
- 1某赛通电子文档安全管理系统 UploadFileToCatalog SQL注入漏洞复现_亿赛通电子文档安全管理系统 uploadfiletocatalog sql注入
- 2破坏计算机系统什么罪,破坏计算机信息系统罪是什么
- 3【Unity每日一记】音频,麦克风,粒子和拖尾渲染器_unity 麦克风
- 4进程间通信(IPC)----Unix域socket(命名socket)_c语言本地socket采用af_unix域抽象命名时,客户端怎么使用与服务端不同的命名文件
- 5Centos7下Samba服务器配置_centos7samba服务器配置
- 6钉钉电脑版扫描登录不了出现二维码失效和手机上确认登录电脑端没反应_203.119.129.47:443
- 7sdkmanager工具安装
- 8sklearn学习之KNN
- 9Java快递服务系统(开题+源码)
- 10R语言进阶 | 程序结构控制_x_option <- function(x) { if (x == "a")
三种经典的图像分类的模型_图片分类的模型
赞
踩
1. VGG网络
《Very Deep Convolutional Networks For Large Scale Image Recognition》
In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3 × 3) convolution filters, which shows that a significant improvement on the prior-art configurations can be achieved by pushing the depth to 16–19 weight layers. These findings were the basis of our ImageNet Challenge 2014
submission, where our team secured the first and the second places in the localisation and classification tracks respectively. We also show that our representations generalise well to other datasets, where they achieve state-of-the-art results. We have made our two best-performing ConvNet models publicly available to facilitate further research on the use of deep visual representations in computer vision.
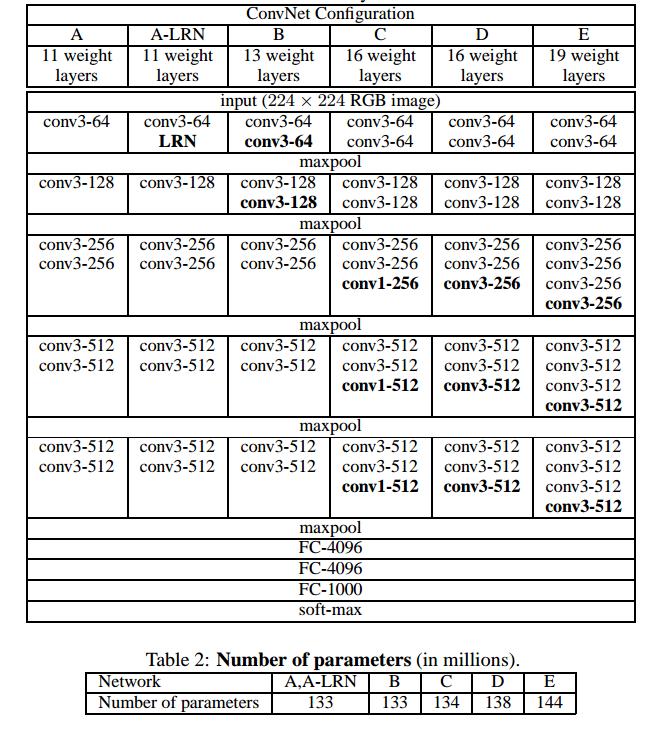
VGG网络分为VGG16和VGG19,16是指卷积层 + 全连接层, 池化层不包括进去,因为池化层没有参数需要进行训练。2.1Architecture提到在VGG中LRN(Local Response Normalization)局部响应归一化并没有起到提升性能的作用,反而增加了内存的消耗和计算时间。LRN在现在的网络中可能已经越来越不被使用了。
All hidden layers are equipped with the rectification (ReLU (Krizhevsky et al., 2012)) non-linearity. We note that none of our networks (except for one) contain Local Response Normalisation (LRN) normalisation (Krizhevsky et al., 2012): as will be shown in Sect. 4, such normalisation does not improve the performance on the ILSVRC dataset, but leads to increased memory consumption and computation time. Where applicable, the parameters for the LRN layer are those of (Krizhevsky et al., 2012).
