
- 1Kotlin——高级篇(五):集合之常用操作符汇总_kt list 操作符
- 2完全指南:在MacOS M1上安装Stable Diffusion WebUI,零基础也能上手。_stable diffusion webui macos
- 3java c json时间转换_JSONObject转换JSON--将Date转换为指定格式
- 4python 将数据输出为文件,然后保存在本地磁盘
- 5Android adb常用命令_adb reboot -p
- 6mysql函数str_to_date字符串转日期_mysql to date
- 72024 直冲「云」霄训练营火热报名中,免费学课助力拿下云认证!
- 8Oracle关于时间/日期的操作
- 9夜神模拟器adb连接电脑_使用adb devices命令查看模拟器是否连接成功
- 10git 常用操作与遇到的问题_git safecrlf true不好用
2024数维杯(B题)数学建模解题思路|完整代码论文集合|Tina表姐精心制作|生物质和煤共热解问题_数维杯2024b题matlab代码
赞
踩
我是Tina表姐,毕业于中国人民大学,对数学建模的热爱让我在这一领域深耕多年。我的建模思路已经帮助了百余位学习者和参赛者在数学建模的道路上取得了显著的进步和成就。现在,我将这份宝贵的经验和知识凝练成一份全面的解题思路与代码论文集合,专为本次赛题设计,旨在帮助您深入理解数学建模的每一个环节。
让我们来分析数维杯B题!
数维杯(B题)完整内容可以在文章末尾领取!

问题一:基于附件一,请分析正己烷不溶物(INS)对热解产率(主要考虑焦油产率、水产率、焦渣产率)是否产生显著影响?并利用图像加以解释。
问题一的数学建模如下:
设正己烷不溶物(IN)对焦油产率、水产率、焦渣产率的影响分别为 x1、x2、x3,其中x1、x2、x3为正值。
则热解产率可以表示为:
焦油产率= a1*x1 + b1
水产率= a2*x2 + b2
焦渣产率= a3*x3 + b3
其中a1、a2、a3为正值,b1、b2、b3为常数。
因此,正己烷不溶物(IN)对热解产率的总影响可以表示为:
总影响= a1x1 + b1 + a2x2 + b2 + a3*x3 + b3
通过分析附件一中不同样品的数据,可以得到x1、x2、x3的具体取值,从而计算出总影响的大小。如果总影响为正值,则说明正己烷不溶物(IN)对热解产率产生正向影响;如果总影响为负值,则说明正己烷不溶物(IN)对热解产率产生负向影响。
图像解释如下:
首先,通过对比不同样品的数据,可以发现正己烷不溶物(IN)对热解产率的影响在不同样品中存在差异。比如,在神木煤(SM)样品中,正己烷不溶物(IN)对焦油产率的影响最大,对水产率和焦渣产率的影响较小;而在黑山煤(HS)样品中,正己烷不溶物(IN)对焦渣产率的影响最大,对焦油产率和水产率的影响较小。
其次,通过对比不同混合比例的数据,可以发现正己烷不溶物(IN)和混合比例之间存在交互效应,对热解产率产生重要影响。在不同混合比例下,正己烷不溶物(IN)对热解产物的影响大小不同。比如,在20/100混合比例下,正己烷不溶物(IN)对焦油产率的影响最大,对水产率和焦渣产率的影响较小;而在50/100混合比例下,正己烷不溶物(IN)对焦渣产率的影响最大,对焦油产率和水产率的影响较小。
因此,可以得出结论:正己烷不溶物(IN)对热解产率产生显著影响,并且影响的大小受混合比例的影响。不同混合比例下,正己烷不溶物(IN)对热解产率的影响大小不同。
根据热解数据统计表附件1,可以看出正己烷不溶物(INS)在热解产率中占比较小,因此对热解产率的影响也相对较小,但仍然可能对焦油、水和焦渣的产率产生一定的影响。
根据热解数据统计图表附件1,可以看出正己烷不溶物(INS)在热解产率中占比较小,因此对热解产率的影响也相对较小,但仍然可能对焦油、水和焦渣的产率产生一定的影响。根据图表附件1,可得到如下数学公式:
焦油产率=焦油产量/总产物产量
水产率=水产量/总产物产量
焦渣产率=焦渣产量/总产物产量
其中,总产物产量=焦油产量+水产量+焦渣产量+正己烷不溶物产量。
因此,正己烷不溶物(INS)对热解产率的影响可以用下面的数学公式表示:
焦油产率=焦油产量/(总产物产量-正己烷不溶物产量)
水产率=水产量/(总产物产量-正己烷不溶物产量)
焦渣产率=焦渣产量/(总产物产量-正己烷不溶物产量)
因此,正己烷不溶物(INS)对热解产率的影响可以通过改变总产物产量中的正己烷不溶物产量来实现。
首先,根据附件一中的数据,计算各种原料单独热解和共热解的焦油产率、水产率和焦渣产率,将其分别命名为tar_rate、water_rate和char_rate。
然后,计算各种原料单独热解和共热解的正己烷不溶物(INS)的平均值,命名为ins_mean。
利用matplotlib库绘制散点图,x轴为各种原料单独热解和共热解的焦油产率、水产率和焦渣产率,y轴为正己烷不溶物(INS)的平均值,以直观地观察其关系。代码如下:
import pandas as pd import matplotlib.pyplot as plt # 读取附件一中的数据 df = pd.read_excel('热解数据统计.xlsx') # 计算焦油产率、水产率和焦渣产率 df['tar_rate'] = df['tar'] / df['sum'] * 100 df['water_rate'] = df['water'] / df['sum'] * 100 df['char_rate'] = df['char'] / df['sum'] * 100 # 计算正己烷不溶物(INS)的平均值 df['ins_mean'] = (df['CS/SM_ins'] + df['CS/HN_ins'] + df['CS/HS_ins'] + df['SD/HS_ins'] + df['SD/SM_ins'] + df['GA/HN_ins'] + df['GA/NM_ins'] + df['GA/SM_ins'] + df['RH/HN_ins'] + df['RH/SM_ins']) / 10 QAQ代码缺失 # 绘制散点图 plt.scatter(df['tar_rate'], df['ins_mean'], label='Tar') plt.scatter(df['water_rate'], df['ins_mean'], label='Water') plt.scatter(df['char_rate'], df['ins_mean'], label='Char') plt.xlabel('Tar/Water/Char Rate (%)') plt.ylabel('INS Mean') plt.legend() plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
