
- 1Kotlin语法基础,包引入_kotlin 如何引入全包
- 2机器学习算法系列(五)-- 支持向量机(SVM)
- 3为何我们要用GPU,GPU云服务器到底有哪些好处?
- 4mongodb数据库条件操作符、排序及索引使用_mongodb sort
- 5数学学到顶尖到底如何颠覆世界,这15本书讲透了!
- 6iOS 常见 Crash 及解决方案_ios assertion failed:
- 7学习笔记(3):英特尔® OpenVINO™工具套件初级课程-为什么我们需要人工智能
- 8大学考试分数越高学分越多吗_为什么大学过得比高中还累?
- 9错误运行’JBoss 18.0.1′: 无法打开调试器端口 (127.0.0.1:57805): java.net.BindException “Address already in use: NET_无法打开调试端口
- 10android studio真机调试必要条件_android studio64运行条件
【RCNN系列】Faster RCNN论文总结及源码_faster-rcnn论文及其代码实现
赞
踩
目标检测论文总结
【RCNN系列】
RCNN
Fast RCNN
Faster RCNN
前言
一些经典论文的总结。
一、Pipeline
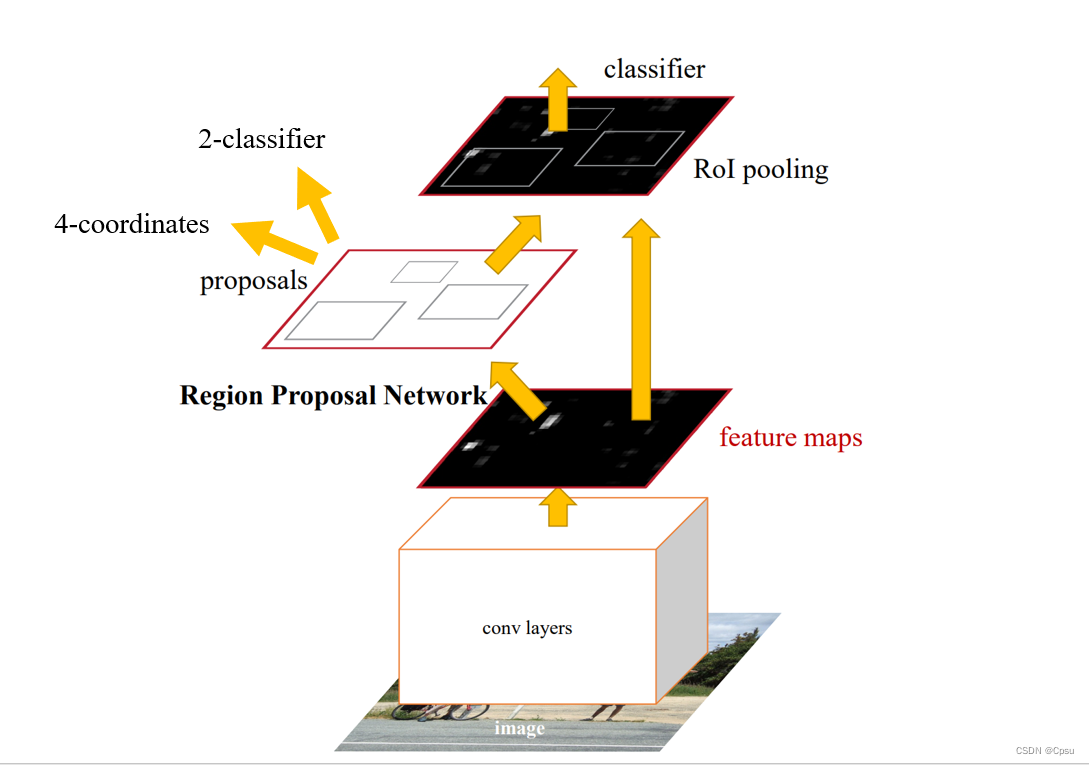
Faster RCNN其实是一个RPN+Fast RCNN,RPN和Fast RCNN是共享卷积层的。input image送入CNN(VGG、ZF)得到feature map,然后使用一个n*n(论文取3)的滑动窗口(其实是一个3*3卷积)来获取RoI(Region proposals),再送进2个head(一个head是二分类前景背景,一个head预测4个坐标值),把属于前景的RoI送入后面的网络,这就是RPN部分。Fast RCNN的卷积部分(conv layers)是和RPN的一样的,input image送入CNN(VGG、ZF)得到feature map,把RPN输出的属于前景的RoI映射到feature map上,跟之前的Fast RCNN一样经过一个RoI pooling layer后进行分类和框回归。
正是RPN网络替代了之前的RCNN系列的SS(selective search)算法来搜索RoI,大大加速了Fast RCNN的运行速度。
二、模型设计
1.RPNHead
理解RPN网络之前先来看一下RPNHead。
RPNHead的代码很简单,传入feature map,经过一个33的卷积,也就是论文中的n*n(n取3)的滑动窗口来选取proposals,并且33卷积以后shape是不变的(有padding)。随后接上两个1*1卷积,一个用来区分前景和背景,一个用来预测4个坐标的偏移。为什么是11卷积,首先11卷积可以起到降维的作用也就是降低通道数,也就是把in_channels(VGG为backbone则in_channels为512,ZF是256)的通道数降到num_anchors(论文取9),如下图,1*1卷积后得到是一个[C,H,W]的三维tensor,H,W是feature map的高宽,通道数C就是代码中的num_anchors也就是9。
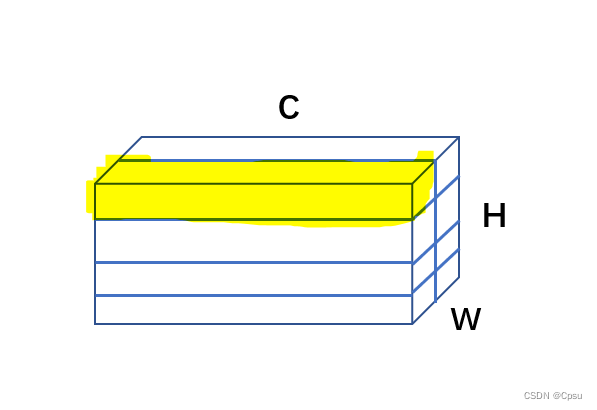
取出黄色标记的这一维向量,就是把9个通道取出来,这9个通道就代表9个anchor的objectness(属于前景背景的概率)。论文说的是用的是一个二分类,如果按照论文的写法应该是2x9=18也就是18个通道,同理18个通道对应每个anchor的objectness。在论文作者也说了可以用一个更很简单的逻辑回归来预测,以0.5为阈值,大于0.5属于前景否则就是背景。所以这就是为什么代码中是num_anchors而不是论文中的num_anchors*2。
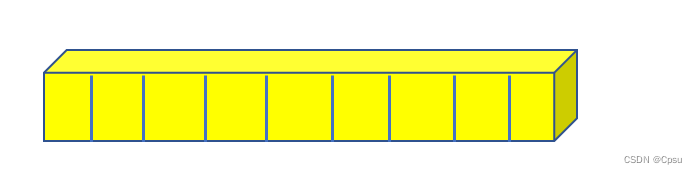

同理,预测坐标偏移的就应该是num_anchors*4即36个通道,代表每个anchor的4个坐标预测。
其实我感觉和YOLO的预测方法很类似,YOLO最后也是输出一个三维的Tensor,只不过YOLO是多类别预测,我认为YOLO完全可以看作是一个RPN或者是RPN的改进版(省略了Fast RCNN直接用RPN预测),他们的结构都很类似。
class RPNHead(nn.Module): """ add a RPN head with classification and regression 通过滑动窗口计算预测目标概率与bbox regression参数 Arguments: in_channels: number of channels of the input feature num_anchors: number of anchors to be predicted """ def __init__(self, in_channels, num_anchors): super(RPNHead, self).__init__() # 3x3 滑动窗口 # 卷积后大小不变 # bs*512*h*w self.conv = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1) # 计算预测的目标分数(这里的目标只是指前景或者背景) # 逻辑回归 以0.5为阈值 # bs*9*h*w # 特征图每个点都有9个anchor 也就是和yolo相似9个通道代表代表每个anchor的objectness self.cls_logits = nn.Conv2d(in_channels, num_anchors, kernel_size=1, stride=1) # 计算预测的目标bbox regression参数 # bs*36*h*w 代表9个anchor的坐标 self.bbox_pred = nn.Conv2d(in_channels, num_anchors * 4, kernel_size=1, stride=1) for layer in self.children(): if isinstance(layer, nn.Conv2d): torch.nn.init.normal_(layer.weight, std=0.01) torch.nn.init.constant_(layer.bias, 0) def forward(self, x): # type: (List[Tensor]) -> Tuple[List[Tensor], List[Tensor]] logits = [] bbox_reg = [] for i, feature in enumerate(x): t = F.relu(self.conv(feature)) logits.append(self.cls_logits(t)) bbox_reg.append(self.bbox_pred(t)) return logits, bbox_reg

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
2.Anchors
Faster RCNN的anchor有三种高宽比[0.5,1,2]。有三种面积大小[128*128,256*256,512*512]。
