
【传知代码】BERT论文解读及情感分类实战-论文复现_bert-base-uncased情感二分类
赞
踩
本文涉及的源码可从BERT论文解读及情感分类实战该文章下方附件获取
概述
本文将先介绍BERT架构和技术细节,然后介绍一个使用IMDB公开数据集情感分类的完整实战(包含数据集构建、模型训练微调、模型评估)。
IMDB数据集分为25000条训练集和25000条测试集,是情感分类中的经典公开数据集,这里使用BERT模型进行情感分类,测试集准确率超过93%。
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的双向编码器语言模型,它在自然语言处理(NLP)领域取得了显著的成果。以下是BERT的架构和技术细节,以及使用BERT在IMDB公开数据集上进行情感分类的实战介绍。
- BERT架构和技术细节
- 双向编码器:BERT模型通过联合考虑所有层中的左侧和右侧上下文来预训练深度双向表示,这使得BERT能够在预训练阶段捕获更丰富的语言特征。
- 预训练任务
- 掩码语言模型(MLM):BERT随机掩蔽词元并使用来自双向上下文的词元以自监督的方式预测掩蔽词元。在预训练任务中,BERT将随机选择15%的词元作为预测的掩蔽词元,其中80%的时间用特殊的
<MASK>词元替换,10%的时间替换为随机词元,剩下的10%保持不变。 - 下一句预测(NSP):为了帮助理解两个文本序列之间的关系,BERT在预训练中考虑了一个二元分类任务——下一句预测。在生成句子对时,有一半的时间它们确实是连续的句子,另一半的时间第二个句子是从语料库中随机抽取的。
- 掩码语言模型(MLM):BERT随机掩蔽词元并使用来自双向上下文的词元以自监督的方式预测掩蔽词元。在预训练任务中,BERT将随机选择15%的词元作为预测的掩蔽词元,其中80%的时间用特殊的
- 模型微调:预训练的BERT模型可以通过添加少量额外的输出层来微调,从而适应广泛的任务,如问答和语言推断,而无需对模型架构进行大量特定任务的修改。
- 使用BERT在IMDB数据集上进行情感分类的实战
- 数据集:IMDB公开数据集分为25000条训练集和25000条测试集,用于情感分类任务。
- 模型训练与微调
- 加载预训练的BERT模型。
- 对原始数据进行预处理,使其符合BERT模型的输入要求。
- 在训练集上训练BERT模型,进行微调以适应情感分类任务。
- 模型评估
- 在测试集上评估模型的性能,计算准确率等指标。
- 报告测试集准确率超过93%的结果。
BERT模型在多个自然语言处理任务上取得了新的最先进结果,包括情感分类任务。使用BERT模型进行情感分类能够取得较好的效果,尤其是在拥有足够数据量和计算资源的情况下。
原理介绍
BERT模型架构
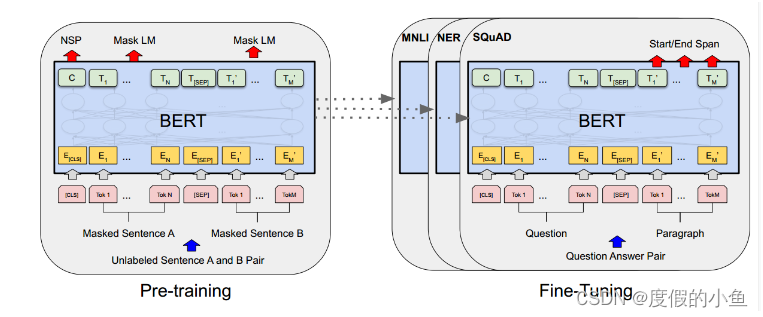
BERT模型就是transformer的encoder堆叠而成,只是训练方式是有所讲究。
BERT能够在下游任务微调,模型结构也只需要改变输出层即可方便地适配下游任务。
[CLS]是添加在每个输入示例前面的一个特殊符号,用于整体信息的表示
[SEP]是一个特殊的分隔符标记(例如分隔问题/答案)
BERT不使用传统的从左到右或从右到左的语言模型来预训练。相反,是使用两个无监督任务预训练BERT。
任务1 Masked LM(MLM)
直观地说,我们有理由相信深度双向模型严格地比从左到右模型或从左到左模型和从右到左模型的简单结合更强大。不幸的是,标准条件语言模型只能从左到右或从右到左进行训练,因为双向条件反射允许每个单词间接地“看到自己”,并且该模型可以在多层上下文中预测目标单词。
