
flask中的操作数据库的插件Flask-SQLAlchemy_python flask 使用 插件库
赞
踩
1、ORM 框架
Web 开发中,一个重要的组成部分便是数据库了。Web 程序中最常用的莫过于关系型数据库了,也称 SQL 数据库。另外,文档数据库(如 mongodb)、键值对数据库(如 redis)近几年也逐渐在 web 开发中流行起来,我们习惯把这两种数据库称为 NoSQL 数据库。
大多数的关系型数据库引擎(比如 MySQL、Postgres 和 SQLite)都有对应的 Python 包。在这里,我们不直接使用这些数据库引擎提供的 Python 包,而是使用对象关系映射(Object-Relational Mapper, ORM)框架,它将低层的数据库操作指令抽象成高层的面向对象操作。也就是说,如果我们直接使用数据库引擎,我们就要写 SQL 操作语句,但是,如果我们使用了 ORM 框架,我们对诸如表、文档此类的数据库实体就可以简化成对 Python 对象的操作。
Python 中最广泛使用的 ORM 框架是 SQLAlchemy,它是一个很强大的关系型数据库框架,不仅支持高层的 ORM,也支持使用低层的 SQL 操作,另外,它也支持多种数据库引擎,如 MySQL、Postgres 和 SQLite 等
2、Flask-SQLAlchemy
在 Flask 中,为了简化配置和操作,我们使用的 ORM 框架是 Flask-SQLAlchemy,这个 Flask 扩展封装了 SQLAlchemy 框架。在 Flask-SQLAlchemy 中,数据库使用 URL 指定,下表列出了常见的数据库引擎和对应的 URL
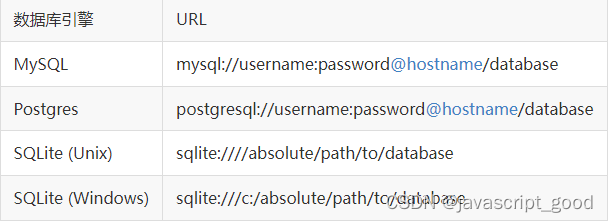
上面的表格中,username 和 password 表示登录数据库的用户名和密码,hostname 表示 SQL 服务所在的主机,可以是本地主机(localhost)也可以是远程服务器,database 表示要使用的数据库。有一点需要注意的是,SQLite 数据库不需要使用服务器,它使用硬盘上的文件名作为 database。
3、一个最小的应用
创建数据库
首先,我们使用 pip 安装 Flask-SQLAlchemy:
pip install flask-sqlalchemy
- 1
接下来,我们配置一个简单的 SQLite 数据库:
$ cat app.py # -*- coding: utf-8 -*- from flask import Flask from flask_sqlalchemy import SQLAlchemy app = Flask(__name__) app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///db/users.db' app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True db = SQLAlchemy(app) class User(db.Model): """定义数据模型""" __tablename__ = 'users' id = db.Column(db.Integer, primary_key=True) username = db.Column(db.String(80), unique=True) email = db.Column(db.String(120), unique=True) def __init__(self, username, email): self.username = username self.email = email def __repr__(self): return '<User %r>' % self.username

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
这里有几点需要注意的是:
- app 应用配置项 SQLALCHEMY_DATABASE_URI 指定了 SQLAlchemy 所要操作的数据库,这里我们使用的是 SQLite,数据库 URL 以 sqlite:/// 开头,后面的 db/users.db 表示数据库文件存放在当前目录的 db 子目录中的 users.db 文件。当然,你也可以使用绝对路径,如 /tmp/users.db 等。
- db 对象是 SQLAlchemy 类的实例,表示程序使用的数据库。
- 我们定义的 User 模型必须继承自 db.Model,这里的模型其实就对应着数据库中的表。其中,类变量__tablename__ 定义了在数据库中使用的表名,如果该变量没有被定义,Flask-SQLAlchemy 会使用一个默认名字。
接着,我们创建表和数据库。为此,我们先在当前目录创建 db 子目录和新建一个 users.db 文件,然后在交互式 Python shell 中导入 db 对象并调用 SQLAlchemy 类的 create_all() 方法:
$ mkdir db
$ python
>>> from app import db
>>> db.create_all()
- 1
- 2
- 3
- 4
我们验证一下,”users” 表是否创建成功:
$ sqlite3 db/users.db # 打开数据库文件
SQLite version 3.8.10.2 2015-05-20 18:17:19
Enter ".help" for usage hints.
sqlite> .schema users # 查看 "user" 表的 schema
CREATE TABLE users (
id INTEGER NOT NULL,
username VARCHAR(80),
email VARCHAR(120),
PRIMARY KEY (id),
UNIQUE (username),
UNIQUE (email)
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
插入数据
我们创建一些用户,通过使用 db.session.add()来添加数据:
@app.route('/adduser')
def add_user():
user1 = User('ethan', 'ethan@example.com')
user2 = User('admin', 'admin@example.com')
user3 = User('guest', 'guest@example.com')
user4 = User('joe', 'joe@example.com')
user5 = User('michael', 'michael@example.com')
db.session.add(user1)
db.session.add(user2)
db.session.add(user3)
db.session.add(user4)
db.session.add(user5)
db.session.commit()
return "<p>add succssfully!"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这里有一点要注意的是,我们在将数据添加到会话后,在最后要记得调用 db.session.commit() 提交事务,这样,数据才会被写入到数据库。
查询数据
查询数据主要是用 query 接口,例如 all() 方法返回所有数据,filter_by() 方法对查询结果进行过滤,参数是键值对,filter 方法也可以对结果进行过滤,但参数是布尔表达式,详细的介绍请查看这里。
>>> from app import User
>>> users = User.query.all()
>>> users
[<User u'ethan'>, <User u'admin'>, <User u'guest'>, <User u'joe'>, <User u'michael'>]
>>>
>>> user = User.query.filter_by(username='joe').first()
>>> user
<User u'joe'>
>>> user.email
u'joe@example.com'
>>>
>>> user = User.query.filter(User.username=='ethan').first()
>>> user
<User u'ethan'>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
如果我们想查看 SQLAlchemy 为查询生成的原生 SQL 语句,只需要把 query 对象转化成字符串:
>>> str(User.query.filter_by(username='guest'))
'SELECT users.id AS users_id, users.username AS users_username, users.email AS users_email \nFROM users \nWHERE users.username = :username_1'
- 1
- 2
分页方法
分页方法可以采用 limit() 和 offset() 方法,比如从第 3 条记录开始取(注意是从 0 开开始算起),并最多取 1 条记录,可以这样:
users = User.query.limit(1).offset(3)
- 1
更新数据
更新数据也用 add() 方法,如果存在要更新的对象,SQLAlchemy 就更新该对象而不是添加。
>>> from app import db
>>> from app import User
>>>
>>> admin = User.query.filter_by(username='admin').first()
>>>
>>> admin.email = 'admin@hotmail.com'
>>> db.session.add(admin)
>>> db.session.commit()
>>>
>>> admin = User.query.filter_by(username='admin').first()
>>> admin.email
u'admin@hotmail.com'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
删除数据
删除数据用 delete() 方法,同样要记得 delete 数据后,要调用 commit() 提交事务:
>>> from app import db
>>> from app import User
>>>
>>> admin = User.query.filter_by(username='admin').first()
>>> db.session.delete(admin)
>>> db.session.commit()
- 1
- 2
- 3
- 4
- 5
- 6