生成Anchor的步骤:
1.首先生成三种高宽比的anchors,这些anchors都是以(0,0)为中心,anchor的坐标用[x1,y1,x2,y2]表示,(x1,y1)表示左下角的坐标,(x2,y2)表示右上角的坐标。相当于在原点生成9个anchors。
2.根据特征图和原图之间的缩放比例,将以(0,0)为中心的这些anchor加上一个偏移平移到相应的位置,也就是把特征图上的每一个点映射到原图上,然后在原图上把这些anchor的位置标注出来。所以anchor是在原图上的,而不是在特征图上,特征图只是起一个承接作用。
class AnchorsGenerator(nn.Module): __annotations__ = { "cell_anchors": Optional[List[torch.Tensor]], "_cache": Dict[str, List[torch.Tensor]] } """ anchors生成器 Module that generates anchors for a set of feature maps and image sizes. The module support computing anchors at multiple sizes and aspect ratios per feature map. sizes and aspect_ratios should have the same number of elements, and it should correspond to the number of feature maps. sizes[i] and aspect_ratios[i] can have an arbitrary number of elements, and AnchorGenerator will output a set of sizes[i] * aspect_ratios[i] anchors per spatial location for feature map i. Arguments: sizes (Tuple[Tuple[int]]): aspect_ratios (Tuple[Tuple[float]]): """ # size=128,256,512每个不同大小的特征图的base anchor大小不一致 def __init__(self, sizes=(128, 256, 512), aspect_ratios=(0.5, 1.0, 2.0)): super(AnchorsGenerator, self).__init__() # 128*128 # 转换成((128,),(256,),(512,)) # 把每个元素都转换成tuple if not isinstance(sizes[0], (list, tuple)): # TODO change this sizes = tuple((s,) for s in sizes) # 把每个aspect_ratios转化成tuple # ((0.5, 1, 2), (0.5, 1, 2), (0.5, 1, 2)) # 每个tuple里面tuple长度和sizes长度一致 if not isinstance(aspect_ratios[0], (list, tuple)): # 9种anchor的比例 # 每个tuple里面tuple长度和sizes长度一致 aspect_ratios = (aspect_ratios,) * len(sizes) assert len(sizes) == len(aspect_ratios) self.sizes = sizes self.aspect_ratios = aspect_ratios self.cell_anchors = None # 私有变量 self._cache = {} def generate_anchors(self, scales, aspect_ratios, dtype=torch.float32, device=torch.device("cpu")): # type: (List[int], List[float], torch.dtype, torch.device) -> Tensor """ compute anchor sizes Arguments: # 即上文的sizes scales: sqrt(anchor_area) # anchor宽高比 aspect_ratios: h/w ratios dtype: float32 device: cpu/gpu """ # as_tensor浅拷贝 # shape [3,1] scales = torch.as_tensor(scales, dtype=dtype, device=device) # shape [3,1] aspect_ratios = torch.as_tensor(aspect_ratios, dtype=dtype, device=device) # 开根号 # h*w=h*h=ratios # 所以开根号 h_ratios = torch.sqrt(aspect_ratios) w_ratios = 1.0 / h_ratios # [r1, r2, r3]' * [s1, s2, s3] # number of elements is len(ratios)*len(scales) # w_ratios[:, None]注意这里是在中间插入一维数据[3,1,3] # scales[None, :]意这里是在中间插入一维数据[1,3,3] ws = (w_ratios[:, None] * scales[None, :]).view(-1) # torch.Size([3, 1, 3]) # torch.Size([1, 3, 1]) # 不看通道相当于1*3的矩阵和3*1的向量相乘 hs = (h_ratios[:, None] * scales[None, :]).view(-1) # left-bottom, right-top coordinate relative to anchor center(0, 0) # 生成的anchors模板都是以(0, 0)为中心的, shape [len(ratios)*len(scales), 4] base_anchors = torch.stack([-ws, -hs, ws, hs], dim=1) / 2 return base_anchors.round() # round 四舍五入 # 分组生成anchor模板 # output三组tensor 左下右上的格式 """ [tensor([[-91., -45., 91., 45.], # 128*128 [-64., -64., 64., 64.], # 256*256 [-45., -91., 45., 91.]]),# 512*512 tensor([[-181., -91., 181., 91.], [-128., -128., 128., 128.], [ -91., -181., 91., 181.]]), tensor([[-362., -181., 362., 181.], [-256., -256., 256., 256.], [-181., -362., 181., 