
- 1入华十五载终“折戟”,“亚马逊中国”输给了谁?_据报道,近些年亚马逊在中国的业务开展并不如意
- 2RabbitMQ在Ubuntu 16.04下的安装与配置_ubunto17.10 安装rabbitmq
- 3NLP-RNN_rnn与nlp
- 4AI作画算法详解:原理、应用与未来发展_ai绘画 算法
- 52020A证(安全员)模拟考试题及A证(安全员)实操考试视频_5、起重机在靠近架空电缆线作业时,臂架、吊具、辅具、钢丝绳、缆风绳及载荷等
- 6汇总利用YOLO8训练遇到的报错和解决方案(包含训练过程中验证阶段报错、精度报错、损失为Nan、不打印GFLOPs)_yolov8训练的时候 amp checks failed
- 7git 回滚指令_git rollback 命令行
- 8C++调用Yolov3模型实现目标检测_yolov3-tiny.pt
- 9机器学习实验报告——EM算法_em算法最早提出
- 10云安全之OpenStack 高可用和灾备方案 [OpenStack HA and DR]
大数据系统开发实践项目——安装完全分布式Hadoop集群并利用MapReduce实现倒排索引(北理工大三小学期)(1)_大数据头歌实验 使用 mapreduce 实现倒排索引
赞
踩
HDFS提供了可扩展的分布式存储,使搜索引擎能够有效存储和管理大规模的爬取数据。其块存储机制和数据冗余机制确保了数据的可靠性和容错性,为后续的计算和检索提供了基础;
(2)MapReduce
MapReduce模型将大规模的计算任务分解成可并行处理的子任务,为搜索引擎中的索引构建、查询处理和排名等计算任务提供了高效的分布式计算框架,提高了整个搜索引擎的计算能力;
(3)HBase
HBase作为分布式、可伸缩的列式数据库,存储中间数据(如倒排索引),提供了高效的读写能力,支持搜索引擎对数据的快速检索,为搜索引擎提供了高效的数据访问能力;
(4)Apache Nutch
Apache Nutch作为开源的分布式爬虫框架,实现了高效的分布式爬取。对于搜索引擎而言,Nutch能够支持大规模、可扩展的网页抓取,确保搜索引擎及时获取互联网上的最新数据;
(5)Pig
Pig作为数据流处理工具,在搜索引擎的开发中,可用于对爬取的大规模数据进行ETL(提取、转换、加载)操作(即预处理)、清洗和格式化数据,以便后续的索引构建;
(6)Yarn
Yarn用于Hadoop集群的资源管理,够有效分配和管理集群资源,确保各个组件(如MapReduce任务)能够充分利用集群的计算能力,提高搜索引擎的运行效率。
(7)Flume
Flume专注于大规模数据的日志收集和聚合,可以用于收集分布式爬虫、服务器日志等数据,将其传输到Hadoop生态系统中进行进一步的处理和分析,可用于故障分析及修复、状态检测等。
2.优势与不足
(1)优势
搜索引擎需要处理海量的爬取数据、建立庞大的索引以及执行复杂的查询任务,Hadoop提供了高度可扩展的架构,能够有效应对搜索引擎的大规模数据处理需求理;
HDFS提供的可靠的分布式存储与MapReduce模型实现的分布式计算相互配合使得搜索引擎可以将数据存储在分布式文件系统中,同时通过并行计算加速索引构建和查询处理等任务,充分发挥集群的性能;
HDFS采用数据冗余机制,提供了搜索引擎系统在面对硬件故障或其他异常情况时的容错性和可靠性;
Hadoop生态系统中的Pig、Nutch等工具,使得开发人员可以更灵活地执行复杂的数据处理任务(如ETL)与更大规模可拓展的网页抓取需求;
Hadoop拥有庞大的开源社区和丰富的生态系统,开发者可以利用已有的工具、库和解决方案,避免从头开始构建所有组件。社区的存在也意味着搜索引擎可以及时获取新的功能和修复bug。
(2)不足
Hadoop主要面向大规模批处理任务,而不是实时处理。在搜索引擎中,有些应用场景对实时性要求较高,Hadoop在这方面可能存在一些延迟,需要额外的技术手段来解决实时性问题;
Hadoop生态系统对于处理非结构化数据的能力相对较弱。对于搜索引擎来说,这可能会限制其处理某些类型的数据的灵活性;
搭建和维护一个Hadoop集群需要专业知识和经验。配置、调优以及处理集群中的故障等任务都需要熟悉Hadoop生态系统的工程师,且Hadoop生态系统覆盖的技术较多,对新手而言需要不短的时间来掌握,对开发团队而言可能存在挑战;
搭建和维护一个大规模的Hadoop集群需要相应的、不小的硬件和资源投入,包括大量的存储、计算节点以及网络带宽等。
三、功能实现
1.数据的爬取、清洗与储存
数据爬取的实现需要使用分布式爬虫工具Nutch,配置并运行Nutch集群。采用深度优先策略,合理配置爬虫参数,确保尽可能多的地获取一个界面的所有链接以及对目标网站的全面爬取。此外,还可以利用URL过滤机制,排除无关链接。配置定时调度任务,定期运行爬虫以更新索引;
数据的清洗可依赖于Nutch自带的插件如HTML解析器,针对不同类型的网站,去除HTML标签、广告、过滤无关内容等。此外还可以利用正则表达式,针对特定噪声字符或格式进行过滤和清理;
在数据的爬取过程中,使用HDFS作为主要的分布式存储系统。利用HDFS的可扩展性和容错性,每个爬取的网页内容被按照网页URL或其他标识进行划分,并分块存储在HDFS上。此外,还可以通过配置HDFS的副本数,数据得到冗余存储,从而进一步提高了数据的可靠性保障了爬取的内容能够被高效地管理、存储和检索;
