- 1【华为OD机试真题 C语言】426、部门人力分配 | 机试真题+思路参考+代码解析(C卷)(未)
- 2Immunity Canvas 7.26 Windows安装踩坑_immunity canvas kali
- 3三分钟明白zookeeper集群中的三种角色Leader、Follower和observer_zookeeper集群中的角色有哪些?有什么区别?
- 4FFmpeg常用命令汇总_ffmpeg指令集
- 5【论文阅读】2018-基于深度学习的网络流量分类及异常检测方法研究_王伟
- 6带你操作RabbitMQ管理界面,用完不想敲命令了_rabbitmq界面
- 7@Component,@service,@autowired等注解的实现原理_@service原理
- 8objc - NSString Category实现+initialize导致EXC_BAD_ACCESS_objc category 的方法闪退
- 9LabVIEW鸡蛋品质智能分级系统
- 10gradio初体验_gradio网站增加用户登录和注册页面
云架构师学习------腾讯云通识-存储与数据库_10t对象存储 20t云硬盘可以满足
赞
踩
云架构师学习------腾讯云通识-存储与数据库
云架构师学习------腾讯云通识-存储与数据库
腾讯云通识-存储与数据库
存储
基础存储服务
对象存储-COS
产品概述
对象存储(Cloud Object Storage,COS)是腾讯云提供的一种存储海量文件的分布式存储服务,用户可通过网络随时存储和查看数据。腾讯云 COS 使所有用户都能使用具备高扩展性、低成本、可靠和安全的数据存储服务。
COS 通过控制台、API、SDK 和工具等多样化方式简单、快速地接入,实现了海量数据存储和管理。通过 COS 可以进行任意格式文件的上传、下载和管理。腾讯云提供了直观的 Web 管理界面,同时遍布全国范围的 CDN/EdgeOne 节点可以对文件下载进行加速。
基本概念
下面通过几个名词概念,帮助您进一步了解腾讯云 COS:
· 存储桶(Bucket) :是对象的载体,可理解为存放对象的“容器”。一个存储桶可容纳无数个对象。
· 对象(Object):是 COS 的基本单元,可理解为任何格式类型的数据,例如图片、文档和音视频文件等。
· 地域(Region):是腾讯云托管机房的分布地区,COS 的数据存放在这些地域的存储桶中。
· 多 AZ(Multiple Availability Zones) :是由腾讯云对象存储推出的多 AZ 存储架构。客户数据分散存储在城市中多个不同的数据中心,当某个数据中心因为自然灾害、断电等极端情况导致整体故障时,多 AZ 存储架构依然可以为客户提供稳定可靠的存储服务。
· 访问域名(Endpoint):对象被存放到存储桶中,用户可通过访问域名访问和下载对象。
· 存储类型(StorageClass):指对象在 COS 中的存储级别和活跃程度。COS 提供多种存储类型:标准存储(多 AZ)、低频存储(多 AZ)、智能分层存储(多 AZ)、智能分层存储、标准存储、低频存储、归档存储、深度归档存储。每种存储类型适用于不同的业务场景,拥有不同的特性(例如对象访问频度、访问时延等)。关于不同存储类型的详细介绍,请参见 存储类型概述。
功能概览
1)操作
| 功能 | 说明 |
|---|---|
| 存储桶操作 | 支持创建、查询、删除、清空存储桶,具体操作请参见存储桶管理目录下的文档,例如 创建存储桶。 |
| 对象操作 | 多种存储类型:根据访问频度的高低和容灾程度高低,COS 提供多种对象的存储类型,包括标准存储(多 AZ)、低频存储(多 AZ)、智能分层存储、标准存储、低频存储、归档存储和深度归档存储,详情请参见 存储类型。对象/文件夹:上传、查询、下载、复制和删除操作,具体操作请参见对象管理目录下的文档,例如 上传对象。 |
2)数据管理
| 功能 | 说明 |
|---|---|
| 生命周期 | COS 支持给对象设置生命周期规则,定期对指定对象进行自动删除或转换存储类型 |
| 静态网站 | 将存储桶配置成静态网站托管模式,并通过存储桶域名访问该静态网站 |
| 清单 | COS 可根据用户的清单任务配置,每天或者每周定时扫描用户存储桶内指定的对象或拥有相同对象前缀的对象,并输出一份清单报告,以 CSV 格式的文件存储到用户指定的存储桶中 |
| 存储桶标签 | 存储桶标签可以作为管理存储桶的一个标识,便于用户对存储桶进行分组管理。用户可以对指定的存储桶进行标签的设定、查询和删除操作 |
