
热门标签
热门文章
- 1最新能让老外对口型讲中文的AI 视频教程,免费开源AI工具——Wav2Lip_sd-wav2lip-uhq
- 2nginx安装http_ssl_module模块_nginx http ssl
- 3mac 安装mysql_macbook 安装mysql
- 4Data truncation: Out of range value for column ‘id‘ at row 1_data truncation: out of range value for column 'id
- 5常见运维监控系统的技术选型_开发运营 技术监控手段
- 6【小白学习C++ 教程】十九、C++ 中的<cmath> 数学函数和 <random>随机数_c++ math random
- 7解决Ubuntu系统下/home满了的问题_vscode-cpptools可以删除吗
- 8kafka 的consumer配置参数_kafkaconsumer参数
- 9单片机设计基于Arduino的物流分拣控制系统_请利用arduino套装中的oled、rfid和舵机部件,模拟物流的分拣系统,实现以下功
- 10Transformer从零详细解读(可能是你见过最通俗易懂的讲解)_transformer代码逐步讲解
当前位置: article > 正文
YoloV8改进策略:Block篇|基于FasterNet的Block改进|附结构图|性能和精度得到大幅度提高(独家原创)
作者:繁依Fanyi0 | 2024-06-04 00:03:55
赞
踩
YoloV8改进策略:Block篇|基于FasterNet的Block改进|附结构图|性能和精度得到大幅度提高(独家原创)
摘要
本文使用FasterNet的Block改进YoloV8,对FasterNet的Block做了适当的修改,使其能够适配YoloV8,可以替换YoloV8的Bottleneck模块。
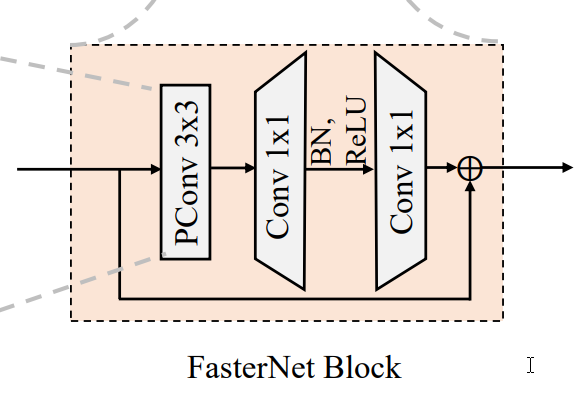
论文翻译:《CVPR2023年最新的网络,基于部分卷积PConv,性能远超MobileNet,MobileVit
为了设计快速神经网络,许多工作都专注于减少浮点运算(FLOPs)的数量。然而,我们观察到这样的flop减少并不一定会导致类似水平的延迟减少。这主要源于低效的低浮点运算每秒(FLOPS)。为了实现更快的网络,我们重新考察了流行的运算符,并证明了这样低的FLOPS主要是由于运算符频繁的内存访问,特别是深度卷积。因此,我们提出了一种新的部分卷积(PConv),通过同时减少冗余计算和内存访问,更有效地提取空间特征。在PConv的基础上,我们进一步提出了fastternet,这是一种新的神经网络家族,它在各种设备上获得了比其他网络更高的运行速度,而不影响各种视觉任务的准确性。例如,在ImageNet- 1k上,我们的小型FasterNet-T0分别比GPU、CPU和ARM处理器上的MobileViT-XXS快3.1×、3.1×和2.5×,同时精度提高了2.9%。我们的大型fastnet-l达到了令人印象深刻的83.5%的top-1精度,与Swin-B相当,同时在GPU上具有49%的更高推断吞吐量,以及在CPU上节省42%的计算时间。代码可从https://gi
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/669498
推荐阅读
相关标签

