
- 1ELK7 ---- Kibana7.x基本的操作 kibana命令 ES查询 ES命令_kibana7.x使用教程
- 2LeetCode-热题100:74. 搜索二维矩阵
- 3Python 用pytorch从头写Transformer源码,一行一解释;机器翻译实例代码;Transformer源码解读与实战_python transformer
- 4阿里天池供应链需求预测(二)_aic热力图
- 5主流消息队列rocketMq,rabbitMq比对使用_rocketmq和rabbitmq使用上
- 6《科技创新与应用》是什么级别的期刊?是正规期刊吗?能评职称吗?
- 7TTS | 一文了解语音合成经典论文/最新语音合成论文篇【20240111更新版】_tts原理架构图
- 83分钟彻底搞懂什么是 token_token 人工智能
- 9O2OA(翱途)开发平台系统安全-用户登录IP限制
- 10Python OpenCV提取物体轮廓_python 轮廓提取
【代价函数】MSE:均方误差(L2 loss)_mseloss的表达式
赞
踩
MSE均方误差(L2 loss)
1.代码展示MAE和MSE图片特性
import tensorflow as tf import matplotlib.pyplot as plt sess = tf.Session() x_val = tf.linspace(-1.,-1.,500) target = tf.constant(0.) #计算L2_loss l2_y_val = tf.square(target - x_val) l2_y_out = sess.run(l2_y_val)#用这个函数打开计算图 #计算L1_loss l1_y_val = tf.abs(target - x_val) l1_y_out = sess.run(l1_y_val)#用这个函数打开计算图 #打开计算图输出x_val,用来画图 #用画图来体现损失函数的特点 x_array = sess.run(x_val) plt.plot(x_array, l1_y_out, 'b--', lable = 'L1_loss') plt.plot(x_array, l2_y_out, 'r--', lable = 'L2_loss')

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19

2.MSE公式及导数推导
损失函数:
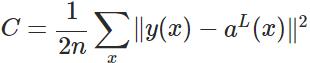
以单个样本举例:
[外链图片转存失败(img-PAQ9mnqd-1562394972088)(http://i.imgur.com/D4n2Dsz.jpg)] ,a=σ(z), where z=wx+b
利用SGD算法优化损失函数,通过梯度下降法改变参数从而最小化损失函数:
对两个参数权重和偏置进行求偏导(这个过程相对较容易):
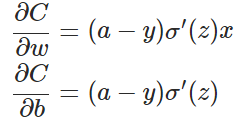
参数更新:
这边就说一种简单的更新策略(随机梯度下降):
[外链图片转存失败(img-pTU7Q58r-1562394972090)(http://image107.360doc.com/DownloadImg/2017/06/1400/101675026_3)]
3.分析L2 Loss的特点
根据上面的损失函数对权重和偏置求导的公式我们发现:
其中,z表示神经元的输入,σ表示激活函数。从以上公式可以看出,w和b的梯度跟激活函数的梯度成正比,激活函数的梯度越大,w和b的大小调整得越快,训练收敛得就越快。但是L2 Loss的这个特点存在的缺陷在于,对于我们常用的sigmoid激活函数来说,并不是很符合我们的实际需求。
先介绍下sigmoid激活函数的特性:
sigmoid函数就是损失函数的输入:a=σ(z) 中的σ()的一种。这是一个激活函数,该函数的公式,导数以及导数的分布图如下图所示:
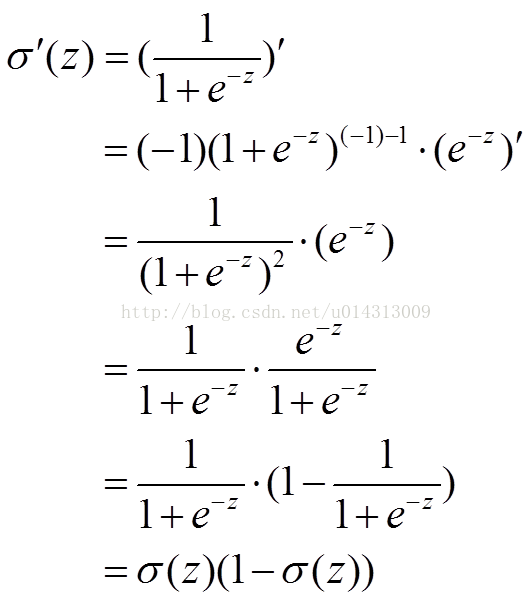
我们可以从sigmoid激活函数的导数特性图中发现,当激活值很大的时候,sigmoid的梯度(就是曲线的斜率)会比较小,权重更新的步幅会比较小,这时候网络正处在误差较大需要快速调整的阶段,而上述特性会导致网络收敛的会比较慢;而当激活值很小的时候,sigmoid的梯度会比较大,权重更新的步幅也会比较大,这时候网络的预测值正好在真实值的边缘,太大的步幅也会导致网络的震荡。这我们的期望不符,即:不能像人一样,错误越大,改正的幅度越大,从而学习得越快。而错误越小,改正的幅度小一点,从而稳定的越快。而交叉熵损失函数正好可以解决这个问题。



{kind=link}