| 事件通知 | COS 结合云函数 SCF(Serverless Cloud Function)实现当 COS 资源发生变动(例如新文件上传、文件删除)时,用户可以及时接收通知消息 |
| 数据检索 | COS Select 功能通过结构化查询语句(SQL)筛选存储在 COS 上的对象,以便检索对象并获取用户所需的数据。通过 COS Select 功能筛选对象数据,用户可以减少 COS 传输的数据量,这将降低检索此数据所需的成本和延迟 |
| 日志管理 | 日志管理功能可以记录指定源存储桶的详细访问信息,并将这些信息以日志文件的形式保存在指定的存储桶中,以实现对存储桶更好的管理 |
| 对象标签 | 对象标签功能的实现是通过为对象添加一个键值对形式的标识,协助用户分组管理存储桶中的对象。对象标签由标签的键(tagKey)和标签的值(tagValue)与=相连组成,例如 group = IT。用户可以对指定的对象进行标签的设定、查询、删除操作 |
| 存储网关 | 存储网关是腾讯云提供的混合云存储服务。您可以选择为存储桶配置存储网关,配置完成后,COS 中的存储桶可以以网络文件夹的形式挂载至您任意一台 CVM 服务器上作为存储设备进行使用 |
3)异地容灾
| 功能 | 说明 |
|---|---|
| 版本控制 | 版本控制用于实现在相同存储桶中存放同一对象的多个版本。用户在为某一存储桶开启版本控制功能后,可以根据版本 ID 检索、删除或还原存放在存储桶中的对象。这有助于恢复被用户误删或应用程序故障而丢失的数据 |
| 存储桶复制 | 用户可以通过配置存储桶复制规则,在不同存储桶中自动、异步地复制增量对象,实现数据的容灾与备份 |
| 多 AZ 特性 | COS 推出多 AZ 存储架构,这一存储架构能够为用户数据提供数据中心级别的容灾能力 |
4)数据安全
| 功能 | 说明 |
|---|---|
| 加密 | COS 在数据写入数据中心内的磁盘之前,支持在对象级别上应用数据加密的保护策略,并在访问数据时自动解密,详情请参见 服务端加密概述 和 存储桶加密概述。 |
| 防盗链 | COS 支持防盗链配置,用户可以通过控制台的防盗链功能配置黑/白名单,对数据资源进行安全防护 |
5)访问管理
| 功能 | 说明 |
|---|---|
| 跨域访问 | COS 提供 HTML5 标准中的跨域访问设置,帮助实现跨域访问。针对跨域访问,COS 支持响应 OPTIONS 请求,并根据开发者设定的规则向浏览器返回具体设置的规则 |
| 回源功能 | 对存储桶设置回源规则,当用户请求的对象在存储桶中不存在或者需要对特定的请求进行重定向时,用户可以通过回源规则从 COS 访问到对应的数据 |
| 存储桶策略 | 用户可以为存储桶添加策略,可实现允许或禁止某个账号、某个来源 IP(或 IP 段)访问 COS 资源 |
| 访问控制 | 用户可以对存储桶和对象的访问权限进行管理,当收到某个资源的请求时,COS 将检查相应的 ACL 以验证请求者是否拥有所需的访问权限 |
6)访问速率
| 功能 | 说明 |
|---|---|
| CDN 加速 | COS 结合 CDN/EdgeOne 加速服务,可将存储桶中的内容进行大范围的下载、分发,特别适用于相同内容反复下载的使用场景 |
| 全球加速 | COS 的全球加速功能,可帮助全球各地用户快速访问您的存储桶,提升您的业务访问成功率,进一步保障您的业务稳定和提升您的业务体验 |
| 单链接限速 | COS 支持上传、下载文件时进行流量控制,以保证您其他应用的网络带宽 |
7)批量作业
| 功能 | 说明 |
|---|---|
| 批量处理 | 用户可以指定存储桶内的对象列表执行指定的操作。具体操作是通过清单功能生成一份对象清单作为指定的对象列表,或者将需要处理的对象依照清单文件的格式记录在一份 CSV 格式的文件中,COS 批量处理功能将根据这份对象清单文件进行批量处理 |
8)数据监控与告警
| 功能 | 说明 |
|---|---|
| 查看数据概览 | COS 提供存储数据的监控能力,您可通过监控数据窗口按照不同时间段查询不同存储类型数据的数据量及趋势 |
| 设置监控告警 | 您可以通过腾讯云可观测平台的告警策略来设置 COS 监控指标的阈值告警,告警策略包括名称、策略类型和告警触发条件、告警对象、告警通知模板五个必要组成部分 |
9)数据处理
| 功能 | 说明 |
|---|---|
| 图片处理 | COS 集成了数据万象(Cloud Infinite,CI)专业的一体化媒体解决方案,涵盖图片处理、审核、识别等功能。您可以通过 COS 的上传和处理接口来进行媒体数据的处理操作,此外还支持图片高级压缩和盲水印功能 |
