
- 1PHP-搭建Web服务器_php搭建web服务器
- 2Istio系列学习(二)----Istio架构_istio和k8s区别
- 3Pytorch使用yolov3训练自己的数据进阶_best.pt可以继续训练吗
- 4【开题报告】基于SpringBoot的在线诊疗预约系统_springboot软件设计开题报告
- 5C++Qt开发——QSS样式表_background-color: rgb(240,241,242); border: 1px so
- 6【Labview-3D虚拟平台】Labview与Solidworks联合仿真(保姆级)(下)在Labview中使用Solidworks的3D模型——装配体、父级与子级_labview 三维图片导入的是个壳
- 7linux驱动-定时器_linux驱动关闭定时器
- 8ERROR 1226 (42000): User ‘root‘ has exceeded the ‘max_connections_per_hour‘ resource (current value:_user 'root' has exceeded the 'max_connections_per_
- 9HanLP Demo(学习笔记)_hanlp训练自己领域的模型
- 10python之OCR文字识别_python ocr
机器都能写SQL了,CURD boys(girls)慌不慌_可视化curd
赞
踩
背景
结构化查询语言(Structured Query Language)简称SQL,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
CURD代表创建(Create)、更新(Update)、读取(Retrieve)和删除(Delete)操作。 大量应用业务代码,总是一些curd的东西。随着人工智能发展,机器生成代码已经变成可能,前段时间GitHub官方和openAI联合为程序员们送上编程神器——GitHub Copilot。
程序员只要写下一段注释,Github Copilot就可以补全剩下的代码、提出改进的建议。
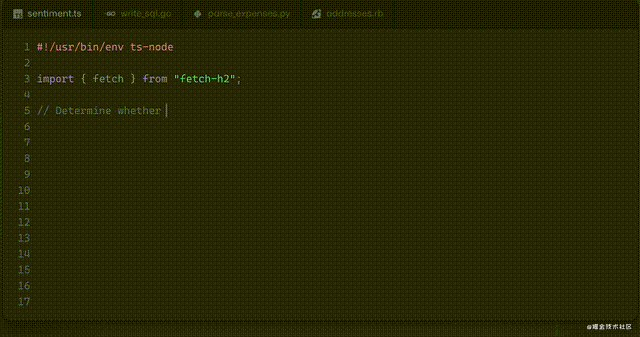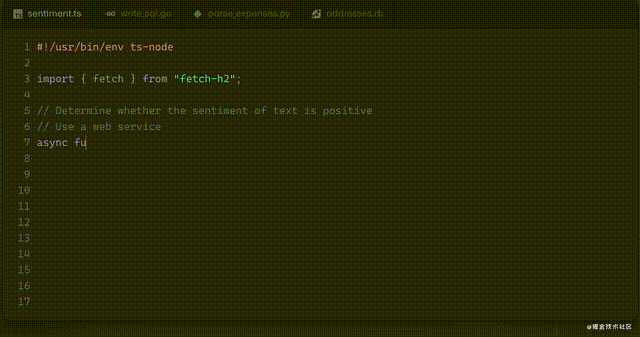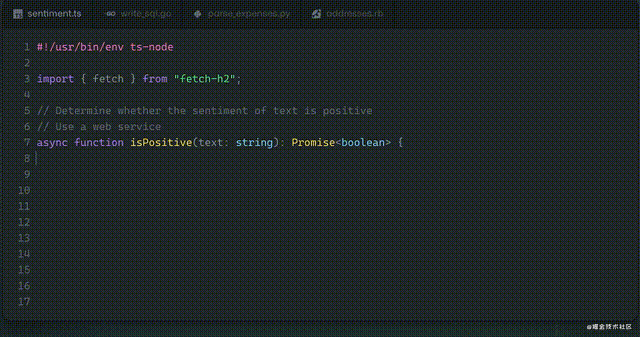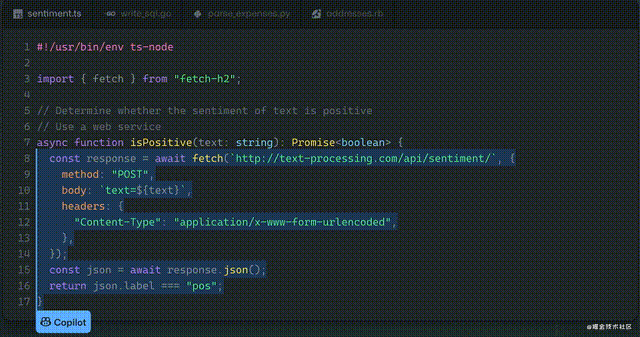
今天我们来看另一种可能性:我们输入一串汉字,计算机帮我们从数据库中直接获取我们要的统计数据。这样连代码都不用机器生成了,计算机直接可以帮终端用户解决一些常用的数据分析需求了。先来看下最终效果

系统搭建
我们先来描述下系统搭建过程,最后再介绍一下原理,搭建过程很简单,大家有时间可以自己上手实验下,这里用到了百度的Sugar可视化服务以及云数据库MemFireDB
