
- 1(整理)手机上一些常用的url_url大全
- 2【毅力挑战】PCIe 每日一问一答(2022.02 归档)_modified compliance pattern
- 3Android的前后端分离尝试——基于springboot和okhttp3_android后台能用spring吗
- 4redis持久化
- 5《智能家居系统》6_gec6818划屏算法
- 6Zookeeper集群搭建_zookeeper.request.timeout
- 7No route info of this topic, RMQ_SYS_TRACE_TOPIC 解决方案
- 8【pytorch】nn.linear 中为什么是y=xA^T+b
- 9adb 常用命令记录_adb保存日志到本地
- 10git分布式版本控制工具_分布式版本控制 fork clone update push commit
第5章:5.3.2 字符向量元胞数组(MATLAB入门课程)_names 必须为非空字符向量,或者包含非空名称的字符串数组或字符向量元胞数组。
赞
踩
讲解视频:可以在bilibili搜索《MATLAB教程新手入门篇——数学建模清风主讲》。
MATLAB教程新手入门篇(数学建模清风主讲,适合零基础同学观看)_哔哩哔哩_bilibili
5.3.2 字符向量元胞数组
在上一节中,我们详细介绍了一般的元胞数组的使用方法。本节将重点学习字符向量元胞数组,这是一种特殊的元胞数组,元胞中的每个数据都是字符向量类型。
在 MATLAB 2016b 版本以前,字符向量元胞数组是处理和分析文本数据的核心工具。但是,自 MATLAB 2017a 版本起,官方推荐使用更为高效的字符串类型来处理文本。这种新的字符串类型采用英文双引号(")进行标识,单个这类文本被称为字符串标量。将多个字符串标量放到同一个数组中,便构成了一个字符串数组。关于这一点,我们将在下一小节中进行更深入的探讨。即便引入了这种新的文本类型,本节介绍的文本处理方法依然至关重要,它们不仅助力于理解即将介绍的字符串类型,而且许多文本处理函数能同时适用于字符向量元胞数组和字符串类型。以下是本节将要学习的一些基础文本处理函数,这些函数自 MATLAB 2016b 版本以前就已经存在:

(1)cellstr函数:将其他类型的文本转换为字符向量元胞数组
cellstr 函数可以将其他类型的文本数据转换为字符向量元胞数组,它的基本用法非常简单:C = cellstr(A),这里的A通常是字符数组,也可以是我们下一节要学的字符串数组,C就是转换后得到的字符向量元胞数组。下面我们来看几个例子:

从上面的例子可以看出,如果输入的数据类型是字符数组(包括字符向量和字符矩阵),cellstr函数在转换过程中会自动删除每行尾部的空白字符。这相当于对转换后的每个元胞中的数据应用了 deblank 函数。然而,如果转换的对象是字符串数组(将在下一节学习),则不会删除尾部的空白字符。
下面我们来看一道例题:请将字符向量'1'、 '2'一直到'100'保存到元胞数组C中。
这个题目有多种实现的思路,最容易想到的就是使用for循环,我们可以使用num2str函数将数字1至100转换为字符向量,然后依次储存到元胞数组C中。

现在考考大家,如果不用循环语句大家可以解决这个问题吗?
在之前的小节中,我们介绍过 num2str 函数,当输入变量分别是行向量和列向量时:

我们重点来看列向量的转换结果,转换后的结果是一个字符矩阵,每一行的字符向量由原来的数字转换而成,因此借助这个思路我们可以给出相应的代码:

然而,转换后的数字前面有num2str函数自动填充的空格,由于cellstr函数不会自动删除前面的空白字符,因此我们需要手动处理。这里我们可以使用strip函数或者strtrim函数删除C中各字符向量开头的空格:

