
- 1Android Studio音频视频播放器课程设计_androidstuiod做视频播放器需要用到什么技术
- 2firewalld:禁ping设置_icmp-block-inversion
- 3如何利用 GPT4创建引人注目的流程图_gpt 绘制流程图
- 4机器人机械臂抓取综述_机械臂平面抓取
- 5ros2 launch如何控制node的启动顺序_ros2 launch文件先后启动顺序
- 6Python之密码设置_python一个合格的密码应该符合下面规则: 密码至少有8个字符。 密码包括
- 7在19计算机考研炸掉的情况下,21计算机考研的难度会很大吗?
- 8嵌入式人工智能是一个怎样的概念呢?
- 9Python爬取淘宝商品评价信息实战_python 获取商品评论
- 10从 CoT 到 Agent,最全综述来了!上交出品_cot 大模型
免费打造个人专属的高颜值本地大模型AI助手,无限量使用 Ollama+LobeChat开源工具,在本地运行AI大模型,安全的和AI对话。_ollama卸载模型
赞
踩
1、安装ollama
第一步,首先安装ollama,选择对应系统的安装包
ollama官网地址:https://ollama.com/
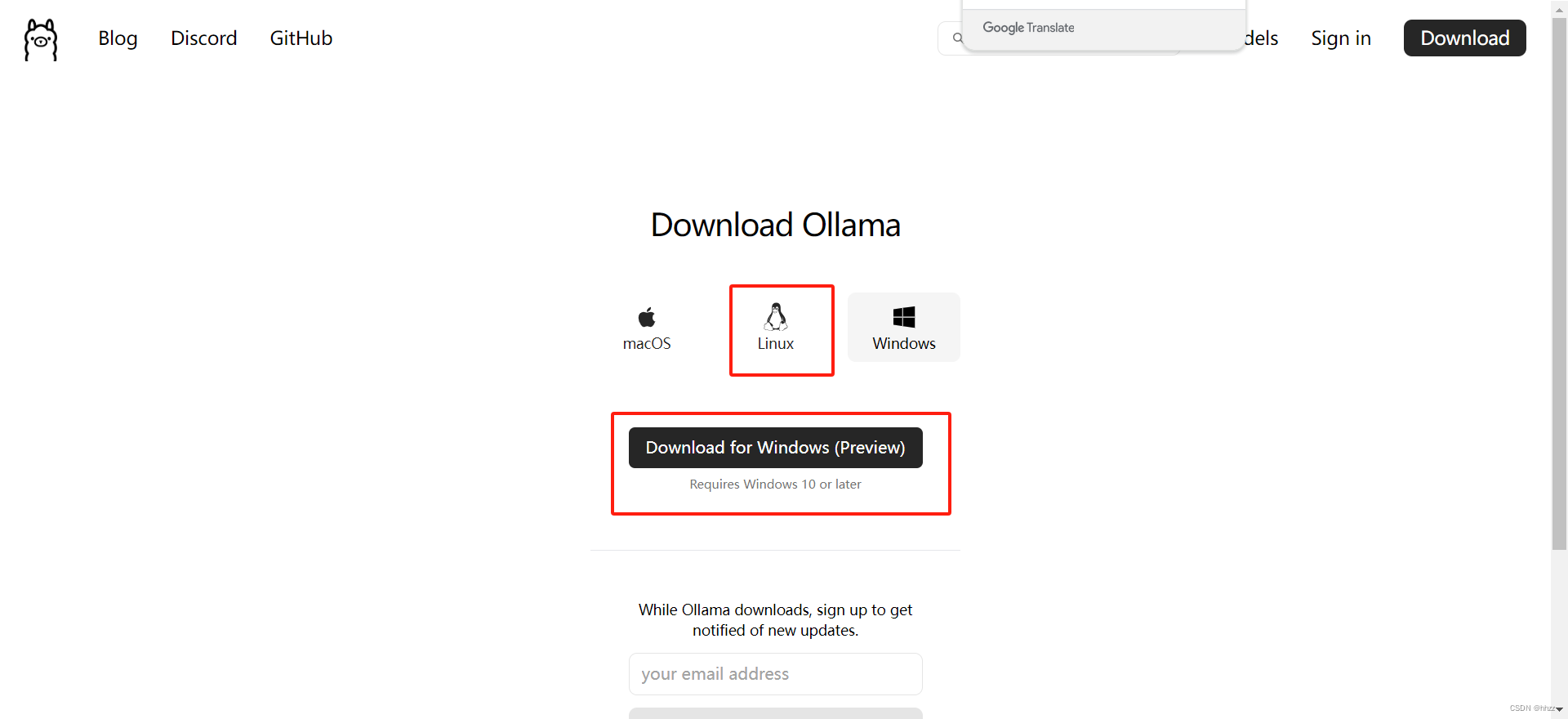
本问是lunix系统上安装ollama:
curl -fsSL https://ollama.com/install.sh | sh
- 1

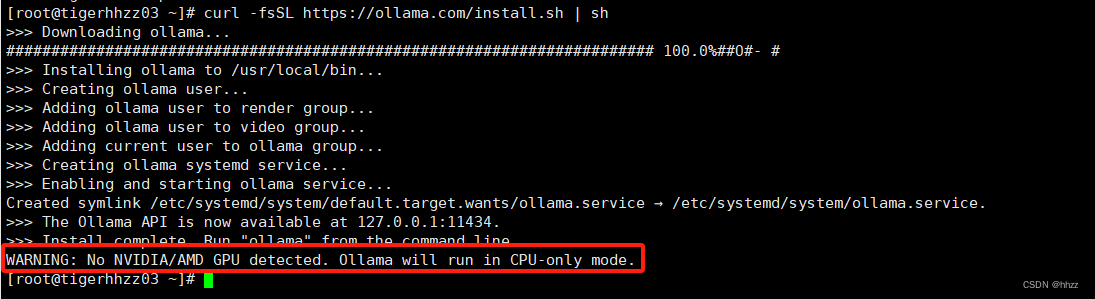
如果机子没有GPU显卡的话,ollama会提示只通过cpu模式运行。
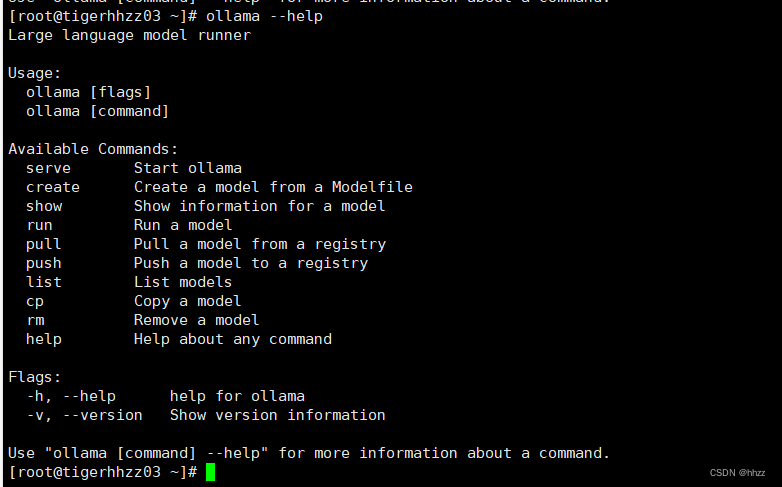
测试ollama命令:
ollama --help
- 1
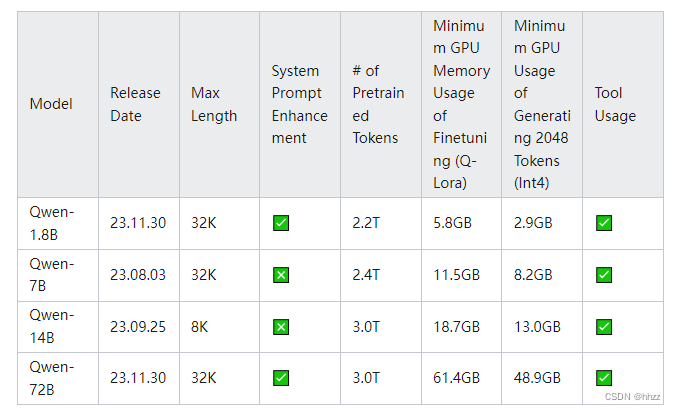
想要流畅运行,推荐配置:
-
4b的模型:8GB内存。
-
7b的模型:16GB内存。
-
13b模型: 32GB内存。
-
70b模型:64GB内存,32也能跑,太卡。
2、下载模型
ollama支持的LLM模型很多:
https://ollama.com/library
第二步,下载model,本文选择下载阿里的通义千问模型:
