
- 1计算机网络的性能指标(速率、带宽、吞吐量、时延、往返时延、时延带宽积、信道利用率)...
- 2(三)基于arm64/aarch64架构的Debian Linux中mysql5.7+详细安装过程_aarch mysql5.7
- 3写写k8s的四种service类型和使用场景_k8sservice4种模式
- 4KEIL编译器【C语言编译选项优化等级说明】【支持C99(变量声明在执行语句之后)】【反汇编设置】【C语言联合汇编】【use microlib选项】_keil use microlib
- 5DaZeng:web页面使用markdown编辑器组件_markdown web
- 6【多线程编程学习笔记4】终止线程执行的3种方法(pthread_exit()、pthread_cancel()、return)_c语言终止线程
- 7华为鸿蒙系统需要谷歌的服务器吗,如果谷歌服务不能用,华为P40或用鸿蒙!
- 8nginx通用日志采集工具将数据落地磁盘的同时传入kafka_nginx本地和日志服务器同时采集日志
- 9在CMD中无法运行python_py -0p,在cmd上无法运行
- 10ActiveMQ与Zookeeper高可用集群_dzookeeper和mq的关系
Towards Interpretable Video Anomaly Detection 论文阅读
赞
踩
论文题目:Towards Interpretable Video Anomaly Detection
文章信息:

发表于:WACV2023
原文链接:https://openaccess.thecvf.com/content/WACV2023/html/Doshi_Towards_Interpretable_Video_Anomaly_Detection_WACV_2023_paper.html
源代码:无
Abstract
我们提出了一种新颖的框架,可以解释监控视频中检测到的异常事件。大多数视频异常检测方法基于数据密集型的端到端训练的神经网络,这些网络从视频中提取时空特征。在这种方法中提取的特征表示不具有解释性,这阻碍了对异常原因的自动识别。为此,我们提出了一种新颖的框架,可以解释监控视频中检测到的异常事件。除了独立监测对象外,我们还监测它们之间的相互作用,以检测异常事件并解释其根本原因。具体来说,我们证明了通过监测对象相互作用获得的场景图提供了异常事件背景的解释,并且在性能上与最近的最新技术方法竞争力相当。此外,所提出的可解释方法实现了跨领域适应性(即在另一个监控场景中进行迁移学习),这对于大多数现有的端到端方法来说是不可行的,因为每个监控场景都缺乏足够的标记训练数据。所提出的方法的快速可靠的检测性能在理论上(通过渐近最优性证明)和经验上都进行了评估,应用了流行的基准数据集。
1. Introduction
随着闭路电视(CCTV)摄像头数量不断增加,以及随之而来的实时连续生成的视频数据量,人工操作员手动分析收集到的数据已变得低效且几乎不可能。特别是,实时检测事件的能力对于预防潜在灾难至关重要。因此,视频异常检测引起了越来越多的研究兴趣。最近的大多数方法依赖以黑盒方式提取的时空特征,这些特征具有有限的视觉可解释性,无法明确解释异常的上下文。