在VGG网络中从头到尾使用的是3x3的卷积核,使用这种小卷积核会带来两个主要的好处,在论文中一一提到了:一是两个3x3卷积具有和5x5卷积相同的感受野,三个3x3卷积具有和7x7相同的感受野,但是与它们后者相比却增加了非线性Relu的个数,从而增加了决策函数的非线性;二是较少了参数数量(3x3x3<7x7)。同样地,1x1的卷积在有些地方保持输入和输出通道数一致,并没有起到降维减少参数的作用,但是却通过额外的Relu引入了非线性。非线性会使决策函数更容易进行区分(为什么)。
Rather than using relatively large receptive fields in the first conv. layers (e.g. 11×11 with stride 4 in (Krizhevsky et al., 2012), or 7×7 with stride 2 in (Zeiler & Fergus, 2013; Sermanet et al., 2014)), we use very small 3 × 3 receptive fields throughout the whole net, which are convolved with the input at every pixel (with stride 1). It is easy to see that a stack of two 3×3 conv. layers (without spatial pooling in between) has an effective receptive field of 5×5; three such layers have a 7 × 7 effective receptive field. So what have we gained by using, for instance, a stack of three 3×3 conv. layers instead of a single 7×7 layer?
- First, we incorporate three non-linear rectification layers instead of a single one, which makes the decision function more discriminative.
- Second, we decrease the number of parameters: assuming that both the input and the output of a three-layer 3 × 3 convolution stack has C channels, the stack is parametrised by 3x3x3 C2 = 27C2 weights; at the same time, a single 7 × 7 conv. layer would require 7x7C2 = 49C2 parameters, i.e. 81% more. This can be seen as imposing a regularisation on the 7 × 7 conv. filters, forcing them to have a decomposition through the 3 × 3 filters (with non-linearity injected in between).
The incorporation of 1 × 1 conv. layers (configuration C, Table 1) is a way to increase the nonlinearity of the decision function without affecting the receptive fields of the conv. layers. Even though in our case the 1 × 1 convolution is essentially a linear projection onto the space of the same dimensionality (the number of input and output channels is the same), an additional non-linearity is introduced by the rectification function. It should be noted that 1 × 1 conv. layers have recently been utilised in the “Network in Network” architecture of Lin et al. (2014).
网络结构和参数量
多尺度的数据裁剪
在3.1Training中提到了通过在原始数据集上进行多尺度的数据裁剪,这也是数据增强的一种方式,代码如下:
def _preprocess(image):
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
image = tf.multiply(tf.subtract(image, 0.5), 2)
image = tf.reshape(image, [64, 64, 3])
image = tf.random_crop(image, [54, 54, 3])
return image
- 1
- 2
- 3
- 4
- 5
- 6
2.GoogLeNet网络
googlenet的主要思想就是围绕这两个思路去做的:
- 深度,层数更深,文章采用了22层,为了避免上述提到的梯度消失问题,googlenet巧妙的在不同深度处增加了两个loss来保证梯度回传消失的现象。
- 宽度,增加了多种核 1x1,3x3,5x5,还有直接max pooling的,但是如果简单的将这些应用到feature map上的话,concat起来的feature map厚度将会很大,所以在googlenet中为了避免这一现象提出的inception具有如下结构,在3x3前,5x5前,max pooling后分别加上了1x1的卷积核起到了降低feature map厚度的作用。
《Going deeper with convolutions》在论文的摘要中提到了Hebbian Principle,Hebbian principle的精确表达就是如果两个神经元常常同时产生动作电位,或者说同时激动(fire),这两个神经元之间的连接就会变强,反之则变弱(neurons that fire together, wire together)。
We propose a deep convolutional neural network architecture codenamed Inception that achieves the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC14). The main hallmark of this architecture is the improved utilization of the computing resources inside the network. By a carefully crafted design, we increased the depth and width of the network while keeping the computational budget constant.
To optimize quality, the architectural decisions were based on the Hebbian principle and the intuition of multi-scale processing. One particular incarnation used in our submission for ILSVRC14 is called GoogLeNet, a 22 layers deep network, the quality of which is assessed in the context of classification and detection.
