
- 1箭头函数()=>{}与function的区别_(() => {
- 2Unity入门--Unity的下载安装及基本使用_unity tmp下载和使用
- 3Tweening过度缓动效果_tweening 缓动
- 4Unity3D游戏开发之使用AssetBundle和Xml实现场景的动态加载_asset table 工具 xml
- 5<HarmonyOS第一课>ArkTS开发语言介绍_harmonyos第一课>arkts开发语言介绍
- 6Canvas 关于混合模式 PorterDuff.Mode.MULTIPLY(正片叠底)的使用_canvas正片叠底
- 7display: table-row; 实现等高布局_display: table-row; 高度
- 8Elasticsearch基础篇(三):Elasticsearch7.x的集群部署_elasticsearch集群部署
- 9Android轻量级进程间通信Messenger源码分析
- 10Faster-RCNN网络详解
深度学习笔记(八)——构建网络的常用辅助增强方法:数据增强扩充、断点续训、可视化和部署预测_机器学习数据扩充
赞
踩
文中程序以Tensorflow-2.6.0为例
部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。
截图和程序部分引用自北京大学机器学习公开课
要构建一个完善可用的神经网络,除了设计网络结构以外,还需要添加一些辅助代码来增强网络运行的稳定性,鲁棒性。可以用来增强的方向主要有 个,首先是数据输入前的预处理环节,其次是数据在训练过程中的优化,最后的数据在训练结束后的导出和可视化,同时能够及时保存结果和继续上一次训练在实际工作中是十分有效的。
训练的前奏曲——数据集
在前面的代码中往往是直接加载现有的数据集,然后送入网络进行学习,实际工作研究中,数据往往需要重新花费不少时间去采集、标准化和标注。对于不同的数据集一般可以有不同的处理方式。首先是最常见的图像数据,在进行图像学习之前先要制作图像数据集,一个好的数据集可以帮助我们达到事半功倍的效果。制作图像数据集时,有几个基础要求:
- 有比较明显的特征,图像中背景信息和语义信息有比较明显的区分,语义信息就是我们关注的对象;
- 尺寸合适,图像尺寸能够满足网络输入的基本要求,现在大部分主流手机拍照得到的照片尺寸太大,不合适在验证阶段使用;
- 数据格式能够加载,图像数据格式最好是RGB或者灰度图;
- 数据覆盖全面,数据源尽可能多的覆盖研究对象可能出现或者存在的场景;
- 标注不出错,标注时不能只图快,要保证一定的精确度
当然,研究的数据不一定都是图像,还有可能是时间序列数据,是多组传感器的采集值,是一段文本等等,但是都避不开 数据格式、数据规模、标签准确度这几个关键因素。
下面还是以基础的图像处理来说明数据集处理中常用的几个方法。
数据增强,扩充数据集
当被用来的训练的数据由于成本、时间等原因受到限制的时候可以通过数据的扩充适当的将原始的数据增加出一定比例。但这不意味着可以无限制的增加数据规模,只有当已经采集到的数据达到一定规模之后,数据的扩充作为锦上添花才能起到比较好的作用。
在数据扩充之前要先解决一个问题,就是如何把数据从原始的文件夹中读取到程序中。通常可以使用python自带的os库遍历某个路径下所有符合要求格式的数据,然后以此加载数据,随后通过PIL或Pands对读取的数据进行格式化操作,最后转化为numpy数组,再导入为tensor格式就可以用来训练了。在加载数据和格式化数据时,要注意做好特征数据和标签数据的对应。
下面我们尝试从指定的本文文件中读取数据和对应的标签,首先假设我们有这样的一组数据:
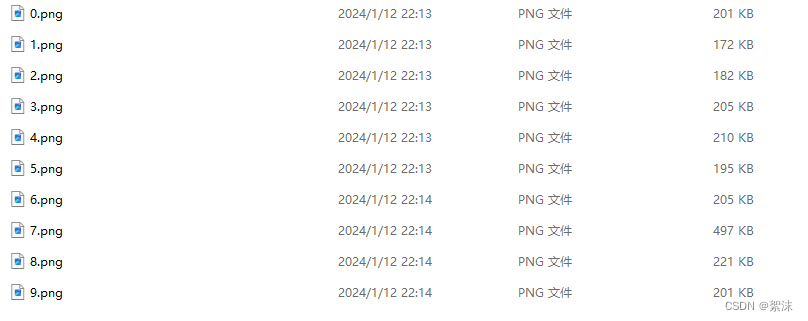
右键,在所在位置打开终端输入:
dir/b>file_name.csv
- 1
这段代码会将当前目录下的所有文件名以此写到一个csv表格中。我们可以使用excel打开这个表格,修改其中数据的分类,或者根据自己的需要进行修改。当然不一定要使用csv,也可以使用txt后缀,这样文件就直接输出到txt文本中。
针对csv我们可以逐行或者逐列读取:
import pandas as pd
# 读取 CSV 文件
df = pd.read_csv('../Data/MNIST/file_name.csv')
# 获取列数据
train_data_file = df['train']
train_data_label = df['train_label']
test_data_file = df['test']
test_data_label = df['test_label']
# 打印列数据
print(train_data_file )
