
- 1django 重定向如何解决iframe页面嵌套问题_django 重定向 禁止iframe
- 2C语言求n的阶乘(n!)的3种方法
- 3python中的时间戳和日期的相互转化_python timestamp转换成date
- 4第十四届蓝桥杯第三期模拟赛 【python】_蓝桥杯模拟赛第三期python
- 5基于SpringBoot+VUE的考试题库刷题系统_在线刷题系统springboot+vue
- 6Git Gui相关术语_amend last commit
- 7JavaScript的基础运算符重点表达式_js 字符串+1
- 82024-01-06-AI 大模型全栈工程师 - 机器学习基础
- 9英伟达3080Ti、3070Ti来了:继续封锁挖矿性能,网友:不信,空气卡+1
- 10深入浅出Java基础_autoboxcachemax
ViT/vit/VIT详解_vit和vit.
赞
踩
参考:
- Vision Transformer详解:
https://blog.csdn.net/qq_37541097/article/details/118242600
目录:
- x.1 (论文中)模型理解
- x.2 代码理解
建议阅读时间:10min
x.1 模型理解
ViT是发表在ICLR2021上的一篇文章,通过将图片分割成一个一个小patch而将Transformer引入了CV。这个ViT的模型可以用下面一张图表示,模型经历的步骤如下:
- 将图片分成一个一个小的patch
- 将patch通过Linear Projection of Flattened Patches展平成一个一个token
- concat一个维度的类别的信息
- add位置信息Position Embedding(这里面的参数是要训练的)
- 将向量传入Transformer Encoder中进行训练
- 将输出的向量中只取类别信息,将类别信息经过MLP Head处理(Linear层/或者Linear + tanh + Linear层)
- 再传入softmax层,输出类型Class
根据上面的步骤,我们将整个ViT分为如下几个部分理解:
- x.1.1 Embedding层结构理解
- x.1.2 Transformer Encoder理解
- x.1.3 MLP Head理解
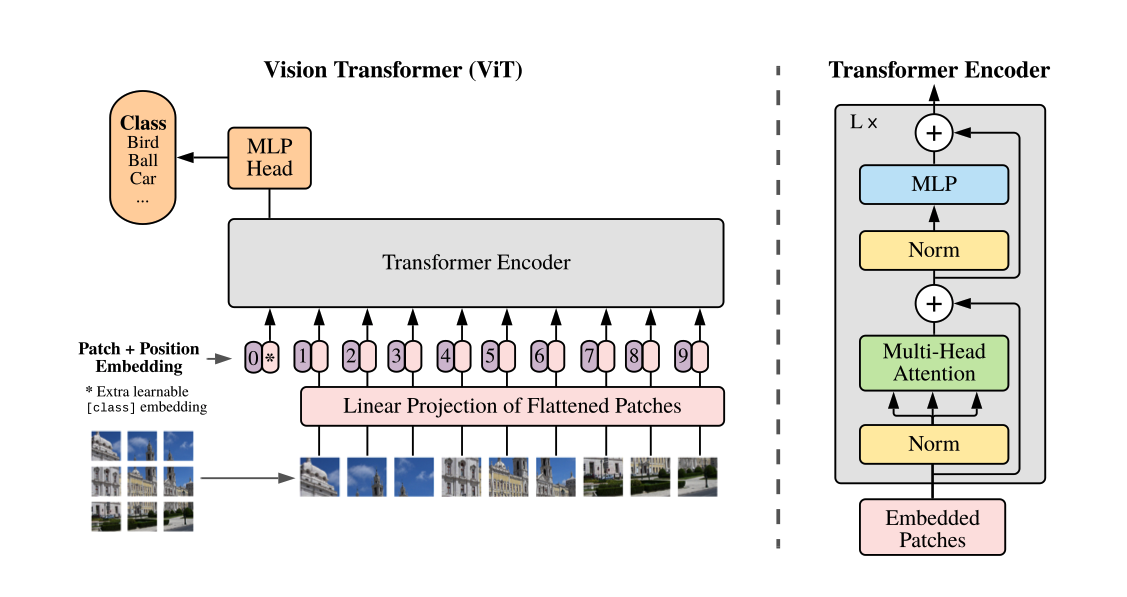
x.1.1 Embedding层结构理解
以输入224x224的图片大小,ViT-B/16为例,我们将图片切割成16x16的大小,最终我们可以得到 224 ∗ 224 16 ∗ 16 = 196 p i e c e s \frac{224*224}{16*16}=196pieces 16∗16224∗224=196pieces的patches,即将1张[224, 224, 3]的图片 ->(切割成) 196张[16, 16, 3]的patches。

接着我们将196张[16, 16, 3]patches经过Linear Projection of Flattened Patches转成tokens,即将196个patches的Height,Width和Channel进行展平处理(
H
∗
W
∗
c
h
a
n
n
e
l
H*W*channel
H∗W∗channel)变成196个[768]的tokens。最终变成[196, 768]的tokens输入,其中196是num_query=num_token,768是query_dimension=token_dimension=词向量长度。
同时我们要增加一个类别信息,类别信息的shape为[1, 768],我们将类别信息和token进行(concat)拼接,Cat([1, 768], [196, 768]) -> [197, 768]。Q:不是很理解为什么不是196个类别,768长度的词向量变成769的词向量,因为类别应该算是一个特征,而不是样本吧?猜测:可能是因为一整个图片才算一个类别,我们只是输入了一个值?