为了训练深度双向表示,只需随机屏蔽一定百分比的输入令牌,然后预测那些屏蔽的令牌。文章将此过程称为“masked LM”(MLM)。在这种情况下,被屏蔽的单词的最终隐藏向量被馈送到词汇表上的输出softmax中,然后得出预测。
文章随机屏蔽每个序列中15%的单词。然后只预测被屏蔽的单词。
尽管这能够获得双向预训练模型,但缺点是在预训练和微调之间造成了不匹配,因为[MASK]在微调过程中不会出现。为了缓解这种情况,我们并不总是用实际的[MASK]替换“屏蔽”单词。训练数据生成器随机选择15%的单词用于预测。在这些单词中,使用
(1)80%概率的替换为[MASK],即需要进行预测。 这是最常见的掩盖策略,模型需要学习根据上下文来预测原本的词汇,这样的训练方式使得模型能够更好地理解词汇在不同上下文中的含义。
(2)10%概率的替换为随机单词。 这种策略增加了训练数据的多样性,迫使模型不仅仅依赖于特定的掩盖词汇来做出预测。这种随机性有助于模型学习到更加鲁棒的上下文表示,因为它不能简单地记忆或依赖于特定的掩盖词汇。
(3)10%概率单词不变。 这种策略保留了原始词汇,不进行掩盖,这有助于模型学习到词汇本身的表示,同时也为模型提供了一些直接从输入中学习的机会,而不是完全依赖于上下文推断。
任务2 Next Sentence Prediction (NSP)
许多重要的下游任务,如问答(QA)和自然语言推理(NLI),都是基于理解两句之间的关系,而语言建模并不能直接捕捉到这一点。为了训练一个理解句子关系的模型,文章让模型在下一个句子预测任务上进行预训练,该任务可以从任何单语语料库中轻松生成。
具体而言,当为每个预训练示例选择句子A和B时,50%的概率B是A后面的下一个句子(标记为Is Next),50%的概率B是来自语料库的随机句子(标记为Not Next)。
模型输入
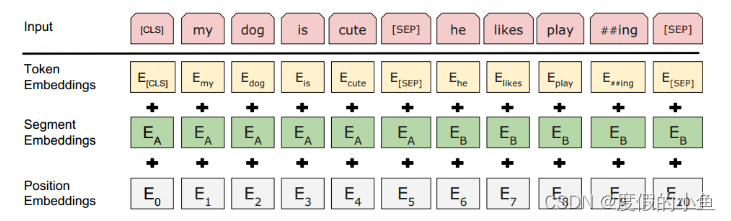
Token Embeddings就是词的嵌入层表示,只不过句子开头要加[CLS]不同句子之间要加[SEP]。
[CLS]的用处如下:
句子表示:在预训练阶段,[CLS]标记的最终隐藏状态(即经过Transformer最后一层的输出)被用作整个输入序列的聚合表示(aggregate sequence representation)。这意味着[CLS]的表示捕捉了整个序列的上下文信息。
分类任务:在微调阶段,尤其是在句子级别或序列级别的分类任务中,[CLS]的最终隐藏状态被用来作为分类的输入特征。例如,在情感分析、自然语言推断或其他类似的任务中,[CLS]的输出向量会被送入一个额外的线性层(分类层),然后应用softmax函数来预测类别。
问答任务:在问答任务中,[CLS]也可以用来进行答案的预测。例如,在SQuAD问答任务中,模型会输出答案的开始和结束位置的概率分布,而[CLS]的表示有助于模型理解问题和段落之间的关系。
[SEP]用处如下:
分隔句子:
当BERT处理由多个句子组成的句子对时(例如,在问答任务中的问题和答案),[SEP]标记用来明确地分隔两个句子。它允许模型区分序列中的不同部分,尤其是在处理成对的句子时,如在自然语言推断或问答任务中。
输入表示:
在构建输入序列时,句子A(通常是第一个句子或问题)会以[CLS]标记开始,接着是句子A的单词,然后是[SEP]标记,然后是句子B(通常是第二个句子或答案)的单词…
通过在句子之间插入[SEP],模型可以明确地知道序列的结构,从而更好地处理和理解输入的文本。
位置嵌入:
与[CLS]类似,[SEP]也有一个对应的嵌入向量,这个向量是模型学习到的,并且与[CLS]的嵌入向量不同。这个嵌入向量帮助模型理解[SEP]标记在序列中的位置和作用。
注意力机制:
在Transformer模型的自注意力机制中,[SEP]标记使得模型能够区分来自不同句子的标记,这对于模型理解句子间关系的任务至关重要。
预训练和微调:
在预训练阶段,[SEP]帮助模型学习如何处理成对的句子,这在NSP(Next Sentence Prediction)任务中尤为重要。在微调阶段,[SEP]继续用于分隔句子对,使得模型能够适应各种需要处理成对文本的下游任务。
Segment Embeddings 用于标记是否属于同一个句子。
Position Embeddings 用于标记词的位置信息
下游任务微调
BERT能够轻松地适配下游任务,此时使用已经预训练好的BERT模型就能花很少的资源和时间得到很不错地结果,而不需要我们从头开始训练BERT模型。
接下来就看一下BERT在不同数据集是怎么使用的
GLUE数据集
GLUE(General Language Understanding Evaluation)基准测试是一组不同的自然语言理解任务的集合。任务描述如下:
MNLI(Multi-Genre Natural Language Inference):给定一对句子,预测第二个句子是否是第一个句子的蕴含、矛盾或中立。
QQP(Quora Question Pairs):判断Quora上的两个问题是否语义等价。
QNLI(Question Natural Language Inference):基于斯坦福问答数据集的二分类任务,判断问题和句子是否包含正确答案。
SST-2(Stanford Sentiment Treebank):电影评论中句子的情感分类任务。
CoLA(Corpus of Linguistic Acceptability):判断英语句子是否语法正确。
STS-B(Semantic Textual Similarity Benchmark):判断句子对在语义上的相似度。
MRPC(Microsoft Research Paraphrase Corpus):判断句子对是否语义等价。
RTE(Recognizing Textual Entailment):文本蕴含任务,与MNLI类似,但训练数据更少。
WNLI(Winograd NLI):自然语言推理数据集,但由于构建问题,该数据集的结果未被考虑。
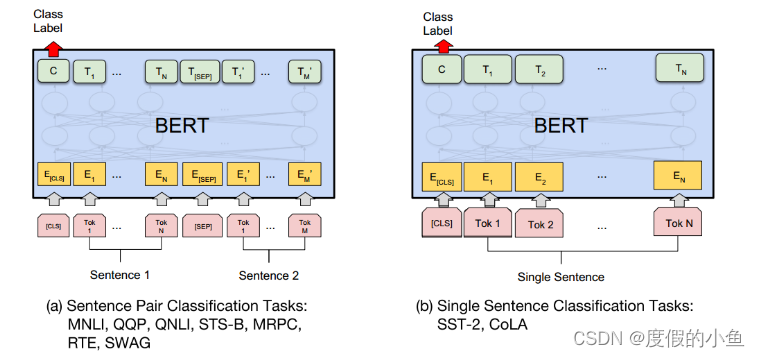
对于多个句子的,输入形式就是[CLS]+句子1+[SEP]+句子2+…
对于单个句子的就是[CLS]+句子
然后最后一层输出的[CLS]用来接个全连接层进行分类,适配不同任务需要。
SQuAD v1.1 和 v2.0
SQuAD(Stanford Question Answering Dataset)是问答任务的数据集,包括SQuAD v1.1和SQuAD v2.0两个版本。任务描述如下:
SQuAD v1.1:给定一个问题和一段文本,预测答案在文本中的位置。
SQuAD v2.0:与SQuAD v1.1类似,但允许问题没有答案,使问题更具现实性。
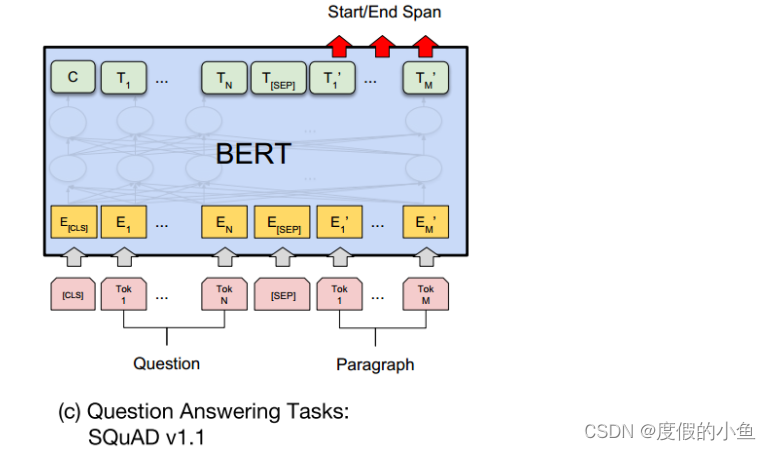
对于SQuAD v1.1,输入格式为[CLS]+问题+[SEP]+段落信息
因为这个数据集就是问题能够在段落中找到答案,构造一个得分,得分最大的作为预测值,具体如下:
首先引入S和E两组可训练参数,用于计算答案的开始和结束文章

NER
对于命名实体识别的任务,BERT实现起来也是非常简单。