对于搜索引擎系统的索引构建过程,倒排索引等中间数据被存储在HBase中。考虑到HBase的列式存储特性,在HBase中设计适合倒排索引的表结构,使用列族存储文档ID和位置信息,并支持快速的查询操作。通过设计合理的分区策略,确保分布式存储的负载均衡,使得系统在检索时能够以高效的方式获取倒排索引的信息。
2.索引构建
索引构建基于存储在HDFS中爬取的网页内容的分布式存储。在索引构建的初始阶段,为应对有效处理大规模的文档集合使用MapReduce任务进行分词,建立词项与文档ID的映射关系。具体来说,首先以键值对形式读取文档,其中键为文档ID,值为文档内容,再利用分词工具(如jieba中文分词),将文档内容分割成词项,并将每个词项与文档ID组成新的键值对,最后生成并输出新的键值对,其中键为词项,值为文档ID;
接着,在倒排索引的构建过程中,再次运用MapReduce任务,应用TF-IDF算法,将词项映射到包含它的文档,并记录词项在文档中的位置信息,以计算每个词项的在文档中的重要性,确保了对文档的全面索引,为后续的搜索排序提供基础。具体来说,Map阶段首先以键值对形式读取之前生成的分词结果,其中键为词项,值为文档ID,然后将每个词项与文档ID组成新的键值对,并将文档内容作为值,最后生成新的键值对,其中键为词项,值为文档ID和文档内容。Reduce阶段首先以键值对形式接收来自Map部分的输出,其中键为词项,值为文档ID和文档内容的列表,然后针对相同的词项,将它们对应的文档ID和文档内容列表合并,形成倒排索引的条目,最后生成输出最终的键值对,其中键为词项,值为包含该词项的文档ID和位置信息。倒排索引的输出结果被存储在HBase中;
3.查询处理
查询处理的实现方案主要涉及MapReduce任务,通过对用户查询进行解析和倒排索引的检索,以生成初步的搜索结果;
在查询解析阶段,Map部分首先对用户查询进行解析表。具体来说,首先接收用户查询作为输入,然后利用分词器或其他文本处理工具,将用户查询拆分成关键词列表。最后生成输出键值对,其中键为查询的唯一标识符,值为关键词列表。在Reduce部分,系统利用索引构建中生成的倒排索引进行检索,对每个关键词获取包含该关键词的文档列表;
最终,在整个查询处理过程中,MapReduce任务将各个关键词的文档列表合并,得到包含所有关键词的文档。这些文档将作为初步的搜索结果,为后续的排序提供基础。
4.查询结果排序
查询结果排序的具体实现采用BM25算法。在Map部分的实现中,对于每个文档,首先提取查询中的关键词列表。然后,通过BM25算法计算每个关键词在文档中的得分,并将这些得分累加得到整个文档的BM25分数。最后,将文档ID作为键,BM25分数和文档信息(如文档内容、URL等)组成的结构体作为值,生成键值对输出。
在Reduce部分,接收到来自Map部分的一系列键值对,Reduce任务首先对这些键值对进行合并,即将具有相同键(BM25分数)的值进行合并。然后,对合并后的结果按照BM25分数进行排序,得到搜索显示的最终排序名次,并通过用户交互界面展示给查询用户。
四、工作计划与阶段划分
1.准备阶段
在需求分析和系统设计阶段,详细分析搜索引擎的功能需求,制定系统设计方案。同时,开始爬虫模块的实现与测试,确保能够高效地获取互联网上的数据,并进行初步的数据清洗。
2.分布式存储的构建阶段
在此阶段,搭建Hadoop集群是首要任务。配置HDFS、Zookeeper与HBase,确保分布式存储系统的顺利运行。进行性能测试,验证存储系统的可靠性和扩展性。
3.索引模块设计阶段
设计和实现索引构建的MapReduce任务,确保能够高效地进行分词、倒排索引的构建。进行性能和准确性的测试,不断优化MapReduce任务以适应大规模文档的处理。
4.查询模块设计阶段
设计和实现查询处理的MapReduce任务,集成查询处理和索引构建。进行性能测试,确保系统能够在查询时迅速定位相关文档。优化任务以应对不同查询场景。
5.排序模块设计以及优化阶段
在排序模块设计阶段,采用BM25算法设计排序的MapReduce任务。进行性能优化,确保搜索结果能够按照相关性高低进行有效排名。进行系统整体测试,验证整个搜索引擎系统的性能。
6.界面开发
开发用户友好的搜索引擎界面,确保用户能够方便地使用搜索功能。与后端系统对接,进行综合测试和用户体验优化。不断根据用户反馈进行调整,保证搜索引擎的易用性和用户满意度。
五、组织结构及分工
1.项目经理(1人)
项目经理负责整体项目规划和协调,确保项目按时交付。担当决策关键技术选型的责任,协调各团队成员的工作,并与相关利益方保持沟通。
2.系统架构师(1人)
系统架构师负责设计整体系统架构,确保系统的可扩展性和高性能。制定核心技术实现方案,为开发团队提供技术支持和指导。
3.后端开发工程师(2人)
后端开发团队负责具体的技术实现,包括爬虫模块、索引构建、查询处理、结果排序等后端任务。通过协同工作,确保后端系统的高效运行和数据处理。
4.前端开发工程师(2人)
前端开发团队负责设计和开发用户界面,与后端对接以实现完整系统。通过用户友好的界面提供良好的搜索体验,并确保前后端的协同工作流畅。