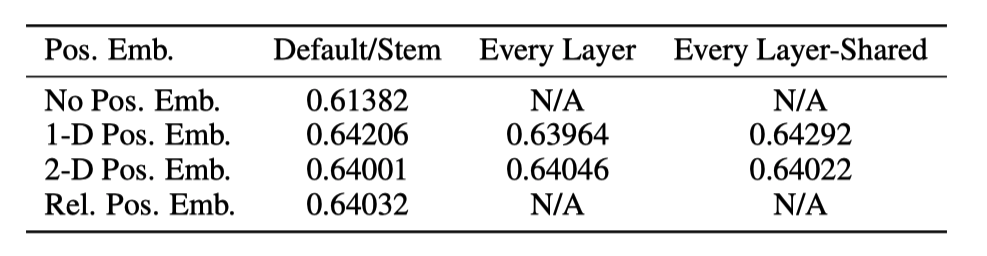
最后我们需要增加Position Embedding类别信息,这里直接进行(add)加操作,Add([197, 768], [197, 768]) -> [197, 768]这是一个需要训练的操作。通过增加增加Position Embedding,我们的准确率增加了3个点,如下图2。
至此我们得到了[197, 768]的词向量。

x.1.2 Transformer Encoder
单单使用摞了L层的Transformer Encoder。参考https://blog.csdn.net/qq_43369406/article/details/129306734。
我们输入[197, 768]的词向量得到[197, 768]的词向量。
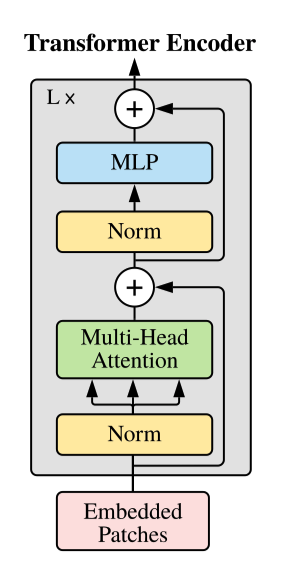
Q: L层是什么意思?A:是串行操作,如下图所示:
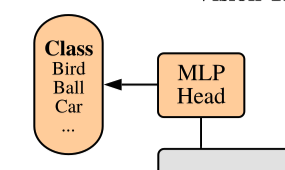
x.1.3 MLP Head理解