当然,这个例题仅仅是为了帮助大家复习相关的知识点,如果大家学习了下一节要介绍的字符串数组,只需要一行代码就能解决:C = cellstr(string(1:100))。
拓展:和cellfun函数类似,MATLAB中还有 arrayfun 函数,它可以对数组中的每个元素应用给定的函数。这个函数我们会在后续的章节进行讲解。使用arrayfun函数也只需要一行代码就能解决:C = arrayfun(@num2str, 1:100, 'UniformOutput', false) 。
(2)isletter、isspace和isstrprop函数:识别特定种类的字符
在MATLAB中,isletter、isspace 和 isstrprop 函数用于识别文本中特定种类的字符。这三个函数在文本处理中非常有用,尤其是在字符数据的预处理和分析阶段,其中isstrprop 函数是前两个函数的进阶版。
isletter 函数用于判断字符是否为字母,它的使用方法非常简单:TF = isletter(A),输入参数A通常是字符数组或字符串标量(如果A是其他数据类型,那么isletter函数会返回全为0的逻辑数组或者直接报错);返回值TF是一个逻辑数组,当 A 中的某个字符是字母时,TF中对应位置的元素是逻辑值1,否则是逻辑值0。(注意:isletter函数不仅会识别英文字母,还会识别其他语言中的文字,例如中文的汉字也会被识别为逻辑值1)

如果你想处理字符向量元胞数组,你可以借助 cellfun 函数,给定isletter函数句柄并指定'UniformOutput'参数为false(isletter函数的返回值不是标量):

isspace函数和isletter 函数的使用方法类似,它用于判断字符是否为空白字符,如空格、制表符、换行符。

下面我们来看一个思考题:能否找出所有被isspace函数识别为空白字符对应的Unicode编码?
在Unicode字符集中,十进制0 到 2^16-1 (十六进制0000-FFFF)涵盖了绝大多数常用字符,包括各种语言的文字、符号、以及特殊字符,因此我们识别的字符范围可以限定在这个区间内。下面我们给出代码:

上面代码中的ind是一个逻辑数组,all_unicode(ind)就是使用ind对变量all_unicode进行逻辑索引,得到这些空白字符对应的Unicode编码。限于篇幅,右侧的结果没有显示完整,完整的结果中有25个编码,感兴趣的同学可以查看本章附录2:MATLAB中的空白字符。
isstrprop函数是前两个函数的进阶版本,它不仅能够识别字母和空白字符,还能识别更广泛的文本形式,如数字、标点符号、控制字符等。此外,isstrprop函数具备处理多种类型的文本数据的能力,包括字符数组、字符串标量、数值数组(其中的元素代表 Unicode 编码)、字符向量元胞数组,以及字符串数组。(prop来自单词property,可翻译为属性)
isstrprop 函数的基本用法是 TF = isstrprop(str, category)。其中,第一个输入参数str 表示文本数据, 第二个输入参数category 是你想要检测的字符类别。它支持多种字符类别,例如 'alpha'(字母)、'digit'(数字)等。以下它是支持的字符类别的列表(来自MATLAB官网):

根据输入文本数据 str 的数据类型,isstrprop 函数返回不同类型的结果:
- 如果str是字符数组、字符串标量或数值数组,则TF为逻辑数组类型;
- 如果str是字符向量元胞数组或字符串数组,则TF为元胞数组类型。
此外,我们还可以在输入参数的最后加上'ForceCellOutput', true,这样可以强制返回值TF为一个元胞数组,即使 str 是一个字符数组、字符串标量或数值数组也是如此。
我们来看例子:
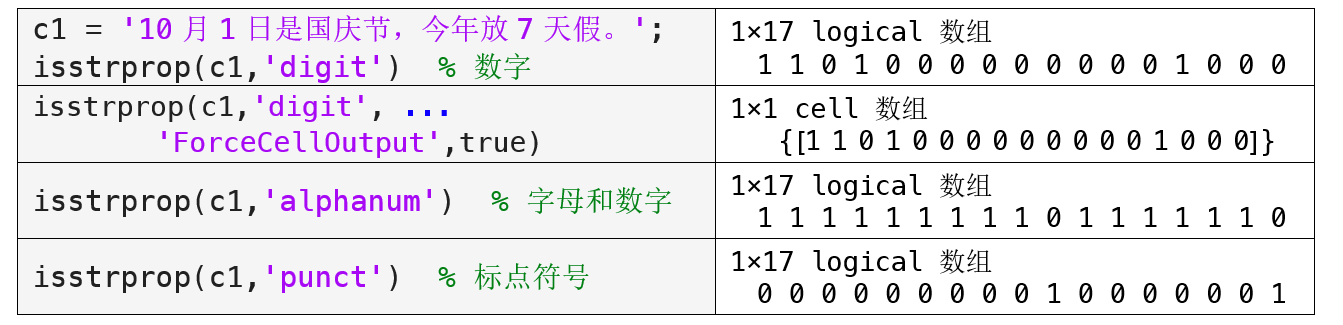
下面再来看一个实际的例子。假设字符向量元胞数组c2中保存着客户的信息,包括客户的姓名、手机号和所在城市,我们的目标就是提取客户的手机号。如果每位客户的手机号在字符向量中的位置都是固定的,例如都是1至11位,那么就可以借助字符向量的索引来提取手机号,但下面给的例子显然不满足这样的规则,此时我们可以借助isstrprop函数:

isstrprop函数返回了一个逻辑向量构成的元胞数组TF,逻辑向量中为1的位置就是手机号所在的位置。接下来,我们可以通过循环遍历 c2,并使用TF中的逻辑索引提取手机号码:

通过 isstrprop 函数,我们可以有效地处理和分析含有混合类型文本的数据,特别是在提取特定格式的信息(如电话号码)时。它的灵活性和强大的识别能力使其成为MATLAB文本分析的有力工具。
拓展:能否不使用循环语句直接提取元胞数组中每一个字符向量对应的电话号码信息?
下面我们给出两种解决方案(这两种方法涉及到后面章节的内容,这里仅作演示):
 第一种方法利用了 cellfun 函数和匿名函数。我们首先定义了一个匿名函数 f,该函数通过 isstrprop 函数识别并提取字符向量中的数字。然后,我们利用 cellfun 函数,将这个匿名函数应用于元胞数组 c2 中的每个字符向量,以便提取电话号码。在本书后续关于自定义函数的章节中,我们将对匿名函数的使用方法进行详细的介绍。
第一种方法利用了 cellfun 函数和匿名函数。我们首先定义了一个匿名函数 f,该函数通过 isstrprop 函数识别并提取字符向量中的数字。然后,我们利用 cellfun 函数,将这个匿名函数应用于元胞数组 c2 中的每个字符向量,以便提取电话号码。在本书后续关于自定义函数的章节中,我们将对匿名函数的使用方法进行详细的介绍。
第二种方法借助了 MATLAB 强大的正则表达式处理能力。我们首先定义一个匹配11位数字的电话号码模式,然后使用 regexp 函数来从每个字符向量中提取符合该模式的文本。在下一章中,我们将详细探讨正则表达式的使用技巧。
(3)strfind函数和strrep函数:查找与替换文本
在处理文本数据时,我们经常需要查找指定的文本,并在必要时进行替换。事实上这一需求在文本处理中非常常见,下图是记事本和Word软件的查找替换界面:
在MATLAB中,对文本数据进行查找和替换可以通过 strfind 和 strrep 函数实现(rep来自单词replace,单词find和replace翻译成中文分别是查找和替换),下面我们直接引用MATLAB官网的帮助文档来介绍它们的用法。
先来看strfind函数的帮助文档:
k = strfind(str,pat) 在 str 中搜索出现的 pat。输出 k 指示 str 中每次出现的 pat 的起始索引。如果未找到 pat,则 strfind 返回一个空数组 []。strfind 函数执行区分大小写的搜索。
str:输入文本,指定为字符串数组、字符向量或字符向量元胞数组。
pat:搜索模式,指定为下列值之一:字符串标量、字符向量和pattern标量。
如果 str 是字符向量或字符串标量,则 strfind 返回 double 类型的向量。
如果 str 是字符向量元胞数组或字符串数组,则 strfind 返回 double 类型的向量元胞数组(即元胞数组中的数据为double类型的向量)。
当 cellOutput 参数设置为 true 时,即使 str 是字符向量, k = strfind(str,pat,'ForceCellOutput',cellOutput) 也会强制 strfind 以元胞数组形式返回 k。
让我们通过几个实例来具体了解 strfind 函数的用法:

以上示例清晰展示了 strfind 函数在各类文本数据中查找指定文本的能力,同时也突出了它对大小写敏感的特性。
另外,在上方介绍搜索模式pat时,提到了一个新概念:“pattern标量”。MATLAB从 2020b 版本开始,引入了 pattern 类型作为一种新的搜索模式。pattern 类型专门用于搜索和匹配文本,它提供了一些高级的匹配功能,大家可以在MATLAB官网搜索关键词:pattern。
pattern可翻译为模式,以下是MATLAB官方文档中对它的介绍:

为了更好地理解 pattern 类型的应用,让我们看两个例子。假设我们想在文本中匹配数字,可以这样编写代码(请确保您的MATLAB版本不低于2020b,否则会报错):

尽管 pattern 类型是一个非常有用的功能,但在本教程中,我们不打算深入探讨它,主要基于以下三点考虑:首先,pattern 类型对MATLAB版本有较高要求,仅在2020b及以上版本中可用,低版本中使用会导致错误。其次,pattern 类型涉及多个新函数,这些函数名称较长,对非英语母语的读者可能不够友好,且不易记忆。最后,我们在下一章要学习的正则表达式功能可以完全替代 pattern 类型的功能。正则表达式是一种广泛使用且功能强大的文本处理工具,在多种编程语言中都有应用,且各语言间的语法高度相似。
因此,为了保持教程的实用性和通用性,我们将重点放在下一章要介绍的正则表达式上,这是一种更广泛认可和使用的文本处理方法。
接下来,让我们了解一下 strrep 函数的用法。strrep 函数用于将旧文本替换成新的文本。
newStr = strrep(str,old,new) 将 str 中出现的所有 old 都替换为 new。
str:输入文本,指定为字符串数组、字符向量或字符向量元胞数组。
old:要替换的子字符串(注意:这里所说的“字符串”可以理解为文本,并不仅限于字符串这种数据类型),指定为字符串数组、字符向量或字符向量元胞数组。
new:新的子字符串(子文本),指定为字符串数组、字符向量或字符向量元胞数组。
如果任何输入参数是非标量字符串数组或字符向量元胞数组,则其他输入参数的大小必须兼容。
下面我们来看例子:

在最基本的用法中,strrep 函数用于替换指定的子文本。例如,我们将c1中的'喜欢'替换为了'不喜欢'。此外, strrep 函数在替换时是区分英文字母的大小写的,例如我们将c2中的'matlab'替换为了'MATLAB'。
strrep 函数还可以接受元胞数组作为输入,这允许用户在单个函数调用中执行多种不同的替换操作,返回的结果也是元胞数组形式。
此外,strrep 函数在处理重叠文本时的特性值得关注。当要替换的文本相互重叠时,strrep 函数的处理方式会有特定的表现。下面我们用 strrep 来处理一个包含重叠文本的例子:

大家观察MATLAB的返回结果,结果中出现了三次*,这是因为strrep函数认为'abababab'中出现了三次'aba',即允许重叠子文本。下图给出了两种不同的替换方式,strrep函数使用的就是左侧的方式。
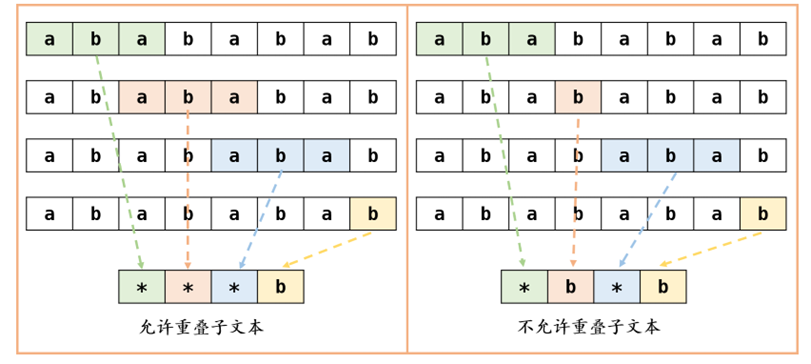
如果你希望使用右侧的方法进行替换,那么你可以使用MATLAB在2016b版本中推出的replace函数,它在替换时不允许重叠子文本:

另外,replace函数和strrep函数用法非常相似,newStr = replace(str,old,new) 将所有出现的子文本 old 替换为 new。如果 old 包含多个子文本,则 new 必须与 old 具有相同的大小,或者必须为单个子文本。注意:如果old或new不是标量(即不是单个文本,而是包含多个文本的字符向量元胞数组或者字符串数组),replace函数和strrep函数返回的结果有很大差异:

大家可以对比 strrep 函数的返回结果,当输入参数old 或 new 中的文本不是标量时,strrep 函数会依次将 old 和 new 中的文本进行匹配,并分别进行替换。因此,如果输入的 old 或 new 是元胞数组或字符串数组,strrep 函数会返回一个相应大小的元胞数组或字符串数组,其中包含了每次替换的结果。相比之下,replace 函数在处理非标量文本时,它的返回值是一个标量,即相当于在该文本中进行了多轮替换。
此外,replace函数的old参数还支持pattern 数组,前文介绍过,pattern 类型专门用于搜索和匹配文本,我们教程不会具体讲解,下一章中将使用正则表达式代替它。
(4)strjoin函数:对数组中的文本进行连接
有时候我们希望对字符向量元胞数组或者字符串数组中的文本进行连接,例如使用空格连接不同的单词、使用换行符连接各段文字等。strjoin函数可以帮助我们完成这个任务,下面来看它的基本用法:
str = strjoin(C) 使用空格将 C 的元素与相邻的元素之间连接起来,构造 str。C 可以是字符向量元胞数组或字符串数组。
str = strjoin(C,delimiter) 使用delimiter将 C 的元素与相邻的元素之间连接起来,构造 str。delimiter是分隔字符,它通常是字符向量类型。如果它是字符向量元胞数组或字符串数组,则它包含的元素数必须比 C 中包含的元素数少一个,此时strjoin 通过交错插入 delimiter 和 C 的元素来形成 str。
它的使用方法非常简单,我们直接来看例子:

注意,在使用 strjoin 函数时,分隔符可能包括一些在文本中不易直接表示的特殊字符,比如上述示例中的换行符。在MATLAB中,为了便于使用换行符,提供了专用的 newline 函数。此外,换行符的ASCII编码是10,因此我们还可以通过 char(10) 来表示换行符。
对于其他一些不方便使用文本表示的字符,你也可以使用对应的ASCII编码来表示。下面我们将介绍另一种表示特殊字符的方法:使用转义字符。
什么是转义字符?转义字符在许多编程语言中都存在,它是一类特殊的字符,用于在文本中表示特定的字符,以下是MATLAB中常用的转义字符:
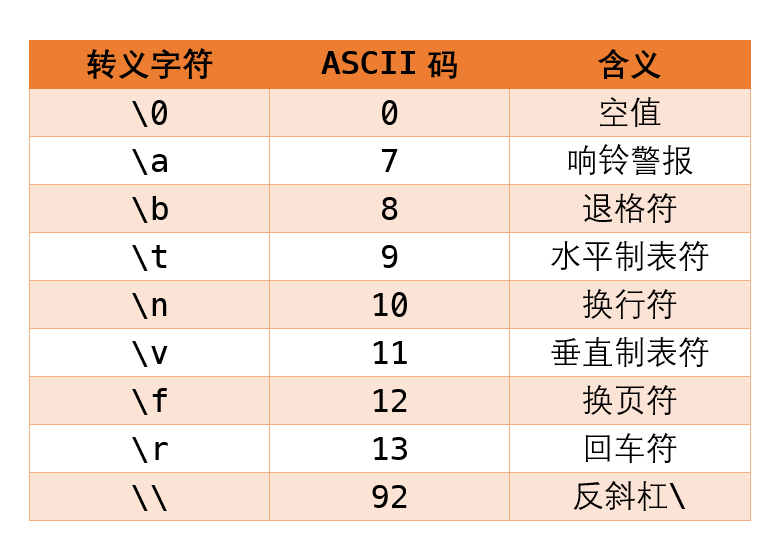
(注:上表中常用的转义字符为\t和\n,另外\\表示的是反斜杠\本身,类似于字符向量中两个连续的单引号''表示的是单引号'本身。)
strjoin函数的分隔字符中可以包括上表列举的转义字符,这样可以更方便的对文本进行连接。

