
- 1SpringBoot基于RabbitMQ实现消息可靠性_springboot整合rabbitmq保证消息可靠性
- 2AI绘画的6种方式将你的显卡性能拉满体验SDXL 这一种你绝对没听过_如何让显卡在ai生图中满载运转
- 3Verilog学习之时序控制、语句块(1)
- 4A* 搜索算法
- 5一个优秀的可定制化Flutter相册组件,看这一篇就够了
- 6python使用pyecharts构建柱状图_python柱状图自定义y轴
- 7安卓逆向 和 手游辅助 学习 路线
- 8SWJTU 数电实验报告——可控分频器设计
- 9交叉驰豫的影响因素_自体单束前交叉韧带移植重建不同股骨隧道位置对髌股关节的影响...
- 10win10下使用iverilog仿真+gtkwave/WaveDrom查看波形_gtkwave怎么看波形
K-SVD算法
赞
踩
K-SVD算法
- 算法简介
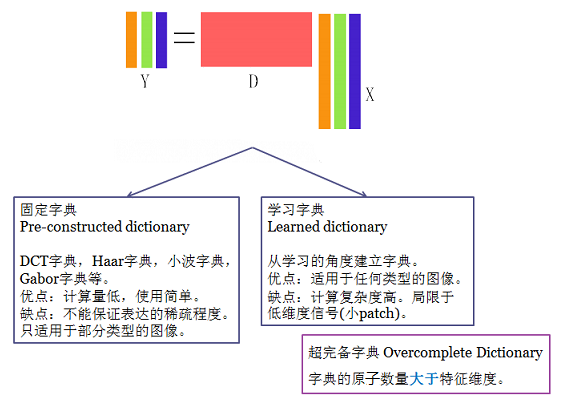
- K-SVD可以看做K-means的一种泛化形式(由K-means扩展而来),K-means算法中每个信号量只能用一个原子来近似表示,而K-SVD中每个信号是用多个原子的线性组合来表示的。
- K-SVD通过构建字典来对数据进行稀疏表示,经常用于图像压缩、编码、分类等应用。
主要问题
其中
(其中第一个函数的意思是指求矩阵
算法求解
给定训练数据后一次找到全局最优解的字典为NP难的问题, 只能逐步逼近最优解. 构造D算法分为两步: 稀疏表示和字典更新
稀疏表示
首先设定一个初始化的字典, 用该字典对给定数据进行稀疏表示(即用尽量少的系数尽可能近似的表示数据)得到系数矩阵
字典更新
初始字典往往不是最优的, 满足稀疏性的系数矩阵表示的数据和原数据会有较大误差, 我们需要在满足稀疏度的条件下逐行逐列更新优化, 减少整体误差, 逼近可用字典. 剥离字典中第
误差值为
上式可以看做把第
求解流程
K-SVD是一个迭代的过程. 首先, 假设字典
字典D的更新是逐列进行的. 首先假设系数矩阵X和字典D都是固定的, 将要更新的是字典的第k列
得到当前误差矩阵
对于上面的问题, 如果直接用
. 形成
具体如下:

算法流程

参考:
1. http://blog.csdn.net/chlele0105/article/details/16886795
2. K-SVD: An algorithm fordesigning overcomplete dictionaries for sparse representation (IEEE Trans. OnSignal Processing 2006)
3. http://home.ustc.edu.cn/~zywvvd/files/K-SVD.pdf
4. http://blog.csdn.net/cc198877/article/details/9167989