从[197, 768]中取出添加的类别词向量[1, 768],以ViT-B/16为例,在MLP Head中经过一个Linear层,再经过一个softmax层得到最终的类别。
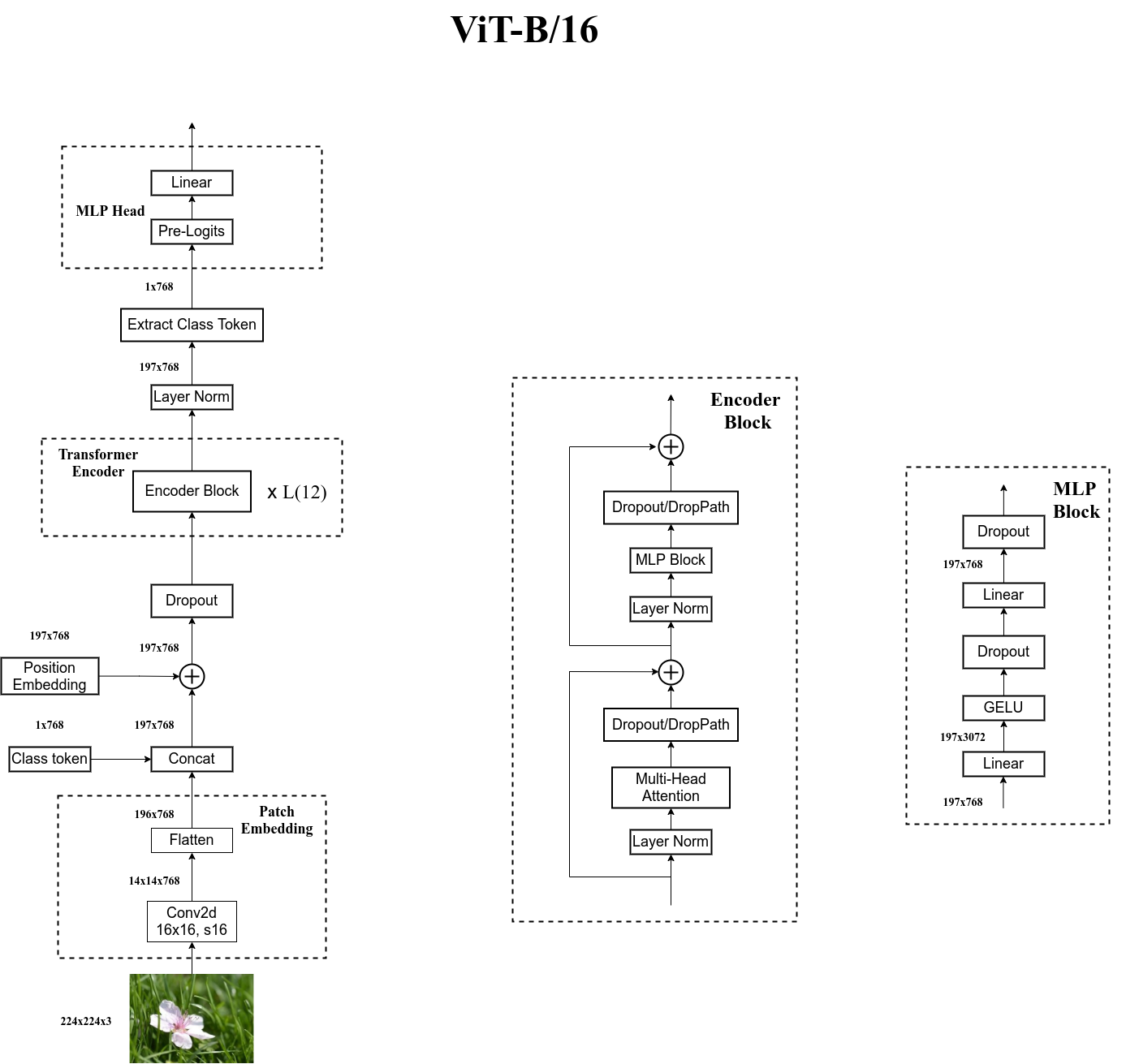
x.2 代码理解
代码实现的时候:
-
∗
*
∗在Embedding时,我们使用的是Conv2d的卷积层将
[224, 224, 3]的图片卷积成[14, 14, 768]的patch,再经过展平,变成[196, 768]的token。 - 在传入Transformer Encoder前进行了dropout层
- 在Transformer的Encoder Block层中进行了dropout;且在第二个sub-block中的MLP block中增加了GELU激活函数。
- 在传出Transformer Encoder后还进行了一次LN处理。
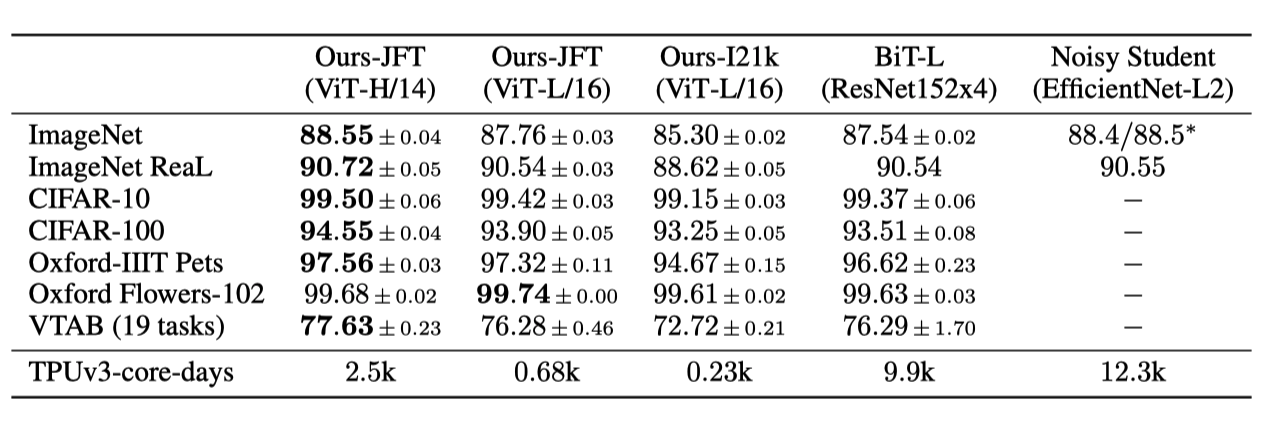
最终在ViT中采用了3中不同的网络结构,得到的模型效果如下:
备注说明 ...赞
踩

