
热门标签
热门文章
- 1STM32F1与STM32CubeIDE快速入门:物联网开发环境搭建_stm32 cubeide开发环境
- 2【7年工作-Java技术栈整理】——容器化编排技术K8S——单机版K8S最简安装 【练手k8s必备】_java web 容器及容器编排
- 3【Postman&JMeter】使用Postman和JMeter进行signature签名_使用postman怎么拿签名
- 4阿里面试官:Android面试这些原理都给我讲明白了,最低都是20k起步!_android面试考原理有啥用
- 5耗时半月,终于把牛客网上的软件测试面试八股文整理成了PDF合集(测试基础+linux+MySQL+接口测试+自动化测试+测试框架+jmeter测试+测试开发)_牛客网题库pdf
- 6如何优化深度学习模型_加强智能学习系统,优化学习模型
- 7【云原生】Docker Compose 使用详解_使用 docker compose
- 8【SpringBoot系列!】Spring Boot 3 核心技术和最佳实践_springboot3核心技术与最佳
- 9完全使用gnu linux工作_linux hspice教程
- 10Prometheus学习和整理_prometheus.yaml配置
当前位置: article > 正文
Yolov8轻量级:Next-vit,用于现实工业场景的下一代视觉 Transformer_yolov8轻量化
作者:繁依Fanyi0 | 2024-05-24 01:17:10
赞
踩
yolov8轻量化
1.Next-vit介绍
论文:https://arxiv.org/pdf/2207.05501.pdf
由于复杂的注意力机制和模型设计,大多数现有的视觉 Transformer(ViT)在现实的工业部署场景中不能像卷积神经网络(CNN)那样高效地执行。这就带来了一个问题:视觉神经网络能否像 CNN 一样快速推断并像 ViT 一样强大?
主要贡献总结如下:
1)开发了具有部署友好机制的强大卷积块和变换块,即NCB和NTB。Next-ViT堆栈NCB和NTB 构建先进的CNN-Transformer混合架构。
2)从一个新的角度设计了一种创新的CNN Transformer混合策略,该策略可以高效地提高性能。
3)介绍了Next ViT。大量实验证明了Next ViT的优势。它在TensorRT和CoreML上实现了图像分类、目标检测和语义分割的SOTA延迟/精度权衡。
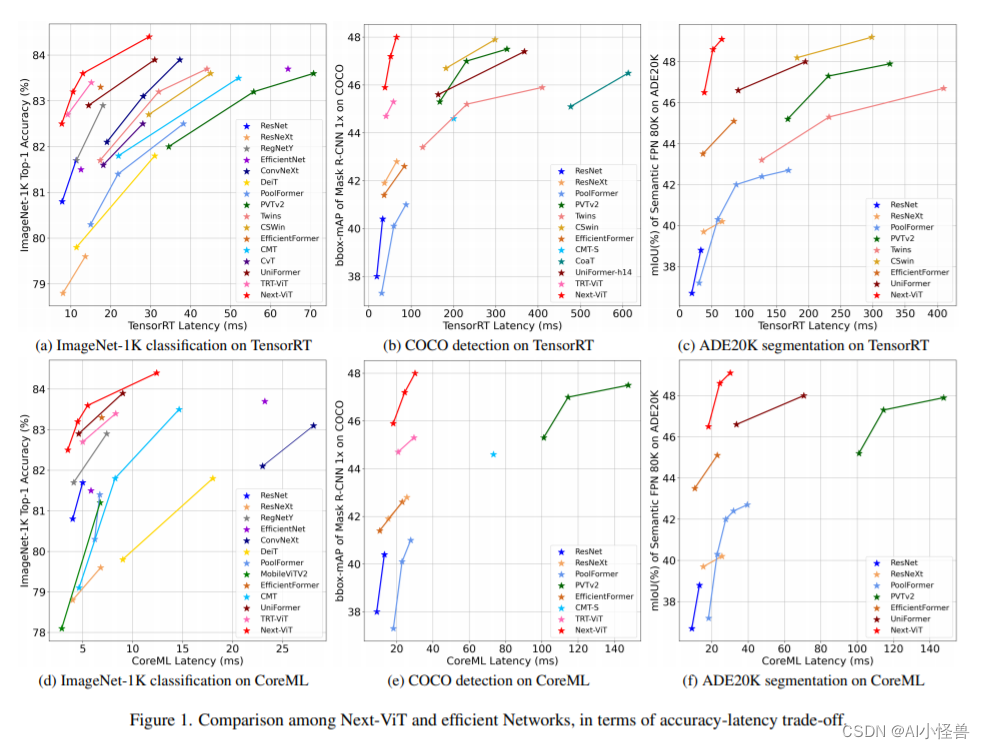 Next-ViT 的研究团队通过开发新型的卷积块(NCB)和 Transformer 块(NTB),
Next-ViT 的研究团队通过开发新型的卷积块(NCB)和 Transformer 块(NTB),
推荐阅读
相关标签