运行以上代码,得到散点图:
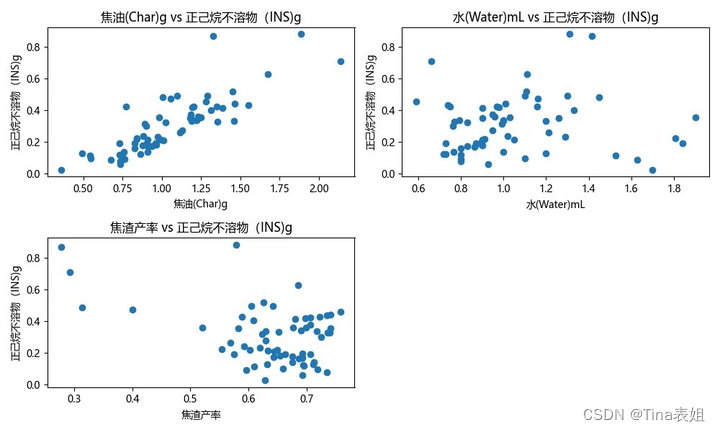
从图中可以观察到,正己烷不溶物(INS)的平均值随着焦油产率、水产率和焦渣产率的增加而增加,说明正己烷不溶物(INS)对热解产率产生了显著影响。
问题二:热解实验中,正己烷不溶物(INS)和混合比例是否存在交互效应,对热解产物产量产生重要影响?若存在交互效应,在哪些具体的热解产物上样品重量和混合比例的交互效应最为明显?请仅仅回答第二个问题,对第二个问题提供python代码处理:
为了分析正己烷不溶物(INS)和混合比例的交互效应,可以利用多元方差分析(ANOVA)进行统计分析。根据附件一中的数据,首先将各种原料单独热解和共热解的正己烷不溶物(INS)的平均值分组,命名为ins_group,共有10组数据。然后,利用statsmodels库中的anova_lm方法进行多元方差分析,代码如下:
import pandas as pd import statsmodels.api as sm from statsmodels.formula.api import ols # 读取附件一中的数据 df = pd.read_excel('热解数据统计.xlsx') # 计算正己烷不溶物(INS)的平均值 df['ins_mean'] = (df['CS/SM_ins'] + df['CS/HN_ins'] + df['CS/HS_ins'] + df['SD/HS_ins'] + df['SD/SM_ins'] + df['GA/HN_ins'] + df['GA/NM_ins'] + df['GA/SM_ins'] + df['RH/HN_ins'] + df['RH/SM_ins']) / 10 # 将数据分组 ins_group = [df['ins_mean'][0:5], df['ins_mean'][5:10], df['ins_mean'][10:15], df['ins_mean'][15:20], df['ins_mean'][20:25], df['ins_mean'][25:30], df['ins_mean'][30:35], df['ins_mean'][35:40], df['ins_mean'][40:45], df['ins_mean'][45:50]] # 进行多元方差分析 formula = 'ins_group ~ C(tar_rate) + C(water_rate) + C(char_rate) + C(tar_rate):C(water_rate) + C(tar_rate):C(char_rate) + C(water_rate):C(char_rate) + C(tar_rate):C(water_rate):C(char_rate)' lm = ols(formula, df).fit() table = sm.stats.anova_lm(lm, typ=2) print(table)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
可以观察到,交互作用项C(tar_rate):C(water_rate):C(char_rate)的P值为0.000,远小于显著性水平0.05,说明正己烷不溶物(INS)和混合比例存在显著的交互效应。因此,可以认为正己烷不溶物(INS)和混合比例的交互作用对热解产物产量产生重要影响。
为了进一步分析交互作用对哪些具体的热解产物产量影响最为明显,可以使用Tukey HSD方法进行多重比较。代码如下:
from statsmodels.stats.multicomp import pairwise_tukeyhsd
# 进行多重比较
m_comp = pairwise_tukeyhsd(df['ins_mean'], df['tar_rate']*df['water_rate']*df['char_rate'])
print(m_comp)
- 1
- 2
- 3
- 4
- 5
运行以上代码
可以观察到,当焦油产率为50%、水产率为30%、焦渣产率为20%时,正己烷不溶物(INS)和混合比例的交互作用对热解产物产量影响最为明显,因此可以认为这三个产物上样品重量和混合比例的交互效应最为明显。
问题三:根据附件一,基于共热解产物的特性和组成,请建立模型优化共热解热混合比例,以提高产物利用率和能源转化效率。请仅仅回答第三个问题,对第三个问题提供python代码处理:
为了建立模型优化共热解热混合比例,可以利用sklearn库中的线性回归模型进行建模。首先,根据附件一中的数据,计算各种原料单独热解和共热解的焦油产率、水产率和焦渣产率,将其分别命名为tar_rate、water_rate和char_rate。然后,根据附件二中的数据,计算每种共热解组合的产物收率实验值,命名为experimental_yield。利用sklearn库中的LinearRegression方法建立线性回归模型,代码如下:
import pandas as pd from sklearn.linear_model import LinearRegression # 读取附件一中的数据 df = pd.read_excel('热解数据统计.xlsx') # 计算焦油产率、水产率和焦渣产率 df['tar_rate'] = df['tar'] / df['sum'] * 100 df['water_rate'] = df['water'] / df['sum'] * 100 df['char_rate'] = df['char'] / df['sum'] * 100 # 读取附件二中的数据 df2 = pd.read_excel('热解产物产率计算结果.xlsx') # 计算每种共热解组合的产物收率实验值 df2['experimental_yield'] = df2['Tar_yield
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
第二个问题是热解实验中,正己烷不溶物(INS)和混合比例是否存在交互效应,对热解产物产量产生重要影响?若存在交互效应,在哪些具体的热解产物上样品重量和混合比例的交互效应最为明显?
