
热门标签
热门文章
- 1DIY剪刀石头布机器人(一)_kittenblock识别左右手势
- 2cmd输入python弹出应用商店_删除了商店的环境变量cmd 还会启动
- 3简单的TCP网络程序:英译汉服务器
- 4《视觉SLAM十四讲精品总结》6.1:VO—— 2D-2D对极约束求位姿R、t_slam位姿图中的rr算法
- 5源码驱动,同城代驾更智能
- 6C++学习8内联函数_c++ 在.h文件中声明的inline在cpp文件要加吗?
- 7ffmpeg源码编译_centos手动编译github中的ffmpeg源码
- 8Pyinstaller使用与常见问题_pyinstaller 创建mac二进制
- 9Spring Cloud Alibaba面试题
- 10假设现在你是A公司的产品经理,需要策划一款产品能帮助客户解决需求:描述一下这款产品的定位、需求、目标用户,以及基本的产品形态。_假如你是一位企业老总,现在要开发一款产品。请列出这款产品的具体名称,及整个开发及上市步骤有哪些?此商
当前位置: article > 正文
[开源]CNN-BiLSTM-Attention时间序列预测模型python代码_cnn+attention代码
作者:盐析白兔 | 2024-05-31 22:09:51
赞
踩
cnn+attention代码
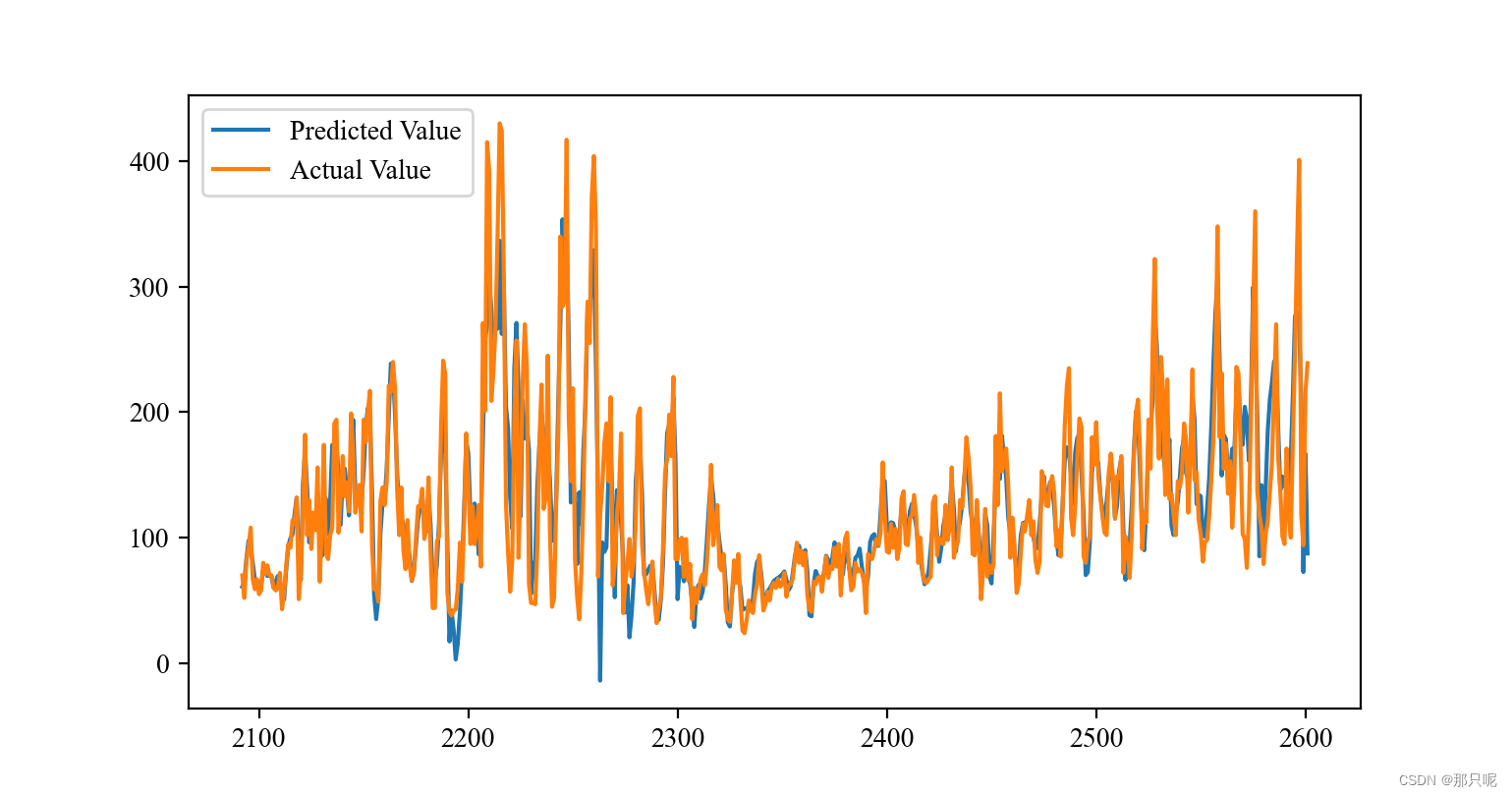
整理了CNN-BiLSTM-Attention时间序列预测模型python代码分享给大家,记得点赞哦!
- #帅帅的笔者
- # coding: utf-8
-
-
- from keras.layers import Input, Dense, LSTM ,Conv1D,Dropout,Bidirectional,Multiply,Concatenate,BatchNormalization
- from keras.models import Model
- from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
- from keras.layers.core import *
- from keras.models import *
- from keras.utils.vis_utils import plot_model
- from keras import optimizers
- import numpy
- import numpy as np
- import pandas as pd
- import math
- import datetime
- import matplotlib.pyplot as plt
- from pandas import read_csv
- from keras.models import Sequential
- from keras.layers import Dense
- from sklearn.preprocessing import MinMaxScaler
- from keras import backend as K
-
-
-
-
-
- def attention_function(inputs, single_attention_vector=False):
- TimeSteps = K.int_shape(inputs)[1]
- input_dim = K.int_shape(inputs)[2]
- a = Permute((2, 1))(inputs)
- a = Dense(TimeSteps, activation='softmax')(a)
- if single_attention_vector:
- a = Lambda(lambda x: K.mean(x, axis=1))(a)
- a = RepeatVector(input_dim)(a)
- a_probs = Permute((2, 1))(a)
- output_attention_mul = Multiply()([inputs, a_probs])
- return output_attention_mul
-
-
- def creat_dataset(dataset, look_back):
- dataX, dataY = [], []
- for i in range(len(dataset) - look_back - 1):
- a = dataset[i: (i + look_back)]
- dataX.append(a)
- dataY.append(dataset[i + look_back])
- return np.array(dataX), np.array(dataY)
-
-
-
- dataframe = pd.read_csv('天气.csv', header=0, parse_dates=[0], index_col=0, usecols=[0, 1])
- dataset = dataframe.values
-
-
-
- scaler = MinMaxScaler(feature_range=(0, 1))
- dataset = scaler.fit_transform(dataset.reshape(-1, 1))
-
-
- train_size = int(len(dataset) * 0.8)
- test_size = len(dataset) - train_size
- train, test = dataset[0: train_size], dataset[train_size: len(dataset)]
-
-
-
- look_back = 5
- trainX, trainY = creat_dataset(train, look_back)
- testX, testY = creat_dataset(test, look_back)
-
-
-
- def attention_model():
- inputs = Input(shape=(look_back, 1))
- x = Conv1D(filters = 128, kernel_size = 1, activation = 'relu')(inputs)
- BiLSTM_out = Bidirectional(LSTM(64, return_sequences=True,activation="relu"))(x)
- Batch_Normalization = BatchNormalization()(BiLSTM_out)
- Drop_out = Dropout(0.1)(Batch_Normalization)
- attention = attention_function(Drop_out)
- Batch_Normalization = BatchNormalization()(attention)
- Drop_out = Dropout(0.1)(Batch_Normalization)
- Flatten_ = Flatten()(Drop_out)
- output=Dropout(0.1)(Flatten_)
- output = Dense(1, activation='sigmoid')(output)
- model = Model(inputs=[inputs], outputs=output)
- return model
-
-
-
- model = attention_model()
- model.compile(loss='mean_squared_error', optimizer='adam')
- model.summary()
-
-
-
- history = model.fit(trainX, trainY, epochs=100, batch_size=64, verbose=0,validation_data=(testX, testY))
-
-
-
- trainPredict = model.predict(trainX)
- testPredict = model.predict(testX)
-
-
-
- trainPredict = scaler.inverse_transform(trainPredict)
- trainY = scaler.inverse_transform(trainY)
- testPredict = scaler.inverse_transform(testPredict)
- testY = scaler.inverse_transform(testY)
-
-
- testScore = math.sqrt(mean_squared_error(testY, testPredict[:, 0]))
- print('RMSE %.3f' %(testScore))
- testScore = mean_absolute_error(testY, testPredict[:, 0])
- print('MAE %.3f' %(testScore))
- testScore = r2_score(testY, testPredict[:, 0])
- print('R2 %.3f' %(testScore))
-
-
-
- trainPredictPlot = np.empty_like(dataset)
- trainPredictPlot[:] = np.nan
- trainPredictPlot = np.reshape(trainPredictPlot, (dataset.shape[0], 1))
- trainPredictPlot[look_back: len(trainPredict) + look_back, :] = trainPredict
-
-
-
-
- testPredictPlot = np.empty_like(dataset)
- testPredictPlot[:] = np.nan
- testPredictPlot = np.reshape(testPredictPlot, (dataset.shape[0], 1))
- testPredictPlot[len(trainPredict) + (look_back * 2) + 1: len(dataset) - 1, :] = testPredict
-
-
-
- plt.plot(history.history['loss'])
- plt.title('model loss')
- plt.ylabel('loss')
- plt.xlabel('epoch')
- plt.show()
-
-
-
-
- M = scaler.inverse_transform(dataset)
- N = scaler.inverse_transform(test)
-
-
-
-
- plt.figure(figsize=(10, 3),dpi=200)
- plt.plot(range(len(train),len(dataset)),N, label="Actual", linewidth=1)
- plt.plot(testPredictPlot, label='Prediction',linewidth=1,linestyle="--")
- plt.title('CNN-BiLSTM-attention Prediction', size=10)
- plt.ylabel('AQI',size=10)
- plt.xlabel('时间',size=10)
- plt.legend()
- plt.show()
-
-
-
-
-
-

更多55+时间序列预测python代码获取链接:时间序列预测算法全集合--深度学习

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/654614
推荐阅读
相关标签