| 媒体处理 | 媒体处理是 COS 基于数据万象推出的多媒体文件处理服务,涵盖音视频转码、视频截帧、音视频拼接、视频转动图、视频元信息获取等视频处理服务,以及结合腾讯云先进 AI 技术的智能封面高级处理服务 |
| 文件处理 | 文件处理是 COS 基于数据万象推出的针对所有格式文件的处理服务,当前提供了文件的哈希值计算、文件解压缩和多文件打包压缩能力 |
| 文档预览 | 文档预览服务基于腾讯云数据万象,开启该功能后,存储桶中的文档类型文件即可在线预览无需下载,解决文档内容的页面展示问题 |
| 智能语音 | 智能语音服务基于腾讯云数据万象,开启之后,可进行语音合成、语音识别、音频降噪等操作 |
| 函数计算 | COS 支持对指定存储桶设置 CDN 缓存刷新 |
9)数据审核
| 功能 | 说明 |
|---|---|
| 内容审核 | 对象存储内容审核服务提供了图片、视频、语音、文本、文档、网页等多媒体的内容安全智能审核服务,可帮助用户有效识别色情低俗、暴力恐怖、违法违规、恶心反感等违禁内容,规避运营风险 |
10)应用集成
| 功能 | 说明 |
|---|---|
| 与其他云产品集成 | COS 基于云函数(Serverless Cloud Function,SCF)为用户提供数据库备份、消息备份、日志备份、日志分析、数据导出等功能 |
11)工具
| 功能 | 说明 |
|---|---|
| 多种管理工具 | COS 提供 COSBrowser、COSCMD、COSCLI、COS Migration 等多种实用工具,可方便用户进行数据管理或数据迁移 |
12)API/SDK
| 功能 | 说明 |
|---|---|
| 多种 API 和 SDK | API:COS 提供丰富的 API 接口,包括功能接口的使用方法和参数,提供请求示例、响应示例以及错误码介绍;COS 提供多种开发语言:Android、C、C++、.NET(C#)、Flutter、Go、iOS、Java、JavaScript、Node.js、PHP、Python、React Native、小程序 SDK |
产品优势
稳定持久
腾讯云对象存储(Cloud Object Storage,COS)提供数据跨多架构、多设备冗余存储,为用户数据提供异地容灾和资源隔离功能,为每一个对象实现高达99.9999999999%的数据持久性,保障您数据的耐久性高于其他存储架构。
安全可靠
COS 提供防盗链功能,可屏蔽恶意来源的访问;支持数据 SSL 加密传输,控制每个单独文件的读写权限。结合腾讯的攻击防御系统,能够有效抵御 DDoS 攻击、CC 攻击,保障您的业务正常运行。
成本最优
使用 COS,您无需传统硬件的采购、部署和运维,从而节省了运维工作和托管成本。COS 支持按需按量使用,您无需预先支付任何预留存储空间的费用,通过生命周期管理进行数据降冷,进一步降低成本。
简单易用
COS 提供图形化程序、命令行工具、协议工具等多种途径对存储对象进行批量操作,让使用更为简单。COS 还提供能够将存储桶挂载到本地的工具,让您能像使用本地文件系统一样直接操作。
接入便捷
COS 提供丰富的 SDK 接入工具,简单且可靠,详尽的 RESTful API 接入指南能够帮助您轻松通过 Internet 传输数据。COS 提供无缝迁移工具让您的业务快速上云,为您免除了高昂的迁移成本和接入成本。
服务集成
COS 支持与其他腾讯云产品联动,包括 CDN 加速、数据万象图片处理、音视频转码、文件预览等组件,提供「存储 + 处理」一体化解决方案。此外,COS 可作为大数据计算的数据池,为大数据分析与计算提供数据源;也可以结合云函数(Serverless Cloud Function,SCF)服务可以实现事件通知及自动处理。
云硬盘-CBS
云硬盘(Cloud Block Storage,CBS)为您提供用于云服务器的持久性数据块级存储服务。CBS 中的数据自动地在可用区内以多副本冗余方式存储,避免数据的单点故障风险,提供高达99.9999999%的数据可靠性。CBS 提供多种类型及规格的磁盘实例,支持在同可用区云服务器上挂载/卸载,并且可以在几分钟内调整存储容量,满足稳定延迟的存储性能及弹性的数据需求。您只需为所配置的资源量支付低廉的价格即可享受以上功能特性。
产品概述
什么是腾讯云云硬盘
云硬盘(Cloud Block Storage,CBS)是一种高可用、高可靠、低成本、可定制化的块存储设备,可以作为云服务器的独立可扩展硬盘使用,为云服务器实例提供高效可靠的存储能力。