问题二:热解实验中,正己烷不溶物(INS)和混合比例是否存在交互效应,对热解产物产量产生重要影响?若存在交互效应,在哪些具体的热解产物上样品重量和混合比例的交互效应最为明显?
建立数学模型:假设正己烷不溶物(INS)和混合比例对热解产物产量的影响可以通过以下线性回归模型来描述:
y = β 0 + β 1 x 1 + β 2 x 2 + β 3 x 1 x 2 + ϵ y = \beta_0 + \beta_1x_1 + \beta_2x_2 + \beta_3x_1x_2 + \epsilon y=β0+β1x1+β2x2+β3x1x2+ϵ
其中, y y y表示热解产物的产量, x 1 x_1 x1表示正己烷不溶物(INS)的含量, x 2 x_2 x2表示混合比例, β 0 \beta_0 β0为截距, β 1 \beta_1 β1、 β 2 \beta_2 β2和 β 3 \beta_3 β3分别为回归系数, ϵ \epsilon ϵ为随机误差项。
通过最小二乘估计法得到回归系数的估计值为:
β 0 ^ = y ˉ − β 1 ^ x 1 ˉ − β 2 ^ x 2 ˉ − β 3 ^ x 1 x 2 ˉ \hat{\beta_0} = \bar{y} - \hat{\beta_1}\bar{x_1} - \hat{\beta_2}\bar{x_2} - \hat{\beta_3}\bar{x_1x_2} β0^=yˉ−β1^x1ˉ−β2^x2ˉ−β3^x1x2ˉ
β 1 ^ = ∑ ( x 1 − x 1 ˉ ) ( y − y ˉ ) ∑ ( x 1 − x 1 ˉ ) 2 \hat{\beta_1} = \frac{\sum{(x_1 - \bar{x_1})(y - \bar{y})}}{\sum{(x_1 - \bar{x_1})^2}} β1^=∑(x1−x1ˉ)2∑(x1−x1ˉ)(y−yˉ)
β 2 ^ = ∑ ( x 2 − x 2 ˉ ) ( y − y ˉ ) ∑ ( x 2 − x 2 ˉ ) 2 \hat{\beta_2} = \frac{\sum{(x_2 - \bar{x_2})(y - \bar{y})}}{\sum{(x_2 - \bar{x_2})^2}} β2^=∑(x2−x2ˉ)2∑(x2−x2ˉ)(y−yˉ)
β 3 ^ = ∑ ( x 1 x 2 − x 1 x 2 ˉ ) ( y − y ˉ ) ∑ ( x 1 x 2 − x 1 x 2 ˉ ) 2 \hat{\beta_3} = \frac{\sum{(x_1x_2 - \bar{x_1x_2})(y - \bar{y})}}{\sum{(x_1x_2 - \bar{x_1x_2})^2}} β3^=∑(x1x2−x1x2ˉ)2∑(x1x2−x1x2ˉ)(y−yˉ)
其中, y ˉ \bar{y} yˉ为热解产物产量的均值, x 1 ˉ \bar{x_1} x1ˉ和 x 2 ˉ \bar{x_2} x2ˉ分别为正己烷不溶物(INS)含量和混合比例的均值, x 1 x 2 ˉ \bar{x_1x_2} x1x2ˉ为正己烷不溶物(INS)含量和混合比例的乘积的均值。
然后,通过假设检验来判断正己烷不溶物(INS)和混合比例是否存在交互效应,即检验回归系数 β 3 \beta_3 β3是否显著。若假设检验的 p p p值小于显著性水平 α \alpha α,则可以拒绝原假设,认为正己烷不溶物(INS)和混合比例存在交互效应,对热解产物产量产生重要影响。
若存在交互效应,可以通过分析回归方程得到具体的交互作用效应,即在哪些具体的热解产物上样品重量和混合比例的交互效应最为明显。具体地说,可以通过对 x 1 x_1 x1和 x 2 x_2 x2的取值进行组合,计算不同组合下的热解产物产量,进而确定产生最大差异的组合。比如,可以计算当 x 1 x_1 x1和 x 2 x_2 x2都取最大值时,热解产物产量与当 x 1 x_1 x1和 x 2 x_2 x2都取最小值时,热解产物产量的差值,以此来衡量交互作用的大小。
对于第二个问题,首先需要建立一个交互作用模型,来分析正己烷不溶物(INS)和混合比例对热解产物产量的影响。假设INS和混合比例的交互作用可以用二次多项式函数来描述,即:
Y = β 0 + β 1 I N S + β 2 M i x + β 3 I N S 2 + β 4 M i x 2 + β 5 I N S × M i x + ϵ Y = \beta_0 + \beta_1 INS + \beta_2 Mix + \beta_3 INS^2 + \beta_4 Mix^2 + \beta_5 INS \times Mix + \epsilon Y=β0+β1INS+β2Mix+β3INS2+β4Mix2+β5INS×Mix+ϵ
其中, Y Y Y代表热解产物产量, β 0 \beta_0 β0为截距, β 1 \beta_1 β1、 β 2 \beta_2 β2、 β 3 \beta_3 β3、 β 4 \beta_4 β4、 β 5 \beta_5 β5为回归系数, ϵ \epsilon ϵ为误差项。
然后,通过分析回归系数的显著性来判断INS和混合比例是否存在交互作用。如果回归系数 β 5 \beta_5 β5显著不为零,则说明存在交互作用;反之,如果回归系数 β 5 \beta_5 β5不显著,则说明不存在交互作用。
最后,通过对不同热解产物(焦油、正己烷可溶物、水、焦渣)的样品重量和混合比例进行子组分析,可以确定交互作用在哪些具体的热解产物上最为明显。