- 我们先登录MemFireDB,将已经准备好的数据上传上去,这里我们准备三张表,stockbars股票原始信息、stockrsvs我们计算的rsv指标、stockkdj我们计算的kdj指标,具体如何上传数据以及计算指标可以参看另外一篇文章 https://juejin.cn/post/6979204911879684104

- 我们进入百度Sugar配置数据源以及数据模型,配置数据源时用到的数据库IP在MemFireDB控制台中获取,这里我们需要把表stockrsvs和stockkdjs两个表进行内连接,连接字段用stock_id和date
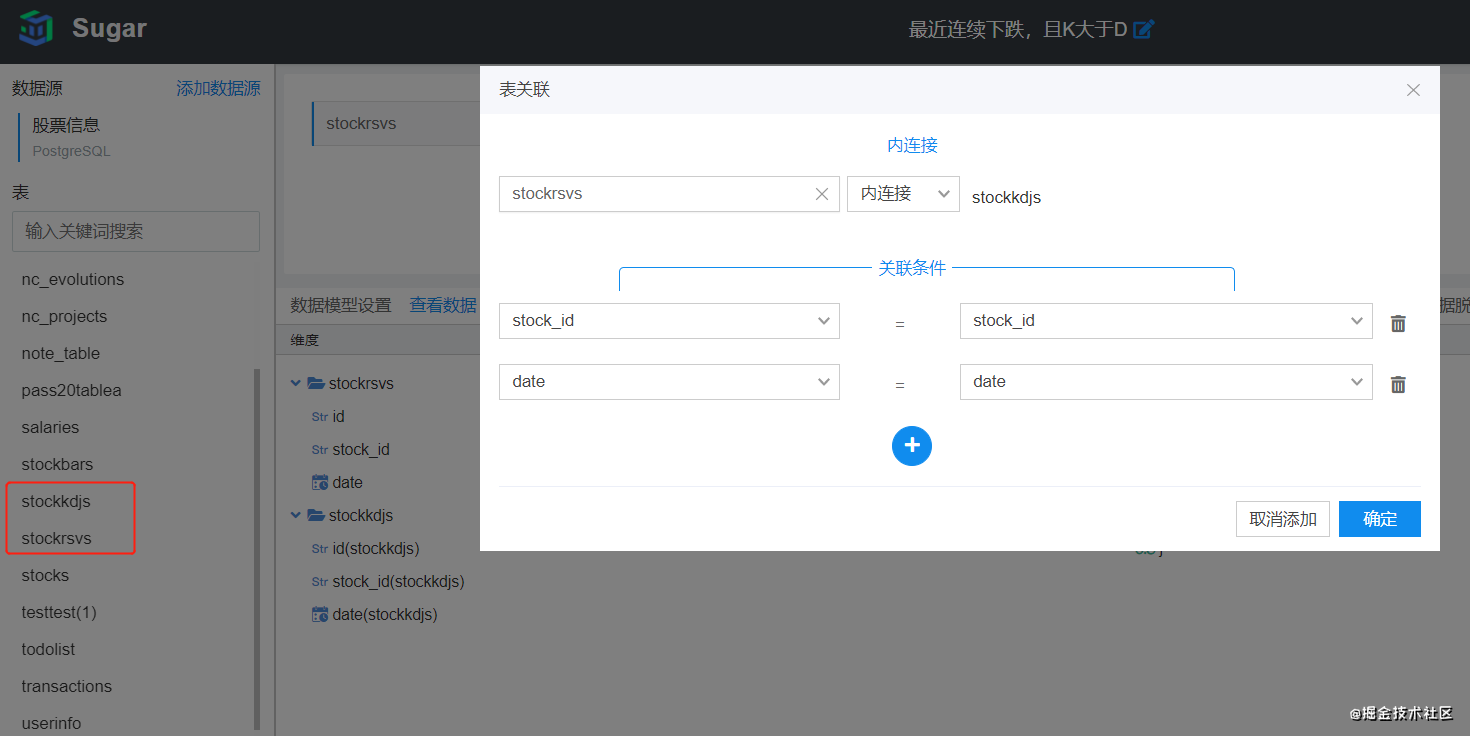
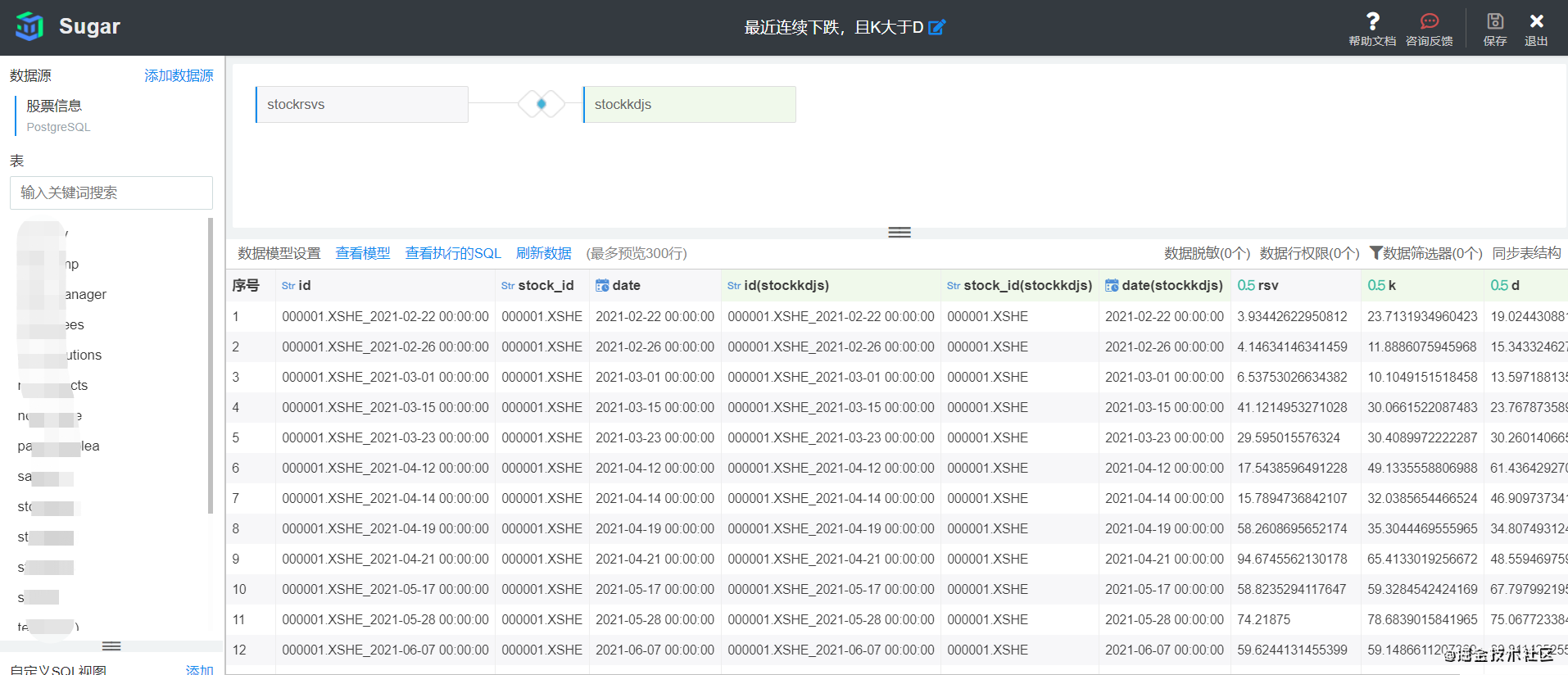
关联好的数据可以点击“查看数据”进行预览
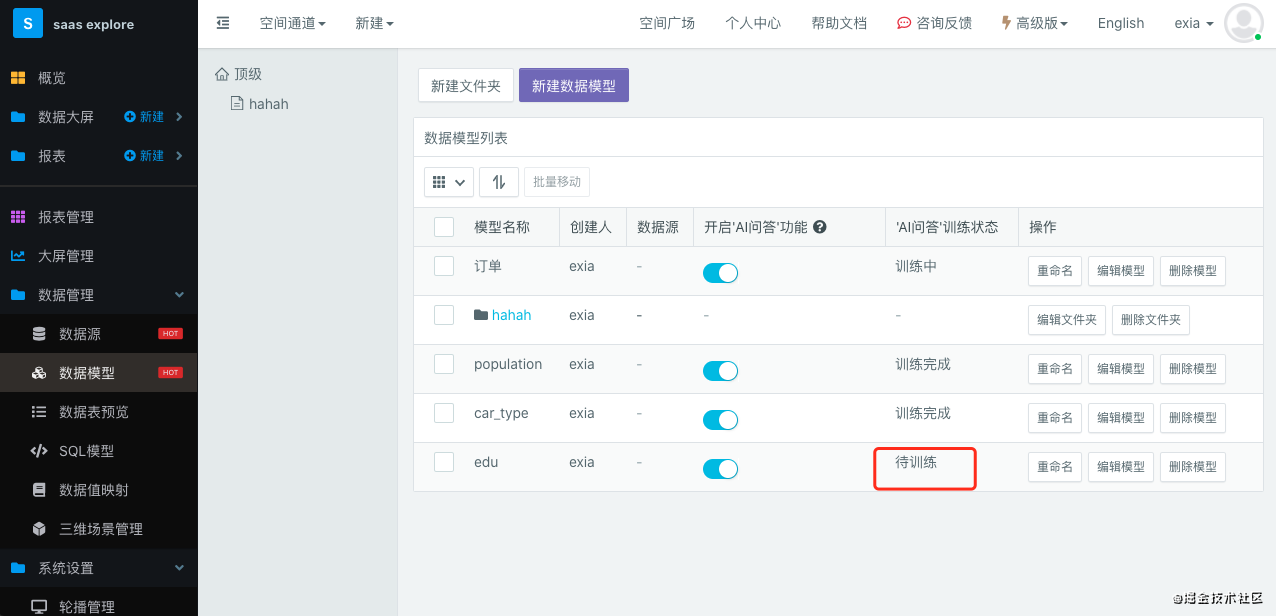
- 打开数据模型的“智能问答”选项,数据模型会先变为“待训练”,后变为“训练完成”,默认使用数据字段的「物理字段名称」以及「数据模型中的显示名称」来匹配数据字段,如果需要通过更多的说法来对数据字段进行匹配,可以对数据字段配置同义词这里还可以配置每个字段的同义词。
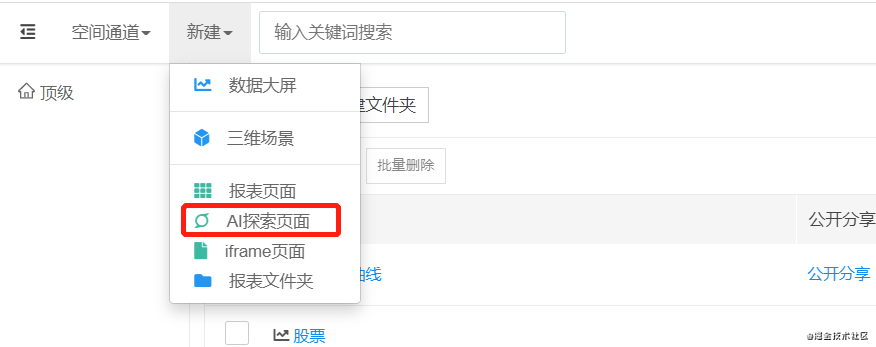