GoogLeNet的层数达到了22Layers,但是却能使用比AlexNet少12倍的参数量。这里面的原因主要是虽然看上去GoogLeNet更宽更深,使用了更多的卷积,但是每一个Inception块的分支上都有1x1卷积,起到了非常大的降维的作用。 文章已开始就特意强调Hebbian Principle, 意思难道是尽管使用了Inception块,并且也使用了22Layers, 但是只有某些特定相关性比较强的层会被用于计算。
Our GoogLeNet submission to ILSVRC 2014 actually uses 12 times fewer parameters than the winning architecture of Krizhevsky et al [9] from two years ago, while being significantly more accurate.
不断增加网络的深度可以提高网络的性能,但随着网络层数的不断增加,会带来两个主要的问题:一是过拟合,训练数据不足;二是计算资源的浪费,因为网络中大量神经元激活函数的输出最后会变为零。
- Bigger size typically means a larger number of parameters, which makes the enlarged network more prone to overfitting, especially if the number of labeled examples in the training set is limited. This is a major bottleneck as strongly labeled datasets are laborious and expensive to obtain, often requiring expert human raters to distinguish between various fine-grained visual categories such as those in ImageNet (even in the 1000-class ILSVRC subset) as shown in Figure 1.
- The other drawback of uniformly increased network size is the dramatically increased use of computational resources. For example, in a deep vision network, if two convolutional layers are chained, any uniform increase in the number of their filters results in a quadratic increase of computation. If the added capacity is used inefficiently (for example, if most weights end up to be close to zero), then much of the computation is wasted. As the computational budget is always finite, an efficient distribution of computing resources is preferred to an indiscriminate increase of size, even when the main objective is to increase the quality of performance.
解决这两个问题的方法:
解决这两个问题的基本方法最终一般是把全连接改成稀疏连接的结构,甚至包括在卷积中也这么做。除了模拟生物系统,根据Arora【2】的突破性研究证明,这样做也可以在理论上获得更强健的系统。 Arora等人的主要结果显示如果数据集的概率分布是一个十分稀疏的大型神经网络所能表达的,那么最合适的网络拓扑结构可以通过分析每一步的最后一层激活函数的统计关联性,并将具有高相关性输出的神经元进行聚类,而将网络一层一层地搭建起来。虽然严格的数学证明需要很强的条件,但事实上这种情况符合著名的赫布原则——神经元如果激活条件相同,它们会彼此互联——这意味着在实践中,赫布原则在不那么严苛的条件下还是可以使用。【转自百度百科:Hebb学习规则是一个无监督学习规则,这种学习的结果是使网络能够提取训练集的统计特性,从而把输入信息按照它们的相似性程度划分为若干类。这一点与人类观察和认识世界的过程非常吻合,人类观察和认识世界在相当程度上就是在根据事物的统计特征进行分类。Hebb学习规则只根据神经元连接间的激活水平改变权值,因此这种方法又称为相关学习或并联习。】