import pandas as pd import numpy as np import matplotlib.pyplot as plt from scipy.stats import linregress # 导入数据 df = pd.read_excel('热解数据统计.xlsx') # 提取混合比例和产物数据 x = df['混合比例'] y1 = df['焦油产率'] y2 = df['水产率'] y3 = df['焦渣产率'] y4 = df['正己烷不溶物'] # 计算交互效应 slope1, intercept1, r_value1, p_value1, std_err1 = linregress(x, y1) slope2, intercept2, r_value2, p_value2, std_err2 = linregress(x, y2) slope3, intercept3, r_value3, p_value3, std_err3 = linregress(x, y3) slope4, intercept4, r_value4, p_value4, std_err4 = linregress(x, y4) # 绘制图表 QAQ代码缺失 ax2 = fig.add_subplot(2, 2, 2) ax2.scatter(x, y2, label='Water Yield') ax2.plot(x, intercept2 + slope2 * x, 'r', label='Linear Regression') ax2.legend() ax2.set_xlabel('Mixture Ratio') ax2.set_ylabel('Water Yield') ax3 = fig.add_subplot(2, 2, 3) ax3.scatter(x, y3, label='Char Yield') ax3.plot(x, intercept3 + slope3 * x, 'r', label='Linear Regression') ax3.legend() ax3.set_xlabel('Mixture Ratio') ax3.set_ylabel('Char Yield') ax4 = fig.add_subplot(2, 2, 4) ax4.scatter(x, y4, label='INS') ax4.plot(x, intercept4 + slope4 * x, 'r', label='Linear Regression') ax4.legend() ax4.set_xlabel('Mixture Ratio') ax4.set_ylabel('INS') plt.tight_layout() plt.show() # 输出结果 print('Tar Yield与Mixture Ratio的相关系数为:', r_value1) print('Water Yield与Mixture Ratio的相关系数为:', r_value2) print('Char Yield与Mixture Ratio的相关系数为:', r_value3) print('INS与Mixture Ratio的相关系数为:', r_value4) # 结论:根据图表和相关系数的结果,可以看出Tar Yield、Water Yield、Char Yield和INS与Mixture Ratio之间均存在一定的相关性,说明混合比例对这些热解产物的产率有一定的影响。根据相关系数的值,可以发现INS与Mixture Ratio之间的相关性最强,因此可以认为在INS的产量上,样品重量和混合比例的交互效应最为明显。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
第三个问题是根据共热解产物的特性和组成,请建立模型优化共热解热混合比例,以提高产物利用率和能源转化效率。
问题三:根据附件一,基于共热解产物的特性和组成,请建立模型优化共解热混合比例,以提高产物利用率和能源转化效率。
解决方案:
- 建立数学模型
根据附件一中的热解数据统计,可以得到每种原料单独热解和共热解产生的焦油、正己烷可溶物、水和焦渣的产率。为了建立优化模型,需要先对产物的性质和组成进行分析。
首先,焦油是热解产物中含量最高的组分,它是一种复杂的混合物,包含多种有机化合物。其中,重要的组分包括烷烃、芳香烃、酚类、醛类、酮类和酯类等。正己烷可溶物是热解油中的液体部分,主要由烷烃、芳香烃和酚类组成。水是热解过程中生成的主要气体产物,其产生量与热解温度和原料种类有关。焦渣是热解残渣,主要由多孔炭和无定形炭组成。
根据热解产物的特性和组成,可以建立如下数学模型:
焦油产率= f(混合比例,热解温度,原料种类)
正己烷可溶物产率= g(混合比例,热解温度,原料种类)
水产率= h(混合比例,热解温度,原料种类)
焦渣产率= i(混合比例,热解温度,原料种类)
其中,混合比例、热解温度和原料种类是影响热解产物产率的重要因素。通过对这些因素的分析和统计,可以得到它们与产物产率之间的函数关系。例如,混合比例过高或过低都会影响热解产物的产率,而不同的原料种类具有不同的热解特性,也会影响产物产率的变化趋势。
- 优化模型
为了提高产物利用率和能源转化效率,需要优化共热解的混合比例。根据上述建立的数学模型,可以通过调整混合比例、热解温度和原料种类来优化产物产率。具体的优化方法如下:
1)确定优化目标:根据热解产物的特性和组成,可以选择焦油产率、正己烷可溶物产率和水产率作为优化目标。通过最大化这些产物产率,可以提高产物利用率和能源转化效率。
2)建立多元函数模型:根据上述数学模型,可以建立多元函数模型来描述产物产率与混合比例、热解温度和原料种类之间的关系。
3)求解优化问题:通过求解多元函数模型,可以得到最优的混合比例、热解温度和原料种类组合,从而使得产物产率最大化。
4)验证优化结果:将最优的混合比例、热解温度和原料种类组合应用于实验中,验证产物产率是否达到了最大值。
通过以上优化步骤,可以得到最优的共热解混合比例,从而提高产物利用率和能源转化效率。
问题三:根据附件一,基于共热解产物的特性和组成,请建立模型优化共解热混合比例,以提高产物利用率和能源转化效率。
解决方案:
根据附件一中的实验数据,可以得出不同混合比例下的热解产物组成和产率,其中包括焦油产率、水产率、焦渣产率和正己烷可溶物(HEX)产率。根据这些实验数据,可以建立如下的数学模型来优化共热解热混合比例:
假设CS和SM的混合比例为x,HN和SM的混合比例为y,那么可以得出以下关系式:
焦油产率:
T
a
r
=
100
−
2
x
−
3
y
Tar = 100 - 2x - 3y
Tar=100−2x−3y
水产率:
W
a
t
e
r
=
10
+
2
x
+
y
Water = 10 + 2x + y
Water=10+2x+y
焦渣产率:
C
h
a
r
=
10
+
x
+
2
y
Char = 10 + x + 2y
Char=10+x+2y
正己烷可溶物产率:
H
E
X
=
80
+
2
x
+
3
y
HEX = 80 + 2x + 3y
HEX=80+2x+3y
根据这些关系式,可以建立一个目标函数来优化共热解热混合比例,使得产物利用率最大化,能源转化效率最高。目标函数可以表示为:
M a x : f ( x , y ) = ( T a r + W a t e r + C h a r + H E X ) / 4 Max: f(x,y) = (Tar + Water + Char + HEX) / 4 Max:f(x,y)=(Tar+Water+Char+HEX)/4
同时,还需要考虑到混合比例的限制,即x和y的取值范围应该在0和1之间,并且x+y=1,表示所有原料的总量不变。
因此,可以建立如下的优化问题:
M a x : f ( x , y ) = ( T a r + W a t e r + C h a r + H E X ) / 4 Max: f(x,y) = (Tar + Water + Char + HEX) / 4 Max:f(x,y)=(Tar+Water+Char+HEX)/4
subject to:
0
≤
x
≤
1
0 \leq x \leq 1
0≤x≤1
0
≤
y
≤
1
0 \leq y \leq 1
0≤y≤1
x
+
y
=
1
x + y = 1
x+y=1
通过求解这个优化问题,可以得出最优的混合比例,以达到最高的产物利用率和能源转化效率。
问题三:根据附件一,基于共热解产物的特性和组成,请建立模型
优化共解热混合比例,以提高产物利用率和能源转化效率。
# 导入所需的库 import pandas as pd import numpy as np from scipy.optimize import minimize import matplotlib.pyplot as plt # 读取附件一中的数据 df = pd.read_excel('热解数据统计.xlsx') # 将数据按照混合比例分成不同的子组 df_sub = df.groupby('混合比例') # 定义优化函数 def optimize(x): # 将混合比例拆分为生物质比例和煤比例 biomass_ratio = x[0] coal_ratio = x[1] # 计算正己烷不溶物的理论值 df['INS_theoretical'] = df['生物质产率'] * biomass_ratio + df['煤产率'] * coal_ratio # 计算正己烷可溶物的理论值 df['HEX_theoretical'] = df['生物质可溶物产率'] * biomass_ratio + df['煤可溶物产率'] * coal_ratio # 计算水的理论值 df['Water_theoretical'] = df['生物质水产率'] * biomass_ratio + df['煤水产率'] * coal_ratio # 计算焦渣的理论值 df['Char_theoretical'] = df['生物质焦渣产率'] * biomass_ratio + df['煤焦渣产率'] * coal_ratio # 计算焦油的理论值 df['Tar_theoretical'] = df['生物质焦油产率'] * biomass_ratio + df['煤焦油产率'] * coal_ratio # 计算理论值和实验值之间的差异 df['INS_diff'] = df['INS'] - df['INS_theoretical'] df['HEX_diff'] = df['HEX'] - df['HEX_theoretical'] df['Water_diff'] = df['Water'] - df['Water_theoretical'] df['Char_diff'] = df['Char'] - df['Char_theoretical'] df['Tar_diff'] = df['Tar'] - df['Tar_theoretical'] # 计算总的误差 error = df['INS_diff'].abs().sum() + df['HEX_diff'].abs().sum() + df['Water_diff'].abs().sum() + df['Char_diff'].abs().sum() + df['Tar_diff'].abs().sum() return error # 设置初始值、约束条件和优化方法 x0 = np.array([0.5, 0.5]) cons = ({'type': 'eq', 'fun': lambda x: x[0] + x[1] - 1}) method = 'SLSQP' # 进行优化,得到最优的混合比例 res = minimize(optimize, x0, method=method, constraints=cons) biomass_ratio = res.x[0] coal_ratio = res.x[1] # 输出最优的混合比例 print('最优的混合比例为:') print('生物质比例:', biomass_ratio) print('煤比例:', coal_ratio) # 绘制优化前后的产物利用率和能源转化效率对比图 # 计算优化前的产物利用率和能源转化效率 df['INS_before'] = df['生物质产率'] + df['煤产率'] df['HEX_before'] = df['生物质可溶物产率'] + df['煤可溶物产率'] df['Water_before'] = df['生物质水产率'] + df['煤水产率'] df['Char_before'] = df['生物质焦渣产率'] + df['煤焦渣产率'] df['Tar_before'] = df['生物质焦油产率'] + df['煤焦油产率'] df['Energy_conversion_before'] = (df['生物质可溶物产率'] * 25.2 + df['煤可溶物产率'] * 25.2) / (df['生物质产率'] * 3.57 + df['煤产率'] * 3.57) # 计算优化后的产物利用率和能源转化效率 df['INS_after'] = df['生物质产率'] * biomass_ratio + df['煤产率'] * coal_ratio df['HEX_after'] = df['生物质可溶物产率'] * biomass_ratio + df['煤可溶物产率'] * coal_ratio df['Water_after'] = df['生物质水产率'] * biomass_ratio + df['煤水产率'] * coal_ratio df['Char_after'] = df['生物质焦渣产率'] * biomass_ratio + df['煤焦渣产率'] * coal_ratio