362.]])] """ def set_cell_anchors(self, dtype, device): # type: (torch.dtype, torch.device) -> None # 如果传入anchor模板就不用生成了 if self.cell_anchors is not None: cell_anchors = self.cell_anchors assert cell_anchors is not None # suppose that all anchors have the same device # which is a valid assumption in the current state of the codebase if cell_anchors[0].device == device: return # 根据提供的sizes和aspect_ratios生成anchors模板 # anchors模板都是以(0, 0)为中心的anchor cell_anchors = [ self.generate_anchors(sizes, aspect_ratios, dtype, device) for sizes, aspect_ratios in zip(self.sizes, self.aspect_ratios) ] self.cell_anchors = cell_anchors # cell_anchor list类型 def num_anchors_per_location(self): # 计算每个预测特征层上每个滑动窗口的预测目标数 return [len(s) * len(a) for s, a in zip(self.sizes, self.aspect_ratios)] # [3,3,3] # For every combination of (a, (g, s), i) in (self.cell_anchors, zip(grid_sizes, strides), 0:2), # output g[i] anchors that are s[i] distance apart in direction i, with the same dimensions as a. def grid_anchors(self, grid_sizes, strides): # type: (List[List[int]], List[List[Tensor]]) -> List[Tensor] """ anchors position in grid coordinate axis map into origin image 计算预测特征图对应原始图像上的所有anchors的坐标 Args: grid_sizes: 预测特征矩阵的height和width strides: 预测特征矩阵上一步 对应 原始图像上的步距 # 比如VGG最后一层缩放了16倍 """ anchors = [] cell_anchors = self.cell_anchors assert cell_anchors is not None # 遍历每个预测特征层的grid_size,strides和cell_anchors for size, stride, base_anchors in zip(grid_sizes, strides, cell_anchors): grid_height, grid_width = size stride_height, stride_width = stride device = base_anchors.device # For output anchor, compute [x_center, y_center, x_center, y_center] # shape: [grid_width] 对应原图上的x坐标(列) # 特征图大小grid_width shifts_x = torch.arange(0, grid_width, dtype=torch.float32, device=device) * stride_width # shape: [grid_height] 对应原图上的y坐标(行) shifts_y = torch.arange(0, grid_height, dtype=torch.float32, device=device) * stride_height # 计算预测特征矩阵上每个点对应原图上的坐标(anchors模板的坐标偏移量) # torch.meshgrid函数分别传入行坐标和列坐标,生成网格行坐标矩阵和网格列坐标矩阵 # shape: [grid_height, grid_width] # 生成网格坐标 shift_y, shift_x = torch.meshgrid(shifts_y, shifts_x) shift_x = shift_x.reshape(-1) shift_y = shift_y.reshape(-1) # 计算anchors坐标(xmin, ymin, xmax, ymax)在原图上的坐标偏移量 # shape: [grid_width*grid_height, 4] # 给base anchor的左下和右上坐标同时加上shift,所以要写成如下形式 shifts = torch.stack([shift_x, shift_y, shift_x, shift_y], dim=1) # For every (base anchor, output anchor) pair, # offset each zero-centered base anchor by the center of the output anchor. # 将anchors模板与原图上的坐标偏移量相加得到原图上所有anchors的坐标信息(shape不同时会使用广播机制) # shifts.view(-1, 1, 4) shape [grid_width*grid_height,1,4] # base_anchors.view(1, -1, 4) shape [1,3,4] # base anchor的shape是[3,4] # [3,4]表示3个anchor的4个坐标左下右上 shifts_anchor = shifts.view(-1, 1, 4) + base_anchors.view(1, -1, 4) # shifts_anchor [12,3,4] anchors.append(shifts_anchor.reshape(-1, 4)) return anchors # List[Tensor(all_num_anchors, 4)] def cached_grid_anchors(self, grid_sizes, strides): # type: (List[List[int]], List[List[Tensor]]) -> List[Tensor] """将计算得到的所有anchors信息进行缓存""" key = str(grid_sizes) + str(strides) # self._cache是字典类型 if key in self._cache: return self._cache[key] anchors = self.grid_anchors(grid_sizes, strides) self._cache[key] = anchors return anchors def forward(self, image_list, feature_maps): # type: (ImageList, List[Tensor]) -> List[Tensor] # 获取每个预测特征层的尺寸(height, width) grid_sizes = list([feature_map.shape[-2:] for feature_map in feature_maps]) # 获取输入图像的height和width image_size = image_list.tensors.shape[-2:] # 获取变量类型和设备类型 dtype, device = feature_maps[0].dtype, feature_maps[0].device # one step in feature map equate n pixel stride in origin image # 计算特征层上的一步等于原始图像上的步长 # 缩放了多少倍 strides = [[torch.tensor(image_size[0] // g[0], dtype=torch.int64, device=device), torch.tensor(image_size[1] // g[1], dtype=torch.int64, device=device)] for g in grid_sizes] # 根据提供的sizes和aspect_ratios生成anchors模板 self.set_cell_anchors(dtype, device) # 计算/读取所有anchors的坐标信息(这里的anchors信息是映射到原图上的所有anchors信息,不是anchors模板) # 得到的是一个list列表,对应每张预测特征图映射回原图的anchors坐标信息 anchors_over_all_feature_maps = self.cached_grid_anchors(grid_sizes, strides) anchors = torch.jit.annotate(List[List[torch.Tensor]], []) # 遍历一个batch中的每张图像 for i, (image_height, image_width) in enumerate(image_list.image_sizes): anchors_in_image = [] # 遍历每张预测特征图映射回原图的anchors坐标信息 for anchors_per_feature_map in anchors_over_all_feature_maps: anchors_in_image.append(anchors_per_feature_map) anchors.append(anchors_in_image) # 将每一张图像的所有预测特征层的anchors坐标信息拼接在一起 # anchors是个list,每个元素为一张图像的所有anchors信息 anchors = [torch.cat(anchors_per_image) for anchors_per_image in anchors] # Clear the cache in case that memory leaks. self._cache.clear() return anchors
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
3.RPN(Region Proposal Networks)
从foward可以看出RPN的流程:
1.从卷积网络中获取feature map,由于这里使用了FPN也就是多尺度特征图来更好的检测小目标,所以会传入卷积网络中的多个大小不同的feature map。
2.将feature map传入RPNHead,利用RPNhead进行坐标预测偏移和类别预测(前景和背景)。
3.生成Anchors,并加上RPNHead计算出来的偏移量得到预测的Anchor坐标。
4.filter_proposals即过滤目标区域,用NMS算法来消除冗余的proposals。具体来说:
- 首先根据置信度(前景得分)对同一level特征图产生的proposals进行降序排序(如果引入FPN,不同level特征图产生的proposals之间独立),最多选择前pre_nms_topn(人为设定)个。
- 然后对超出图片范围的proposal进行clip剪裁,有的anchor都超出原图大小。
- 去除面积太小的proposals
- 进行nms操作,注意这里在不同level的feature_map上产生的proposal,它们之间独立地进行nms操作。
- 最后对nms的结果根据置信度进行降序排序,最多返回前post_nms_topn个proposals,若nms后bbox数量小于post_nms_topn,全部都送入roi_head层。
RPN的设计最好读一下源码,下面是来自Pytorch官方代码,其中RPN的代码及自己的注释:
class RegionProposalNetwork(torch.nn.Module): """ Implements Region Proposal Network (RPN). Arguments: anchor_generator (AnchorGenerator): module that generates the anchors for a set of feature maps. # RPNhead head (nn.Module): module that computes the objectness and regression deltas # 确定为正样本的IoU阈值 论文为0.7 fg_iou_thresh (float): minimum IoU between the anchor and the GT box so that they can be considered as positive during training of the RPN. # 确定为负样本的IoU阈值 论文为0.3 bg_iou_thresh (float): maximum IoU between the anchor and the GT box so that they can be considered as negative during training of the RPN. # batch_size的大小 论文是256 正负样本1:1 batch_size_per_image (int): number of anchors that are sampled during training of the RPN for computing the loss # minibatch中正负样本的比例 论文为1:1 positive_fraction (float): proportion of positive anchors in a mini-batch during training of the RPN # 按分类得分降序保留前pre_nms_top_n个proposals, 训练是2000和预测1000 