几乎所有现有算法都忽略了一个关键任务,即可解释的决策制定,其中模型能够准确解释异常的原因。视频异常检测的一个关键应用是在异常事件发生时采取适当的行动。然而,对异常事件的适当响应通常取决于其严重程度,而没有模型可解释性,很难准确评估其严重程度。例如,车祸可能需要立即处理,而行人简单地违章横穿马路则不需要。最近的视频异常检测方法提取视频中检测到的对象的外观和运动特征,并在学习到的标准数据模式发生变化时发出警报。然而,虽然对象及其相对运动是视频的核心构建模块,但通常是对象之间的关系定义了其整体解释。例如,一个由人和自行车组成的视频可能涉及人骑行、站在旁边,甚至是携带自行车。与现有方法不同,我们在此重点关注对象之间的相互作用,除了独立监测对象外。
另一个关键观察是,通常活动在语义上彼此相关,但尚未有任何现有视频异常检测方法利用语义信息。例如,“骑自行车的人”和“骑滑板的人”在语义上是相似的,因此即使对于一个类别没有足够的训练数据,我们也应该能够从语义相关的类别中推断出来。同样,现有方法无法执行跨领域适应性,即在一个监控场景上训练的模型能够在完全新的场景中实现具有竞争力的性能,而几乎不需要额外的训练数据,或者只需要很少的额外训练数据。虽然[24]中讨论了类似的任务,但所提出的方法仍然需要来自新场景的一些训练数据,以使用元学习微调其模型。这种方法并不总是可行的,因为它需要人工操作员手动收集一组具有代表性的正常帧,其中还包括与监控场景相关的新活动。另一方面,人类能够解释异常的原因,并将学到的知识适应不同的场景。我们相信,理解不同对象之间的关系多样性对于可解释性和跨领域适应性至关重要。
近年来,场景图由于其可解释性和在不同任务中的泛化能力,在图像处理领域引起了越来越多的研究关注。具体来说,场景图结合了计算机视觉和自然语言处理,生成了图像的视觉图形表示,其中节点表示对象,边表示它们之间的关系。在本文中,我们旨在通过监测每个对象以及它们与场景中其他对象的交互来解决可解释性和跨领域适应性的挑战。本文的贡献可以总结如下:
- 我们提出了一种新的可解释的方法,使用场景图的视频异常检测。
- 我们提出了一种新的基于语义嵌入的方法,用于使用深度度量学习进行视频异常检测,从而显着降低了内存和计算需求。
- 我们使用公开的数据集广泛评估了我们提出的方法,并表明除了可解释性和跨域适应性之外,它还具有竞争力。
2. Related Work
对视频中的异常检测进行了多年的广泛研究。早期的方法主要集中在使用手工制作的运动特征,例如定向梯度直方图(HOGs)[2, 3, 20],隐马尔可夫模型(HMMs)[18, 16],稀疏编码[47, 27]和外观特征[4, 20]。然而,近期的方法完全被深度学习算法所主导。最近的算法可以大致分为基于重建的方法[13, 15, 26, 29, 30],试图根据重建误差对帧进行分类,和基于预测的方法[22, 19, 7, 9],试图通过使用生成对抗网络(GANs)[14]来预测未来的帧。最近,一些基于骨骼轨迹的方法[28, 33]被提出,因为基准数据集中的大部分异常涉及异常的人体姿势。在这些算法中,通常使用RNN架构来学习正常的姿势,并在测试期间使用估计误差来检测异常程度。除了这些方法,[32]提出了使用孪生网络学习时空补丁并利用补丁之间的不相似性来检测异常。虽然这些方法在流行的基准数据集上表现竞争力,但它们完全依赖于复杂的神经网络,并且主要是端到端训练的。这限制了它们的可解释性,并使它们在新数据上训练变得非常困难,这在复杂的顺序应用程序(如视频异常检测)中是至关重要的。此外,这些方法适应不同正常基线的过程并不清晰。
最近,已经提出了几种面向图像和语言相关任务的视觉关系理解方法。几种方法[23, 48, 41, 5, 39, 37]采用的常见方法是使用现成的检测器来检测感兴趣的对象,然后将第二步视为一个分类任务[23, 48, 41, 5, 39, 38, 21, 36, 40, 42, 44, 45, 46],该任务接受对象对的特征并输出它们关系的标签。就视频异常检测而言,据我们所知,我们是第一个提出基于视觉关系理解的方法。