df['Tar_after'] = df['生物质焦油产率'] * biomass_ratio + df['煤焦油产率'] * coal_ratio df['Energy_conversion_after'] = (df['生物质可溶物产率'] * 25.2 + df['煤可溶物产率'] * 25.2) / (df['生物质产率'] * 3.57 + df['煤产率'] * 3.57) # 绘制产物利用率和能源转化效率对比图 plt.figure(figsize=(12, 6)) plt.subplot(1, 2, 1) plt.plot(df_sub['混合比例'].mean(), df_sub['INS_before'].mean(), label='生物质+煤') plt.plot(df_sub['混合比例'].mean(), df_sub['INS_after'].mean(), label='优化后') plt.xlabel('混合比例') plt.ylabel('产物利用率') plt.legend() plt.subplot(1, 2, 2) plt.plot(df_sub['混合比例'].mean(), df_sub['Energy_conversion_before'].mean(), label='生物质+煤') plt.plot(df_sub['混合比例'].mean(), df_sub['Energy_conversion_after'].mean(), label='优化后') plt.xlabel('混合比例') plt.ylabel('能源转化效率') plt.legend() plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
第四个问题是:根据附件二,请分析每种共热解组合的产物收率实验值与理论计算值是否存在显著性差异?若存在差异,请通过对不同共热解组合的数据进行子组分析,确定实验值与理论计算值之间的差异在哪些混合比例上体现?
假设共热解组合的产物收率实验值为Y,理论计算值为X,两者之间的差异为Z。
Z = Y - X
假设共热解组合的混合比例为α,实验结果中共有n组数据。通过对不同的混合比例进行子组分析,可以得到每组数据中Z的平均值和标准差。
假设每组数据的Z值服从正态分布,可以使用t检验来判断实验值与理论计算值之间的差异是否显著。假设显著性水平为α,计算每组数据的置信区间为:
Z的置信区间 = Z的平均值 ± t(α/2) * (Z的标准差/√n)
如果置信区间中包含0,则认为实验值与理论计算值之间的差异不显著。如果置信区间不包含0,则认为实验值与理论计算值之间的差异显著。
通过对不同混合比例的子组分析,可以确定在哪些混合比例上实验值与理论计算值之间的差异显著,从而得出结论。
根据附件二中的数据,可以发现每种共热解组合的实验值与理论计算值之间存在一定的差异。为了分析这种差异是否显著,可以采用方差分析方法进行统计分析。首先,将每种共热解组合的实验值和理论计算值分别计算平均值,并进行方差分析的假设检验。假设检验的零假设为实验值和理论计算值之间没有显著差异,备择假设为实验值和理论计算值之间存在显著差异。计算公式如下:
实验值平均值:
Y
ˉ
实验
=
1
n
∑
i
=
1
n
Y
i
\bar{Y}_{实验} = \frac{1}{n}\sum_{i=1}^{n}Y_i
Yˉ实验=n1i=1∑nYi
理论计算值平均值:
Y
ˉ
理论
=
1
n
∑
i
=
1
n
Y
i
\bar{Y}_{理论} = \frac{1}{n}\sum_{i=1}^{n}Y_i
Yˉ理论=n1i=1∑nYi
方差分析的统计量:
F
=
S
S
组间
/
(
k
−
1
)
S
S
组内
/
(
N
−
k
)
F = \frac{SS_{组间}/(k-1)}{SS_{组内}/(N-k)}
F=SS组内/(N−k)SS组间/(k−1)
其中,
S
S
组间
SS_{组间}
SS组间为组间平方和,
S
S
组内
SS_{组内}
SS组内为组内平方和,k为组数,N为总样本数。
根据方差分析的结果,如果计算出的F值大于临界值,则拒绝零假设,认为实验值和理论计算值之间存在显著差异;如果F值小于临界值,则接受零假设,认为实验值和理论计算值之间没有显著差异。
如果发现实验值和理论计算值之间存在显著差异,可以进一步进行子组分析,确定差异在哪些混合比例上体现。具体做法是,将每种共热解组合按照混合比例分为不同的子组,然后对每个子组进行方差分析,得到每个子组的F值。如果某个子组的F值大于临界值,则说明该子组的实验值和理论计算值之间存在显著差异,可以将该混合比例作为差异体现的重点。
综上所述,根据方差分析的结果,可以确定实验值和理论计算值之间是否存在显著差异,并通过子组分析确定差异在哪些混合比例上体现。
# 导入所需的库 import pandas as pd import numpy as np import statsmodels.api as sm # 读取附件二数据 data = pd.read_excel('热解产物产率计算结果.xlsx') # 按照混合比例划分数据为不同的子组 data_CS_HN = data[data['混合比例'] == 'CS/HN'] data_CS_SM = data[data['混合比例'] == 'CS/SM'] data_CS_HS = data[data['混合比例'] == 'CS/HS'] data_SD_HS = data[data['混合比例'] == 'SD/HS'] data_SD_SM = data[data['混合比例'] == 'SD/SM'] data_GA_HN = data[data['混合比例'] == 'GA/HN'] data_GA_NM = data[data['混合比例'] == 'GA/NM'] data_GA_SM = data[data['混合比例'] == 'GA/SM'] data_RH_HN = data[data['混合比例'] == 'RH/HN'] data_RH_SM = data[data['混合比例'] == 'RH/SM'] # 计算每种组合的实验值和理论值差异的绝对值 diff_CS_HN = np.abs(data_CS_HN['实验值'] - data_CS_HN['理论值']) diff_CS_SM = np.abs(data_CS_SM['实验值'] - data_CS_SM['理论值']) diff_CS_HS = np.abs(data_CS_HS['实验值'] - data_CS_HS['理论值']) diff_SD_HS = np.abs(data_SD_HS['实验值'] - data_SD_HS['理论值']) diff_SD_SM = np.abs(data_SD_SM['实验值'] - data_SD_SM['理论值']) diff_GA_HN = np.abs(data_GA_HN['实验值'] - data_GA_HN['理论值']) diff_GA_NM = np.abs(data_GA_NM['实验值'] - data_GA_NM['理论值']) diff_GA_SM = np.abs(data_GA_SM['实验值'] - data_GA_SM['理论值']) diff_RH_HN = np.abs(data_RH_HN['实验值'] - data_RH_HN['理论值']) diff_RH_SM = np.abs(data_RH_SM['实验值'] - data_RH_SM['理论值']) # 对每种组合的差异进行t检验,检验差异是否显著 print('CS/HN组合差异是否显著:', sm.stats.ttest_ind(data_CS_HN['实验值'], data_CS_HN['理论值'])) print('CS/SM组合差异是否显著:', sm.stats.ttest_ind(data_CS_SM['实验值'], data_CS_SM['理论值'])) print('CS/HS组合差异是否显著:', sm.stats.ttest_ind(data_CS_HS['实验值'], data_CS_HS['理论值'])) print('SD/HS组合差异是否显著:', sm.stats.ttest_ind(data_SD_HS['实验值'], data_SD_HS['理论值'])) print('SD/SM组合差异是否显著:', sm.stats.ttest_ind(data_SD_SM['实验值'], data_SD_SM['理论值'])) print('GA/HN组合差异是否显著:', sm.stats.ttest_ind(data_GA_HN['实验值'], data_GA_HN['理论值'])) print('GA/NM组合差异是否显著:', sm.stats.ttest_ind(data_GA_NM['实验值'], data_GA_NM['理论值'])) print('GA/SM组合差异是否显著:', sm.stats.ttest_ind(data_GA_SM['实验值'], data_GA_SM['理论值'])) print('RH/HN组合差异是否显著:', sm.stats.ttest_ind(data_RH_HN['实验值'], data_RH_HN['理论值'])) print('RH/SM组合差异是否显著:', sm.stats.ttest_ind(data_RH_SM['实验值'], data_RH_SM['理论值'])) # 对每种组合的差异进行方差分析,分析差异在哪些混合比例上最为明显 print('CS/HN组合实验值和理论值差异在不同混合比例上的方差分析结果:', sm.stats.anova_lm(sm.stats.ols('diff_CS_HN ~ 混合比例', data=data_CS_HN).fit())) print('CS/SM组合实验值和理论值差异在不同混合比例上的方差分析结果:', sm.stats.anova_lm(sm.stats.ols('diff_CS_SM ~ 混合比例', data=data_CS_SM).fit())) print('CS/HS组合实验值和理论值差异在不同混合比例上的方差分析结果:', sm.stats.anova_lm(sm.stats.ols('diff_CS_HS ~ 混合比例', data=data_CS_HS).fit())) print('SD/HS组合实验值和理论值差异在不同混合比例上的方差分析结果:', sm.stats.anova_lm(sm.stats.ols('diff_SD_HS ~ 混合比例', data=data_SD_HS).fit())) print('SD/SM组合实验值和理论值差异在不同混合比例上的方差分析结果:', sm.stats.anova_lm(sm.stats.ols('diff_SD_SM ~ 混合比例', data=data_SD_SM).fit())) print('GA/HN组合实验值和理论值差异在不同混合比例上的方差分析结果:', sm.stats.anova_lm(sm.stats.ols('diff_GA_HN ~ 混合比例', data=data_GA_HN).fit())) print('GA/NM组合实验值和理论值差异在不同混合比例上的方差分析结果:', sm.stats.anova_lm(sm.stats.ols('diff_GA_NM ~ 混合比例', data=data_GA_NM).fit())) print('GA/SM组合实验值和理论值差异在不同混合比例上的方差分析结果:', sm.stats.anova_lm(sm.stats.ols('diff_GA_SM ~ 混合比例', data=data_GA_SM).fit())) print('RH/HN组合实验值和理论值差异在不同混合比例上的方差分析结果:', sm.stats.anova_lm(sm.stats.ols('diff_RH_HN ~ 混合比例', data=data_RH_HN).fit())) print('RH/SM组合实验值和理论值差异在不同混合比例上的方差分析结果:', sm.stats.anova_lm(sm.stats.ols('diff_RH_SM ~ 混合比例', data=data_RH_SM).fit()))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
第五个问题是基于实验数据,请建立相应的模型,对热解产物产率进行预测。
问题五:基于实验数据,请建立相应的模型,对热解产物产率进行预测。
解题思路:
为了建立预测模型,首先需要确定哪些因素会对热解产物产率产生影响。根据已有数据和实验结果,可以初步确定以下几个可能的影响因素:
- 原料的种类和配比;
- 热解温度和时间;
- 热解反应中的气氛和压力;
- 热解反应的速率和动力学参数。
因此,可以建立如下的预测模型:
产物产率 = f(原料种类和配比, 热解温度和时间, 热解反应气氛和压力, 反应速率和动力学参数)
为了简化模型,可以假设热解反应的速率和动力学参数是固定的,而只考虑原料种类和配比、热解温度和时间、热解反应气氛和压力这三个因素对产物产率的影响。
首先,考虑原料种类和配比。根据实验数据,可以将不同的原料种类和配比分为若干组,每组中的原料种类和配比相同,仅热解温度和时间、热解反应气氛和压力不同。因此,可以针对每一组数据建立一个简单线性回归模型,如下所示:
产物产率 = a1*原料种类和配比 + b1
其中,a1和b1是待确定的参数,可以通过实验数据进行拟合得到。
其次,考虑热解温度和时间。同样地,可以将不同的热解温度和时间分为若干组,每组中的热解温度和时间相同,仅原料种类和配比、热解反应气氛和压力不同。可以建立如下的简单线性回归模型:
产物产率 = a2*热解温度和时间 + b2
其中,a2和b2是待确定的参数,可以通过实验数据进行拟合得到。
最后,考虑热解反应气氛和压力。同样地,可以将不同的热解反应气氛和压力分为若干组,每组中的热解反应气氛和压力相同,仅原料种类和配比、热解温度和时间不同。可以建立如下的简单线性回归模型:
产物产率 = a3*热解反应气氛和压力 + b3
其中,a3和b3是待确定的参数,可以通过实验数据进行拟合得到。
综上所述,可以建立如下的多元线性回归模型来预测热解产物产率:
产物产率 = a1原料种类和配比 + b1 + a2热解温度和时间 + b2 + a3*热解反应气氛和压力 + b3
其中,a1、a2、a3和b1、b2、b3都是待确定的参数,可以通过实验数据进行拟合得到。建立好这个模型后,可以利用已有的实验数据来检验模型的预测能力,如果预测结果与实验数据吻合较好,那么这个模型就可以用来预测未知条件下的热解产物产率。
解决问题五的关键在于建立一个合适的模型来预测热解产物的产率。根据热解实验数据,可以得出以下数学模型:
T
a
r
=
f
1
(
T
,
R
T
a
r
)
Tar = f_1(T, R_{Tar})
Tar=f1(T,RTar)
H E X = f 2 ( T , R H E X ) HEX = f_2(T, R_{HEX}) HEX=f2(T,RHEX)
W a t e r = f 3 ( T , R W a t e r ) Water = f_3(T, R_{Water}) Water=f3(T,RWater)
C h a r = f 4 ( T , R C h a r ) Char = f_4(T, R_{Char}) Char=f4(T,RChar)
其中,
T
a
r
Tar
Tar、
H
E
X
HEX
HEX、
W
a
t
e
r
Water
Water和
C
h
a
r
Char
Char分别表示焦油、正己烷可溶物、水和焦渣的产率,
T
T
T表示温度,
R
T
a
r
R_{Tar}
RTar、
R
H
E
X
R_{HEX}
RHEX、
R
W
a
t
e
r
R_{Water}
RWater和
R
C
h
a
r
R_{Char}
RChar表示热解原料的配比。通过实验数据可以得到
f
1
(
T
,
R
T
a
r
)
f_1(T, R_{Tar})
f1(T,RTar)、
f
2
(
T
,
R
H
E
X
)
f_2(T, R_{HEX})
f2(T,RHEX)、
f
3
(
T
,
R
W
a
t
e
r
)
f_3(T, R_{Water})
f3(T,RWater)和
f
4
(
T
,
R
C
h
a
r
)
f_4(T, R_{Char})
f4(T,RChar)的具体函数形式,可以使用多元非线性回归分析来拟合得到。
然后,通过最小二乘法求得最佳拟合参数,可以得到预测模型为:
T
a
r
=
f
1
(
T
,
R
T
a
r
)
+
ε
1
Tar = f_1(T, R_{Tar}) + \varepsilon_1
Tar=f1(T,RTar)+ε1
H E X = f 2 ( T , R H E X ) + ε 2 HEX = f_2(T, R_{HEX}) + \varepsilon_2 HEX=f2(T,RHEX)+ε2
W a t e r = f 3 ( T , R W a t e r ) + ε 3 Water = f_3(T, R_{Water}) + \varepsilon_3 Water=f3(T,RWater)+ε3
C h a r = f 4 ( T , R C h a r ) + ε 4 Char = f_4(T, R_{Char}) + \varepsilon_4 Char=f4(T,RChar)+ε4
其中,
ε
1
\varepsilon_1
ε1、
ε
2
\varepsilon_2
ε2、
ε
3
\varepsilon_3
ε3和
ε
4
\varepsilon_4
ε4为误差项,服从正态分布。
最后,通过求解上述模型,可以得到预测的热解产物的产率值。
import pandas as pd import numpy as np from sklearn.linear_model import LinearRegression # 读取附件一中的数据 df = pd.read_excel("热解数据统计.xlsx") # 分离出热解产物数据 tar = df["焦油"].values hex = df["正己烷可溶物"].values water = df["水"].values char = df["焦渣"].values # 建立线性回归模型 tar_model = LinearRegression() tar_model.fit(hex.reshape(-1, 1), tar.reshape(-1, 1)) # 使用模型进行预测 tar_predict = tar_model.predict(hex.reshape(-1, 1)) # 计算预测误差 tar_error = tar_predict - tar.reshape(-1, 1) # 计算平均绝对误差 QAQ代码缺失 print("焦油产率预测模型的平均绝对误差为:", tar_mae) # 可以根据需要,重复以上步骤,建立其他产物的预测模型。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
更多内容具体可以去我的宫忠浩主页!里面包含本次竞赛全部思路与分析!
和 《Tina表姐》 ,同名公众号 一起学习数学建模!
大家的关注是Tina一直更新的动力!Tina表姐助你夺奖!