5.测试工程师(2人)
测试团队负责进行系统测试和性能测试,确保系统的稳定性和可靠性。通过全面的测试,提供反馈和建议,帮助优化系统的性能和功能。
六、质量测试和非功能性保证
1.质量保证
质量保证主要通过质量测试来实现。
(1)单元测试
在搜索引擎开发过程中,每个模块,如爬虫、索引构建、查询处理、排序等,将被分解成小的单元进行测试。例如,对于爬虫模块,可以编写单元测试来验证它是否能够正确获取网页内容并存储到HDFS中。对于查询处理模块,可以编写单元测试来验证它是否能够正确解析用户查询并检索倒排索引。
(2)集成测试
通过集成测试,确保各个模块能够协同工作。例如,可以测试整个流程,从爬取网页到构建索引再到用户查询,确保整个搜索引擎系统在集成时能够正常运行。
(3)系统测试
系统测试将验证整个搜索引擎系统的功能、性能、安全性等方面。通过模拟用户实际使用情景,测试系统的响应时间、吞吐量、并发性等指标,以确保系统能够在各种条件下稳定运行。
2.非功能性保证
非功能性保证主要通过非功能性测试来实现。
(1)性能测试
通过性能测试,评估搜索引擎在处理大规模数据和高并发请求时的性能。例如,在构建索引和查询处理阶段,可以测量其响应时间和吞吐量,确保系统在用户需求增加时依然保持高效。
(2)安全性测试
搜索引擎系统可能涉及到用户敏感信息和大量数据,因此安全性测试至关重要。通过模拟网络攻击、数据泄露等场景,验证系统对潜在威胁的抵御能力。
(3)用户体验测试
用户体验测试通过调查和分析用户行为,评估搜索结果的准确性、搜索速度以及用户界面的友好性。通过用户体验测试,确保用户能够获得令人满意的搜索体验。
通过以上质量测试和非功能性保证,搜索引擎系统可以提供高质量的服务,确保其功能稳定、性能卓越、安全可靠、用户体验优秀。这有助于满足用户期望,同时保障系统在面对未来挑战时能够持续高效运行。
③文档倒排索引的实验报告
(下面进入正片)
一、实验要求
运用MapReduce算法计算、构建一个倒排索引,并将倒排索引存储在HBase中。将下载后的数据按照文件的大小或句子数量(例如10000个句子)构成一个文件,形成一个文件集合。
二、实验环境
虚拟机版本:VMware Workstation 17 Pro
Hadoop版本:Hadoop-3.1.3
Zookeeper版本:Zookeeper-3.5.7
HBase版本:hbase-2.4.11
Java版本:oracl jdk-8u212-linux-x64
Linux版本:CentOS-7.5-x86_64-DVD-1804
三、数据准备
观察到实验提供的数据集sentences.txt解压后包含约940万条语句,所占内存约为1.43GB,内存较大,直接运行倒排索引可能会出现问题,故先进行分割处理。
采用Python代码对txt文件进行分割,每1万条语句组成一个新的文件,并按照顺序依次命名为file1.txt、file2.txt、……、file970.txt。执行分割的代码如下:
import os # 指定输入文件和输出目录 input_file_path = r'D:\hadoop_example\sentences.txt' # 你的输入txt文件路径 output_directory = r'D:\hadoop_example\files' # 指定的输出目录路径 # 打开原始txt文件 with open(input_file_path, 'r', encoding='utf-8') as input_file: lines = input_file.readlines() # 计算总行数和文件数 total_lines = len(lines) num_files = (total_lines + 9999) // 10000 # 分割文件 for i in range(num_files): start = i * 10000 end = min((i + 1) * 10000, total_lines) output_filename = os.path.join(output_directory, f'file{i + 1}.txt') # 写入分割后的内容到新文件 with open(output_filename, 'w', encoding='utf-8') as output_file: output_file.writelines(lines[start:end])

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
分割后各文件的情况如下图所示:

四、环境的安装与配置
以下内容请搭配尚硅谷Hadoop教学视频使用,讲得非常细致全面,~~小学期救我狗命,~~搭建完全分布式Hadoop集群请务必一步步跟着操作!!!
尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放
1.虚拟机的安装与配置
为实现代码的运行在分布式环境下进行,本实践项目利用三台虚拟机模拟三台主机节点:hadoop102、hadoop103、hadoop104,并进行以下操作:
(1)关闭对应的防火墙;
(2)创建用户名与密码;
(3)修改每台虚拟机对应的IP与主机名;