在论文的3.动机与高层设计考虑和4.结构细节 这两部分包含的理论深奥复杂,非常难以理解。应该重点理解它这里说的“局部最优的稀疏结构”,这种结构是通过卷积块的堆叠(Inception模块)来实现。
3 动机与高层设计考虑
最直接提高深度神经网络性能的方法是增加其规模,包括通过增加层数以增大深度,通过增加每一层的节点数以增加宽度。这是训练高质量模型最简单安全的方法,特别是对于给定的大规模标签数据集。然而这种简单的解决方法有两大缺陷。
更大的网络规模往往意味着更多的参数,这使得扩大后的网络更易过拟合,特别是当训练集中的标签样例有限的时候。这能够变成一个主要的瓶颈,因为制作高质量的训练集是要技巧的,也是很昂贵的,特别是人类专家对于类别力度的准确把握对于ImageNet这样的数据集而言是很重要的(即使是ILSVRC的1000类子集),如图一所示。
另一个统一增加网络大小的缺陷是计算资源需求的暴增。例如,在一个深度视觉网络,如果两个卷积层相连,任何增加过滤器数量的改动都会导致增加二次方倍数的计算量。如果增加的计算力没有被有效使用(比如大部分的权值趋于0),那么大量的计算会被浪费。实际应用中可用的计算力是有限的,即使是以提高模型质量为主要目标,高效分布计算资源,其实也比盲目增加网络体积更加有效。
解决这两个问题的基本方法最终一般是把全连接改成稀疏连接的结构,甚至包括在卷积中也这么做。除了模拟生物系统,根据Arora【2】的突破性研究证明,这样做也可以在理论上获得更强健的系统。
Arora等人的主要结果显示如果数据集的概率分布是一个十分稀疏的大型神经网络所能表达的,那么最合适的网络拓扑结构可以通过分析每一步的最后一层激活函数的统计关联性,并将具有高相关性输出的神经元进行聚类,而将网络一层一层地搭建起来。
虽然严格的数学证明需要很强的条件,但事实上这种情况符合著名的赫布原则——神经元如果激活条件相同,它们会彼此互联——这意味着在实践中,赫布原则在不那么严苛的条件下还是可以使用。【转自百度百科:Hebb学习规则是一个无监督学习规则,这种学习的结果是使网络能够提取训练集的统计特性,从而把输入信息按照它们的相似性程度划分为若干类。这一点与人类观察和认识世界的过程非常吻合,人类观察和认识世界在相当程度上就是在根据事物的统计特征进行分类。Hebb学习规则只根据神经元连接间的激活水平改变权值,因此这种方法又称为相关学习或并联学习。】
从负面而言,当涉及大量非统一的(non-uniform)稀疏的数据结构的计算时,现在的计算设施是很低效的。即使算术运算量降低100倍,查表运算和缓存失准(cache miss)也依然是主要瓶颈以至于稀疏矩阵的处理无法成功。如果使用稳定改进(steadily improving)、高度调制(highly tuned)、拥有大量库函数支持极快速密集矩阵相乘、关注CPU或GPU底层细节的方法,那么这种计算需求与计算资源之间的鸿沟甚至可能被进一步拉大。
另外,非统一(non-uniform?异构????)的稀疏模型需要复杂的工程结构与计算结构。目前大部分面向机器学习的系统都利用卷积的优势在空间域中使用稀疏性。然而,卷积是通过一系列与前层区块的密集连接来实现的,文献【11】发表后,卷积神经网通常在特征维度中使用随机的稀疏的连接表,以打破对称性,提高学习水平,然而,根据文献【9】这种趋势会倒退回全连接模式,以便更好滴使用并行计算。
统一的结构、巨大的过滤器数量和更大的批次(batch)规模将允许使用高效的密集矩阵运算。
这就导致了一个问题,是不是存在一个中间步骤,如同理论上所显示的,能够让整个结构即使在过滤器层面上都能使用额外的稀疏性,但依旧是利用现有硬件进行密集矩阵计算【an architecture that makes use of the extra sparsity, even at filter level, as suggested by the theory, but exploits our current hardware by utilizing computations on dense matrices】。大量关于稀疏矩阵计算的文献,比如文献【3】,都显示将稀疏矩阵聚类到相对密集的子矩阵上能够让稀疏矩阵相乘的性能达到实用水平,把同样的方法应用到自动构建非统一深度学习结构上,在不远的将来看起来并不过分。