3. Proposed Technique
3.1. Overall Structure
在现有的视频异常检测文献中,唯一的目标是检测相对于训练数据而言不符合预期的帧。大多数检测器在一批视频帧上训练一个基于重建或预测的深度学习模型,通常以端到端的方式学习正常外观或运动特征。然而,我们认为对于一般的视频监控来说,这样的设置并不是最优的,因为学习到的视觉嵌入极大地依赖于诸如照明、视角变化、遮挡等条件。此外,由于端到端训练的神经网络的黑盒特性,这些模型是不可解释的。此外,标准框架隐含地假设在将检测器部署到目标场景时,对每种活动都有足够的训练数据可用[24]。这样的假设要求人工手动标注每个场景的数小时的视频,以生成一个无异常的训练数据集,这远非理想。由于人类以活动的形式感知视觉环境,我们认为从语义上学习视频活动比存储整个帧缓冲区或学习高维度视觉嵌入更自然、更高效。
受到这些缺点的启发,我们提出了一种用于检测视频异常的新型双监测方法。所提出的方法包括两个监测分支,即全局对象监测和局部对象监测,然后是顺序异常检测(图1)。
全局对象监测分支专门观察场景中不同对象之间的交互并生成场景图,
而局部对象监测分支独立监测视频中的每个人。
最后,顺序异常检测模块监测两个对象监测模块的统计信息,以快速可靠地检测异常事件。在接下来的部分中,我们详细讨论我们提出的框架。
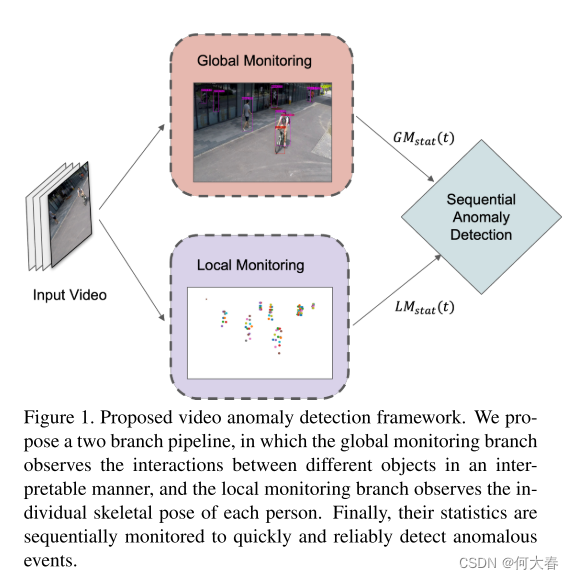
图1. 提出的视频异常检测框架。我们提出了一个两个分支的流程,其中全局监测分支以可解释的方式观察不同对象之间的交互,而局部监测分支观察每个人的个体骨骼姿势。最后,它们的统计数据被顺序监测,以快速可靠地检测异常事件。
3.2. Global Object Monitoring
我们旨在捕捉并监视监控视频中对象对之间的交互(图2)。与[46, 43, 23]类似,我们提出了一种视觉语义方法,通过场景图检测对象对之间的交互。场景图由对象作为图顶点和谓词(即,将两个对象联系起来的词,如动词)作为图边组成。交互检测网络是以全监督方式使用VRD数据集[23]进行训练的,该数据集包含一组带有对象和关系注释的图像。然后,通过将其与视频监控的标准训练数据集中的检测到的交互进行比较(例如,ShanghaiTech数据集[26]),监视每个检测到的交互以查找可能的异常。输出
G
M
s
t
a
t
(
t
)
GM_{stat}(t)
GMstat(t)是一个标量,表示帧t中的交互与标准交互之间的语义距离。
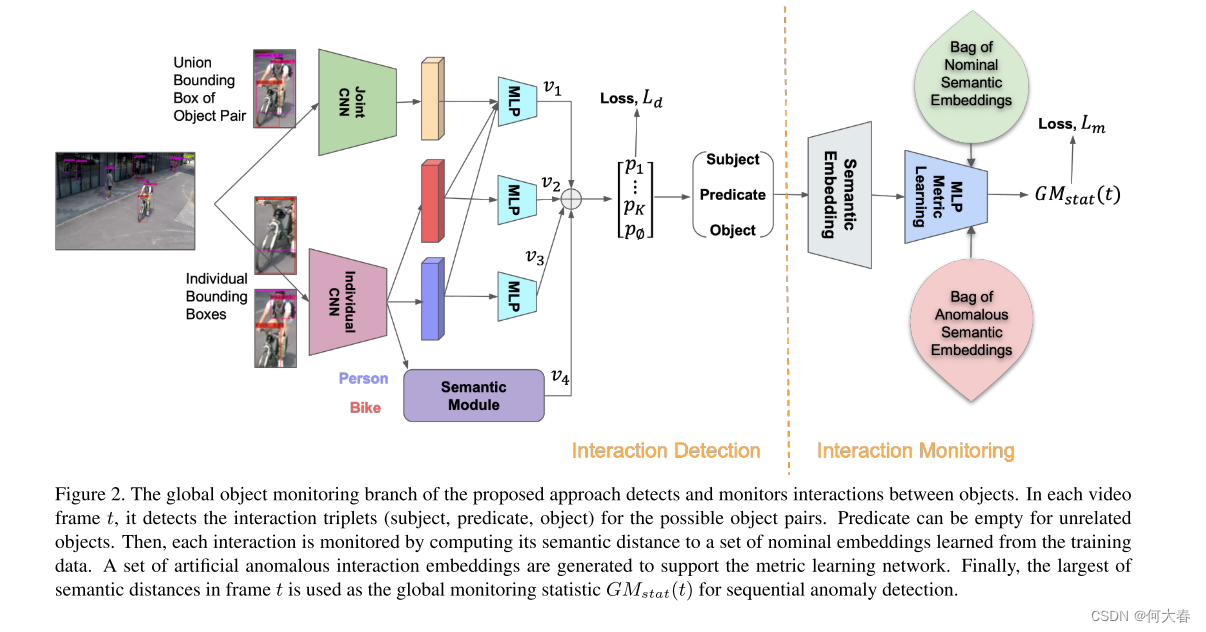
Interaction Detection:
如图2所示,所提出的方法首先检测每帧中的边界框,然后对它们进行成对处理。使用卷积神经网络(CNN)分别从每个边界框中提取个体外观特征(个体CNN)。同时,另一个CNN处理边界框的并集以提取联合外观特征(联合CNN)。联合和个体外观特征被连接起来,并通过多层感知器(MLP)传递,以获得每个谓词类别在VRD数据集中的评分向量
v
1
v_1
v1,以及无谓词类别。类似地,个体外观特征由两个MLP处理,以获得两个
(
K
+
1
)
(K + 1)
(K+1)维评分向量
v
2
v_2
v2和
v
3
v_3
v3,其中
K
K
K表示谓词类别的数量。语义模块提供另一个评分向量
v
4
v_4
v4,该模块从个体CNN中获取对象标签(例如,人和自行车),并使用带注释的训练数据中考虑的主客体对的谓词类别的经验概率{
q
i
,
.