(4)搭建虚拟机网络环境并修改windows的主机映射文件(hosts文件);
2.JDK与Hadoop的安装
以主机节点hadoop102为例,我们需要在其上配置JDK与Hadoop,具体步骤如下:
(1)卸载虚拟机自带的JDK;
(2)利用Xshell将hadoop-3.1.3与jdk-8u212-linux-x64的安装包传至hadoop102的指定文件夹下(/opt/software),并解压安装到指定文件夹(/opt/module);
(3)配置JDK与Hadoop的环境变量,即创建/etc/profile.d/my_env.sh文件;
此时我们只完成了hadoop102上JDK与Hadoop的配置,为实现完全分布式环境下运行,我们也需要对hadoop103、hadoo104进行配置。下面是详细步骤:
(1)在hadoop102上利用scp安全拷贝将hadoop102上的JDK拷贝到hadoop103与hadoop104上:
scp -r /opt/module/jdk1.8.0_212 用户名@hadoop103:/opt/module
scp -r /opt/module/jdk1.8.0_212 用户名@hadoop104:/opt/module
- 1
- 2
(2)在hadoop102上利用scp安全拷贝将hadoop102上的Hadoop拷贝到hadoop103与hadoop104上:
scp -r /opt/module/hadoop-3.1.3 用户名@hadoop103:/opt/module
scp -r /opt/module/hadoop-3.1.3 用户名@hadoop104:/opt/module
- 1
- 2
以上我们便完成了对三台主机JDK与Hadoop的配置。此外,为方便后续文件的配发,我们还实现了xsync集群分发脚本(用于实现循环复制文件到所有节点的相同目录下)与ssh无密登陆(用于实现连接两个节点时不需要输入密码,详见尚硅谷视频P28、P29)。
3.Hadoop集群配置
(1)集群部署规划
考虑到管理类节点对主机内存的占用很大,故将NameNode、SecondaryNameNode与ResourceManager配置在不同的服务器上,下表是三台主机节点的集群规划部署:
| 主机节点 | hadoop102 | Hadoop103 | Hadoop104 |
| 实现功能 | NameNode DataNode NodeManager | DataNode ResourceManager NodeManager | SecondaryNameNode DataNode NodeManager |
(2)修改核心配置文件
在/etc/hadoop路径下利用vim指令分别进入core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个文件进行修改:
vim core-site.xml
vim hdfs-site.xml
vim yarn-site.xml
vim mapred-site.xml
- 1
- 2
- 3
- 4
需要配置的内容较多,故不一一列出。具体内容详见尚硅谷视频P30
(3)在hadoop102上向集群分发配置好的Hadoop文件
利用上述已配置好的xsync脚本进行分发:
xsync hadoop/
- 1
此时再去hadoop103与hadoop104上查看可发现Hadoop配置文件已完成分发。
4.Hadoop集群启动前准备
(1)配置workers,即配置节点与之对应的主机名称,并利用xsync脚本同步所有节点配置文件;
(2)首次启动集群前要在hadoop102上格式化NameNode:
hdfs namenode -format
- 1
5.Zookeeper的安装与集群配置
我们需要在hadoop102、hadoop103、hadoop104三台服务器上均部署Zookeeper。以主机节点hadoop102为例,具体步骤如下:
(1)利用Xshell将apache-zookeeper-3.5.7传输安装到Linux系统下并解压到指定文件夹(/opt/module),随后修改名称为zookeeper-3.5.7;
(2)修改opt/module/zookeeper-3.5.7/conf路径下的zoo_sample.cfg为zoo.cfg,并将其中的dataDir路径修改为在opt/module/zookeeper-3.5.7路径下新创建的zkData文件夹;3
mkdir zkData
vim zoo.cfg
dataDir=/opt/module/zookeeper-3.5.7/zkData
- 1
- 2
- 3
(3)在zkData文件夹下创建myid文件,在其中添加“2”,用于表示该台服务器的编号;
vim myid //进入后增加2
- 1
(4)利用vim打开zoo.cfg文件,增加三台服务器地址、follower与leader交换信息的端口以及执行选举时服务器互相通信的端口的配置信息;
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
- 1
- 2
- 3
此时我们只完成了hadoop102上Zookeeper的配置,为实现完全分布式环境下运行,我们利用xsync分发脚本将配置好的zookeeper-3.5.7拷贝到hadoop103与hadoop104上,并将其中的myid分别修改为3和4。分别启动三台服务器上的Zookeeper,我们发现hadoop103为leader,而hadoop102与hadoop104为follower。
6.HBase的安装与集群配置
(1)利用Xshell将hbase-2.4.11传输安装到Linux系统下并解压到指定文件夹(/opt/module),随后修改名称为hbase;
(2)修改/etc/profile.d/my_env.sh文件,增加HBase的环境变量,并使之生效:
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase
export PATH=$PATH:$HBASE_HOME/bin
source /etc/profile.d/my_env.sh
- 1
- 2
- 3
- 4
(3)修改/hbase/conf下的hbase-env.sh、hbase-site.xml、regionservers文件,确保HBase集群可以正常启动.此处修改内容较多,故不一一列出。
(4)修改HBase的slf4j-reload4j-1.7.33.jar包名称为slf4j-reload4j-1.7.33.jar.bak,避免出现HBase的jar包与Hadoop的jar包出现不兼容的问题:
mv /opt/module/hbase/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar /opt/module/hbase/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar.bak
- 1
此时我们只完成了hadoop102上hbase的配置,为实现完全分布式环境下运行,我们利用xsync分发脚本将配置好的hbase拷贝到hadoop103与hadoop104上。启动三台服务器上的HBase,我们发现hadoop102的JPS中有HMaster与HReigonServer,而hadoop102与hadoop103的JPS中只有HReigonServer。
7.Hadoop、Zookeeper、HBase集群启动
(1)启动Zookeeper并查看状态
[用户名@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start
[用户名@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh status
- 1
- 2
下图为三台节点Zookeeper的启动状态:

(2)启动Hadoop并在Web端查看HDFS的NameNode与YARN的ResourceManager
[用户名@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[用户名@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
http://hadoop102:9870
http://hadoop103:8088
- 1
- 2
- 3
- 4
下图为Web端HDFS的NameNode情况:

下图为Web端YARN的ResourceManager情况:

(3)启动HBase并在Web端访问HBase管理界面
1.[用户名@hadoop102 hbase]$ bin/stop-hbase.sh
2.http://hadoop102:16010
- 1
- 2
下图为Web端访问HBase管理界面:
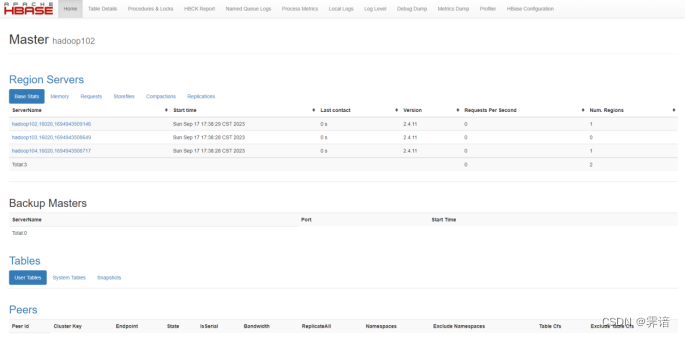
五、算法及实现
1.倒排索引Mapper阶段实现代码及实现说明
invertedindexmapper.java代码:
package com.name.mapreduce.invertedindex; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import java.io.IOException; import java.util.Arrays; import java.util.HashMap; import java.util.Map; public class invertedindexmapper extends Mapper<LongWritable, Text, Text, Text> { // 定义用于Map函数的输入键值对的数据类型:LongWritable用于表示行号,Text用于表示文本行 private Text keyInfo = new Text(); // Map输出的键,表示单词 private Text valueInfo = new Text(); // Map输出的值,表示句子编号和出现次数的组合 private Map<String, Map<String, Integer>> wordCounts = new HashMap<>(); // 用于存储单词和其在句子中出现的次数 @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 将输入的文本行拆分为单词和句子编号 String[] orderedsentences = value.toString().split(" "); // 获取文件名 FileSplit filesplit = (FileSplit) context.getInputSplit(); String filename = filesplit.getPath().getName(); String[] sentences = Arrays.copyOfRange(orderedsentences, 1, orderedsentences.length); // 获取句子中的单词数组 // 遍历句子中的单词 for (String word : sentences) { if (!wordCounts.containsKey(word)) { wordCounts.put(word, new HashMap<>()); } // 获取该单词在句子中的出现次数,如果不存在则默认为0,然后加1 Map<String, Integer> sentenceCounts = wordCounts.get(word); sentenceCounts.put(filename, sentenceCounts.getOrDefault(filename, 0) + 1); } } @Override protected void cleanup(Context context) throws IOException, InterruptedException { // 在Map任务结束时,将单词和其出现次数写入上下文以供Reducer使用 for (Map.Entry<String, Map<String, Integer>> entry : wordCounts.entrySet()) { String word = entry.getKey(); Map<String, Integer> sentenceCounts = entry.getValue(); // 遍历单词在不同句子中的出现次数,并将它们写入上下文 for (Map.Entry<String, Integer> sentenceEntry : sentenceCounts.entrySet()) { keyInfo.set(word); // 设置键为单词 valueInfo.set(sentenceEntry.getKey() + ":" + sentenceEntry.getValue()); // 设置值为句子编号:出现次数 // 将键值对写入上下文 context.write(keyInfo, valueInfo); } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
Mapper阶段类与数据类型定义
(1)invertedindexmapper类继承自Mapper类,用于处理Map阶段的任务。
(2)读入键值对的数据类型为<LongWritable, Text>,其中LongWritable用于读入key,无实际意义,Text用于读入待处理的文本句子数据。
(3)输出键值对的数据类型定义为<Text, Text>,其中两个Text表示单个单词作为键,句子的编号与出现次数的组合作为值。
Mapper阶段核心逻辑
(1)map函数
map函数为Mapper阶段核心函数,用于将输入的文本句子拆分为单词与句子编号和出现次数组合的键值对。文本首先被读入Text类型的value中,每一行文本句子被split函数拆分为包含句子编号与单词数组的字符串数组ordersentences。在该数组基础上提取句子编号和纯单词数组,创建sentences,用于标识纯单词文本。此外,利用context及getInputSplit、getPath、getName方法获取该句子的文件名。此后遍历sentences中每个单词,利用提前定义好的嵌套Map类型的wordCounts获取该单词在当前句子中的出现次数,并在记录中更新,如果不存在则默认为0并加1。wordCounts的结构可表示为Map<String, Map<String, Integer>>,外部Map的键表示单个单词,每个单词都映射到一个内部Map,内部Map的键代表句子编号,并对应映射到该单词的出现次数。
(2)cleanup函数
cleanup函数由两层循环组成,在Mapper任务结束后被调用,用于将单词和其在不同句子中出现的次数写入上下文,以备Reducer阶段使用。外层循环遍历存储在wordCounts中的单词及出现次数;内层循环遍历每个单词在不同句子中的出现次数,并为每个单词设置键,将句子编号和出现次数组合为值,最后将键值对写入上下文,以输出给Reducer阶段。
2.倒排索引Reducer阶段实现代码及实现说明
invertedindexreducer.java代码