Inception的体系结构始于第一作者研究的一个例子——评估复杂拓扑结构的网络算法的假设输出,尝试近似地用一个密集的可获得的组件表示一个文献【2】提出的视觉网络的稀疏结构的假设输出。
然而这项工作在很大程度上是基于假设进行的,仅仅在两次迭代之后,我们就已经能够看到一些对于选定的拓扑结构非常不利的有限的成果【12】。在调节了学习速率、超系数,和采用了更好的训练方法之后,我们成功地建立了Inception的体系结构,使之能够在基于文献【5】和【6】提出的局部化和物体检测的上下文环境中非常好用。有趣的是,大多数最初的结构都被彻底地检测过,它们都至少能够达到局部最优。
然而还是需要被谨慎考虑的是:虽然我们提出的体系结构在计算机视觉方面的应用很成功,但这能否归功于其背后的设计指导原则还不是很确定。
想要确定这一点还需要更加彻底的分析和验证:比如,基于这些规则的自动化工具是否能够找到与之类似但却更好的网络拓扑结构。最有说服力的证据将会是自动化系统能够利用相同的算法在不同的领域创建出具有相似结果,但整体架构有很大不同的网络拓扑。
最后,Inception最初的成功为探索这一领域让人激动的未来产生了巨大的动力。
4 结构细节
Inception的体系结构的主要设计思路是要在一个卷积视觉网络中寻找一个局部最优的稀疏结构,这个结构需要能够被可获得的密集组件(dense component)覆盖和近似表达。
请注意,假定转义的不变性(translation invariance)意味着我们的网络将利用卷积砌块(convolutional building blocks)建立。我们所需要做的只是寻找局部最优化结构并在空间上对其进行重复。
Arora等人在文献【2】中提出,一个逐层搭建的结构,需要分析其每一步的最后一层的统计关联性,并将高度相关的神经单元聚类为簇。
这些簇组成了下一层的单元并与前一层的各个单元相连。
我们假设前面一层的每个单元都对应输入图像的某些区域,而这些单元被分组分配给过滤器。在较低的层次(更靠近输入端),相关的单元聚焦于局部区域。这意味着我们能够得到大量聚焦于同一区域的簇,它们会被下一层的1×1卷积覆盖,如同文献【12】所述。然而,更少的在空间上传播更多的簇(a smaller number of more spatially spread out clusters)(这些簇会被区块更大的卷积所覆盖)是可以被期待的,这样的话,覆盖大型区域的区块数量就会减少。为了避免区块对齐问题(patch alignment issues),现有的Inception结构将过滤器大小限制为1×1,3×3 和 5×5,然而这种设定更多是为了方便而不是必要的。
这也意味着合理的网络结构应该是将层次的输出过滤器bank结合起来,并将其合并为单一向量作为输出以及下一层的输入。
另外,因为池化操作对于现有水平的卷积网络是很重要的,建议最好在每一部增加一条并行池化通路,这样应该也会有一些额外的好处:如图2a所示。
Inception模块是一层一层往上栈式堆叠的,所以它们输出的关联性统计会产生变化:更高层抽象的特征会由更高层次所捕获,而它们的空间聚集度会随之降低,因为随着层次的升高,3×3和5×5的卷积的比例也会随之升高。
一个大问题是,上述模型,至少是朴素形式(naive form)的模型,即使只有很有限个数的5×5卷积,其最上层卷积层的巨量过滤器的开支都会让人望而却步。一旦把池化层加进来,这个问题会变得更加严重:
它们的输出过滤器个数与前面过程的过滤器个数相等。池化层输出与卷积层输出的合并会导致无法避免的每步输出暴增。
即使是当这种结构覆盖了最优的稀疏结构,它可能依然还是很低效,从而导致少数几步的计算量就会爆炸式增长。
这种情况导致我们提出了第二种设想:审慎地把降维和投影使用到所有计算量可能急剧增加的地方。
这是基于嵌入的成功(success of embeddings)来设计的:相对于一个大型的图像区块,即使是低维的嵌入也可能包含大量的信息。
然而,嵌入会把信息以一种致密的,压缩的方式展现出来,而压缩信息是很难被建模的。
我们还是想在大部分位置保持稀疏性(如同文献【2】所要求的),而只在信号需要被聚合的时候压缩它们。
也就是说,1×1卷积被用于在昂贵的3×3和5×5卷积之前降维。
除了用于降维,它们也被用于数据线性修正激活(rectified linear activation),这使之具有双重使命。最后的结果如图2b。
一般而言,一个Inception网络是由一系列上述结构栈式堆叠而成,有时候步长为2的最大池化层会把网络一分为二。