.
.
,
q
K
,
q
∅
q_i,...,q_K,q_∅
qi,...,qK,q∅}输出每个谓词类别i的分数
l
o
g
(
q
i
/
q
∅
)
log(qi/q∅)
log(qi/q∅)。这些先验概率为谓词预测提供了基线知识。从启发式的角度来看,两个对象之间的可能组合通常是有限的。例如,人-自行车对之间的关系通常是“骑”或“在”,而不会是“吃”或“穿”。因此,这使我们能够生成经验分布
q
i
q_i
qi =
P
(
p
r
e
d
P(pred
P(pred
i
∣
s
u
b
,
o
b
j
)
i | sub,obj)
i∣sub,obj)。交互检测的最后一步是将四个评分向量
v
=
v
1
+
v
2
+
v
3
+
v
4
v = v_1 + v_2 + v_3 + v_4
v=v1+v2+v3+v4相加,并应用softmax函数来计算谓词类别概率。
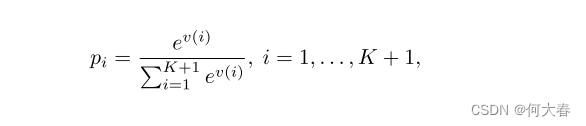
其中 v ( i ) v(i) v(i)是向量 v v v的第 i i i个元素。
为了训练谓词检测/分类网络,我们采用了著名的交叉熵损失和对比损失[46]的增强,以实现更快的收敛,对于每个主体和客体,对比损失旨在最大化与相关对象的最低亲和力和与不相关对象的最高亲和力之间的边界:
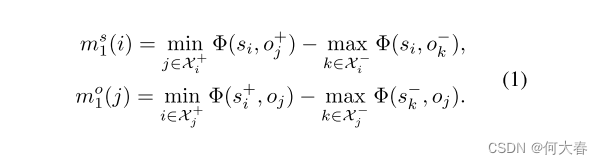
对于主体
s
i
s_i
si,
χ
i
+
\chi^+_i
χi+和
χ
i
−
\chi^-_i
χi−分别表示相关和不相关对象的集合。类似地,对于对象
o
j
o_j
oj,
χ
j
+
\chi^+_j
χj+和
χ
j
−
\chi^-_j
χj−被定义为相关和不相关主体的集合。这些集合是从训练集中预先确定的
Φ
(
s
,
o
)
=
1
−
p
∅
Φ(s, o) = 1 - p_∅
Φ(s,o)=1−p∅是主体s和对象o之间的亲和力,表示主体-对象对之间的互动概率。在使用VRD数据集进行训练时,对于每个具有M个边界框的图像,考虑所有
N
=
M
(
M
−
1
)
N = M(M−1)
N=M(M−1)个主体-对象对,计算并通过产生
v
1
、
v
2
、
v
3
v_1、v_2、v_3
v1、v2、v3以及联合CNN1的MLPs进行反向传播的以下损失:
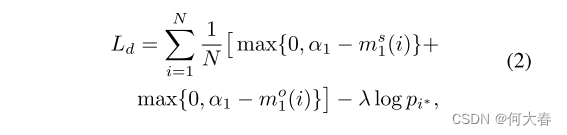
其中,
α
1
α1
α1是边界阈值,低于该阈值的边界会产生损失,
λ
λ
λ有助于将交叉熵损失与对比损失相结合,
i
∗
i^∗
i∗ ∈ {
1
,
.
.
.