云硬盘提供数据块级别的持久性存储能力,通常用作需要频繁更新、细粒度更新的数据(如文件系统、数据库等)的主存储设备,具有高可用、高可靠和高性能的特点。
云硬盘采用三副本的分布式机制,将您的数据备份在不同的物理机上,避免单点故障引起的数据丢失等问题,提高数据的可靠性。
您可以通过控制台轻松购买、调整以及管理您的云硬盘设备,并通过构建文件系统创建出高于单块云硬盘容量的存储空间。
根据生命周期的不同,云硬盘可以分为:
- 非弹性云硬盘
非弹性云硬盘的生命周期完全跟随云服务器,随云服务器一起购买并作为系统盘使用,不支持挂载与卸载。 - 弹性云硬盘
弹性云硬盘的生命周期独立于云服务器,可单独购买然后手动挂载至云服务器,也可随云服务器一起购买并自动挂载至该云服务器,作为数据盘使用。弹性云硬盘支持随时在同一可用区内的云服务器上挂载或卸载。您可以将多块弹性云硬盘挂载至同一个云服务器,也可以将弹性云硬盘从云服务器 A 中卸载然后挂载到云服务器 B。
腾讯云对用户的云硬盘配额有相应的限制
典型使用场景
- 云服务器在使用过程中发现硬盘空间不够,可以通过购买一块或多块云硬盘挂载至云服务器上满足存储容量需求。
- 购买云服务器时不需要额外的存储空间,有存储需求时再通过购买云硬盘扩展云服务器的存储容量。
- 在多个云服务器之间存在数据交换的诉求时,可以通过卸载云硬盘(数据盘)并重新挂载到其他云服务器上实现。
- 可以通过购买多块云硬盘并配置 LVM(Logical Volume Manager)逻辑卷来突破单块云硬盘存储容量上限。
- 可以通过购买多块云硬盘并配置 RAID(Redundant Array of Independent Disks)策略来突破单块云硬盘 I/O 能力上限。
产品功能
腾讯云提供多样化持久性存储设备,您可以灵活选择硬盘类型,并自行在硬盘上执行存储文件、搭建数据库等操作。
- 五种类型硬盘可供选择:高性能云硬盘、 通用型 SSD 云硬盘、SSD 云硬盘、增强型 SSD 云硬盘和极速型 SSD 云硬盘。
- 弹性挂载与卸载:所有类型的弹性云硬盘均支持弹性挂载、卸载,您可以在云服务器上挂载多块云硬盘搭建大容量的文件系统。
- 弹性扩容:您可以随时对云硬盘进行扩容,单块硬盘最大支持32TB。
- 快照备份:支持创建快照、快照回滚,及时备份、恢复关键数据,也支持使用快照创建硬盘,快速实现业务部署。
产品优势
可靠
云硬盘采用三副本的分布式机制,系统确认数据在三个副本中都完成写入后才会返回写入成功的响应。后台数据复制机制能在任何一个副本出现故障时迅速通过数据迁移等方式复制一个新副本,时刻确保有三个副本可用,为您提供安全放心的数据存储服务。数据跨机架存储,可靠性达99.9999999%。
弹性
您可以自由配置存储容量,按需扩容,且无需中断业务。
云硬盘容量上限为32TB,单台云服务器累计可挂载20个弹性云硬盘作为数据盘使用,高效应对 TB/PB 级数据的大数据处理场景,可满足大容量的文件系统要求,适用于大数据、数据仓库、日志处理等场景。
高性能
高性能云硬盘采用 Cache 机制满足用户常规业务需求。SSD 云硬盘采用 NVMe 标准 SSD,单块硬盘提供26,000随机读写 IOPS(Input/Output Operations per Second),适用于对 I/O 能力有极端要求的场景。
易用
通过简单的创建、挂载、卸载以及删除等操作即可轻松管理与使用您的云硬盘,缩短业务部署时间,节省成本。
快照备份
您可以随时通过创建快照的方式为云硬盘备份数据,也可以通过使用快照文件快速创建云硬盘达到快速部署业务的目的。
云硬盘类型
云硬盘是一种高可用、高可靠、低成本、可定制化的网络块设备,可作为云服务器的独立可扩展硬盘使用。它提供数据块级别的数据存储,采用三副本的分布式机制,为云服务器提供数据可靠性保证。云硬盘产品提供高性能云硬盘、通用型 SSD 云硬盘、SSD 云硬盘、增强型 SSD 云硬盘和极速型 SSD 云硬盘五种云硬盘类型,不同的硬盘类型、性能、特点和价格均不同,您可根据部署的应用要求自行选择。
云硬盘类型简介
- 高性能云硬盘
高性能云硬盘是腾讯云推出的混合型存储类型,通过 Cache 机制提供接近固态存储的高性能存储能力,同时采用三副本的分布式机制保障数据可靠性。高性能云硬盘适用于高数据可靠性要求、普通中度性能要求的 Web/App 服务器、业务逻辑处理、中小型建站等中小型应用场景。 - 通用型 SSD 云硬盘
