
- 1Podman添加私有镜像源配置 registries.conf_/etc/containers/registries.conf
- 2探索无限:Sora与AI视频模型的技术革命 - 开创未来视觉艺术的新篇章
- 3[Android]开机自启动脚本和selinux权限配置_手机 开机自启动脚本
- 4淘宝爬虫商品销量数据采集_爬取淘宝
- 5Docker中的RabbitMQ已经启动运行,但是管理界面打不开_docker启动rabbitmq后无法访问
- 6一文看懂,python抓取m3u8里ts加密视频及合成、多线程、写入的问题_scrapy下载m3u8加密视频
- 7DNS解析-连接域名与服务器IP_dns怎么和域名关联
- 8ELF文件详解—初步认识_.elf
- 9腾讯云数据库品牌升级,大咖解读数据库三大变化_腾讯云数据库生态解读
- 10已知图像坐标系求相机坐标系_相机标定之张正友标定法数学原理详解(含python源码)...
python 换行符号_Python正则表达式由浅入深(一)
赞
踩

CDA数据分析师 出品
数据分析工作中很多任务是跟文本处理相关,比如从文本中提取客户的信息,从文本中提取时间等等都是比较常见的操作。 虽然Python处理字符串的方法很多,而且流行的pandas库也提供了大量的向量化字符串方法,但是一旦涉及要经过较为复杂的数据匹配才能进行的字符操作,这些方法就显得非常的乏力。
尤其是由于文本数据来源于爬虫等渠道,数据往往严重不规整,这时候文本处理起来就显得尤为吃力。
幸运的是Python提供了re模块,可以实现正则表达式的操作。re模块主要通过六大方法来对字符串进行处理,包括:match()、search()、findall()、split()、sub()。
这些方法涉及到字符串的匹配与替换等操作,在接下来的4篇连载文章里,我们不单只会讲解这4种方法,还会把元字符、行定位符、限定符、字符类、排除字符、选择字符、转义字符、分组等正则表达式最常用知识点贯穿起来。
接下来的系列文章将会为大家初步搭建较为完整的Python正则表达式知识体系,如果你已经学习完Python编程基础和数据清洗的课程知识,该系列文章将会让你对使用Python正则表达式达到一学就会,一用就懂的技能熟悉程度,实现真正的融会贯通的目的。
re.match方法
我们首先看re模块中较为简单的match()方法。
match 的作用是利用 Pattern 实例,从字符串左侧开始匹配,如果匹配到就返回一个 Match 实例,如果第一个字符不符合条件,就返回 None。其语法格式如下:
re.match(pattern,string,[flags])
· pattern:表示模式字符串,由要匹配的正则表达式转换而来。
· string:表示要匹配的字符串。
· flags:可选参数,表示标志位,这个参数我们后续再讲。
模式字符串是什么意思呢?先看以下例子:
pattern='企业名称'
message='企业名称:CDA数据科学研究院'
match = re.match(pattern, message)
match
Out:
这时我们发现,re.match()方法返回了一个re.match对象,但这对象里面的信息什么意思呢?
在上面的例子中,我们的模式字符串没有使用任何其他特殊字符,只是"企业名称"。
而字符串message前面几个字符串刚好是"企业名称",因此返回来的re.match对象可以解读出以下信息:
· "企业名字"这几个字符串能在message中索引区间span(0,4)中匹配上
· 匹配结果就是match='企业名称'
另外,re.match对象还可以通过调用.start()方法以及.end()来获取匹配值的开始和结束位置:
match.start()
match.end()
也可以通过.span()方法获得记载匹配字符所处位置索引的元组:
match.span()
Out: (0, 4)
在message中被匹配上的字符串可以通过.group()方法获得:
match.group()
Out:'企业名称'
被匹配的字符串可以通过re.match对象的string属性来调用:
match.string
Out:'企业名称:CDA数据科学研究院'

re.search方法
如果说,要匹配字符串并非出现在message的开头,而是中间,match()方法就没办法匹配上了,这时候可以使用re.search()方法。
比如我们想要匹配message中的"CDA数据科学院研究院",我们将pattern指向对象改成"企业名称",调用re.search()方法即可:
pattern='CDA数据科学研究院'
message='企业名称:CDA数据科学研究院'
search = re.search(pattern, message)
search
Out:
值得注意的是,re.search()方法结果返回的也是re.match对象,因此前面提及到的该类对象的方法和属性同样可以调用。
search.start()
search.end()
search.span()
search.group()
search.string
Out:5
15
(5, 15)
'CDA数据科学研究院'
'企业名称:CDA数据科学研究院'
元字符
好,我们继续思考,如果我们想要将message中"CDA"后面的一个字符也匹配上,pattern该如何写?
pattern='CDA.'