pre_nms_top_n (Dict[str]): number of proposals to keep before applying NMS. It should contain two fields: training and testing, to allow for different values depending on training or evaluation # 返回NMS后的前post_nms_top_n个proposals, 训练是2000和预测1000 post_nms_top_n (Dict[str]): number of proposals to keep after applying NMS. It should contain two fields: training and testing, to allow for different values depending on training or evaluation # NMS阈值 0.7 nms_thresh (float): NMS threshold used for postprocessing the RPN proposals """ __annotations__ = { 'box_coder': det_utils.BoxCoder, 'proposal_matcher': det_utils.Matcher, 'fg_bg_sampler': det_utils.BalancedPositiveNegativeSampler, 'pre_nms_top_n': Dict[str, int], 'post_nms_top_n': Dict[str, int], } def __init__(self, anchor_generator, head, fg_iou_thresh, bg_iou_thresh, batch_size_per_image, positive_fraction, pre_nms_top_n, post_nms_top_n, nms_thresh, score_thresh=0.0): super(RegionProposalNetwork, self).__init__() self.anchor_generator = anchor_generator self.head = head self.box_coder = det_utils.BoxCoder(weights=(1.0, 1.0, 1.0, 1.0)) # use during training # 计算anchors与真实bbox的iou self.box_similarity = box_ops.box_iou self.proposal_matcher = det_utils.Matcher( fg_iou_thresh, # 当iou大于fg_iou_thresh(0.7)时视为正样本即前景 bg_iou_thresh, # 当iou小于bg_iou_thresh(0.3)时视为负样本即背景 allow_low_quality_matches=True ) self.fg_bg_sampler = det_utils.BalancedPositiveNegativeSampler( batch_size_per_image, positive_fraction # 256, 0.5 ) # use during testing self._pre_nms_top_n = pre_nms_top_n self._post_nms_top_n = post_nms_top_n self.nms_thresh = nms_thresh self.score_thresh = score_thresh self.min_size = 1. def pre_nms_top_n(self): if self.training: return self._pre_nms_top_n['training'] return self._pre_nms_top_n['testing'] def post_nms_top_n(self): if self.training: return self._post_nms_top_n['training'] return self._post_nms_top_n['testing'] def assign_targets_to_anchors(self, anchors, targets): # type: (List[Tensor], List[Dict[str, Tensor]]) -> Tuple[List[Tensor], List[Tensor]] """ 计算每个anchors最匹配的gt,并划分为正样本,背景以及废弃的样本 Args: anchors: (List[Tensor]) targets: (List[Dict[Tensor]) Returns: labels: 标记anchors归属类别(1, 0, -1分别对应正样本,背景,废弃的样本) 注意,在RPN中只有前景和背景,所有正样本的类别都是1,0代表背景 matched_gt_boxes:与anchors匹配的gt """ labels = [] matched_gt_boxes = [] # 遍历每张图像的anchors和targets for anchors_per_image, targets_per_image in zip(anchors, targets): # 获取GT的信息/取出GTbox对应的值 gt_boxes = targets_per_image["boxes"] # 判断元素个数 if gt_boxes.numel() == 0: device = anchors_per_image.device # 感觉可以替换为zeros_like # 没有目标全0 matched_gt_boxes_per_image = torch.zeros(anchors_per_image.shape, dtype=torch.float32, device=device) labels_per_image = torch.zeros((anchors_per_image.shape[0],), dtype=torch.float32, device=device) else: # 计算anchors与真实bbox的iou信息 # set to self.box_similarity when https://github.com/pytorch/pytorch/issues/27495 lands match_quality_matrix = box_ops.box_iou(gt_boxes, anchors_per_image) # 计算每个anchors与gt匹配iou最大的索引(如果iou<0.3索引置为-1,0.3<iou<0.7索引为-2) matched_idxs = self.proposal_matcher(match_quality_matrix) # get the targets corresponding GT for each proposal # NB: need to clamp the indices because we can have a single # GT in the image, and matched_idxs can be -2, which goes # out of bounds # 这里使用clamp设置下限0是为了方便取每个anchors对应的gt_boxes信息 # 负样本和舍弃的样本都是负值,所以为了防止越界直接置为0 # 因为后面是通过labels_per_image变量来记录正样本位置的, # 所以负样本和舍弃的样本对应的gt_boxes信息并没有什么意义, # 反正计算目标边界框回归损失时只会用到正样本。 # 相当于把小于0的都设置为0 因为只需要把正样本取出来 其他样本无所谓不用区分 matched_gt_boxes_per_image = gt_boxes[matched_idxs.clamp(min=0)] # 记录所有anchors匹配后的标签(正样本处标记为1,负样本处标记为0,丢弃样本处标记为-2) labels_per_image = matched_idxs >= 0 labels_per_image = labels_per_image.to(dtype=torch.float32) # background (negative examples) bg_indices = matched_idxs == self.proposal_matcher.BELOW_LOW_THRESHOLD # -1 labels_per_image[bg_indices] = 0.0 # discard indices that are between thresholds inds_to_discard = matched_idxs == self.proposal_matcher.BETWEEN_THRESHOLDS # -2 labels_per_image[inds_to_discard] = -1.0 labels.append(labels_per_image) matched_gt_boxes.append(matched_gt_boxes_per_image) return labels, matched_gt_boxes # 返回标签和匹配的GTbox def _get_top_n_idx(self, objectness, num_anchors_per_level): # type: (Tensor, List[int]) -> Tensor """ 获取每张预测特征图上预测概率排前pre_nms_top_n的anchors索引值 Args: objectness: Tensor(每张图像的预测目标概率信息 ) num_anchors_per_level: List(每个预测特征层上的预测的anchors个数) Returns: """ r = [] # 记录每个预测特征层上预测目标概率前pre_nms_top_n的索引信息 offset = 0 # 遍历每个预测特征层上的预测目标概率信息 for ob in objectness.split(num_anchors_per_level, 1): if torchvision._is_tracing(): num_anchors, pre_nms_top_n = _onnx_get_num_anchors_and_pre_nms_top_n(ob, self.pre_nms_top_n()) else: num_anchors = ob.shape[1] # 预测特征层上的预测的anchors个数 pre_nms_top_n = min(self.pre_nms_top_n(), num_anchors) # Returns the k largest elements of the given input tensor along a given dimension _, top_n_idx = ob.topk(pre_nms_top_n, dim=1) r.append(top_n_idx + offset) offset += num_anchors return torch.cat(r, dim=1) def filter_proposals(self, proposals, objectness, image_shapes, num_anchors_per_level): # type: (Tensor, Tensor, List[Tuple[int, int]], List[int]) -> Tuple[List[Tensor], List[Tensor]] """ 筛除小boxes框,nms处理,根据预测概率获取前post_nms_top_n个目标 Args: proposals: 预测的bbox坐标 objectness: 预测的目标概率 image_shapes: batch中每张图片的size信息 num_anchors_per_level: 每个预测特征层上预测anchors的数目 Returns: """ num_images = proposals.shape[0] device = proposals.device # do not backprop throught objectness objectness = objectness.detach() objectness = objectness.reshape(num_images, -1) # Returns a tensor of size size filled with fill_value # levels负责记录分隔不同预测特征层上的anchors索引信息 levels = [torch.full((n, ), idx, dtype=torch.int64, device=device) for idx, n in enumerate(num_anchors_per_level)] levels = torch.cat(levels, 0) # Expand this tensor to the same size as objectness levels = levels.reshape(1, -1).expand_as(objectness) # select top_n boxes independently per level before applying nms # 获取每张预测特征图上预测概率排前pre_nms_top_n的anchors索引值 top_n_idx = self._get_top_n_idx(objectness, num_anchors_per_level) image_range = torch.arange(num_images, device=device) batch_idx = image_range[:, None] # [batch_size, 1] # 根据每个预测特征层预测概率排前pre_nms_top_n的anchors索引值获取相应概率信息 objectness = objectness[batch_idx, top_n_idx] levels = levels[batch_idx, top_n_idx] # 预测概率排前pre_nms_top_n的anchors索引值获取相应bbox坐标信息 proposals = proposals[batch_idx, top_n_idx] objectness_prob = torch.sigmoid(objectness) final_boxes = [] final_scores = [] # 遍历每张图像的相关预测信息 for boxes, scores, lvl, img_shape in zip(proposals, objectness_prob, levels, image_shapes): # 调整预测的boxes信息,将越界的坐标调整到图片边界上 boxes = box_ops.clip_boxes_to_image(boxes, img_shape) # 返回boxes满足宽,高都大于min_size的索引 keep = box_ops.remove_small_boxes(boxes, self.min_size) boxes, scores, lvl = boxes[keep], scores[keep], lvl[keep] # 移除小概率boxes,参考下面这个链接 # https://github.com/pytorch/vision/pull/3205 keep = torch.where(torch.ge(scores, self.score_thresh))[0] # ge: >= boxes, scores, lvl = boxes[keep], scores[keep], lvl[keep] # non-maximum suppression, independently done per level # 每个特征层单独NMS keep = box_ops.batched_nms(boxes, scores, lvl, self.nms_thresh) # keep only topk scoring predictions # 调用post_nms_top_n方法 keep = keep[: self.post_nms_top_n()] boxes, scores = boxes[keep], scores[keep] final_boxes.append(boxes) final_scores.append(scores) return final_boxes, final_scores def compute_loss(self, objectness, pred_bbox_deltas, labels, regression_targets): # type: (Tensor, Tensor, List[Tensor], List[Tensor]) -> Tuple[Tensor, Tensor] """ 计算RPN损失,包括类别损失(前景与背景),bbox regression损失 Arguments: objectness (Tensor):预测的前景概率 pred_bbox_deltas (Tensor):预测的bbox regression labels (List[Tensor]):真实的标签 1, 0, -1(batch中每一张图片的labels对应List的一个元素中) regression_targets (List[Tensor]):真实的bbox regression Returns: objectness_loss (Tensor) : 类别损失 box_loss (Tensor):边界框回归损失 """ # 按照给定的batch_size_per_image, positive_fraction选择正负样本 sampled_pos_inds, sampled_neg_inds = self.fg_bg_sampler(labels) # 将一个batch中的所有正负样本List(Tensor)分别拼接在一起,并获取非零位置的索引 # sampled_pos_inds = torch.nonzero(torch.cat(sampled_pos_inds, dim=0)).squeeze(1) sampled_pos_inds = torch.where(torch.cat(sampled_pos_inds, dim=0))[0] # sampled_neg_inds = torch.nonzero(torch.cat(sampled_neg_inds, dim=0)).squeeze(1) sampled_neg_inds = torch.where(torch.cat(sampled_neg_inds, dim=0))[0] # 将所有正负样本索引拼接在一起 sampled_inds = torch.cat([sampled_pos_inds, sampled_neg_inds], dim=0) objectness = objectness.flatten() labels = torch.cat(labels, dim=0) regression_targets = torch.cat(regression_targets, dim=0) # 计算边界框回归损失 box_loss = det_utils.smooth_l1_loss( pred_bbox_deltas[sampled_pos_inds], regression_targets[sampled_pos_inds], beta=1 / 9, size_average=False, ) / (sampled_inds.numel()) # 计算目标预测概率损失 objectness_loss = F.binary_cross_entropy_with_logits( objectness[sampled_inds], labels[sampled_inds] ) return objectness_loss, box_loss def forward(self, images, # type: ImageList features, # type: Dict[str, Tensor] targets=None # type: Optional[List[Dict[str, Tensor]]] ): # type: (...) -> Tuple[List[Tensor], Dict[str, Tensor]] """ Arguments: images (ImageList): images for which we want to compute the predictions features (Dict[Tensor]): features computed from the images that are used for computing the predictions. Each tensor in the list correspond to different feature levels targets (List[Dict[Tensor]): ground-truth boxes present in the image (optional). If provided, each element in the dict should contain a field `boxes`, with the locations of the ground-truth boxes. Returns: boxes (List[Tensor]): the predicted boxes from