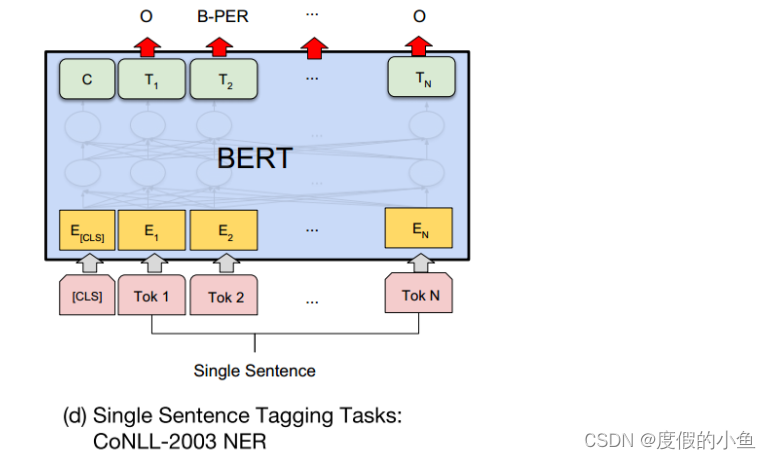
只需要对最后一层的每个单词预测对于的实体标记即可。
情感分类实战
IMDB影评情感数据集
IMDb Movie Reviews数据集是一个用于情感分析的标准二元分类数据集,它包含来自互联网电影数据库(Internet Movie Database,简称IMDB)的50,000条评论,这些评论被标记为正面或负面。
评论数量和平衡性:数据集包含50,000条评论,其中正面和负面评论的数量是相等的,即各占一半。
评分标准:评论是基于10分制的评分进行分类的。负面评论的评分在0到4分之间,而正面评论的评分在7到10分之间。
评论选择:为了确保数据集中的评论具有高度的两极性,选择了评分差异较大的评论。每部电影最多只包含30条评论。
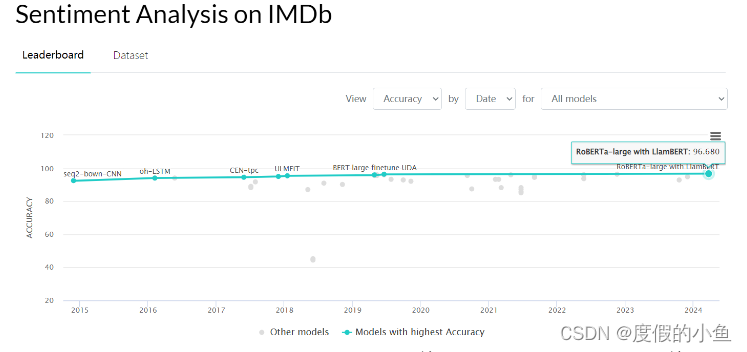
可以看一下榜单,目前在paperwithcode上最高是96.68%,看这模型的名字就不太好惹,但是我们这里简单使用BERT接个全连接进行二分类,也能达到93%
数据集构建
# 定义数据集类 class SentenceDataset(Dataset): def __init__(self, sentences, labels, tokenizer, max_length=512): self.sentences = sentences self.labels = labels self.tokenizer = tokenizer self.max_length = max_length def __len__(self): return len(self.sentences) def __getitem__(self, idx): # 对文本进行编码 encoded = self.tokenizer.encode_plus( self.sentences[idx], add_special_tokens=True, max_length=self.max_length, return_token_type_ids=False, padding='max_length', truncation=True, return_attention_mask=True, return_tensors='pt' ) # 获取编码后的数据和注意力掩码 input_ids = encoded['input_ids'] attention_mask = encoded['attention_mask'] # 返回编码后的数据、注意力掩码和标签 return input_ids, attention_mask, self.labels[idx]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
因为BERT是WordPiece嵌入的,所以需要使用他专门的切词工具才能正常使用,因此在数据预处理的过程中,可以切好词转化为bert字典中的id,这样直接喂入bert就能得到我们要的句子bert向量表示了,然后就可以用来分类了。
模型构建
使用transformers中预训练好的BERT模型(bert-base-uncased)
我们可以先来看一下bert模型的输入输出:
from transformers import BertTokenizer, BertModel
# 初始化分词器和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
sentences = ["Hello, this is a positive sentence."]