,
K
+
1
1, . . . ,K+1
1,...,K+1}表示实际的谓词类别。通过最小化这个损失函数,网络被训练为选择正确的谓词类别,同时最大化相关主体-对象对之间的亲和力,并最小化不相关对之间的亲和力。
Interaction Monitoring:
对于每个帧t中检测到的每个交互
i
i
i,具有最高概率谓词类别的(主体,谓词,对象)三元组被监视以寻找可能的异常证据。首先,使用语义嵌入网络(例如Word2Vec模型)将单词三元组映射到数字向量。经验上,发现300维的嵌入是有用的。然后,三个嵌入的平均值
a
t
i
a^i_t
ati被输入到一个MLP进行度量学习。度量学习的目标是从交互嵌入中提取异常缺失/存在信息。为此,我们使用另一个对比损失,该损失最小化标准嵌入的欧氏距离,并最大化标准和异常嵌入之间的距离。记度量学习嵌入为
g
(
⋅
)
g(·)
g(⋅),目标是最小化
∥
g
(
a
t
i
)
−
g
(
p
)
∥
∥g(a^i_t)−g(p)∥
∥g(ati)−g(p)∥并最大化
∥
g
(
a
t
i
)
−
g
(
n
)
∥
∥g(a^i_t)−g(n)∥
∥g(ati)−g(n)∥,其中
a
t
i
a^i_t
ati,
p
p
p,
n
n
n分别表示锚点、正例和负例的语义嵌入向量。虽然正例(即交互三元组)
p
p
p是从标准训练集中随机选择的,但负例是从人为生成的异常交互三元组集中随机抽样的,例如,人打人。请注意,生成异常(主体,谓词,对象)三元组是一项简单的任务,不需要实际的异常视频。在训练期间,只使用标准实例作为锚点,以使度量学习MLP通过损失函数学习将标准语义嵌入相互靠近,并远离异常实例。
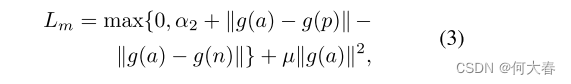
其中,
α
2
α_2
α2充当标准实例与异常实例之间距离的期望边界。
µ
µ
µ有助于将对比损失与L2正则化器相结合,该正则化器确保在训练过程中对标准(正)实例的嵌入较小。
在测试过程中,期望是当检测到的交互是正常的时候,锚定实例的嵌入
g
(
a
t
i
)
g(a^i_t)
g(ati)会与
g
(
p
)
g(p)
g(p)类似地很小,当交互是异常的时候,它会在统计上大于
g
(
p
)
g(p)
g(p)。我们使用一个标量嵌入
g
(
a
t
i
)
∈
R
g(a^i_t) ∈ R
g(ati)∈R,并将在帧中所有检测到的交互中最大的嵌入作为该帧中用于异常检测的全局监控统计量。
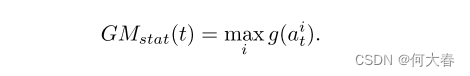
3.3. Local Object Monitoring
为了研究视频中的社会行为,密切观察人类运动是很重要的。对于汽车、卡车、自行车等无生命的物体,监控光流就足以判断它们是否表现出某种异常行为。然而,对于人类来说,我们还需要监视他们的姿势,以确定一个动作是否异常。因此,建议使用预训练的多人姿势估计器,如AlphaPose [10],来提取骨架轨迹。在时间t的每个帧中,姿势 i i i由图像坐标中的一组关节位置表示,即 θ t i = ( x t i , y t i ) i = 1 , . . . , J θ^i_t = {(x^i_t, y^i_t)}_{i=1,...,J} θti=(xti,yti)i=1,...,J,其中 J J J是姿势关节的数量。
然而,由于视角变化和遮挡等波动条件的影响,提取的骨架运动首先需要进行规范化。这可以分为两类,全局身体运动和局部身体姿势。具体而言,全局身体运动描述了姿势在环境中的配置,而局部姿势描述了姿势的变形,不考虑其在环境中的位置。由于在二维图像坐标中缺少深度信息,因此利用边界框的形状来规范化全局姿势组件,如下所示:
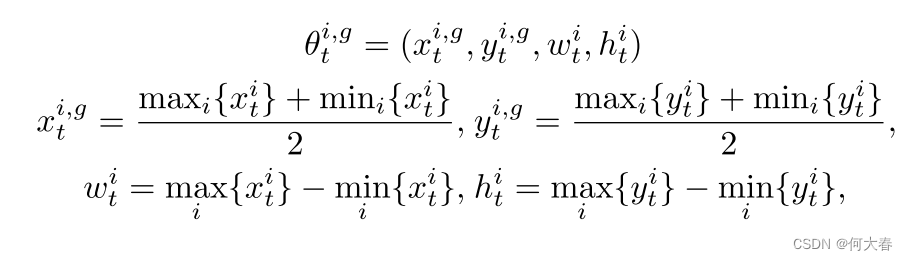
然后将局部分量归一化为
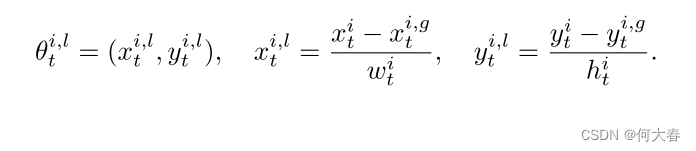
受最近提出的基于门控循环单元(GRU)的模型——称为消息传递编码器-解码器循环神经网络[28]的启发,我们提出了图3中所示的局部监测分支,其中编码器和解码器网络都被分为两个GRU分支。一个GRU分支处理全局特征,另一个处理局部特征。
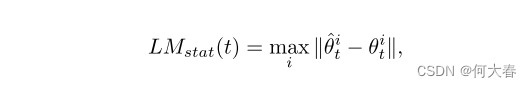
对于训练中的帧,重构误差的大小将与训练中的重构误差相似,而对于异常帧,它将在统计上大于标准重构误差。
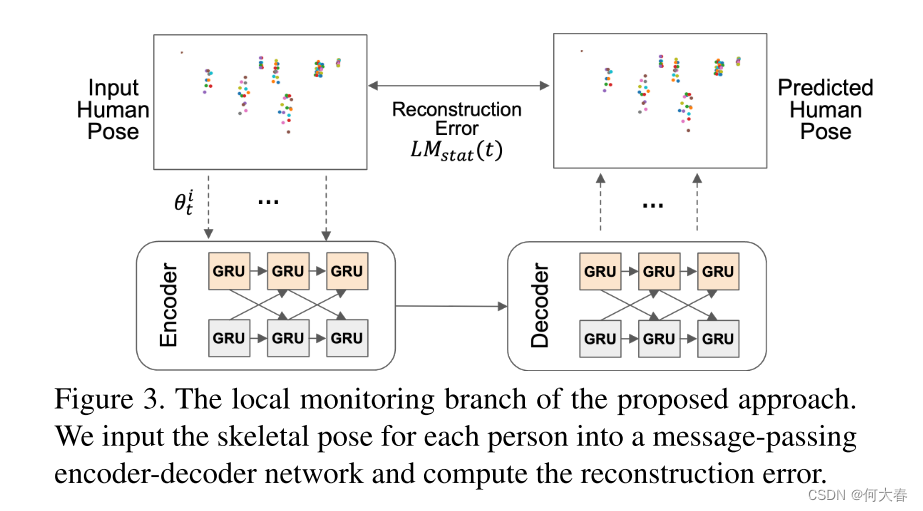
图3. 所提方法的局部监测分支。我们将每个人的骨架姿势输入到一个消息传递编码器-解码器网络中,并计算重构误差。
3.4. Sequential Anomaly Detection
来自每个帧
t
t
t的全局和局部监测统计数据被合并为
z
t
=
[
G
M
s
t
a
t
(
t
)
,
L
M
s
t
a
t
(
t
)
]
z_t = [GM_{stat}(t), LM_{stat}(t)]
zt=[GMstat(t),LMstat(t)],并依次监视可能的异常(见图1)。检测到的对象-对象交互的最大语义距离
G
M
s
t
a
t
(
t
)
GM_{stat}(t)
GMstat(t)和人体姿势的最大重构误差
L
M
s
t
a
t
(
t
)
LM_{stat}(t)
LMstat(t)都预计会取值与标准训练数据集相似,并在异常事件开始时增长。然而,通常情况下,由于几个因素的影响,例如标准和异常视频事件中固有的高方差以及特征提取流程的不完美性,确定标准和异常
z
t
z_t
zt值之间的分界线并不直观。此外,
z
t
z_t
zt中帧的瞬时异常统计数据可能会导致频繁的误报。由于异常真实世界事件在连续视频帧中展开的时间特性,我们考虑以下连续变化检测问题:
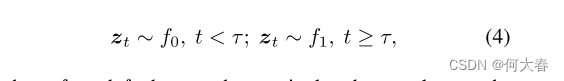
其中
f
0
f_0
f0和
f
1
f_1
f1表示标准和异常概率分布,
τ
τ
τ表示异常开始时间。
为了以序贯方式统计监视 z t z_t zt,我们测量其与标准训练集Z的欧氏距离。具体来说,计算 z t z_t zt到Z中第k个最近邻(kNN)的距离 d t d_t dt,并将其与标准基线 d α d_α dα进行比较,以量化帧 t t t中的任何异常证据。标准基线 d α d_α dα是在训练中获取的,作为与其他训练实例相对于彼此的kNN距离的 ( 1 − α ) (1−α) (1−α)百分位数,其中 α α α是统计显著水平,例如0.05。也就是说,对于Z中的每个训练 z z z向量,计算其与Z中其他向量的距离,并选择大于所有距离的 ( 1 − α ) (1−α)% (1−α)的距离作为 d α d_α dα。
在测试过程中,针对每个时间点t的向量
z
t
z_t
zt,所提出的算法计算即时的帧级异常证据
δ
t
δ_t
δt,如下所示:
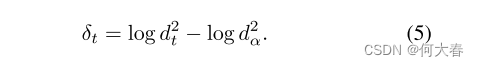
这种特定形式的
δ
t
δ_t
δt使得定理1中所呈现的渐近最优结果成为可能。最后,我们更新一个序贯决策统计量
s
t
s_t
st,如下所示:
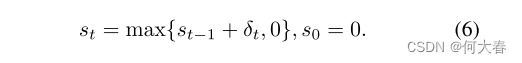
当决策统计量
s
t
s_t
st超过阈值h时,我们决定存在异常。
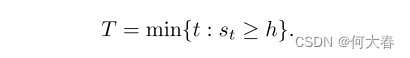
Theorem 1(定理1)
当标准分布
f
0
(
z
t
)
f_0(z_t)
f0(zt)是有限且连续的,而异常分布
f
1
(
z
t
)
f_1(z_t)
f1(zt)是均匀分布时,随着训练集的增长,决策统计量
δ
t
δ_t
δt在概率上收敛到对数似然比。
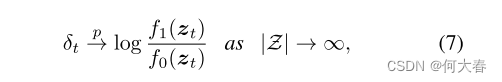
也就是说,所提出的数据驱动检测器收敛到CUSUM,在满足误报约束的同时,最小化预期检测延迟,这是最小化期望检测延迟的极小值最优解。

E
τ
E_τ
Eτ表示在时间
τ
τ
τ发生异常的情况下的期望,
(
.
)
+
(.)^+
(.)+ = max{., 0},
E
∞
E_∞
E∞表示在异常从未发生的情况下的期望,即
E
∞
[
T
]
E_∞[T]
E∞[T]是期望的误报周期。
证据在补充文件中提供。
3.5. Anomaly Interpretation
我们进行了深入的分析,以确定所提出的方法的哪个分支检测到异常。我们开始检查决策统计量 s t s_t st并确定哪个分支导致了增加。因此,在时间T处发出警报之后,我们
- 首先确定检验统计量 S t S_t St从上次为零开始增加的时刻 τ ^ \hat{τ} τ^,其可以被看作是异常开始时间的估计,
- 然后计算平均统计量
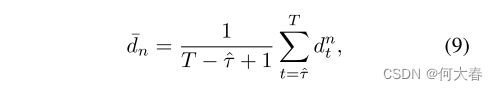
- 对于每个分支n ∈ {global,local},其中( d t g l o b a l d^{global}_t dtglobal) 2 ^2 2 +( d t l o c a l d^{local}_t dtlocal) 2 ^2 2 = d t 2 d^2_t dt2,
- 最后将 d ˉ g l o b a l \bar{d}_{global} dˉglobal和 d ˉ l o c a l \bar{d}_{local} dˉlocal与阈值 η η η进行比较,以确定异常源。
例如,如果我们将异常的源头检测为全局对象监控分支,那么这意味着异常是由两个对象之间的以前未见的交互引起的,并且在 [ τ ^ , T ] [\hat{τ}, T] [τ^,T]期间导致 G M s t a t ( t ) GM_{stat}(t) GMstat(t)变大的交互被提供为异常原因。如果异常的源头是本地对象监控分支,那么这意味着异常是由异常的人类动作引起的。在训练过程中,我们从一个人的轨迹中提取固定长度的段,并将它们分成局部和全局特征,然后将它们输入到提出的模型中。
3.6. Implementation Details
我们使用在MS-COCO数据集上预训练的YOLO-v4目标检测模型来在全局监控分支中生成边界框。为了简化起见,目标检测模型没有在VRD数据集上进行微调。我们使用VGG-16作为个体CNN模型来提取外观特征。它在MS-COCO数据集上预先训练,然后在端到端的方式上对VRD数据集进行微调。联合CNN模型也是一个VGG-16模型,它使用个体CNN模型的权重进行初始化。在使用VRD数据集训练联合CNN模型时,我们遵循[46],独立地对相关和不相关的对进行采样。具体来说,我们采样128个主体/对象,然后对于每个主体/对象,根据公式(1)选择相关和不相关的对象/主体。模型使用学习率为0.001和Adam优化器进行训练。在推断过程中,我们对每个对象对进行排名关系提议,方法是将预测的主体、对象、谓词概率相乘。交互检测模型中的MLP具有两个全连接层。在交互监测部分,使用Word2Vec方法进行语义嵌入。度量学习的MLP具有三个全连接层。我们使用AlphaPose[10]从视频中提取姿势信息,并使用PoseFlow跟踪它们在视频中的变化。在连续异常检测算法中,使用最近邻(k = 1),以及显著水平α = 0.05。所提出的框架概述如算法1所总结。

4. Experiments
在本节中,我们评估了所提方法在解释性、在线异常检测、异常帧定位和跨领域适应性方面在两个基准数据集上的性能。我们考虑了两个公开可用的基准数据集,即香港中文大学Avenue数据集和上海科技大学校园数据集。我们在评估中不考虑UCF-Crime数据集,因为它针对视频异常检测问题的不同表述。
4.1. Results
Interpretability:
为了展示我们所提出的方法的可解释性表现,我们首先手动为每个视频注释了根本原因。然而,对于每个异常活动,存在多种可能的谓词来解释。例如,在一个人骑自行车的情况下,“人在自行车上”和“人使用自行车”都是可能的解释。由于不可能手动注释所有这些可能的组合,我们使用Recall@k指标来评估可解释性表现。由于我们是第一个提出视频异常检测可解释模型的团队,因此无法将我们的性能与任何其他方法进行比较。该方法的定量性能如表1所示。
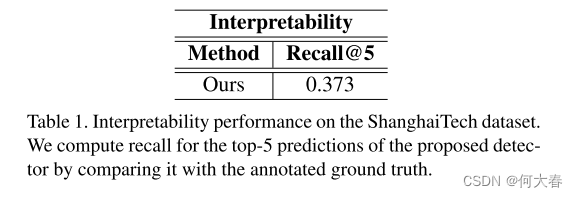
在图4中,我们展示了我们模型的定性表现。正如图中所示,所提出的方法能够解释和说明异常的真正原因。在中间列中,我们可视化了联合CNN的特征图,可以看到分类器能够学习两个对象之间的交互作用。另一方面,现有的方法只学习外观或运动特征,无法解释异常的对象交互。更多的定性分析可以在补充文件中找到。

Cross-Domain Adaptability:
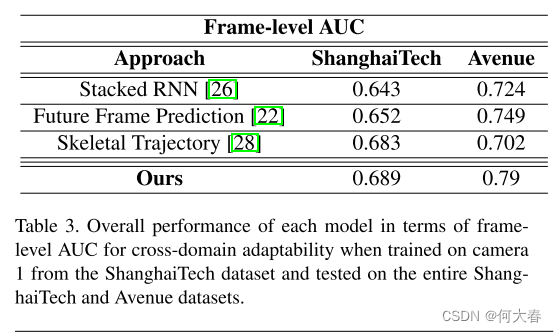
我们的目标是比较所提算法的跨领域场景适应能力,并了解它在新场景中的泛化能力。在这种情况下,我们仅在上海科技数据集中的单个摄像头(摄像头1)的训练视频上训练我们的模型,并在其余摄像头的测试视频以及Avenue数据集上评估其性能。跨领域场景适应大部分尚未被探索,据我们所知,只有[24]讨论了类似的少样本适应概念。然而,[24]中讨论的所提方法需要一些无异常的视频帧来使其模型适应新场景,这可能并不总是可行的。特别地,[24]中使用了类似于[22]的基于GAN的框架,并且使用MAML算法[11]进行元学习。正如表2和表3所示,考虑到零样本适应性,所提出的方法在帧级AUC方面能够胜过最先进的方法。在考虑的两个数据集中,被视为异常的行为相似,这满足了我们的固有假设。由于文献中没有呈现零样本适应性的结果,我们将我们的性能与可用且适合零样本适应性的方法进行了比较。[24]中的少样本适应方法需要视频来适应新场景,因此不适合零样本适应。

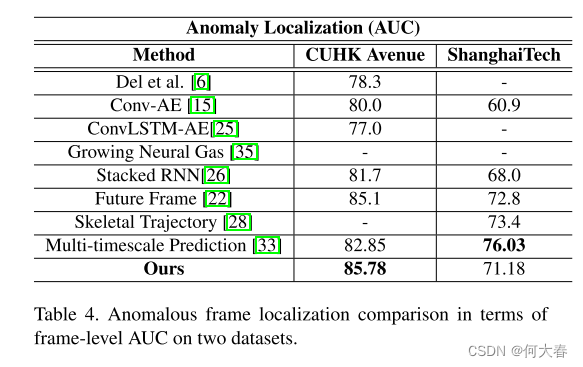
Anomalous Frame Localization:
为了展示我们算法的异常定位能力,我们还使用常用的帧级AUC准则将我们的算法与一系列最先进的方法进行了比较,如表4所示。像素级准则专注于异常的空间定位,可以通过简单的后处理技术等效于帧级准则。因此,对于异常定位,我们考虑帧级AUC准则。虽然[17]最近显示出与其他算法相比显著的增益,但他们计算整个数据集的平均AUC的方法使他们具有不公平的优势。具体来说,与确定连接视频上的AUC相反,首先计算了每个视频段的AUC,然后对这些AUC值进行了平均。如表4所示,我们提出的算法在香港中文大学Avenue数据集上优于现有算法,并在上海科技数据集上表现竞争激烈。多时间尺度框架[33]是唯一在上海科技数据集上优于我们的方法的算法,因为异常主要是由以前未见的人体姿势引起的,而[33]通过基于过去-未来轨迹预测的框架对其进行了广泛的监测。
5. Conclusion
针对视频异常检测,我们提出了一个可解释的框架,同时具有零样本跨领域适应性。我们提出了一个双分支流水线,监测视频中的局部和全局活动。全局分支观察不同对象之间的交互作用,而本地分支观察人类行为。一个顺序检测器在统计上监测两个分支是否存在异常,并在检测到异常时确定异常的根本原因,提供可解释性。所提出的顺序检测器的渐近最优性是在最小极小化平均检测延迟的意义上推导出来的,同时控制假警报率。通过在基准数据集上的广泛测试,我们展示了所提出的方法能够解释检测到的异常的原因,并在跨领域适应性方面明显优于最先进的方法。