print(train_data_label)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
表格数据:

程序输出:
0 0.png
1 1.png
2 2.png
3 3.png
4 4.png
5 5.png
Name: train, dtype: object
0 0
1 1
2 2
3 3
4 4
5 5
Name: train_label, dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
那么我们直接构建一个函数读取指定的数据内容的函数
import pandas as pd from PIL import Image import numpy as np # 读取 CSV 文件 def readImage(image_path, file_path): csv_file = pd.read_csv(file_path) # 获取列数据 train_data_file = csv_file['train'] train_data_label = csv_file['train_label'] test_data_file = csv_file['test'] test_data_label = csv_file['test_label'] x, y_ , t, yt_= [], [], [], [] for _index in np.arange(0, train_data_file.shape[0], 1): if pd.notna(train_data_file.iloc[_index]): # 判断如果数据非空 img_ = Image.open(image_path + train_data_file[_index]) img_ = np.array(img_.convert('L')) img_ = img_ / 255. # 数据标准归一化 x.append(img_) y_.append(train_data_label[_index]) for _index in np.arange(0, test_data_file.shape[0], 1): if pd.notna(test_data_file.iloc[_index]): img_ = Image.open(image_path + test_data_file[_index]) img_ = np.array(img_.convert('L')) img_ = img_ / 255. t.append(img_) yt_.append(test_data_label[_index]) return (x, y_), (t, yt_) (train_img, train_lab), (test_img, test_lab) = readImage(image_path='../Data/MNIST/', file_path='../Data/MNIST/file_name.csv')

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
把数据读取为numpy之后就可以进一步载入tf中,利用tf函数进行数据的扩充。扩充的方法主要有:随机平移、缩放、0填充、随机旋转。
img_prossess_Gen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale='所有数据乘以这个数(倍乘)',
horizontal_flip='是否随机水平旋转 Boolean',
rotation_rang='随机旋转的角度范围 Int',
width_shift_range='随机宽度偏移量',
height_shift_range='随机高度便宜量',
zoom_range='随机缩放的范围 Float or [lower, upper].'
)
img_prossess_Gen.fit(train_img)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
所以结合前面分类博客中的代码,我们可以得到一个简单的例子:
cifar10 = tf.keras.datasets.cifar10 (x_train, y_train), (x_test, y_test) = cifar10.load_data() datagen = ImageDataGenerator( # 定义数据扩充项 featurewise_center=True, featurewise_std_normalization=True, rotation_range=20, width_shift_range=0.2, height_shift_range=0.2, horizontal_flip=True, validation_split=0.2) datagen.fit(x_train) # 扩充训练数据 model.fit(datagen.flow(x_train, y_train, batch_size=32, # 根据扩充数据并辅助分组后进行训练 subset='training'), validation_data=datagen.flow(x_train, y_train, batch_size=8, subset='validation'), steps_per_epoch=len(x_train) / 32, epochs=epochs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
到此我们实现了加载数据并且扩充数据,利用扩充数据实现网络训练的操作。
训练的曲谱——过程优化
当数据量较大的时候并且网络结构比较复杂的情况下,我们比较希望能够在训练的过程中按照一定阶段保存训练模型。并且在未来某个时候重新加载数据继续训练。当然,我们也可以在一个足够大的通用数据集先进行预训练,让网络学习到数据的通用特征。然后将得到的模型导出,并重新加载细节上符合工作研究要求的数据重新开始训练。
同时在训练的过程中,也希望网络能够记住每个迭代计算的结果,并且计时的把训练过程中最好的模型保存下来。这个操作在网络训练的后期会显得十分重要。
断点续训,模型保存和读取
首先应该指定一个模型的保存路径,如果在路径中已经有需要的历史训练数据,就直接加载历史模型。值得注意,保存的动态模型格式是 ckpt
# 记录模型保存路径
checkpoint_save_path = "./checkpoint/Baseline.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path) # 如果有模型则加载后使用
- 1
- 2
- 3
- 4
- 5
在加载之后还需要能够保存模型,这里使用keras提供的训练过程记录器,通过提供一个训练过程的回调函数来检测训练和保存模型。
# 定义保存和记录数据的回调器
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True, # 保存模型
save_best_only=True) # 只保存最好的模型
# 使用数据扩充,并添加回调控制器,用来记录模型
history = model.fit(image_gen_train.flow(x_train, y_train, batch_size=32),
epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
# 训练过程的历史参数可以通过 history 查看
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
参数查看
在上面的程序中已经实现了模型的保存。但是跟具体的还可以把网络中每个层中每个连接的权重参数偏置项,和卷积计算的结果,卷积核的参数,偏置保存下来。
# 保存网络权重参数
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables: # 逐行的将网络中的所有参数写入到 weights.txt 文本文件中
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
训练过程可视化、tensorboard
如何观察参数的效果,除了在终端打印训练过程中的Loss,准确度以外,可以将这些关键的数据保存下来,这样调整参数后不同的效果就可以通过曲线图像的形式保存出来,便于观察变化趋势,指导设计者调节参数。在绘制曲线之前首先要在训练位置的函数输出 history 参数,后续通过调用这个参数中的数据在加上matplotlib来画出曲线。
# 显示训练集和验证集的acc和loss曲线 acc = history.history['sparse_categorical_accuracy'] val_acc = history.history['val_sparse_categorical_accuracy'] loss = history.history['loss'] val_loss = history.history['val_loss'] plt.subplot(1, 2, 1) plt.plot(acc, label='Training Accuracy') plt.plot(val_acc, label='Validation Accuracy') plt.title('Training and Validation Accuracy') plt.legend() plt.subplot(1, 2, 2) plt.plot(loss, label='Training Loss') plt.plot(val_loss, label='Validation Loss') plt.title('Training and Validation Loss') plt.legend() plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
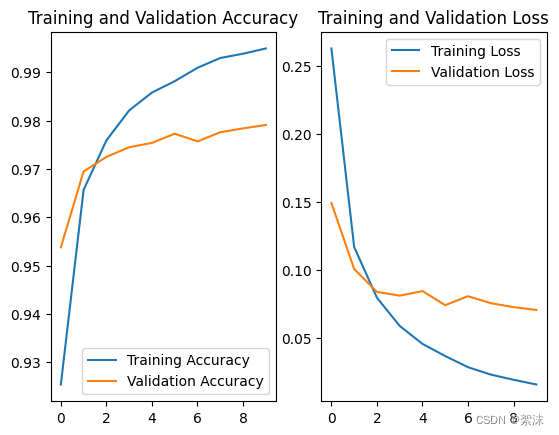