通用型 SSD 云硬盘是腾讯云推出的入门级全闪类型块存储产品,具有高性价比的优势,适用于高数据可靠性要求、中等性能要求的 Web/App 服务器、业务逻辑处理、KV 服务、基础数据库服务等中型应用场景。 - SSD 云硬盘
SSD 云硬盘是腾讯云基于 NVMe SSD 存储介质提供的全闪型存储类型,采用三副本的分布式机制,提供低时延、较高随机 IOPS 和吞吐量的 I/O 能力及数据安全性高达99.9999999%的存储服务。SSD 云硬盘适用于对 I/O 性能有较高要求的场景。 - 增强型 SSD 云硬盘
增强型 SSD 云硬盘由腾讯云基于新一代存储引擎设计,基于全 NVMe SSD 存储介质和最新网络基础设施提供的产品类型,采用三副本的分布式机制,提供低时延、高随机 IOPS、高吞吐量的 I/O 能力及数据安全性高达99.9999999%的存储服务。增强型 SSD 云硬盘适用于对大型数据库、NoSQL 等对时延要求很高的 I/O 密集型场景。增强型 SSD 云硬盘独特性地支持性能与容量单独配置,您可以根据业务的实际情况配置需要的存储容量及存储性能。 - 极速型 SSD 云硬盘
极速型 SSD 云硬盘由腾讯云基于最新自研高性能分布式存储引擎,搭配高速网络基础设施及最新一代存储硬件,长期稳定地提供超低时延的可靠性能。非常适用于需要极低延迟的 IO 密集型和吞吐量密集型工作负载,例如大型 MySQL、HBase 和 Cassandra 等数据库业务,etcd 和 rocksdb 等键值存储,ElasticSearch 等日志检索业务,视频处理、直播等实时高带宽型业务。在关键交易工作负载、核心数据库业务、大型 OLTP 业务、视频处理等场景下表现优秀。极速型 SSD 云硬盘独特性地支持性能与容量单独配置,您可以根据业务的实际情况配置需要的存储容量及存储性能。
性能指标
不同类型云硬盘的性能指标分别为:

适用场景
-
增强型 SSD 云硬盘更适用于时延敏感型或密集型 I/O 的场景,例如:
高性能、高数据可靠性:适用于高负载、核心关键业务系统。提供三份数据冗余,具备完善的数据备份、快照、数据秒级恢复能力。
中大型数据库:可支持百万行表级别的 MySQL、Oracle、SQL Server、MongoDB 等中大型关系数据库应用。
大型 NoSQL:满足 HBase、Cassandra 等 NoSQL 业务对存储的性能要求。
ElasticSearch:满足 ES 对存储低时延的性能要求。
视频服务:满足音视频编解码、直播录播等场景对存储的带宽能力要求。
大数据分析: 提供针对 TB、PB 级数据的分布式处理能力,适用于数据分析、挖掘、商业智能等领域。 -
极速型 SSD 云硬盘适用于对时延有极致要求的时延敏感型的场景,例如:
KV 键值存储:如 rocksdb、容器 etcd 等,键值存储业务常以串行 I/O 模式落盘,对每个 I/O 处理速度及时延有非常严格的要求,单路时延决定了系统的整体性能。极速型 SSD 云硬盘提供最低至数十微秒的时延表现,十分适合对数据可靠性、可用性有要求的核心业务系统。
大型数据库:可支持百万行表级别的 MySQL、Oracle、SQL Server、MongoDB 等中大型关系数据库应用。
大型 NoSQL:满足 HBase、Cassandra 等 NoSQL 业务对存储的性能要求。
ElasticSearch:满足 ES 对存储低时延的性能要求。
视频服务:满足音视频编解码、直播录播等场景对存储的带宽能力要求。
核心业务系统:对数据可靠性要求高的 I/O 密集型等核心业务系统。
大数据分析: 提供针对 TB、PB 级数据的分布式处理能力,适用于数据分析、挖掘、商业智能等领域。
高性能、高数据可靠性: 适用于高负载、核心关键业务系统。提供三份数据冗余,具备完善的数据备份、快照、数据秒级恢复能力。 -
SSD 云硬盘更适用于大中型负载的场景,例如:
中型数据库:可支持 MySQL 等中大型关系数据库应用。
图像处理:可支持图像处理等数据分析存储业务。 -
通用型 SSD 云硬盘主要应用于以下数据场景:
适用于高数据可靠性要求、中等性能要求的 Web/App 服务器、业务逻辑处理、KV 服务、基础数据库服务等中型应用场景。 -
高性能云硬盘主要应用于以下数据场景:
适用于中小型数据库、Web/App 服务器等,提供长期的稳定 I/O 性能输出。
适用于企业办公业务等对存储容量和性能有平衡诉求的场景。
满足核心业务测试、开发联调环境的 I/O 需求。
文件存储-CFS
产品概述