这里选择4b参数的模型:
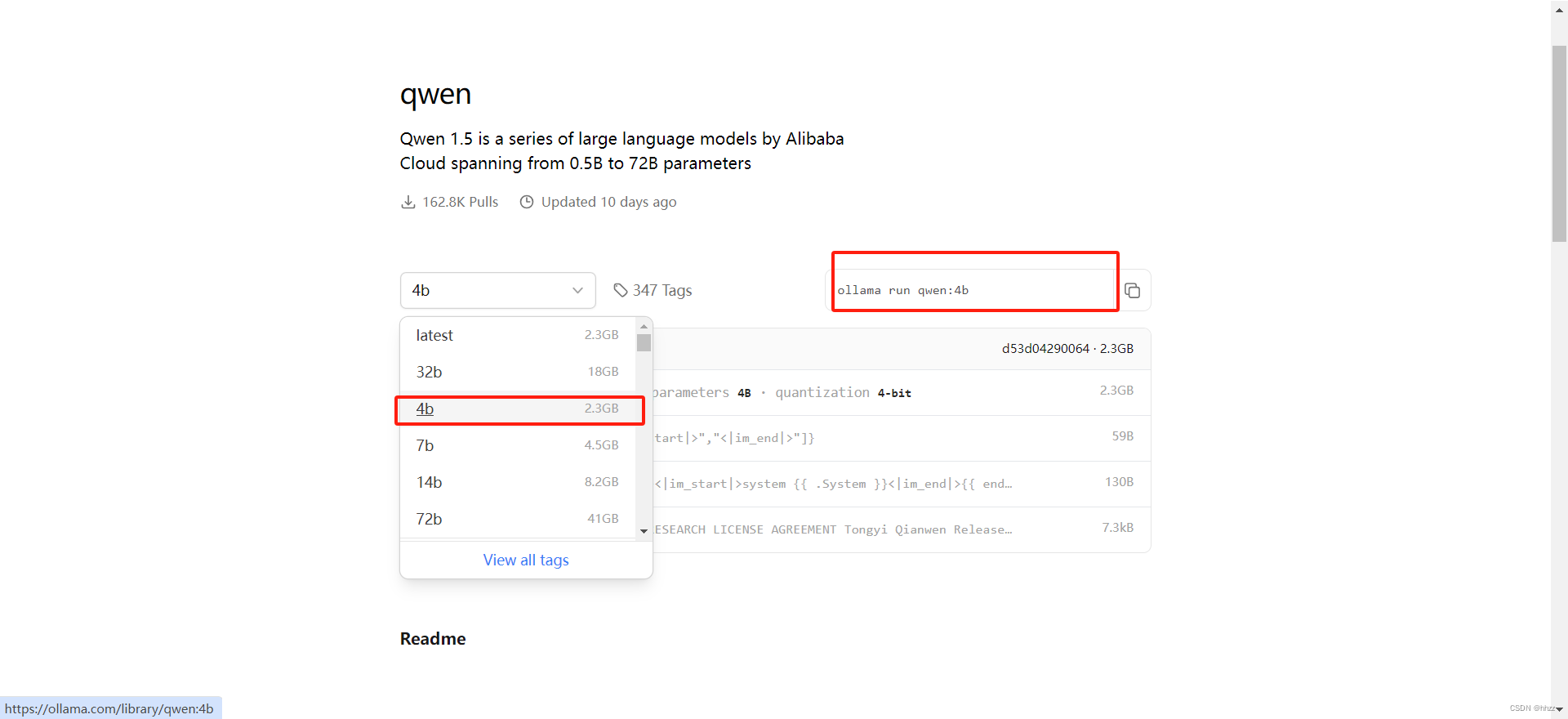
ollama run qwen:4b
- 1

ollama会自动帮我们下载模型和启动模型。
模型下载完成后,可以发送一条消息测试:

修改ollama环境变量:
#找到服务的单元文件:
#/etc/systemd/system/目录下
sudo vi /etc/systemd/system/ollama.service
#添加环境变量:
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"
#如果已经有
Environment="PATH=xxx:/root/bin" "OLLAMA_HOST=0.0.0.0:11434"
#为了使更改生效,您需要重新加载systemd的配置。使用以下命令:
sudo systemctl daemon-reload
#最后,重启服务以应用更改:
sudo systemctl restart ollama
