
热门标签
热门文章
- 1adb 一些常用的命令_adb 根据包名进入原生系统
- 2python+django共享电动车单车管理系统_共享电动车系统
- 3当“软件定义汽车”遇上“硬件拖软件的后腿”_当软件定义汽车遇上硬件拖累软件
- 4什么是 Schnorr 签名?_shnorr聚合签名
- 5YOLOv5代码解读[02] models/yolov5l.yaml文件解析_[-1,1,conv,[64,6,2,2]]
- 6redis登录测试hydra以及python脚本方式_hydra redis
- 7【面试】Morgan Stanley IT面经_摩根士丹利 面经
- 8Qt Visual Studio Tools 3.0发布_legacy qt visual studio tools
- 9ElasticSearch-IK分词器(elasticsearch插件)安装配置和ElasticSearch的Rest命令测试_ik分词器测试
- 10大语言模型-中文chatGLM-LLAMA微调_chatglm llama
当前位置: article > 正文
KFold解释和代码实现
作者:盐析白兔 | 2024-02-19 23:41:35
赞
踩
kfold
KFold解释和代码实现
一、KFold是什么?
0,1,2,3:每一行表示测试集和训练集的划分的一种方式。
class:表示类别的个数(下图显示的是3类),有些交叉验证根据类别的比例划分测试集和训练集(例三)。
group:表示从不同的组采集到的样本,颜色的个数表示组的个数(有些时候我们关注在一组特定组上训练的模型是否能很好地泛化到看不见的组)。举个例子(解释“组”的意思):我们有10个人,我们想要希望训练集上所用的数据来自(1,2,3,4,5,6,7,8),测试集上的数据来自(9,10),也就是说我们不希望测试集上的数据和训练集上的数据来自同一个人(如果来自同一个人的话,训练集上的信息泄漏到测试集上了,模型的泛化性能会降低,测试结果会偏好)。
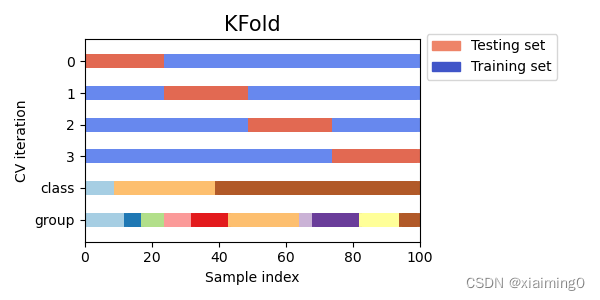
KFold 将所有样本分成样本个数相等的k个样本组,称为折叠(如果 k=n ,n是样本的个数,这相当于 Leave One Out 策略)。使用(k-1)折叠训练模型,并使用剩余的一折叠进行测试。
二、 实验数据设置
2.1 实验数据生成代码
X, y = np.arange(0,60).reshape((30,2)), np.hstack(([0] * 3, [1] * 9, [2] * 18))
print("数据:", end=" ")
for l in X:
print(l, end=' ')
print("")
print("标签:", y)
- 1
- 2
- 3
- 4
- 5
- 6
2.2 代码结果
数据: [0 1] [2 3] [4 5] [6 7] [8 9] [10 11] [12 13] [14 15] [16 17] [18 19] [20 21] [22 23] [24 25] [26 27]
[28 29] [30 31] [32 33] [34 35] [36 37] [38 39] [40 41] [42 43] [44 45] [46 47] [48 49] [50 51] [52 53]
[54 55] [56 57] [58 59]
标签: [0 0 0 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
- 1
- 2
- 3
- 4
数据个数、标签个数:30个
类别个数:3个(分别是0,1,2,比例是0.1:0.3:0.6和class每类对应)
组别(group):由于KFold交叉验证结果和group无关,所以这里不再设置(其实也和class无关,但是我们要通过类别观察实验现象,所以进行了设置)。
三、实验代码
3.1 实验代码
代码如下:
from sklearn.model_selection import StratifiedKFold, KFold import numpy as np # X, y = np.ones((30, 1)), np.hstack(([0] * 20, [1] * 10)) # print(np.arange(0,30).reshape((30,1))) X, y = np.arange(0,60).reshape((30,2)), np.hstack(([0] * 3, [1] * 9, [2] * 18)) print("数据:", end=" ") for l in X: print(l, end=' ') print("") print("标签:", y) kf = KFold(n_splits=3) for i,(train, test) in enumerate(kf.split(X)): print("=================KFold 第%d折叠 ===================="% (i+1)) print('train - {}'.format(np.bincount(y[train]))) print(" 训练集索引:%s" % train) print(" 训练集标签:", y[train]) print(" 训练集数据:", end=" ") for l in X[train]: print(l, end=' ') print("") # print(" 训练集数据:", X[train]) print("test - {}".format(np.bincount(y[test]))) print(" 测试集索引:%s" % test) print(" 测试集标签:", y[test]) print(" 测试集数据:", end=" ") for l in X[test]: print(l, end=' ') print("") # print(" 测试集数据:", X[test]) print("=============================================================")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
3.2 实验结果
结果如下:
数据: [0 1] [2 3] [4 5] [6 7] [8 9] [10 11] [12 13] [14 15] [16 17] [18 19] [20 21] [22 23] [24 25] [26 27] [28 29] [30 31] [32 33] [34 35] [36 37] [38 39] [40 41] [42 43] [44 45] [46 47] [48 49] [50 51] [52 53] [54 55] [56 57] [58 59] 标签: [0 0 0 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2] =================KFold 第1折叠 ==================== train - [ 0 2 18] 训练集索引:[10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29] 训练集标签: [1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2] 训练集数据: [20 21] [22 23] [24 25] [26 27] [28 29] [30 31] [32 33] [34 35] [36 37] [38 39] [40 41] [42 43] [44 45] [46 47] [48 49] [50 51] [52 53] [54 55] [56 57] [58 59] test - [3 7] 测试集索引:[0 1 2 3 4 5 6 7 8 9] 测试集标签: [0 0 0 1 1 1 1 1 1 1] 测试集数据: [0 1] [2 3] [4 5] [6 7] [8 9] [10 11] [12 13] [14 15] [16 17] [18 19] ============================================================= =================KFold 第2折叠 ==================== train - [ 3 7 10] 训练集索引:[ 0 1 2 3 4 5 6 7 8 9 20 21 22 23 24 25 26 27 28 29] 训练集标签: [0 0 0 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2] 训练集数据: [0 1] [2 3] [4 5] [6 7] [8 9] [10 11] [12 13] [14 15] [16 17] [18 19] [40 41] [42 43] [44 45] [46 47] [48 49] [50 51] [52 53] [54 55] [56 57] [58 59] test - [0 2 8] 测试集索引:[10 11 12 13 14 15 16 17 18 19] 测试集标签: [1 1 2 2 2 2 2 2 2 2] 测试集数据: [20 21] [22 23] [24 25] [26 27] [28 29] [30 31] [32 33] [34 35] [36 37] [38 39] ============================================================= =================KFold 第3折叠 ==================== train - [3 9 8] 训练集索引:[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19] 训练集标签: [0 0 0 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2] 训练集数据: [0 1] [2 3] [4 5] [6 7] [8 9] [10 11] [12 13] [14 15] [16 17] [18 19] [20 21] [22 23] [24 25] [26 27] [28 29] [30 31] [32 33] [34 35] [36 37] [38 39] test - [ 0 0 10] 测试集索引:[20 21 22 23 24 25 26 27 28 29] 测试集标签: [2 2 2 2 2 2 2 2 2 2] 测试集数据: [40 41] [42 43] [44 45] [46 47] [48 49] [50 51] [52 53] [54 55] [56 57] [58 59] ============================================================= 进程已结束,退出代码 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
3.3 结果解释
可以看到测试集标签里面有0,但是训练集标签里没有0——这没办法做测试。
可以看到第1折叠的结果,测试集数据和测试集数据的标签对应和图上的第0行对应。
=================KFold 第1折叠 ====================
train - [ 0 2 18]
训练集索引:[10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29]
训练集标签: [1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
训练集数据: [20 21] [22 23] [24 25] [26 27] [28 29] [30 31] [32 33] [34 35] [36 37] [38 39] [40 41] [42 43] [44 45] [46 47] [48 49] [50 51] [52 53] [54 55] [56 57] [58 59]
test - [3 7]
测试集索引:[0 1 2 3 4 5 6 7 8 9]
测试集标签: [0 0 0 1 1 1 1 1 1 1]
测试集数据: [0 1] [2 3] [4 5] [6 7] [8 9] [10 11] [12 13] [14 15] [16 17] [18 19]
=============================================================
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
四、总结
KFold:不考虑标签(class)和组(group)的影响。
- 有时候测试集包含某一类的全部标签,而训练集不包含该类的样本。也就是说没经过训练,就要测试(KFold 第1折叠)。
- 适用于数据比较平衡,数据来自同一组(同一个机器,不同故障)的时候。
- 记住要打乱数据。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/117343?site
推荐阅读
相关标签