文件存储(Cloud File Storage,CFS)提供了可扩展的共享文件存储服务,可与腾讯云的 CVM 、容器、批量计算等服务搭配使用。CFS 提供了标准的 NFS 及 CIFS/SMB 文件系统访问协议,为多个 CVM 实例或其他计算服务提供共享的数据源,支持弹性容量和性能的扩展,现有应用无需修改即可挂载使用,是一种高可用、高可靠的分布式文件系统,适合于大数据分析、媒体处理和内容管理等场景。
文件存储接入简单,您无需调节自身业务结构,或者是进行复杂的配置。只需三步即可完成文件系统的接入和使用:
创建文件系统,启动服务器上文件系统客户端,挂载创建的文件系统。
产品功能
集成管理
支持 NFS v3.0/v4.0,CIFS/SMB2.0/SMB2.5/SMB3.0 协议, 支持 POSIX 访问语义(例如强数据一致性和文件锁定),用户可以使用标准操作系统挂载命令来挂载文件系统。
自动拓展
支持根据文件容量大小自动扩展文件系统存储容量,扩展过程不会中断请求和应用,确保独享所需的存储资源,同时减少管理的工作和麻烦。
安全设置
具有极高的可用性和持久性,每个存储在 CFS 实例中的文件都会拥有3份冗余。支持 VPC 网络及基础网络、支持控制访问权限。
按需付费
按实际用量付费且无最低消费或前期部署及后期运维费用。多个 CVM 可以通过 NFS 或 CIFS/SMB 协议共享同一个存储空间,无需重复购买其他的存储服务,也无需考虑缓存。
产品优势
简单易用
腾讯云计算资源可以通过 SMB/NFS/私有协议来挂载不同的文件存储(Cloud File Storage,CFS),并通过 POSIX 指令,像访问本地硬盘一样,访问 CFS。
CFS 提供控制台界面,让您可以轻松快捷地创建和配置文件系统,节省部署时间和降低维护文件系统工作量。
灵活扩展
CFS 可以根据您的需求灵活扩展,在扩容过程中不中断请求和应用,确保整体业务的连续性,同时降低管理工作的时间成本,减轻工作量。
CFS 单命名空间可以提供 PB 级的存储容量,相比于自建 NAS、云硬盘等存储方式,能支持更大规模的数据存储。
安全可靠
CFS 采用三副本的分布式存储机制、具有极高的可靠性。系统确认数据在三个副本中都完成写入后,才会返回写入成功的响应;后台数据复制机制能在任何一个副本出现故障时,迅速通过数据迁移等方式复制一个新副本,时刻确保有三个副本可用,同时接入层保证高效的 HA 机制,整体可靠性达99.9999999%(9个9),为您提供安全放心的数据存储服务。
CFS 可以严密控制文件系统的访问权限,通过基础网络或 VPC 网络的安全组、并搭配权限组来实现访问权限控制。
性能卓越
CFS 能提供百 GB 级的带宽,百万级的 OPS,千万级的 IOPS,能支持您在各类苛刻性能挑战下的数据存储。
CFS 能支持数千客户端的同时访问,集群后端基于智能负载均衡,保证客户端性能稳定,满足您高并发下的存储需求。
CFS 可以提供亚毫秒级的延时,满足您在延时敏感型场景下的业务诉求。
文件存储类型及性能规格
文件存储(Cloud File Storage,CFS)提供了可扩展的共享文件存储服务,可与腾讯云的云服务器、容器、批量计算等服务搭配使用。云文件存储产品包含如下文件存储类型,您可根据实际应用场景进行选择。
存储类型
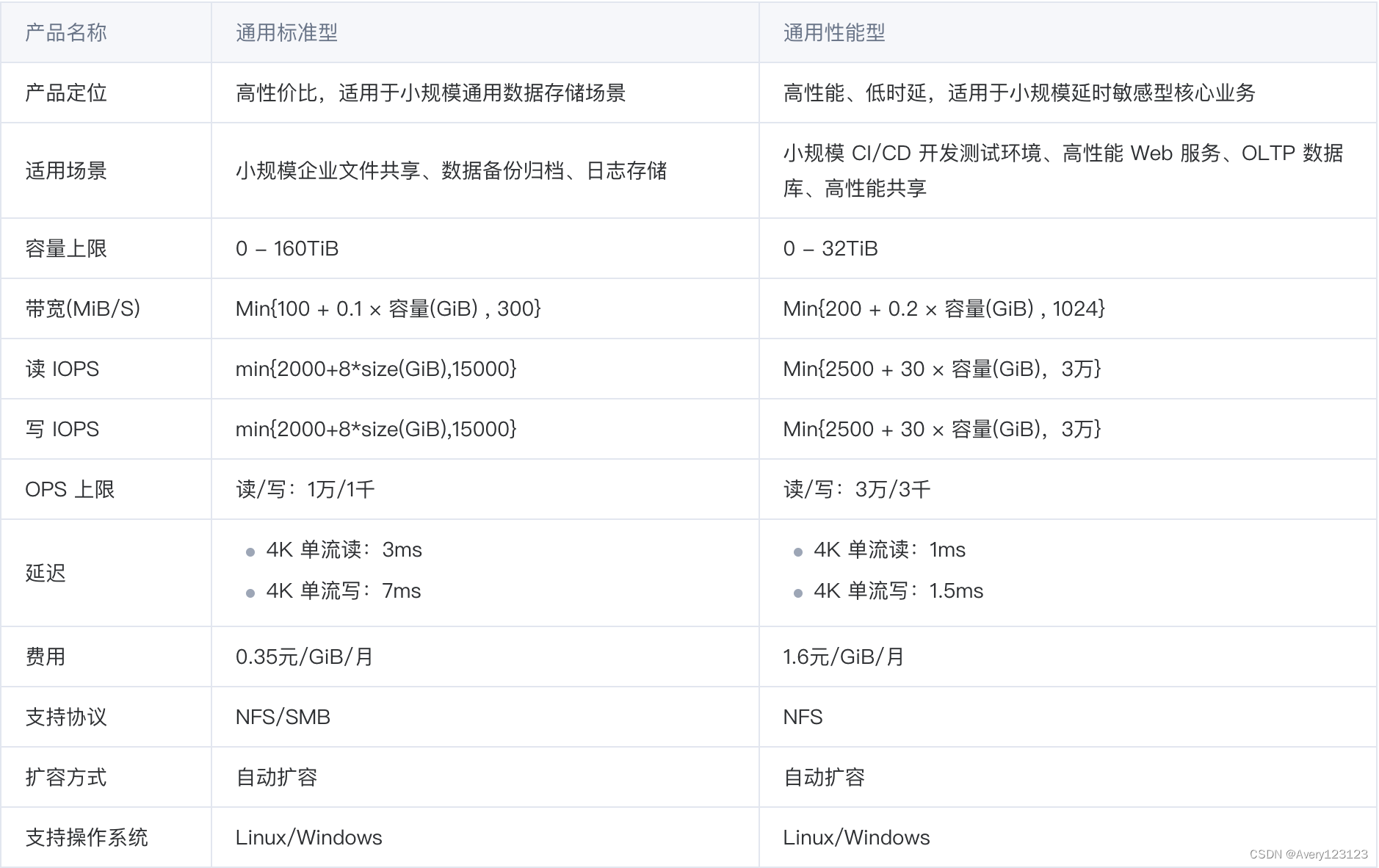
通用标准型
通用标准型文件存储是基于混合介质的高性价比文件存储,通过数据分层机制加速存储读写速度。提供三副本强一致架构能力,每一份写入文件系统的数据确保成功落盘,并位于不同机架的三台独立物理服务器,同时提供接入机热迁移的机制,保障数据的可靠性和服务的可用性,适用于小规模通用数据存储场景。
通用性能型
通用性能型文件存储是基于全 NVMe 介质的低延迟文件存储,通过数据分层机制提供高性能存储能力,提供三副本强一致架构能力,每一份写入文件系统的数据确保成功落盘,并位于不同机架的三台独立物理服务器,同时提供接入机热迁移的机制,保障数据的可靠性和服务的高可用,适合于小规模延时敏感型核心业务。
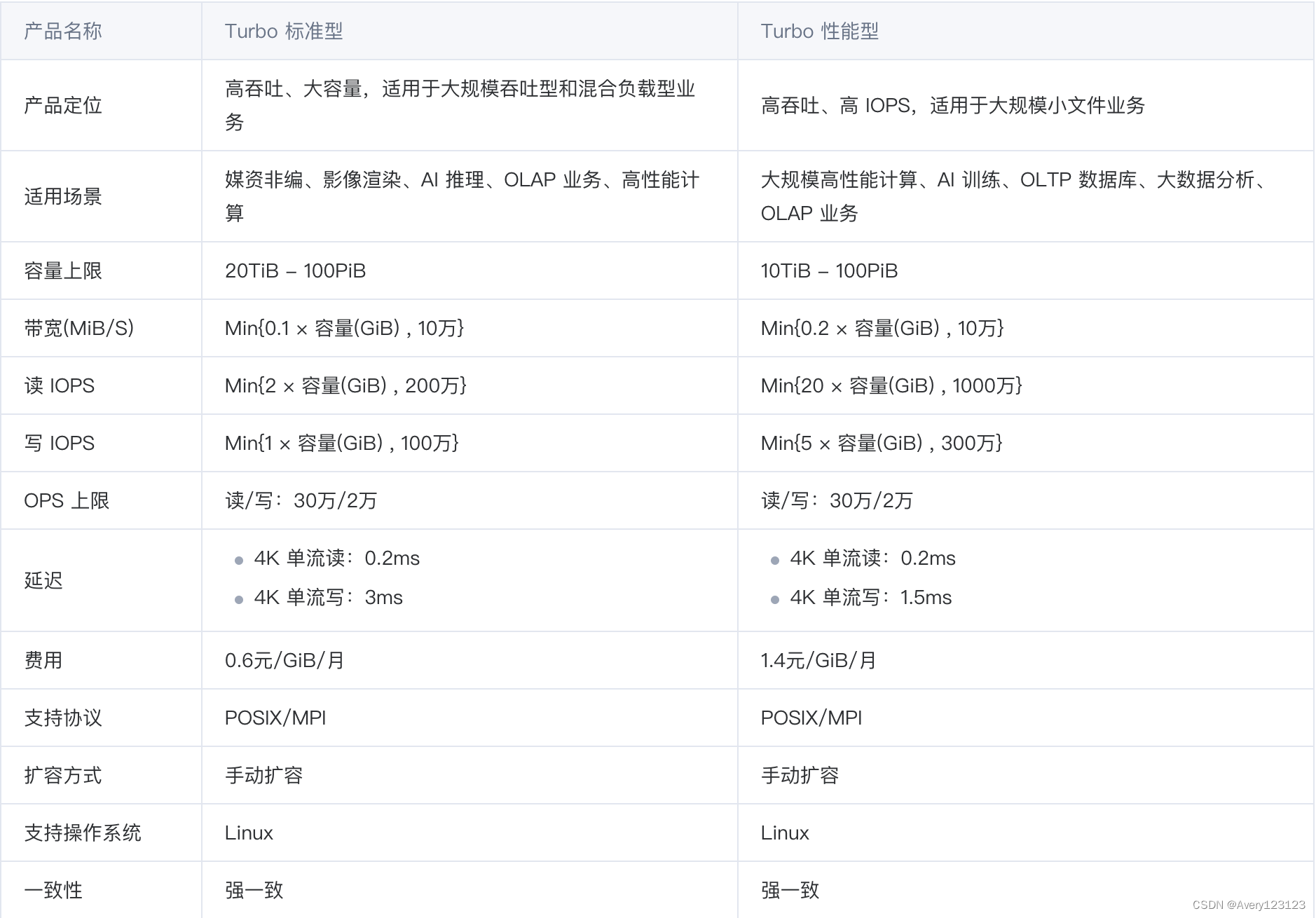
Turbo 标准型
Turbo 标准型文件存储是基于混合介质的并行文件存储,采用非对称架构,数据节点和元数据节点独立部署。提供私有协议的挂载方式,单客户端性能可达存储集群性能。同时资源在底层进行隔离,保障存储集群独享。提供三副本强一致架构能力,每一份写入文件系统的数据确保成功落盘,并位于不同机架的三台独立物理服务器,同时提供接入机热迁移的机制,保障数据的可靠性和服务的高可用,适用于大规模吞吐型和混合负载型业务。
Turbo 性能型
