叶斯、长短时记忆网络(LSTM)等。使用提取的特征和对应的情感标签训练模型,对模型进行调优,包括调整超参数、使用正则化、集成学习等方法提高模型性能。
(5) 模型评估与验证:
将数据集分为训练集、验证集和测试集,用于模型的训练、验证和测试,使用准确率、精确率、召回率、F1分数等指标评估模型的性能,绘制混淆矩阵、ROC曲线等可视化工具帮助理解模型表现。
2.问答机器人
问答机器人是利用自然语言处理技术,通过智能交互来提供服务的机器人系统。其能提供7*24小时的在线服务,解答用户问题,处理任务,提高工作效率和用户满意度,应用于客户服务、电子商务、教育培训等场景。
(1) 数据收集与处理:
从各种来源(如文档、网页、社交媒体)收集相关的问题和答案数据,对数据进行预处理,包括清洗、分词、词性标注等,以便于后续的自然语言处理。
(2) 自然语言理解:
利用自然语言处理技术,如实体识别、意图识别、情感分析等,来理解用户的输入问题,将用户的自然语言输入转化为机器可以理解的内部表示形式。
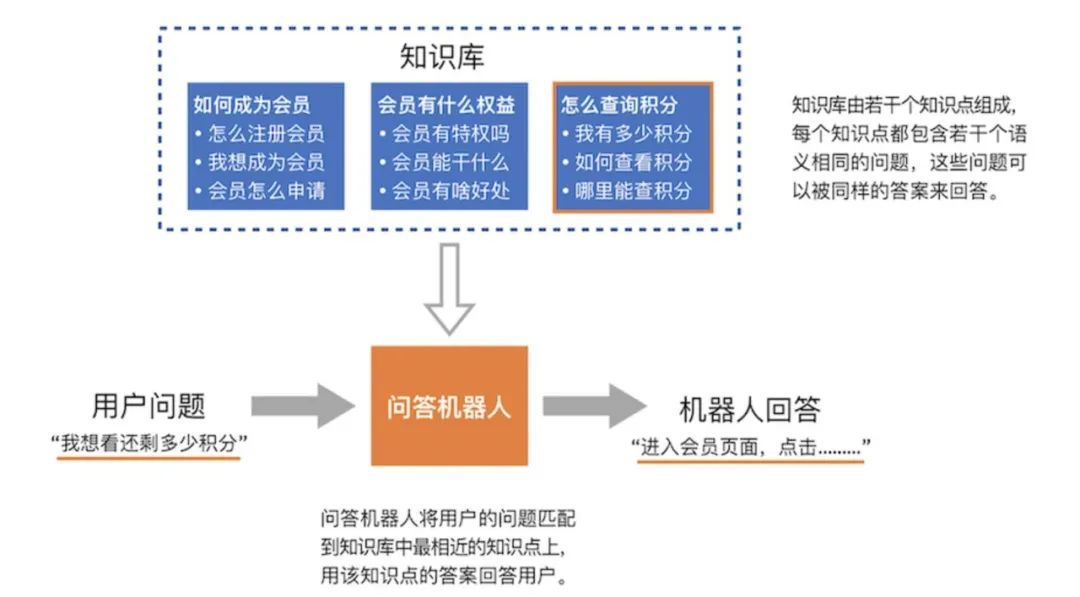
(3) 构建知识库:
将处理后的问答对存储在知识库中,形成一个结构化的知识集合,可以使用数据库、知识图谱或索引等技术来组织和管理知识。
(4) 问答匹配与检索:
设计算法来匹配用户的问题与知识库中的问答对,实现高效的检索机制,以快速找到与用户问题最相关的答案。
(5) 自然语言生成:
将检索到的答案转化为自然语言形式,以便于用户理解,可以使用自然语言生成技术,如模板生成、序列到序列模型等,来生成流畅、自然的回答。
 apisix ...
apisix ...赞
踩