出于技术原因(更高效的训练),只在高层使用Inception结构而把低层保留为传统的卷积模式似乎是有利的。
这并不一定是必要的,只是反映了有些基础设施对于我们的设计而言很低效。
这一结构一个有利的方面是它允许每一步的神经元大量增加,而不会导致计算复杂度的暴增。
降维的普遍存在能够阻挡大量来自上一层的数据涌入下一层的过滤器,在大区块上对其进行卷积之前就对其进行降维。
该设计另一个在实践中很有用的方面是,它与【视觉信息应该被多层次处理,然后被汇集到下面层次汇总,同时抽取多尺度特征】的特性相一致。
计算资源的优化利用允许我们增加每层网络的宽度以及层数,而无需面对增加的计算困难。
另一种使用Inception架构的方法是开发一种质量稍差,但计算起来更便宜的版本。
我们已经发现,用于平衡计算资源的控制因素 可以使得我们的网络比表现相同(译者注:这里可能是指精确度)而不使用Inception结构的网络快2~3倍,只是这需要极为精细的人工调整。
在这篇论文的9.结论中,进一步说明了Inception模块是在解决一个寻找局部最优的稀疏结构的问题。
我们的结果似乎产生了一个坚实的结论——利用现有密集砌块逼近预想中的最佳稀疏结构,是一种可行的提高计算机视觉神经网络能力的方法。这种模型的主要优势是与浅层且较窄的网络相比,只要适度增加计算需求就能极大地提升质量。
还请大家注意,我们的检测技术即使没有使用上下文和边界回归,依然很有竞争力,这一事实提供了进一步的证据证明Inception结构的强大。虽然相同质量的网络可以被同样宽度和深度的更昂贵的网络实现,我们的方法却切实地证明了切换到一个更稀疏的结构上是一个在普遍情况下可行且有用的方法。这意味着一个充满希望的未来——开发文献【2】提出的自动创建一个更稀疏,更有限的结构的方法。
3. Residual Network
假设在一个深度网络中,我们期望一个非线性单元(可以为一层或多层的卷积层)f(x, θ)去逼近一个目标函数为h(x)。如果将目标函数拆分成两部分: 恒等函数(Identity Function) x和残差函数(Residue Function) h(x) − x。根据通用近似定理,一个由神经网络构成的非线性单元有足够的能力来近似逼近原始目标函数或残差函数,但实际中后者更容易学习[He et al., 2016]。因此,原来的优化问题可以转换为:让非线性单元f(x, θ)去近似残差函数h(x)−x,并
用f(x, θ) + x去逼近h(x)。
《Deep Residual Learning For Image Reconnition》论文翻译
摘要
越深的神经网络训练起来越困难。本文展示了一种残差学习框架,能够简化使那些非常深的网络的训练,该框架使得层能根据其输入来学习残差函数而非原始函数(unreferenced functions)。本文提供了全面的依据表明,这些残差网络的优化更简单,而且能由更深的层来获得更高的准确率。本文在ImageNet数据集上使用了一个152层深的网络来评估我们的残差网络,虽然它相当于8倍深的VGG网络,但是在本文的框架中仍然只具有很低的复杂度。这些残差网络的一个组合模型(ensemble)在ImageNet测试集上的错误率仅为 3.57%。这个结果在2015年的ILSVRC分类任务上获得了第一名的成绩。我们在CIFAR-10上对100层和1000层的残差网络也进行了分析。表达的深度在很多视觉识别任务中具有非常核心的重要性。仅仅由于我们相当深的表达,便在COCO目标检测数据集上获得了 28% 的相对提升。 深度残差网络是我们参加ILSVRC & COCO 2015 竞赛上所使用模型的基础,并且我们在ImageNet检测、ImageNet定位、COCO检测以及COCO分割上均获得了第一名的成绩。
网络退化问题
在深度的重要性的驱使下,出现了一个新的问题:训练一个更好的网络是否和堆叠更多的层一样简单呢?解决这一问题的障碍便是困扰人们很久的梯度消失/梯度爆炸,这从一开始便阻碍了模型的收敛。归一初始化(normalized initialization)和中间归一化(intermediate normalization)在很大程度上解决了这一问题,它使得数十层的网络在反向传播的随机梯度下降(SGD)上能够收敛。
当深层网络能够收敛时,一个退化问题又出现了:随着网络深度的增加,准确率达到饱和(不足为奇)然后迅速退化。意外的是,这种退化并不是由过拟合造成的,并且在一个合理的深度模型中增加更多的层却导致了更高的错误率,我们的实验也证明了这点