此外,MATLAB中的转义字符单独使用没有含义,它们通常需要结合文本处理相关的内置函数一起使用。
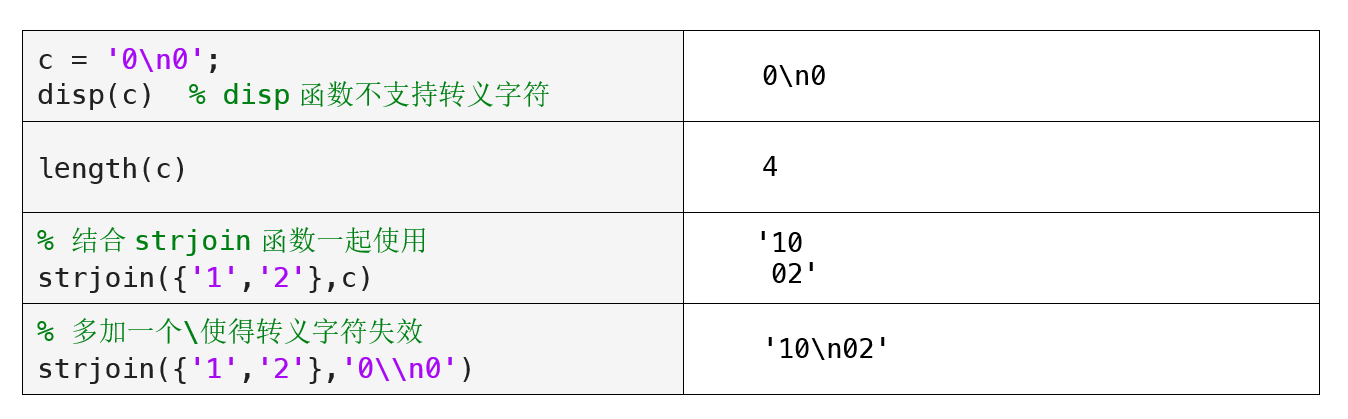
通过上述示例,我们可以看到 strjoin 函数如何有效地将数组中的文本元素连接起来,不论是使用默认的空格还是选用自定义的分隔符。这一特性使得 strjoin 函数特别适用于整合零散的文本数据,进而方便后续的处理和展示。
(5)strsplit函数:在指定分隔符处拆分文本
当我们需要将一个长文本拆分成多个更短的文本时,就需要用到strsplit函数。它的功能非常强大,以下是MATLAB官网给出的它的基本用法:
C = strsplit(str)在空白处将str拆分为C,str指定为字符向量或字符串标量。
返回值C是字符向量元胞数组。空白字符等效于集合{' ','\f','\n','\r','\t','\v'} 中的任何转义序列。如果 str 具有连续的空白字符,则 strsplit 将它们视为一个空格。
C = strsplit(str, delimiter)在 delimiter 指定的分隔符处拆分 str。
如果str具有连续的分隔符,并且它们之间没有其他字符,则strsplit将它们视为一个分隔符。例如,strsplit('Hello.world','.') 和 strsplit('Hello...world','.') 返回相同的输出。
delimiter:分隔字符,指定为字符向量、1×n的字符向量元胞数组或 1×n的字符串数组。在 delimiter 中指定的文本不会显示在输出 C 中。
在元胞数组或字符串数组中可以指定多个分隔符。strsplit函数根据delimiter的元素拆分 str。分隔符在 delimiter 中显示的顺序无关紧要,除非有多个分隔符都从str中的同一字符处开始匹配。在此种情况下,strsplit 将在delimiter中的第一个匹配分隔符处进行拆分。
通过上面的介绍可以看出,strsplit函数和strjoin函数的功能刚好相反,我们来看例子:

除此之外,MATLAB 允许通过名称-值参数来调整 strsplit函数的行为。
名称-值参数是一种在 MATLAB 内置函数中常见的可选参数形式,它提供了一种直观的方式来配置附加选项。这类参数一般成对出现,其中一个参数作为固定文本,定义了要设置或修改的选项,另一个参数则是该选项的具体值。名称-值参数必须位于其他参数之后,且它们的出现顺序并不影响函数的执行结果。
例如,在我们之前学习的 cellfun 函数中,'UniformOutput'是参数的名称,而true或false是它的值,用于指定函数返回结果的格式。同样的,在isstrprop函数中,'ForceCellOutput'是参数的名称,其值为true或false,用于控制函数返回元胞数组形式的结果。(后续章节要学的plot函数的名称-值参数非常多,大家可以提前查看它的帮助文档)
另外,从MATLAB2021a版本开始,可以将名称-值参数使用下面的形式表示:
Name1 = Value1, ..., NameN = ValueN,其中 Name 是参数名称,Value 是对应的值。
注意:为了保持代码的向下兼容性,即确保代码能在早期版本的MATLAB中正常运行,建议大家采用传统的表示方式:'Name1', Value1, ..., 'NameN', ValueN。另外,请将名称指定为单引号的字符向量形式,使用双引号形式的字符串可能会在低版本MATLAB中报错。
strsplit函数支持下面两对名称-值参数:
(1)CollapseDelimiters — 多分隔符处理,指定为true (默认值)或者 false
多分隔符处理,指定为由 'CollapseDelimiters' 和 true/false 组成的名称-值参数。如果为 true,则 str 中的连续分隔符将作为同一个分隔符处理。如果为 false,则连续分隔符将作为单独的分隔符处理,这会导致匹配的分隔符之间出现空字符向量 '' (0×0 char)元素。

(2)DelimiterType — 分隔符类型,指定为 'Simple' (默认)或者 'RegularExpression'
分隔符类型这对参数的名称为 'DelimiterType',它的值指定为下面两个字符向量之一:
- 'Simple': strsplit 函数将 delimiter 当作普通文本处理;
- 'RegularExpression': strsplit 函数将 delimiter 作为正则表达式处理。
注意,这里再次提到了正则表达式,相关内容我们会在下一章中介绍。借助正则表达式,可以大大拓展strsplit函数的应用场景。
对本小节的总结
在本节中,我们深入探讨了MATLAB中与文本处理相关的基础函数。这些函数为处理和分析各种文本数据提供了必要的工具,无论是简单的文本操作还是复杂的文本分析,它们都能胜任。
首先,我们介绍了 cellstr函数,它能将不同类型的文本数据转换成字符向量元胞数组,为后续的文本处理打下基础。
随后,我们探讨了 isletter和 isspace函数,这两个函数用于识别字母和空白字符,是文本分析中常用的工具。isstrprop函数作为它们的进阶版本,能够识别更多种类的字符,其灵活性和强大的识别能力使其成为MATLAB文本分析中的重要工具。
我们还学习了 strfind函数,它用于在文本中查找子文本并返回相应的索引,这对于定位特定信息非常重要。
紧接着,strrep函数和 replace函数则用于将文本中的旧文本替换为新文本,这对于编辑和更新文本数据非常有用。
在连接文本方面,strjoin函数可以将数组中的文本元素用特定的分隔符连接起来,为构建更加整洁和一致的文本提供了便利。
最后,我们讨论了 strsplit函数,它能够根据指定的分隔符将长文本拆分为更短的文本,这在处理大量文本数据时特别有用。
这些函数为我们处理各种文本格式提供了极大的灵活性。通过各种实例,我们看到了这些函数在实际应用中的强大功能。
在接下来的小节中,我们将重点介绍这些函数在综合应用中的实际案例,展示如何将这些独立的函数组合起来,解决更为复杂和实际的文本处理任务。这些综合应用案例不仅将巩固我们对于各个函数的理解,还将展示 MATLAB 在文本处理方面的卓越能力。