根据图像不难看出随着迭代次数的增加,训练集和测试集的测试准确率不断上升,损失值不断下降。此时可以增加训练的迭代次数,并微调相关参数,查看网络可能出现的不同的效果。
除了上面提及的讲训练结果导出画图的方法,还可以安装tensorboard,一般安装tensorflow2时会配套自动安装。只需要在模型训练结果保存的位置打开终端,启动对应的虚拟环境,然后输入 tensorboard,就可以在给出的网页中查看到实时的训练参数。在训练的函数中需要加入关于tensorboard的回调函数。
# 设置TensorBoard输出的回调函数
tf_callback = tf.keras.callbacks.TensorBoard(log_dir="./logs") # 设置log文件存放地址,这里是相对路径,也可以使用绝对路径
# 使用数据扩充
history = model.fit(image_gen_train.flow(x_train, y_train, batch_size=64),
epochs=8, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback, tf_callback]) # 这里的回调包含保存模型和输出tensorboard训练参数
- 1
- 2
- 3
- 4
- 5
- 6
运行后再终端启动虚拟环境,输入指令加上你设置的log文件存放地址
tensorboard --logdir YOU_LOG_PATH
- 1
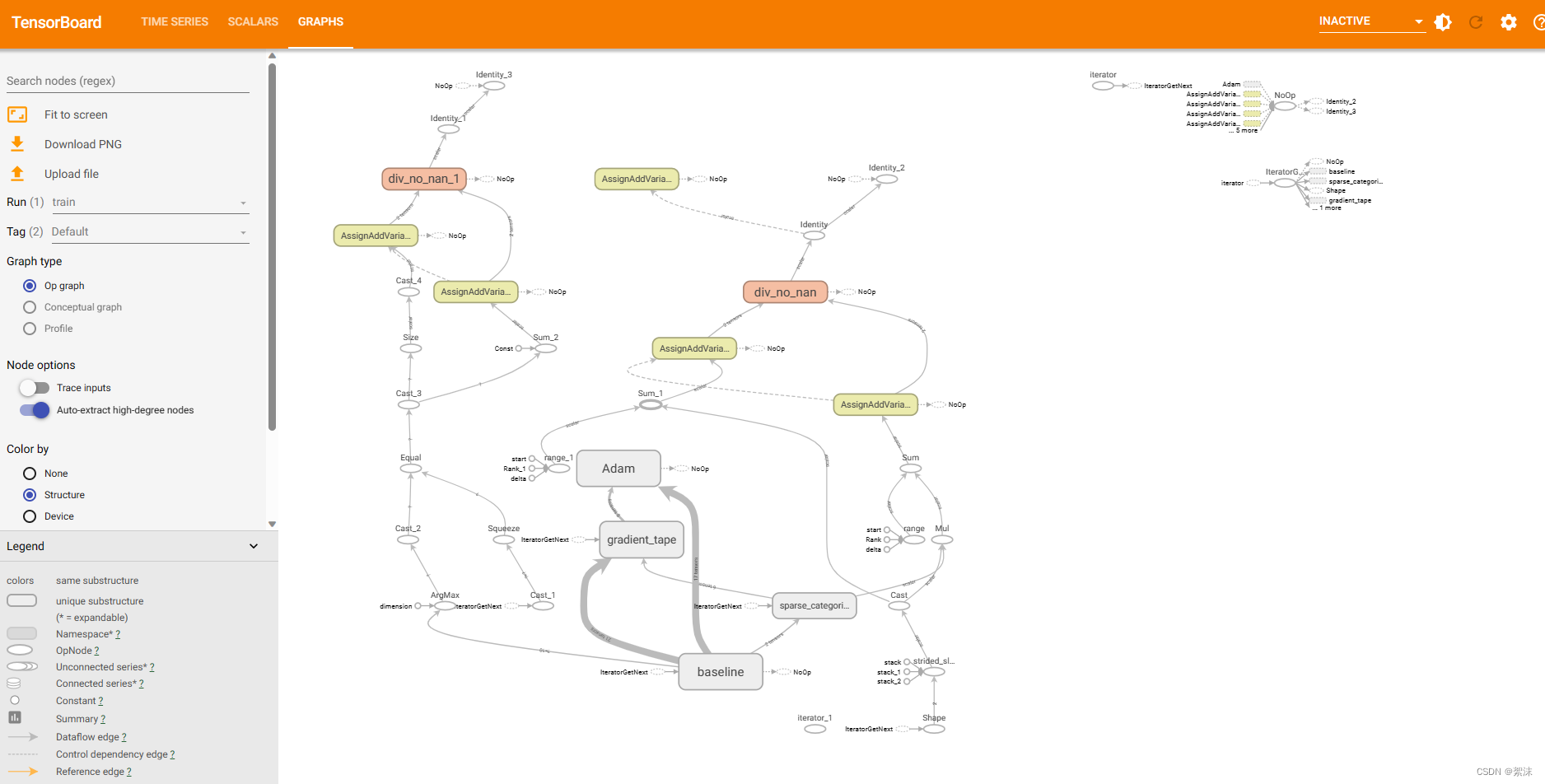
在tensorboard中可以观察模型的结构和训练中的参数数据。
训练的终章——结果可视化与数据评价
训练得到一个新的模型了,那如何使用它。这就需要再继续添加新的代码,用来单独加载模型并实现模型的前向推理,最后推理结果给出。
根据上面的例子,我们以手写数字的代码为例,可以很容易得到如下代码:
import cv2 # opencv-python==4.5.1.48 # 1. 加载图像 model_path = './checkpoint/mnist/mnist.ckpt' image_path = '../Data/MNIST/' new_model = mnisModel() new_model.load_weights(model_path) preNum = int(input("place input how many jpg file while be test:")) for i in range(preNum): imgNum = int(input("place input png name:")) img_path = image_path+str(imgNum)+'.png' print("read image:{}".format(img_path)) img_ = cv2.imread(img_path) resized_img = cv2.resize(img_, (28, 28), interpolation=cv2.INTER_AREA) gray_img = cv2.cvtColor(resized_img, cv2.COLOR_BGR2GRAY) # 4. 准备图像数据,进行归一化和添加批次维度 cv2.imshow("input num", img_) img_for_prediction = gray_img.astype(np.float32) / 255.0 # 归一化到 [0, 1] img_for_prediction = np.expand_dims(img_for_prediction, axis=0) # 添加批次维度 result = model.predict(img_for_prediction) predNum = tf.argmax(result, axis=1) print("predice num is: ") tf.print(predNum)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
通过上面的程序最终我们实现了加载已经有的模型,然后继续开始前向推理,并输出推理的结果。