message='企业名称:CDA数据科学研究院邮箱:1918560461@qq.com'
search = re.search(pattern, message)
search
Out:
通过上面的例子我们会发现,message中字符串"CDA"后面的"数"字也匹配上了,这只需要在设置pattern的时候,在字符串"CDA"后面多加一个圆点,而这圆点的作用就是可以帮你匹配除了换行符以外的任意字符。
除此之外,我们还可以把圆点换成"w",最终效果也是一样的:
pattern='CDAw'
message='企业名称:CDA数据科学研究院邮箱:1918560461@qq.com'
search = re.search(pattern, message)
search
Out:
"w"的作用就是可以帮你匹配字符、数字、下划线或者是汉字。
而这些符号叫做元字符。
除了圆点和"w"以外,还有以下元字符:
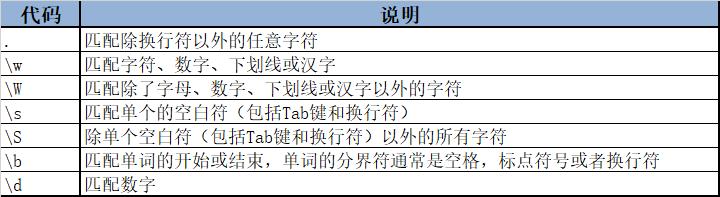
这里需要注意的是,由于元字符大多数都包含特殊字符和反斜杠,因此,为了匹配原生字符串,可以在元字符之前添加r或R,如:
pattern=r'bCDA.{5}' # 在元字符之前添加r
message='企业名称:经管之家CDA数据科学研究院 CDA数据分析师邮箱:1918560461@qq.com'
search = re.search(pattern, message)
print(search)
Out:
在上面的例子中,我们还需要注意的就是,由于模式字符串中带有元字符"b",而"b"会匹配分界符(空格,标点符号或换行符)。
因此messgae中左边起第一个"CDA"字符串前面由于没有分界符,最终匹配的是第二个"CDA"字符串。
那么上面模式字符串中出现的花括号"{}"是什么意思呢?这就是我们接下来要讲解的限定符。
限定符
前面学习了元字符,我们配合re.match()方法和re.search()方法就可以进行非常灵活的字符匹配。
但是只有元字符还有很多地方无法解决,比如,我们希望匹配字符串'企业名称:CDA数据科学研究院邮箱:1918560461@qq.com'中的邮箱,该怎么办?
这个时候,我们就可以在模式字符串中添加限定符:
pattern='邮箱:.{17}'
message='经管之家CDA数据科学研究院邮箱:1918560461@qq.com'
search = re.search(pattern, message)
print(search)
Out:
上面的patrern参数设置的原理是:既然是要匹配出message中的邮箱信息,而邮箱信息是在messaage中字符串"邮箱:"的后面,如果邮箱信息的长度为1,pattern可以写成"邮箱:.".
但是该邮箱信息长度为17个字符,也就是说,要匹配message中"邮箱:"后面的17个字符,这时在上面的pattern后面添加限定符"{17}"就可以匹配17个字符(不包括换行符)。
但是如果邮箱信息长度不是为17,那该怎么办?由于邮件信息就是在message中字符串"邮箱:"的后面一直到末端,因此我们可以这样写:
pattern='邮箱:.*'
message='经管之家CDA数据科学研究院邮箱:1918560461@qq.com'
search = re.search(pattern, message)
print(search)
Out:
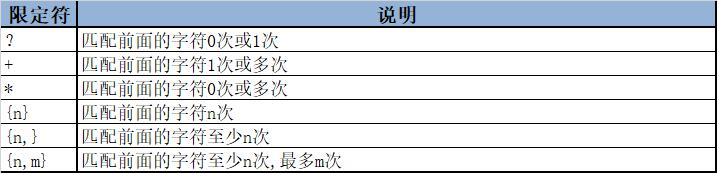
除了上面提及的"{n}"和"*"以外,还有那些常用的限定符呢?
这里需要给大家一个提醒的是,由于元字符"."是匹配除了换行符以外的任意字符,因此,即使我们的message中,邮箱信息后面如果有换行,上面的方法依然可以匹配出邮箱信息,比如:
pattern='邮箱:.*'
message='企业名称:CDA数据科学研究院邮箱:1918560461@qq.com地址:北京市海淀区厂洼街3号2号楼2-3层网址:www.cda.cn'
search = re.search(pattern, message)
print(search)
Out:
但是,如果上面的message中"地址"两个字的前面没有换行符""呢?该如何匹配出邮箱信息?
我们只需要在pattern中星号的后面加上邮箱地址最后的字符"com"作为匹配的结束即可:
pattern='邮箱:.*com'
message='企业名称:CDA数据科学研究院邮箱:1918560461@qq.com地址:北京市海淀区厂洼街3号2号楼2-3层网址:www.cda.cn'
search = re.search(pattern, message)
print(search)
Out:


