
- 1mysql 不可见字符_去除mysql 里不可见字符
- 2PHP如何实现PDF生成?底层原理是什么?_php pdf
- 3Python_vperfect.meidd.xyz
- 4pygame实现俄罗斯方块_pygame俄罗斯方块代码
- 5学习笔记(Python爬虫)——获取网页源代码以及属性和文本内容_怎么爬网页内的链接的属性
- 6python和pip安装详细步骤_windows下面安装Python和pip终极教程
- 7【Qt】Qt Style Sheets (QSS) 指南:打造个性化用户界面_qss -- qt sytle sheet
- 8数据实时传输平台(CDC)与低代码平台(APAAS)数据集成_cdc平台
- 9一文看懂深度学习(白话解释+8个优缺点+4个典型算法)_深度学习算法的优势和局限性
- 10win11 安全中心打开黑屏\白屏\打不开有效解决_win11安全中心打开空白
ICCV 2023 获奖论文公布,扩散模型、分割一切、跟踪一切摘得桂冠_adding conditional control to text-to-image diffus
赞
踩
昨天计算机视觉三大顶级会议之一的ICCV 2023在法国巴黎正式“开奖”了!今年共有两篇论文获得最佳论文奖,大名鼎鼎的“分割一切”荣获最佳论文提名。
ICCV今年共收录了2160篇论文,从今年的录用论文的主题领域来看,3D视觉、图像视频合成、迁移少样本持续学习方向排名前三。
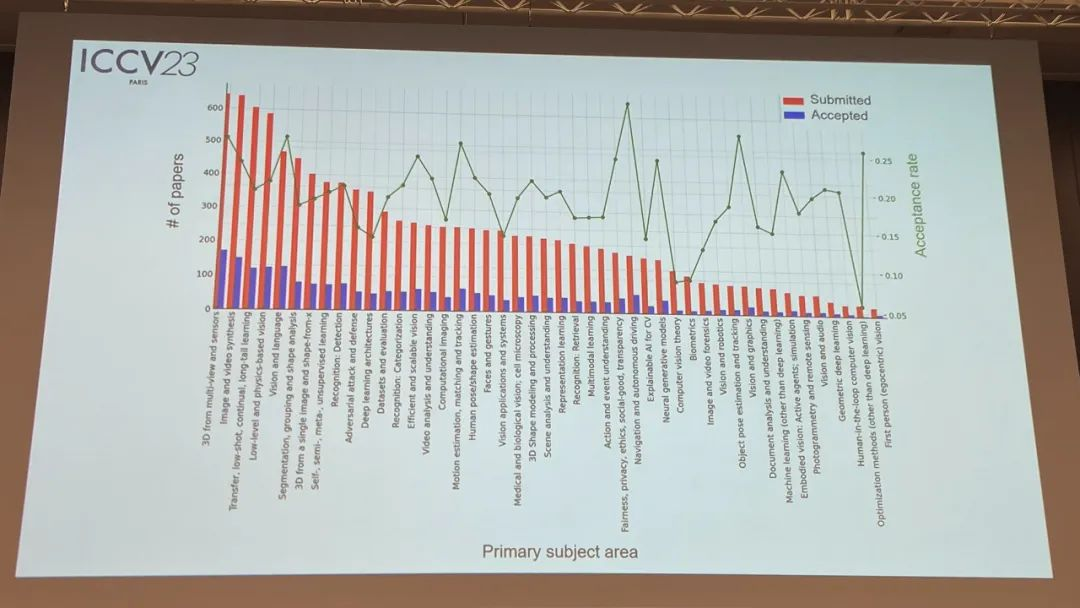
下面我们进入正题,一起来看看ICCV 2023的获奖论文详情:
最佳论文奖
Adding Conditional Control to Text-to-Image Diffusion Models
标星2.4万,被引用量已破300+
标题:向文本到图像扩散模型添加条件控制
作者:斯坦福大学
内容:论文提出了ControlNet,这是一种神经网络架构,可向大型预训练的文本到图像扩散模型添加空间条件控制。ControlNet固定了可用于生产的大型扩散模型,并重用它们在数十亿张图像上预训练的深度和稳健的编码层,作为强大的骨干来学习各种条件控制。该神经网络架构通过“零卷积”(即初始化为零的卷积层)进行连接,逐步从零增长参数,确保调优过程不会受到任何有害噪声的影响。

Passive Ultra-Wideband Single-Photon Imaging
标题:被动超宽带单光子成像
作者:多伦多大学
内容:论文考虑同时成像一个动态场景的极端时间范围的问题——从秒到皮秒级——并且采用被动方式,不需要太多光照,也不需要来自发光源的任何定时信号。由于现有的单光子相机通量估计技术在这种情况下会失效,作者开发了一种通量探测理论,其从随机微积分中获得启发,以使我们能够从单调增加的光子检测时间戳流重构像素的时间变化通量。作者使用这一理论:(1)显示被动自由运行的单光子雪崩二极管相机在低通量条件下具有覆盖整个直流至31GHz范围的可实现频带宽,(2)推导出一种新的傅里叶域通量重建算法,它扫描时间戳数据中具有统计显著支持的频率范围,(3)确保该算法的噪声模型甚至在非常低的光子计数或不可忽略的死时间下仍然有效。
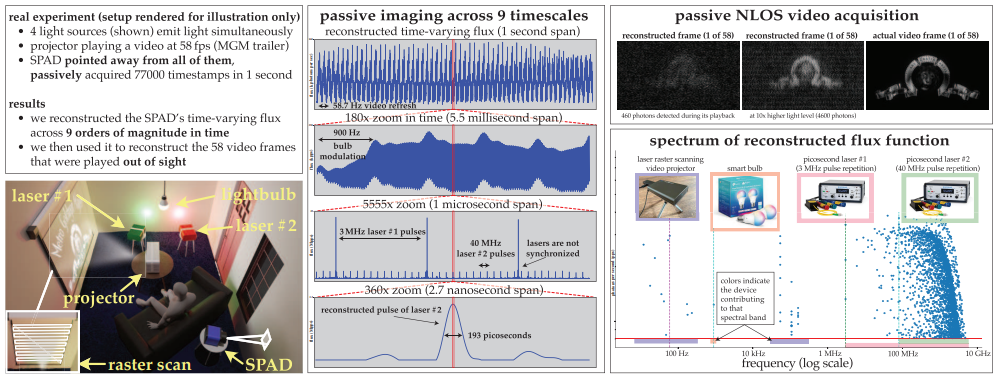
最佳论文荣誉提名奖
Segment Anything
标星4万,被引用量690
标题:分割一切
作者:Meta
内容:论文提出了“分割任何物体”(Segment Anything)项目:一个用于图像分割的新任务、模型和数据集。利用高效的模型进行数据收集,作者构建了迄今为止最大的分割数据集(目前是最大的),包含超过10亿个掩膜和1100万张授权和尊重隐私的图像。该模型的设计和训练使其可以即兴提示,因此可以零样本向新图像分布和任务进行转移。
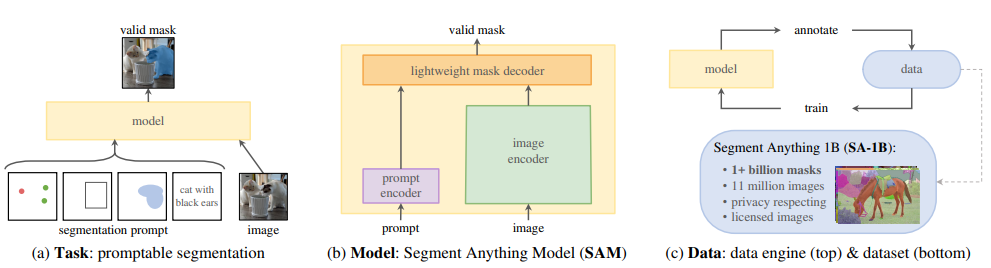
最佳学生论文奖
Tracking Everything Everywhere All at Once
标题:随时随地追踪一切
作者:康奈尔大学
内容:论文提出了一种新的测试时优化方法,用于从视频序列中估计稠密和长距离运动。以前的光流或粒子视频跟踪算法通常在有限的时间窗口内运行,在遮挡情况下跟踪效果不佳,估计的运动轨迹整体一致性较差。作者提出了一种完整的全局一致运动表示OmniMotion,可以准确地对视频中的每个像素进行全过程运动估计。OmniMotion使用准三维规范体积表示视频,并通过局部空间和规范空间之间的双射进行像素级跟踪。这种表示允许我们确保全局一致性,跟踪遮挡情况,并建模任意组合的相机和物体运动。
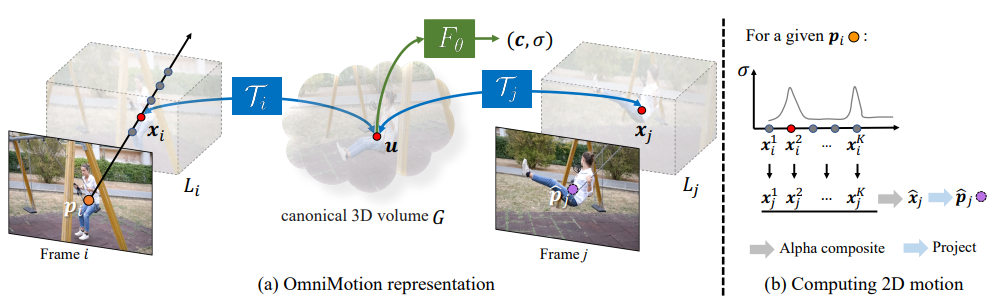
其他奖项
Helmholtz 奖
Action recognition with improved trajectories
标题:使用过改进的轨迹进行动作识别
作者:Heng Wang, Cordelia Schmid
内容:最近,稠密轨迹被证明是动作识别的一种高效视频表示,并在各种数据集上获得了最先进的结果。本文通过考虑相机运动来校正轨迹,从而提高了其性能。为了估计相机运动,作者使用SURF描述子和稠密光流匹配帧之间的特征点,然后使用这些匹配来用RANSAC稳健地估计单应矩阵。人体运动通常与相机运动不同,会生成不一致的匹配。为了改进估计,使用人体检测器去除这些匹配。给定估计的相机运动,作者删除与其一致的轨迹,还使用此估计从光流中消除相机运动,这显著改进了基于运动的描述子,如HOF和MBH。

PAMI Everingham 奖
-
The Ceres Solver open source non-linear optimization software library
-
The Common Objects in Context (COCO) dataset
获奖候选
-
Adding Conditional Control to Text-to-lmage Diffusion Models - Zhang et al.
-
Advancing Example Exploltation Can Alleviate Critical Challenges in Adversarial Training -Ge et al.
-
DiffusionDet: Diffusion Model for Object Detection - Chen et al
-
ITI-GEN: Inclusive Text-to-lmage Generation - Zhang et al.
-
Passive Ultra-Wideband Single-Photon imaging - Wei et al.
-
Ref-NeuS:Ambiguity-Reduced Neural implicit Surface Learning for Multi-View Reconstruction with Reflection -Ge et al.
-
Scale-MAE: A Scale-Aware Masked Autoencoder for Multiscale Geospatfal Representation Learning - Reed et al.
-
Segment Anything - Kirillov et al.
-
Shape Analysis of Euclidean Curves under Frenet-Serret Framework -Chassat et al.
-
The Victim and The Beneficiary: Exploiting a Potsoned Model to Train a Clean Model on Poisoned Data - Zhu et al.
-
Tracking Everything Everywhere All at Once-Wang et al.
-
Tri-MipRF: Tri-Mip Representation for Effcient Anti-Aliasing Neural Radiance Fields -Hu et al.
-
UniDexGrasp++: improving Universal Dexterous Grasping via Geometry-aware Curriculum Learning and terative Generalist-Specialist Learning - Wan et al.
-
Viewing Graph Solvability in Practice - Arrigoni et al.
-
VQ3D: Learning a 3D-Aware Generative Modet on imageNet-Sarget et al.
-
When Noisy Labels Meet Long Tail Dilemmas: A Representation Calibration Method -Zhang et al.
-
Zip-NeRF: Anti-Allased Grid-Based Neural Radiance Fields - Barron et al.
关注下方《学姐带你玩AI》
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