the RPN, one Tensor per image. losses (Dict[Tensor]): the losses for the model during training. During testing, it is an empty dict. """ # RPN uses all feature maps that are available # features是所有预测特征层组成的OrderedDict features = list(features.values()) # 计算每个预测特征层上的预测目标概率和bboxes regression参数 # objectness和pred_bbox_deltas都是list # objectness, pred_bbox_deltas的元素都是tensor objectness, pred_bbox_deltas = self.head(features) # 生成一个batch图像的所有anchors信息,list(tensor)元素个数等于batch_size anchors = self.anchor_generator(images, features) # batch_size num_images = len(anchors) # numel() Returns the total number of elements in the input tensor. # 计算每个预测特征层上的对应的anchors数量 num_anchors_per_level_shape_tensors = [o[0].shape for o in objectness] num_anchors_per_level = [s[0] * s[1] * s[2] for s in num_anchors_per_level_shape_tensors] # 调整内部tensor格式以及shape objectness, pred_bbox_deltas = concat_box_prediction_layers(objectness, pred_bbox_deltas) # apply pred_bbox_deltas to anchors to obtain the decoded proposals # note that we detach the deltas because Faster R-CNN do not backprop through # the proposals # 将预测的bbox regression参数应用到anchors上得到最终预测bbox坐标 proposals = self.box_coder.decode(pred_bbox_deltas.detach(), anchors) proposals = proposals.view(num_images, -1, 4) # 筛除小boxes框,nms处理,根据预测概率获取前post_nms_top_n个目标 boxes, scores = self.filter_proposals(proposals, objectness, images.image_sizes, num_anchors_per_level) losses = {} if self.training: assert targets is not None # 计算每个anchors最匹配的gt,并将anchors进行分类,前景,背景以及废弃的anchors labels, matched_gt_boxes = self.assign_targets_to_anchors(anchors, targets) # 结合anchors以及对应的gt,计算regression参数 regression_targets = self.box_coder.encode(matched_gt_boxes, anchors) loss_objectness, loss_rpn_box_reg = self.compute_loss( objectness, pred_bbox_deltas, labels, regression_targets ) losses = { "loss_objectness": loss_objectness, "loss_rpn_box_reg": loss_rpn_box_reg } return boxes, losses
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
4.RPN正负样本划分阈值
一个用来识别正样本(如跟ground truth的IoU大于0.7或者与GT有最大IoU的anchor这种情况是为了防止没有大于0.7的anchor),另一个用来标记负样本(即背景类,如果和任何一个GT的IoU都小于0.3),而介于两者之间的则为难例(Hard Negatives),若标为正类,则包含了过多的背景信息,反之又包含了要检测物体的特征,对训练没有任何帮助,因而这些Proposal便被忽略掉既不是正样本也不是负样本。
每一个anchor都找一个与之iou最大的gt。若max_iou>0.7,则该anchor的label为1,即认定该anchor是目标;若max_iou<0.3,则该anchor的label为0,即认定该anchor为背景;若max_iou介于0.3和0.7之间,则忽视该anchor,不纳入损失函数。
还有一个特殊情况,可能有一个gt没有与之匹配的anchor,即该groud-truth和所有的bbox的iou都小于0.7,那么我们允许“与这个gt最大iou的bbox”被认为是正样本,确保每个gt都有配对的bbox
Faster RCNN的损失函数和Fast RCNN的没什么太大的变化。
5.训练策略
RPN是一个单独的网络结构,是可以进行单独训练的。在训练时,每个batch有256个anchor,其中正负样本的比例是1:1
Fast RCNN部分的正负样本划分和之前一样。
Faster RCNN采用了四步交替训练。在本文中,我们采用一种实用的共享学习四步训练算法通过交替优化的功能。
第一步,对RPN进行单独训练,卷积网络由预先训练的ImageNet初始化模型进行微调,用来生成proposals。
第二步,我们使用RPN生成的这些proposals训练Fast RCNN。卷积网络也是由预先训练的ImageNet初始化模型进行微调,但这时两个网络不共享卷积层也就是两个不同的微调backbone。
第三步,使用第二步Fast RCNN的卷积网络来做backbone,训练RPN,这时仅微调RPN特有的层(除了CNN的部分),现在两个网络共享卷积层,也就是用同一个backbone。
第四步,使用第三步训练好的RPN生成proposals,送入Fast RCNN,但同样共享卷积层,只微调Fast RCNN的特有层(RoI pooling及之后的层)。
循环四个步骤
三、总结
Faster RCNN解决了区域搜素的问题,使用RPN替代了SS算法,检测速度进一步加快。
RCNN系列的改进思路都很明确,也很好理解:
RCNN:初代两阶段检测网络
Fast RCNN:改进pipeline并且改进每个proposals都送入卷积网络的缺点
Faster RCNN:RPN+Fast RCNN提出RPN

