
- 1嵌入式人工智能应用-第三章 opencv操作1
- 2测试方法——等价类划分基础测试方法_等价类测试方法
- 3sparkmllib决策树算法_sparkmllib决策树归纳算法id3
- 4Unity导出apk出现的问题,JDK,Android SDK,NDK,无“安装模块”_unity导出apk没有东西
- 5ChatGLM推出第三代基座大模型在论文阅读、文档摘要和财报分析等方面提升超过50%推理成本降低一半
- 6STM32固件库简介与使用指南
- 7微信公众号H5页面跳转小程序_微信公众号 调起小程序 jsapi
- 8如何在 GitHub 上高效阅读源码?,2024年最新字节跳动开发面试
- 9深度学习之基于Vgg19预训练卷积神经网络图像风格迁移系统
- 10分布式与一致性协议之一致哈希算法(二)
DBSCAN详解
赞
踩
一、基本概念
DBSCAN的基本概念可以用1,2,3,4来总结。
1个核心思想:基于密度
直观效果上看,DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇。
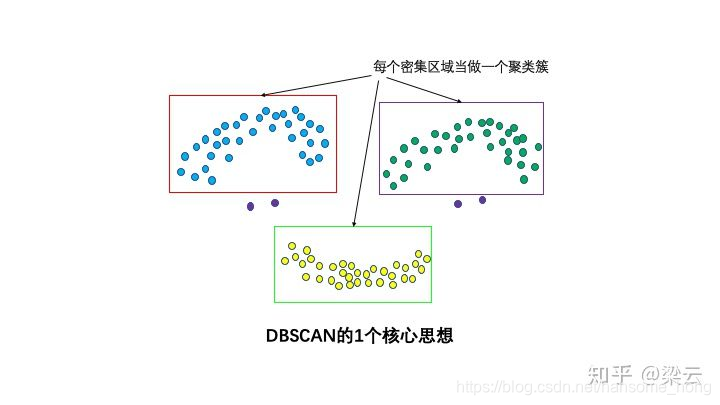
2个算法参数:邻域半径R和最少点数目minpoints
这两个算法参数实际可以刻画什么叫密集——当邻域半径R内的点的个数大于最少点数目minpoints时,就是密集。
3种点的类别:核心点,边界点和噪声点
邻域半径R内样本点的数量大于等于minpoints的点叫做核心点。不属于核心点但在某个核心点的邻域内的点叫做边界点。既不是核心点也不是边界点的是噪声点。
4种点的关系:密度直达,密度可达,密度相连,非密度相连
如果P为核心点,Q在P的R邻域内,那么称P到Q密度直达。任何核心点到其自身密度直达,密度直达不具有对称性,如果P到Q密度直达,那么Q到P不一定密度直达。
如果存在核心点P2,P3,……,Pn,且P1到P2密度直达,P2到P3密度直达,……,P(n-1)到Pn密度直达,Pn到Q密度直达,则P1到Q密度可达。密度可达也不具有对称性。
如果存在核心点S,使得S到P和Q都密度可达,则P和Q密度相连。密度相连具有对称性,如果P和Q密度相连,那么Q和P也一定密度相连。密度相连的两个点属于同一个聚类簇。
如果两个点不属于密度相连关系,则两个点非密度相连。非密度相连的两个点属于不同的聚类簇,或者其中存在噪声点。
二,DBSCAN算法
1.算法描述
DBSCAN 算法对簇的定义很简单,由密度可达关系导出的最大密度相连的样本集合,即为最终聚类的一个簇。
DBSCAN 算法的簇里面可以有一个或者多个核心点。如果只有一个核心点,则簇里其他的非核心点样本都在这个核心点的 Eps 邻域里。如果有多个核心点,则簇里的任意一个核心点的 Eps 邻域中一定有一个其他的核心点,否则这两个核心点无法密度可达。这些核心点的 Eps 邻域里所有的样本的集合组成一个 DBSCAN 聚类簇。
DBSCAN算法的描述如下。
输入:数据集,邻域半径 Eps,邻域中数据对象数目阈值 MinPts;
输出:密度联通簇。
处理流程如下。
1)从数据集中任意选取一个数据对象点 p;
2)如果对于参数 Eps 和 MinPts,所选取的数据对象点 p 为核心点,则找出所有从 p 密度可达的数据对象点,形成一个簇;
3)如果选取的数据对象点 p 是边缘点,选取另一个数据对象点;
4)重复(2)、(3)步,直到所有点被处理。
DBSCAN 算法的计算复杂的度为 O(n²),n 为数据对象的数目。这种算法对于输入参数 Eps 和 MinPts 是敏感的。
2. 算法实例
下面给出一个样本数据集,如表 1 所示,并对其实施 DBSCAN 算法进行聚类,取 Eps=3,MinPts=3。

数据集中的样本数据在二维空间内的表示如图 3 所示。

图 3 直接密度可达和密度可达示意
第一步,顺序扫描数据集的样本点,首先取到 p1(1,2)。
1)计算 p1 的邻域,计算出每一点到 p1 的距离,如 d(p1,p2)=sqrt(1+1)=1.414。
2)根据每个样本点到 p1 的距离,计算出 p1 的 Eps 邻域为 {p1,p2,p3,p13}。
3)因为 p1 的 Eps 邻域含有 4 个点,大于 MinPts(3),所以,p1 为核心点。
4)以 p1 为核心点建立簇 C1,即找出所有从 p1 密度可达的点。
5)p1 邻域内的点都是 p1 直接密度可达的点,所以都属于C1。