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
使用命令行操作不太方便,使用下面的lobe chat进行界面化操作。
3、安装lobechat
Lobe Chat:现代化设计的开源 ChatGPT/LLMs 聊天应用与开发框架,支持语音合成、多模态、可扩展的(function call)插件系统,一键免费拥有你自己的 ChatGPT/Gemini/Claude/Ollama 应用。
lobe chat参考地址:https://github.com/lobehub/lobe-chat/blob/main/README.zh-CN.md
使用docker方式进行安装:
docker run -d -p 3210:3210 -e OLLAMA_PROXY_URL=http://host.docker.internal:11434/v1 lobehub/lobe-chat
- 1
#你在自己的私有设备上部署 LobeChat 服务。使用以下命令即可使用一键启动 LobeChat 服务:
$ docker run -d -p 3210:3210 \
-e OPENAI_API_KEY=sk-xxxx \
-e ACCESS_CODE=lobe66 \
--name lobe-chat \
lobehub/lobe-chat
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
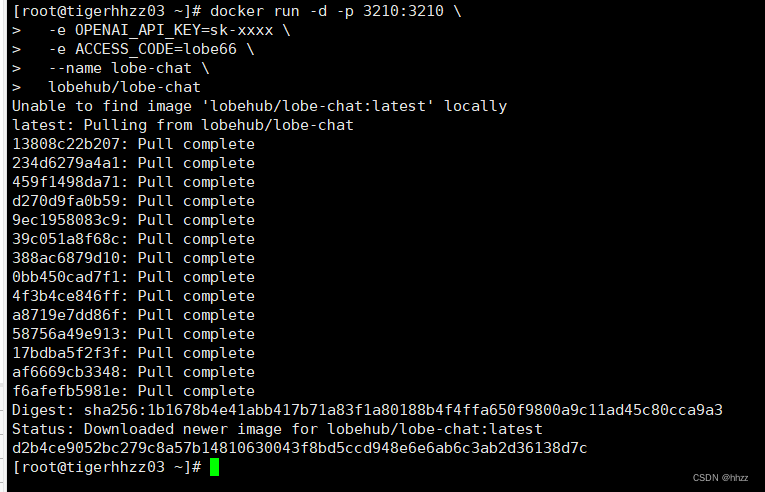
开通3210端口,进行访问测试:
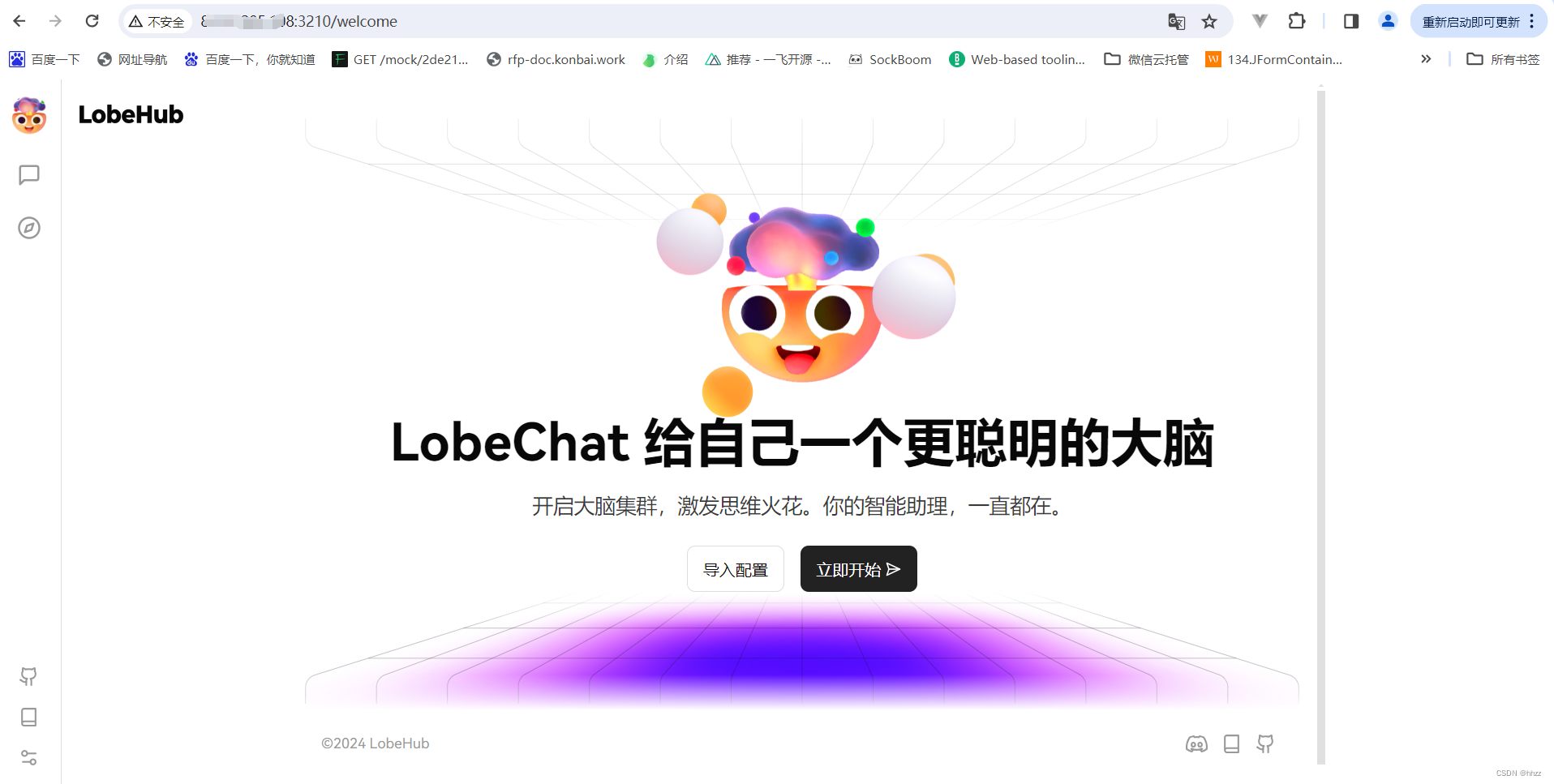
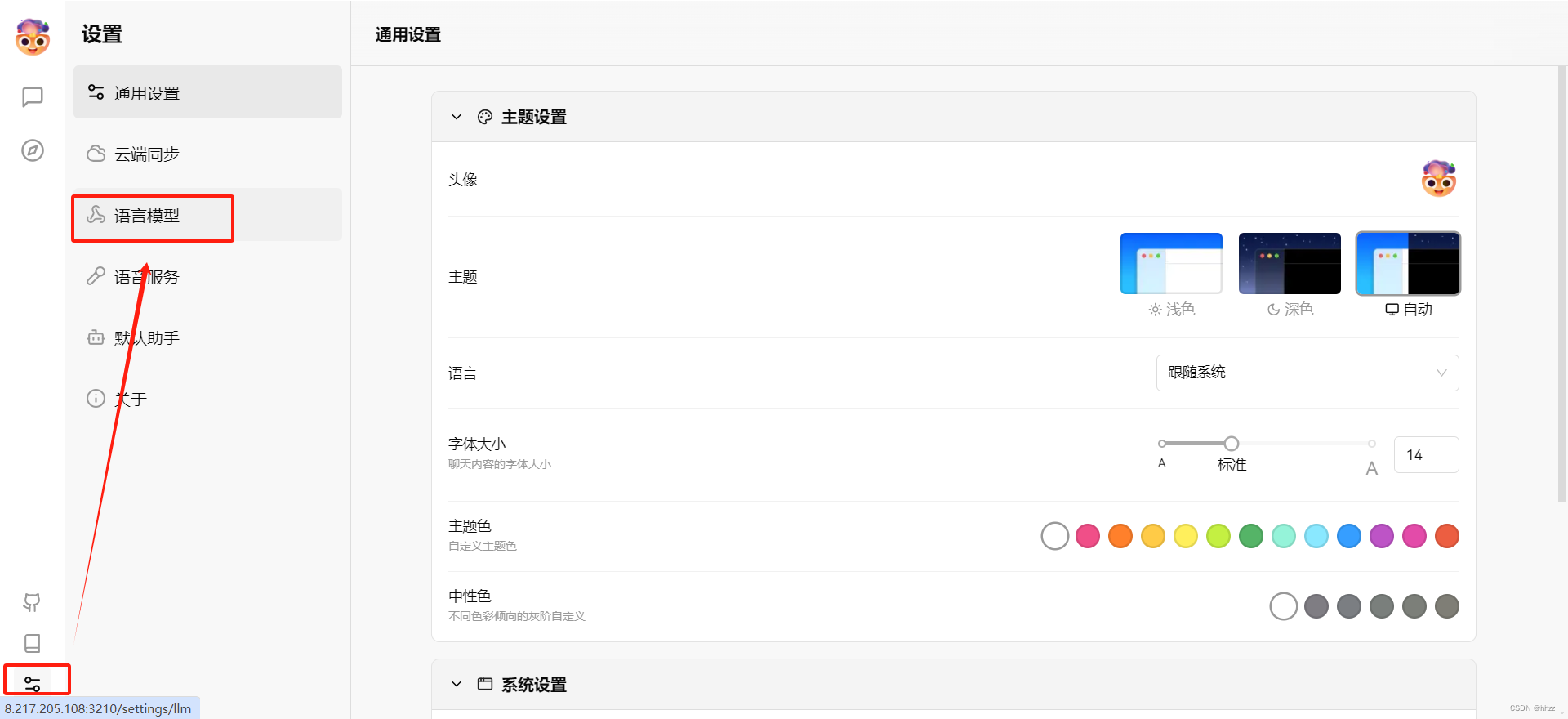
配置lobe chat:
首先将模型切换到我们下载好的qwen 4b模型:
点击设置—选择语言模型
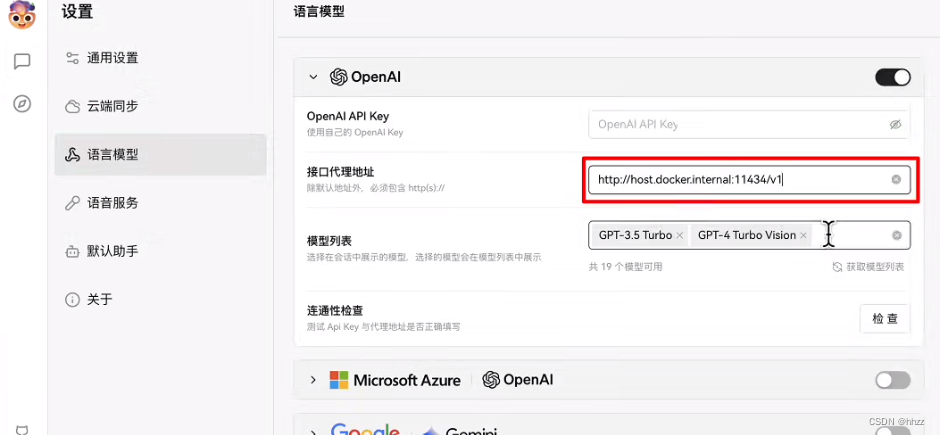
ollama完全兼容openai的接口,在接口代理地址中输入我们的ollama地址。
http://host.docker.internal:11434/v1
- 如果是docker的话,用 http://host.docker.internal:11434/v1
- 手动的话,就用 http://localhost:11434/v1 或者 http://127.0.0.1:11434/v1
如果是跑4b,7b等小模型,普通电脑就可以了,如果要跑32b比较大的,最好是有GPU,还要显存比较大
硬盘没啥要求,比如4b的模型,才2.3GB而已,30b的也就30GB左右,完全不用担心磁盘.
4、卸载Ollama
如果您决定不再使用Ollama,可以通过以下步骤将其完全从系统中移除:
停止并禁用服务:
sudo systemctl stop ollama
sudo systemctl disable ollama
- 1
- 2
删除服务文件和Ollama二进制文件:
sudo rm /etc/systemd/system/ollama.service
sudo rm $(which ollama)
- 1
- 2
清理Ollama用户和组:
sudo rm -r /usr/share/ollama
sudo userdel ollama
sudo groupdel ollama
- 1
- 2
- 3

每一次的跌倒,都是对未来的一次深情拥抱。