Turbo 性能型文件存储是基于全 NVMe 介质的高带宽、低延迟并行文件存储,采用非对称架构,数据节点和元数据节点独立部署。提供私有协议的挂载方式,单客户端性能可达存储集群性能。同时资源在底层进行隔离,保障存储集群独享。提供三副本强一致架构能力,每一份写入文件系统的数据确保成功落盘,并位于不同机架的三台独立物理服务器,同时提供接入机热迁移的机制,保障数据的可靠性和服务的高可用,适用于大规模小文件业务。
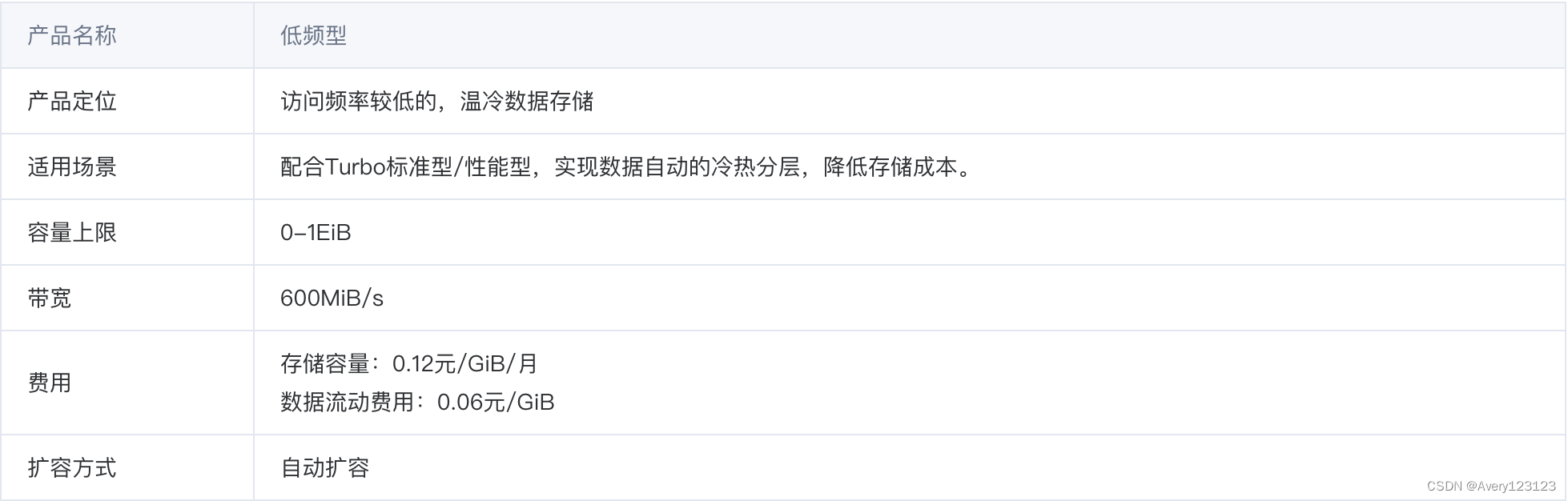
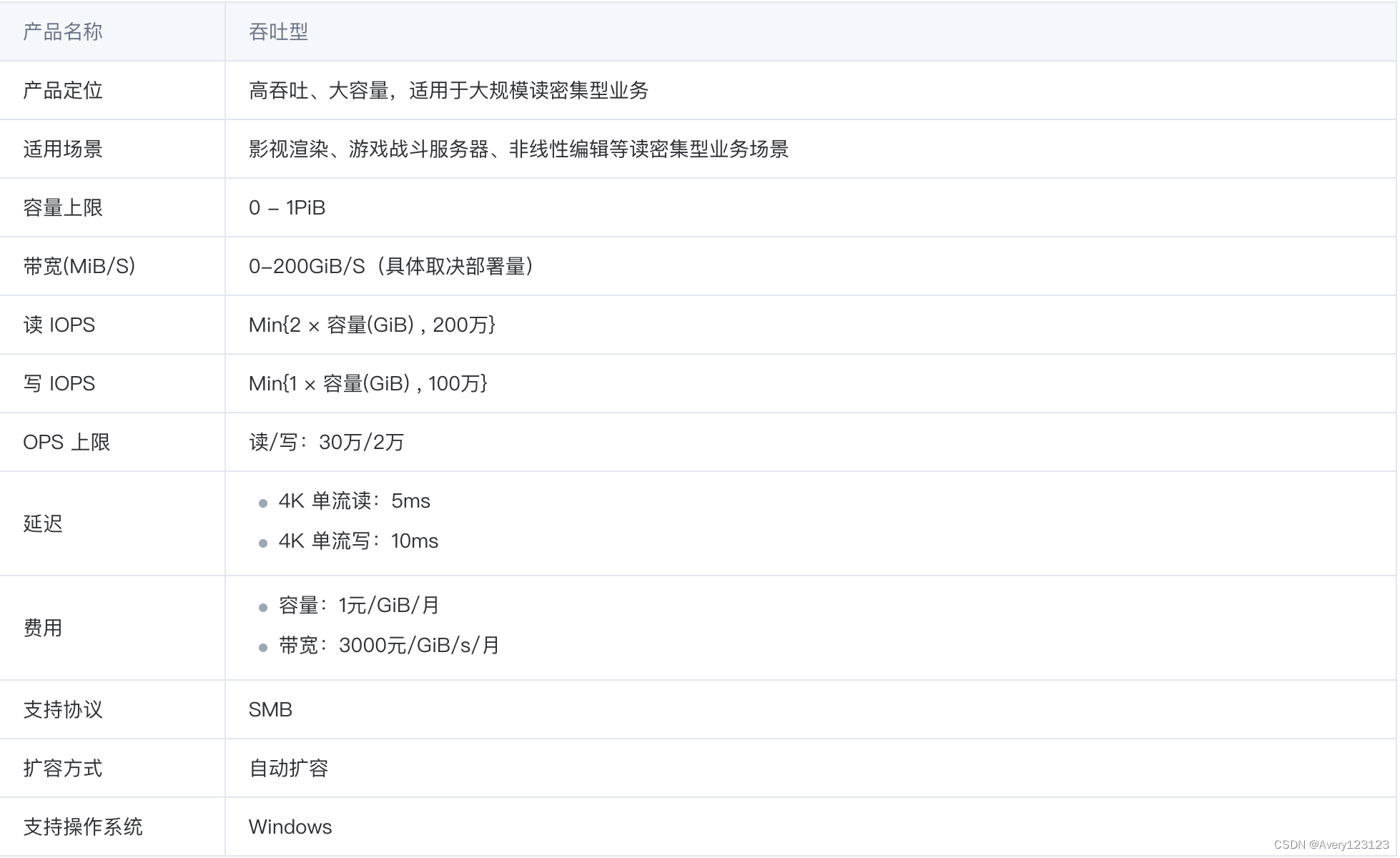
吞吐型
吞吐型是采用分层架构的并行文件存储,可实现更灵活的带宽扩展,提供 SMB 协议的访问方式。满足用户小容量、大带宽的存储需求。提供三副本强一致架构能力,每一份写入文件系统的数据确保成功落盘,并位于不同机架的三台独立物理服务器,同时提供接入机热迁移的机制,保障数据的可靠性和服务的高可用。适用于渲染、游戏战斗服务器、非线性编辑等读密集型场景。
性能与规格
通用系列
Turbo 系列
低频型
吞吐型
使用场景
企业文件共享
文件存储(Cloud File Storage,CFS)提供的存储服务适合员工众多且需要访问和共享相同数据集的组织。管理员可以使用 CFS 来创建文件系统并为组织中的客户端设置读、写权限。
高性能计算及大数据分析
CFS 提供了高性能计算及大数据应用程序所需的规模和性能、计算节点高吞吐量、写后读一致性以及低延迟文件操作,特别适合机器学习、AI 训练、服务器日志集中处理和分析等场景。
流媒体处理
视频编辑、影音制作、广播处理、声音设计和渲染等媒体工作流程通常依赖于共享存储来操作大型文件。强大的数据一致性模型加上高吞吐量和共享文件访问,可以缩短完成上述工作所需的时间。
内容管理和 Web 服务
CFS 可以作为一种持久性强、吞吐量高的文件系统,用于各种内容管理系统,为网站、在线发行、存档等各种应用存储和提供信息。
专用软件环境
CFS 提供了政府、教育、医疗等行业传统服务架构迁移上云的基础,通常专用软件需要共享同一个文件存储系统,且仅支持 POSIX 标准协议操作。
归档存储-CAS
产品概述
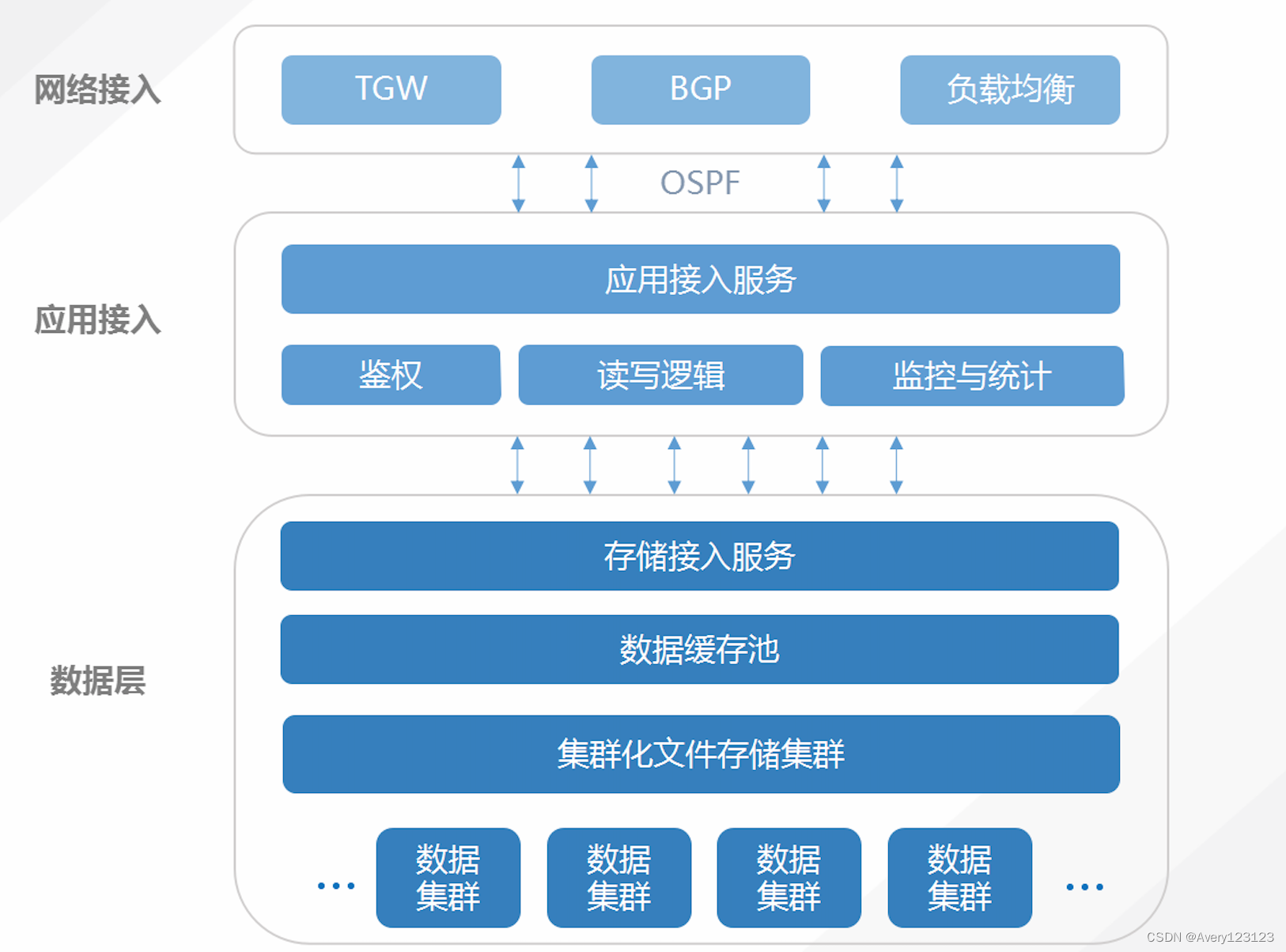
归档存储(Cloud Archive Storage,CAS)是面向企业和个人开发者提供的高可靠、低成本的云端离线存储服务。您可以将任意数量和任何形式的非结构化数据放入 CAS,实现数据的容灾和备份。归档存储采用分布式云端存储,您可以在任何有网络的地方通过 RESTful API 对数据进行管理。
归档存储主要是针对海量、重要且访问频率极低的非结构化数据进行长期的归档保存和备份管理。在数据安全层面,归档存储提供数据锁定机制,防止数据被修改和删除,保障数据安全。用户可以以低廉的存储费用,享受存放海量数据,极大降低存储成本。
技术架构
性能指标
腾讯云归档存储拥有高 QPS、大带宽和数据取回三个性能指标。
QPS(每秒请求数)
每个用户在每个地域默认800。如用户在北京和上海地域使用归档存储,分别有800QPS的频控配额。当用户有较高的 QPS 要求时,可以通过工单或客服联系腾讯云存储进行扩展。
大带宽
为了服务广大用户,腾讯云归档存储每个地域准备了较大的带宽,用户可复用这些公共带宽。一般情况下,腾讯云归档存储提供的带宽是大于单个用户的带宽的,当用户带宽上有特殊需求时,可以通过 提交工单 报备,我们会进行特殊支持。
数据取回
数据取回分为三档,其中加急取回的对象需要小于256MB,当大于256MB时,需要使用标准取回或批量取回方式。
加急取回一般在1 - 5分钟内可以完成;标准取回一般在3 - 5小时完成;批量取回一般在5 - 12小时完成。
与对象存储的差异
归档存储 CAS 是一项离线存储服务,不同于在线的对象存储 COS,在使用过程中差异点如下:
差异一:不保存文件索引
差异描述
对象存储 COS 是一项在线存储服务,主要由两个部分组成:文件数据和文件索引(包括文件元信息)。用户可以凭借一串指定的资源地址(即 URI )来访问数据,用户也可实时获取所有的资源地址(即 URI )。
作为离线存储的 CAS,为了降低成本,去掉了文件索引的部分,转而用档案 ID,档案 ID 中记录了该文件的归属者、存储地址等信息,但是该 ID 对使用者不可解读,只有 CAS 系统可以识别和解译其中的信息。
- 档案 ID 使用方式一
用户上传档案时,系统返回档案 ID,用户记录档案 ID。
用户凭借记录的档案 ID 来发起数据取回任务。 - 档案 ID 使用方式二
用户上传档案时,系统返回档案 ID,但是用户没有记录档案 ID。