6)寻找 p1 密度可达的点,p2 的邻域为 {p1,p2,p3,p4,p13},因为 p1 密度可达 p2,p2 密度可达 p4,所以 p1 密度可达 p4,因此 p4 也属于 C1。
7)p3 的邻域为 {p1,p2,p3,p4,p13},p13的邻域为 {p1,p2,p3,p4,p13},p3 和 p13 都是核心点,但是它们邻域的点都已经在 Cl 中。
8)P4 的邻域为 {p3,p4,p13},为核心点,其邻域内的所有点都已经被处理。
9)此时,以 p1 为核心点出发的那些密度可达的对象都全部处理完毕,得到簇C1,包含点 {p1,p2,p3,p13,p4}。
第二步,继续顺序扫描数据集的样本点,取到p5(5,8)。
1)计算 p5 的邻域,计算出每一点到 p5 的距离,如 d(p1,p8)-sqrt(4+1)=2.236。
2)根据每个样本点到 p5 的距离,计算出p5的Eps邻域为{p5,p6,p7,p8}。
3)因为 p5 的 Eps 邻域含有 4 个点,大于 MinPts(3),所以,p5 为核心点。
4)以 p5 为核心点建立簇 C2,即找出所有从 p5 密度可达的点,可以获得簇 C2,包含点 {p5,p6,p7,p8}。
第三步,继续顺序扫描数据集的样本点,取到 p9(9,5)。
1)计算出 p9 的 Eps 邻域为 {p9},个数小于 MinPts(3),所以 p9 不是核心点。
2)对 p9 处理结束。
第四步,继续顺序扫描数据集的样本点,取到 p10(1,12)。
1)计算出 p10 的 Eps 邻域为 {p10,pll},个数小于 MinPts(3),所以 p10 不是核心点。
2)对 p10 处理结束。
第五步,继续顺序扫描数据集的样本点,取到 p11(3,12)。
1)计算出 p11 的 Eps 邻域为 {p11,p10,p12},个数等于 MinPts(3),所以 p11 是核心点。
2)从 p12 的邻域为 {p12,p11},不是核心点。
3)以 p11 为核心点建立簇 C3,包含点 {p11,p10,p12}。
第六步,继续扫描数据的样本点,p12、p13 都已经被处理过,算法结束。
3. 算法优缺点
和传统的 k-means 算法相比,DBSCAN 算法不需要输入簇数 k 而且可以发现任意形状的聚类簇,同时,在聚类时可以找出异常点。
DBSCAN 算法的主要优点如下。
1)可以对任意形状的稠密数据集进行聚类,而 k-means 之类的聚类算法一般只适用于凸数据集。
2)可以在聚类的同时发现异常点,对数据集中的异常点不敏感。
3)聚类结果没有偏倚,而 k-means 之类的聚类算法的初始值对聚类结果有很大影响。
DBSCAN 算法的主要缺点如下。
1)样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用 DBSCAN 算法一般不适合。
2)样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的 KD 树或者球树进行规模限制来进行改进。
3)调试参数比较复杂时,主要需要对距离阈值 Eps,邻域样本数阈值 MinPts 进行联合调参,不同的参数组合对最后的聚类效果有较大影响。
4)对于整个数据集只采用了一组参数。如果数据集中存在不同密度的簇或者嵌套簇,则 DBSCAN 算法不能处理。为了解决这个问题,有人提出了 OPTICS 算法。
5)DBSCAN 算法可过滤噪声点,这同时也是其缺点,这造成了其不适用于某些领域,如对网络安全领域中恶意攻击的判断。
参考和引用
- https://blog.csdn.net/dsdaasaaa/article/details/94590159?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522159575446519724835834850%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=159575446519724835834850&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_click~default-5-94590159.pc_ecpm_v3_pc_rank_v3&utm_term=DBSCAN&spm=1018.2118.3001.4187
- https://zhuanlan.zhihu.com/p/88747614
- 集成学习 ...
赞
踩