# 对句子进行编码
encoded_inputs = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt', max_length=512)
outputs = model(**encoded_inputs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
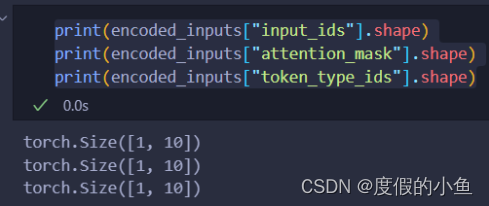
可以看到分词器的输出encoded_inputs由三部分组成,维度都是[batch_size, seq_len]
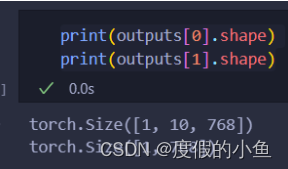
可以看到bert模型的输出为:
outputs[0]是[batch_size, seq_len, hidden_size]
outputs[1]是[batch_size, hidden_size]
outputs[0]就是每个词的表示
outputs[1]就是[CLS],可以看成这句话的表示
对于我们的任务,就是实现情感分类,因此直接使用outputs[1]接全连接就行了
核心代码
# 定义一个简单的全连接层来进行二分类
class BertForSequenceClassification(nn.Module):
def __init__(self, bert, num_labels=2):
super(BertForSequenceClassification, self).__init__()
self.bert = bert #BERT模型
self.classifier = nn.Linear(bert.config.hidden_size, num_labels)
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
pooled_output = outputs[1]
logits = self.classifier(pooled_output)
return logits
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
代码就是非常简洁,当然,如果想要更好地效果,可以直接加个LSTM、BiLSTM+Attention等来更好地进行语义编码,操作空间还是很大地。
超参数设置

batch_size=64 需要50多G显存才能跑起来,现存小的话可以开4
lr=2e-5就是微调大模型的常用学习率
epoch=2 其实结果已经很不错了,这可能就是微调的魅力
num_labels = 2因为数据集是二分类任务
因为这个实战是个简洁版本,所以超参数也设定的很少,代码也是很简洁,适合初学者参考学习
训练结果
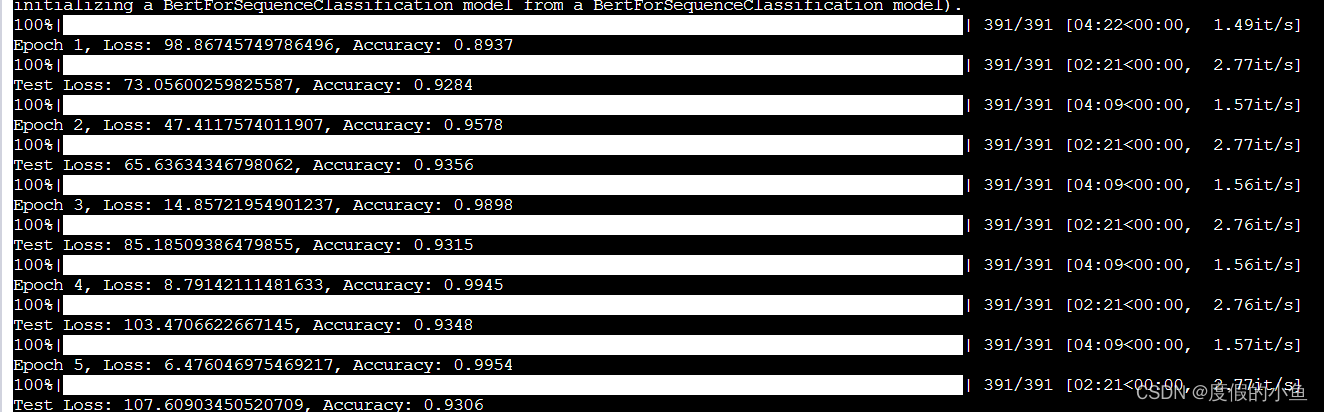
可以看到测试集的准确率最高为93.56%
还是很不错的
不过我并没有固定随机种子
可能多跑几次能够还有望超越93.56%
注意事项
train_sentences, train_labels = get_data(r'./data/train_data.tsv')
test_sentences, test_labels = get_data(r'./data/test_data.tsv')
# 初始化BERT tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
bert_model = BertModel.from_pretrained('bert-base-uncased').to(device)
- 1
- 2
- 3
- 4
- 5
模型和数据附件中都有,运行的适合需要将模型和数据的路径修改为自己的路径
小结
使用BERT在IMDB数据集上进行情感分类的实战取得了令人满意的结果。通过本次实战,我们深入了解了BERT模型的工作原理和训练方法,并获得了宝贵的实践经验。