package com.name.mapreduce.invertedindex; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableReducer; import org.apache.hadoop.io.Text; import java.io.IOException; public class invertedindexreducer extends TableReducer<Text, Text, ImmutableBytesWritable> { private static Text result = new Text(); @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { // 遍历集合,拼接集合内容,生成文档列表 String filelist = new String(); for (Text value : values){ filelist += value.toString() + "; "; } // 写入上下文中 result.set(filelist); Put put = new Put(key.toString().getBytes()); put.addColumn("info".getBytes(), "index".getBytes(), result.toString().getBytes()); context.write(null, put); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
Reducer阶段类与数据类型定义
(1)invertedindexreducer类继承自TableReducer类,用于处理Reduce阶段的任务。
(2)读入键值对的数据类型为<Text, Text>,其中第一个Text用于读入key,表示单词,第二个Text表示对应的句子以及其在该句子的出现次数。
(3)输出键值对的数据类型定义为,表明输出是一个不可变的字节数组,用于表示存储到HBase表里的主键。
Reducer阶段核心逻辑
reduce函数
reduce函数是Reducer阶段的核心函数,用于聚合来自Mapper阶段的键值对并生成倒排索引。在这个函数中,我们遍历代表句子以及其在该句子的出现次数的值,将拥有相同键的元素拼接在一起,形成新的值。在拼接时,使用分号与空格进行分隔,以区分不同的句子。最终,我们创建了一个HBase的Put操作,用于指定key为行键,连接后的字符串result为列info:index的值,并将put写入上下文。
3.倒排索引Driver阶段实现代码及实现说明
invertedindexdriver.java代码
package com.name.mapreduce.invertedindex; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import java.io.IOException; public class invertedindexdriver { public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { // 获取Job任务对象 Configuration conf = new Configuration(); //hdfs 主nameNode通信地址 conf.set("fs.defaultFS", "hdfs://hadoop102:8020"); //yarn 主resourcemanager通信地址 conf.set("yarn.resourcemanager.hostname", "hadoop103"); //zookeeper集群,连接到HMaster conf.set("hbase.zookeeper.quorum", "hadoop102,hadoop103,hadoop104"); Job job = Job.getInstance(conf); // 设置Job任务对象 job.setJarByClass(invertedindexdriver.class); job.setMapperClass(invertedindexmapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); FileInputFormat.setInputPaths(job, new Path(args[0])); //实现reduce结果输出到 HBase的哪个表 TableMapReduceUtil.initTableReducerJob("InvertedIndex", invertedindexreducer.class, job); // 启动Job boolean res = job.waitForCompletion(true); System.exit(res?0:1); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
Driver阶段核心逻辑
(1)初始化MapReduce任务
首先创建一个Hadoop配置对象conf,包含了Mapreduce任务的配置信息,再创建一个Job任务对象,该对象将用于配置和管理MapReduce作业。
(2)设置Hadoop任务的配置信息
