
热门标签
热门文章
- 1uniapp上传文件到腾讯云
- 2kernel起来后报错_avb_slot_verify.c:757: error: vbmeta: error verify
- 3【UE4】物理引擎(蓝图)_ue4引擎
- 4[词根词缀]cre/cred/crit/cult字根由来及词源C的故事_coach词根词缀
- 5echarts Map(地图) 波纹数据点_acroutes
- 6网络图片加载(Universal_Image_Loader,Volley)_baseimagedownloader volley
- 7[Python] remove()方法
- 8懒加载jquery.lazyload.js
- 9ArkTS的Tabs和TabContent(仿微信布局)_arkts tabcontent
- 10放个烟花迎接龙年春节吧
当前位置: article > 正文
基于用户的协同过滤推荐算法实现原理及实现代码_基于用户的协同过滤推荐算法代码
作者:盐析白兔 | 2024-02-21 12:00:30
赞
踩
基于用户的协同过滤推荐算法代码
基于用户的协同过滤推荐算法实现原理及实现代码
一、基于用户的协同过滤推荐算法实现原理
传统的基于用户(User-Based)的协同过滤推荐算法实现原理分四个步骤:
1.根据用户历史行为信息构建用户-项目评分矩阵,用户历史行为信息包括项目评分、浏览历史、收藏历史、喜好标签等,本文以单一的项目评分为例,后期介绍其他行为信息和混合行为信息,用户-项目评分矩阵如表1所示:
| 项目1 | 项目2 | 项目3 | |
|---|---|---|---|
| 用户A | 1 | 0 | 5 |
| 用户B | 3 | 4 | 0 |
| 用户C | 0 | 3 | 2 |
| 注:用户A对项目1的评分是1分,用户A对项目2没有评分。 |
- 根据用户-项目评分矩阵计算用户之间的相似度。计算相似度常用的方法有余弦算法、修正余弦算法、皮尔森算法等等(后期我们会将相似度算法展开讲解,这里以余弦算法为例)。余弦算法公式如图1所示:
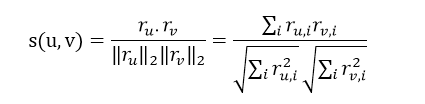
注:r_u表示用户u的评分集合(也就是矩阵中的一行评分数据),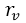 表示用户v的评分集合,i表示项目,
表示用户v的评分集合,i表示项目,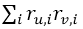 表示用户u对项目1的评分乘以用户v对项目1的评分加上用户u对项目2的评分乘以用户v对项目2的评分……先相加再相乘直到最后一个项目,
表示用户u对项目1的评分乘以用户v对项目1的评分加上用户u对项目2的评分乘以用户v对项目2的评分……先相加再相乘直到最后一个项目, 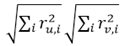 表示用户u对项目1的评分的平方加上用户u对项目2的评分的平方加上……先平方再相加直到最后一个项目然后得到的值取平方根,平方根乘以用户v的平方根。
表示用户u对项目1的评分的平方加上用户u对项目2的评分的平方加上……先平方再相加直到最后一个项目然后得到的值取平方根,平方根乘以用户v的平方根。 - 根据用户之间的相似度得到目标用户的最近邻居KNN。KNN的筛选常用的有两种方式,一种是设置相似度阀值(给定一个相似度的下限,大于下限的相似度为最近邻居),一种是根据与目标用户相似度的高低来选择前N个最近邻居(本次以前N个为例,后期会详细对比讲解两者)。相似度排序可用经典冒泡排序法。
- 预测项目评分并进行推荐。最常用的预测公式如图2所示:
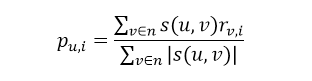
注:该公式实际上是相似度和评分的加权平均数。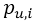 表示用户u对项目i的预测评分,n是最近邻集合,v是任意一个最近邻居,
表示用户u对项目i的预测评分,n是最近邻集合,v是任意一个最近邻居,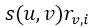 表示最近邻v和目标用户u的相似度乘以最近邻v对项目i的评分。得到预测评分后按照评分高低进行降序推荐。
表示最近邻v和目标用户u的相似度乘以最近邻v对项目i的评分。得到预测评分后按照评分高低进行降序推荐。 - 结论。以上步骤是最简单,最传统的基于用户的协同过滤推荐算法的实现原理,但是在实现过程中还是有很多注意细节。
二、基于用户的协同过滤推荐算法实现代码
本文我们介绍两种实现代码,都是java语言开发,单机版(本地测试),数据集使用movielens的ml-100k,943*1682,80000条数据。
第一种,自定义实现:
1、项目目录,如图3所示:

2、运行结果
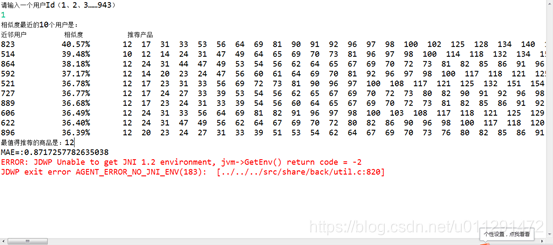
第二种,使用mahout api接口实现:
mahout是一个算法包,实现了很多协同过滤推荐算法接口,传统的基于用户的协同过滤推荐算法调用步骤很固定,运行结果如下:


声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/123582
推荐阅读
相关标签