- 最后、创建“AI探索页面”,勾选已经开启了“智能问答”选项的数据模型即可完成上面视频中的效果,是不是很简单
好了,系统搭建完了,是不是迫不及待的想知道系统实现的原理呢,这里用到了数据技术以及人工智能的NL2SQL技术,数据库系统提供了数据的存取和SQL语句的解析,sugar则提供了自然语言到SQL的转换
技术原理
NL2SQL是自然语言处理技术的一个研究方向,可以将人类的自然语言自动转化为相应的SQL 语句(Structured Query Language结构化查询语言),进而可以与数据库直接交互、并返回交互的结果。比如我们问:大众 10 万到 20 万之间的车型有几种?NL2SQL可以让机器理解这样的自然语言,并从表格中检索出答案。
NL2SQL,让非专业人士,不需要学习和掌握数据库程序语言,就可以自由地查询各种丰富的数据库:
说句话就行。没有条条框框的限制,内容和信息更加丰富。以前是程序员写一个“模板”,在这个模板里查询内容。
NL2SQL的实现,运用了大量前沿的人工智能算法模型,比如运用了多个预训练语言模型,相当于AI大脑,让AI读懂用户语言;运用了图神经网络,让AI“看到”数据库, 一目十行过目不忘,而且更加清晰地分清每个表格内容。

总结
最后,前一两年NL2SQL还在一些学术研究阶段,准确率还只有60%左右,今天我们已经看到了百度已经推出了可以商用的系统,人工智能的发展太迅速了,他不光替代的是简单的重复劳动,现在连写代码的事情也可以代劳了,小伙伴们,你们颤抖么?