在配置对象conf中设置HDFS主NameNode的通信地址、Yarn主ResourceManager的通信地址、Zookeeper集群;
(3)配置MapReduce任务属性
首先指定与MapReduce作业相关的驱动程序类invertedindexdriver,其次设置Mapper阶段的Mapper类即invertedindexmapper,最后设置Mapper阶段的输出键和值的数据类型即Text类型;
(4)配置输入路径为args[0],并实现reduce结果输出到HBase的InvertedIndex表;
(5)启动MapReduce作业;
六、运行结果与分析
1.上传分割后的txt文件与实现代码的jar包
(1)在HDFS中创建一个名为input的文件夹,用来存放输入已分割好的txt输入文件:
hadoop fs -mkdir /input/
- 1
(2)将940份分割好的txt文件首先传入本地文件夹/opt/module/input中,再将该input文件夹传入HDFS中的input文件夹:
hadoop fs -put input /input
- 1
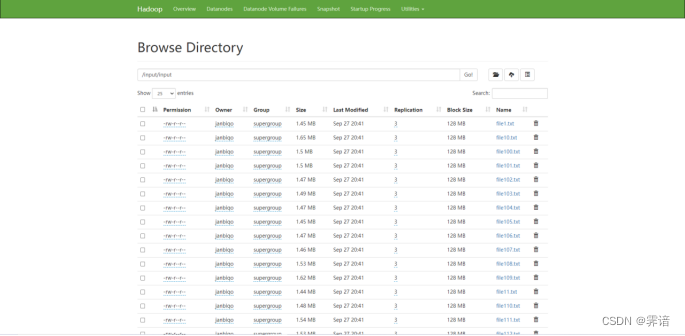
(3)在HDFS的Web端查看上传情况,存放路径为/input/input,下图所示表示在Web端可以查看到上传的分割后文件的相关情况,代表上传成功,下图为txt文件上传后的Web端HDFS情况:
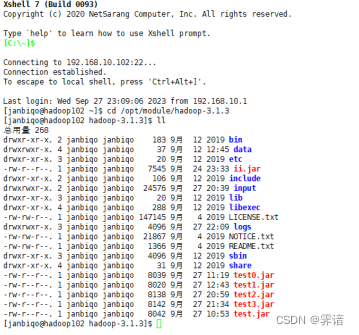
(4)将算法及实现中的代码通过package打包形成一个jar包,命名为test3.jar,并上传到/opt/module/hadoop-3.1.3,下图出现test3.jar,代表上传成功,下图为上传代码的jar包到指定路径图:
2.在HBase中创建存储数据的表格
(1)在/opt/module/hbase目录下进入客户端命令行shell:
bin/hbase shell
- 1
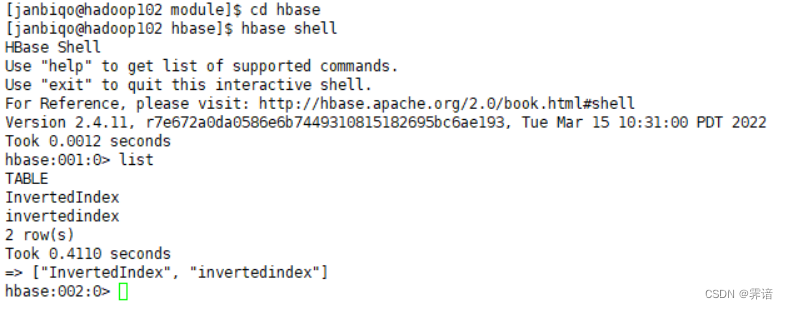
(2)创建InvertedIndex表格并查看:
create 'InvertedIndex','info'
list
- 1
- 2
下图中出现InvertedIndex,代表创建成功:
3.运行倒排索引代码
(1)执行代码
$HBASE_HOME/bin/hbase mapredcp //声明hbase的mapreduce类 **自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。** **深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!** **因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。**      **既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!** **由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新** **如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)**  t
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
下图中出现InvertedIndex,代表创建成功:
3.运行倒排索引代码
(1)执行代码
$HBASE_HOME/bin/hbase mapredcp //声明hbase的mapreduce类 **自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。** **深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!** **因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。** [外链图片转存中...(img-AitYOTEC-1712891657000)] [外链图片转存中...(img-LhrNUYiZ-1712891657001)] [外链图片转存中...(img-yqzgXekI-1712891657001)] [外链图片转存中...(img-fZqw0FTr-1712891657001)] [外链图片转存中...(img-Vf1cfS4Q-1712891657001)] **既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!** **由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新** **如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)** [外链图片转存中...(img-LIK170Nf-1712891657002)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21