用户发起检索档案列表的数据取回任务。
任务返回一张表或者 JSON 字符串,其中每条记录档案 ID,该档案的备注,上传时间等其他信息,该过程约耗时3 - 5小时。
用户使用档案 ID 来发起档案取回类型的任务。
使用效果
- 节约成本:由于不保存文件索引,因而归档存储的价格要远低于对象存储。
- 无法实时获取目前文件库下所有的档案列表,需要发起检索档案列表的数据取回任务,该任务约耗时3 - 5小时。
- 无法使用 URI 直接获取文件,需要记录档案 ID,通过档案 ID 发起数据取回请求。
- 无法实时获取目前文件库下档案个数和总大小,该数据每日更新一次。
差异二:数据取回需要时间等待
差异描述
归档存储是一项离线存储服务,存储集群在归档存储内部分为临时缓存集群和持久化冷数据集群。数据上传时,先进入临时缓存集群,后沉降至持久化冷数据集群。数据取回时,先从持久化冷数据集群进入临时缓存集群,后返回给用户。
保存在持久化冷数据集群的数据会做磁盘休眠,同时在持久化冷数据集群和临时缓存集群之间存在数据调度,因而数据取回的时候存在等待时间用以唤醒磁盘和调度数据
使用效果
节约成本:由于磁盘休眠,节约机房电力成本,因而归档存储的价格要远低于对象存储。
用户需要发起一个任务请求,一段时间之后,再发起 Get Job Output 的请求获取缓存池中的数据,此处的缓存池即临时缓存集群的外部表现。缓存池中的数据保留24小时。
用户发起一个档案取回或者档案导入 COS 的任务,存在三种模式,三个模式时间不同,收费不同。返回时间越短,在系统调度数据中优先级更高,价格越昂贵。
使用场景
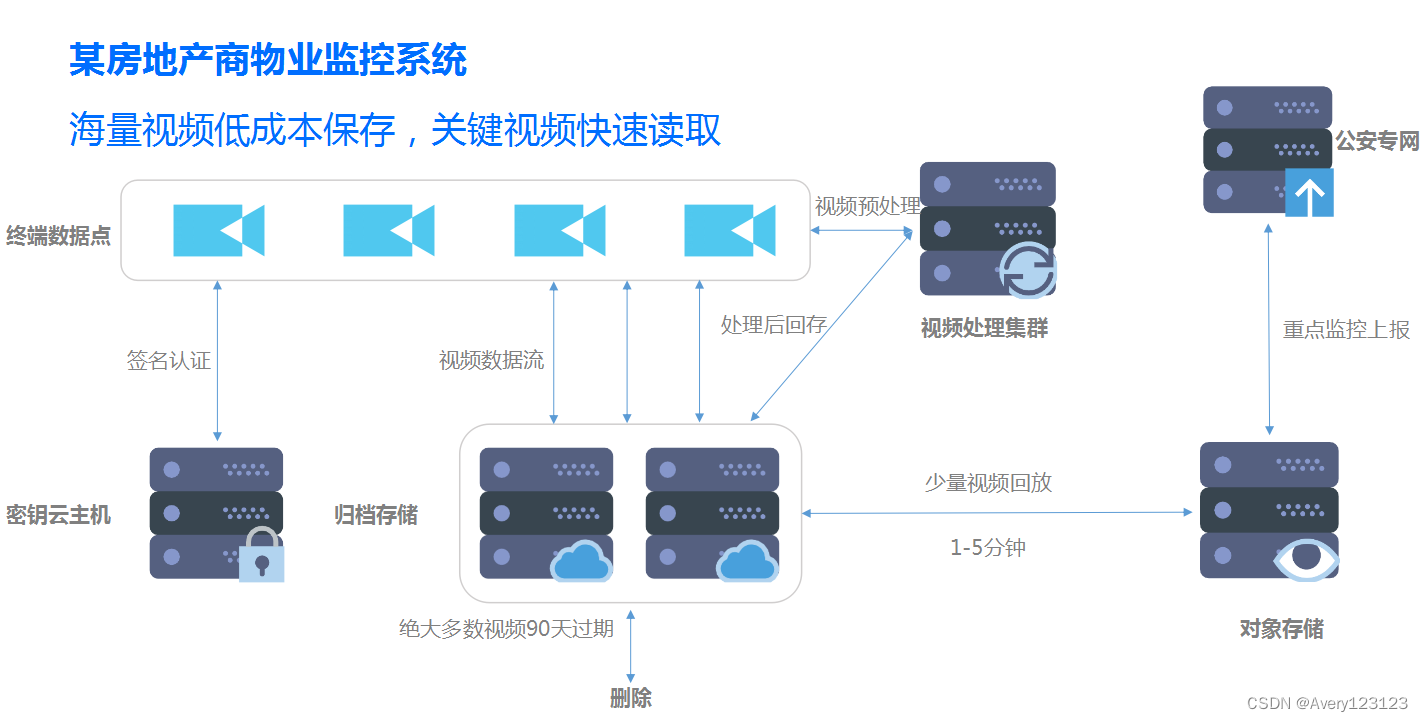
监控视频领域
场景举例
- 道路交通监控视频
- 小区安保监控视频
- 火车站机场海关监控视频
- 银行活体检测视频录像
- 居家宠物视频录像
- 物联网平台
说明
视频监控行业每天都在产生大量的视频数据信息,数据量增长迅速。由于视频数据保存的时间较长,所以积累的数据量庞大,需要对这些视频数据资源进行安全管理。可以将这些视频数据流经过预处理后,自动存入归档存储,按照不同的情况和规定,设置自动删除过期的视频数据资源,降低人工管理成本和存储成本。在特定情况之下的时候,可快速取回特定的视频资料进入对象存储,进行审查监控,重点监控内容上报到公安系统专网。
案例
科学实验与医疗数据领域
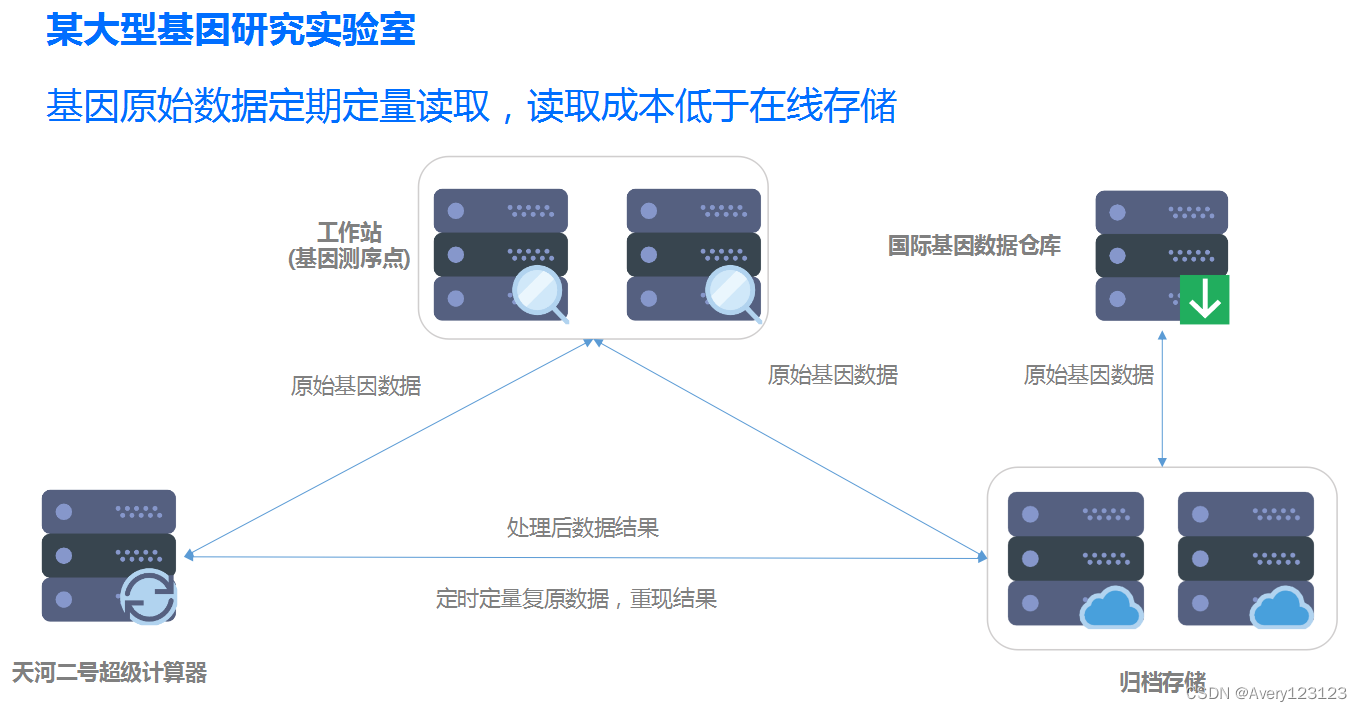
场景举例
- 处理后的基因数据
- 医药实验数据
- 医疗影像
- 电子病历和健康数据库
说明
科学实验与医疗领域孕育有海量数据。基因测序数据量呈倍数增长,电子病历包括文本、图像、视频等类型数据,数据量庞大。大量原始数据经过对比分析可以挖掘到有效信息,为疾病的诊断和治疗提供参考,因此原始数据的长期积累存档管理很重要。通过归档存储,可以以极低的价格成本和管理成本存储大量原始数据和处理后的结果数据。同时,可以定时定量复原数据,重现结果。
案例
数据库和系统服务集成商
场景举例
数据库存档
文件系统快照
用户日志
用户归档邮件
PaaS 服务商
SaaS 服务商
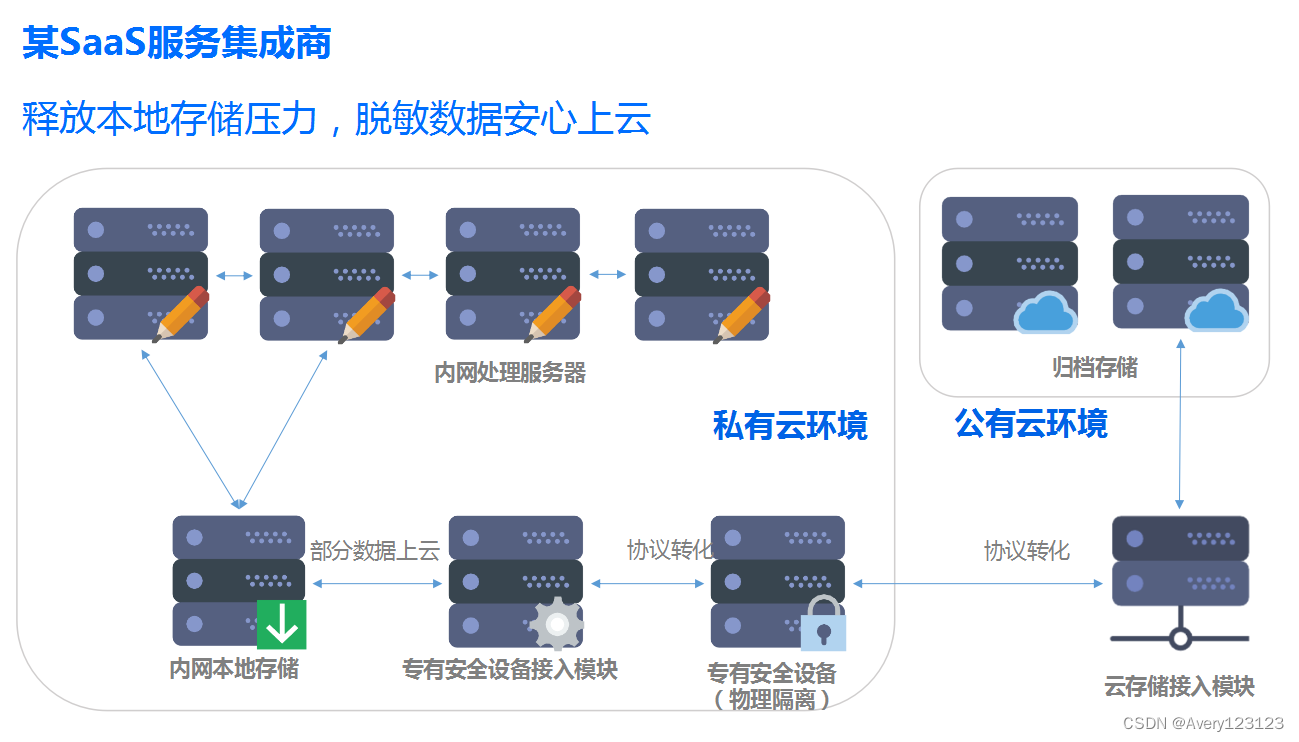
说明
SaaS 服务提供商通过互联网提供了低成本的服务交付和低成本的服务应用方式,大大地降低了以前需要花费大量精力才能关注到的市场的成本。SaaS 服务商使用归档存储,将比传统存储降低存储成本,通过专有安全设备模块,将数据脱敏存档,释放本地存储的压力,在激烈的竞争中,建立自身优势。
案例
极冷的媒体资源
场景举例
- UGC 社区用户生成的视频
- 视频点播平台的历史电影电视
- 各大卫视的历史节目存档
- 报纸杂志原始未编辑素材
- 直播 App 历史影像
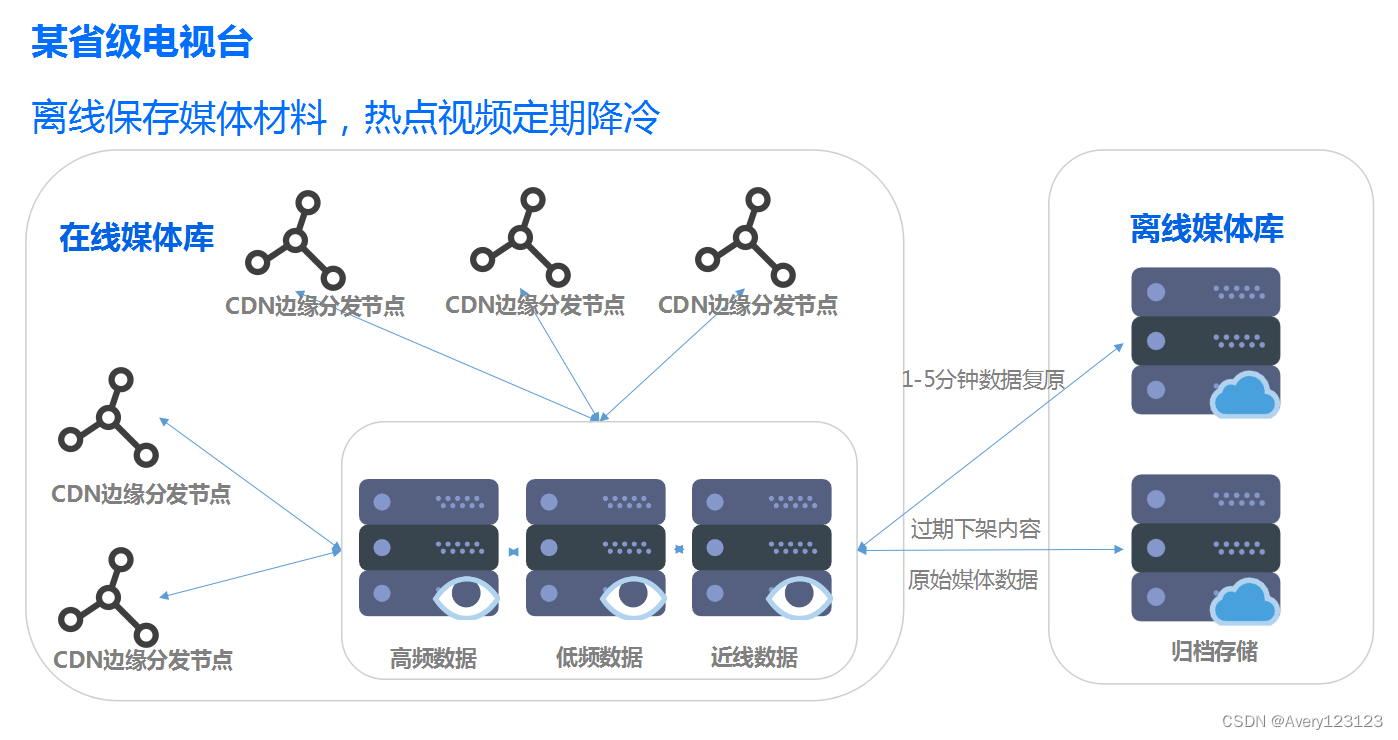
说明
电视台在线媒体库热点视频根据时间和热度,需要定期降冷。从高频数据到低频数据,再到近线数据,将过期下架的原始媒体数据,存入归档存储离线媒体库,释放存储空间资源,降低存储成本。大量旧的视频数据作为历史资料可以安全的在归档存储保存几年甚至十几年,集中、统一的资源管理、检索,降低电视台管理维护成本。在有视频点播需求的时候,1到5分钟即可快速复原数据,提升使用效率。
案例
手机厂商移动数据
场景举例
- 已删除的手机网盘数据
- 历史版本的应用安装包
- 历史版本的系统补丁
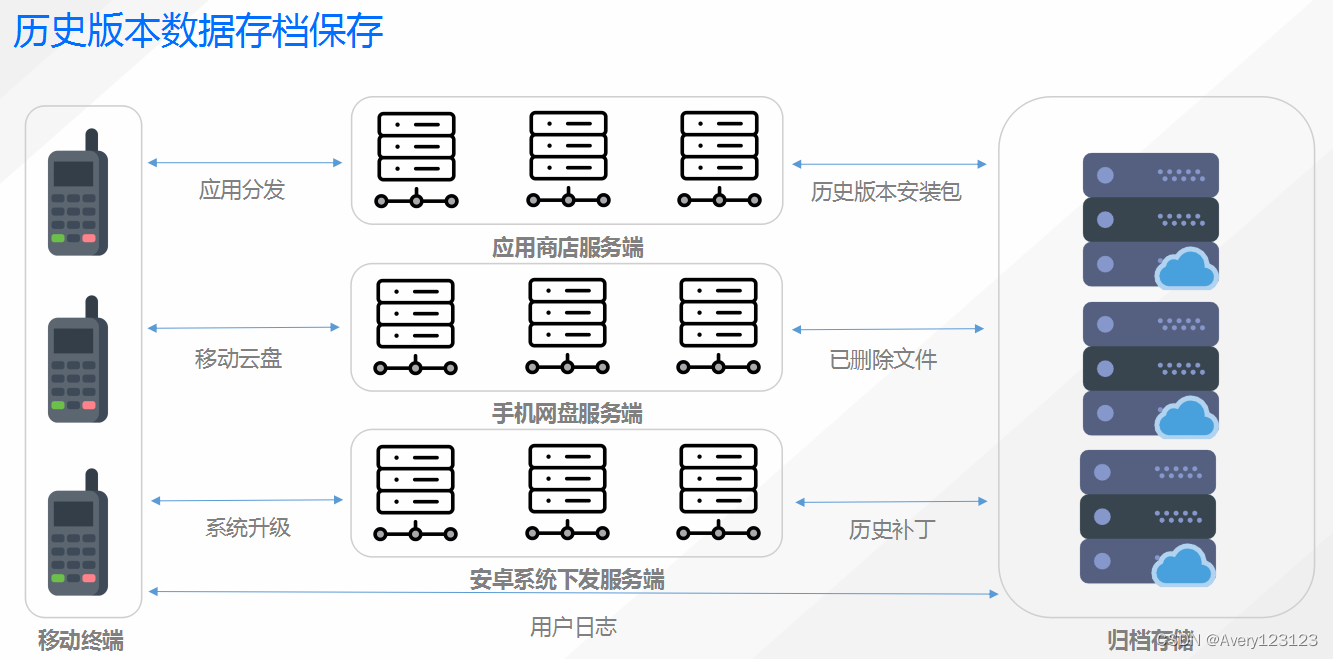
说明
互联网手机厂商需要将历史版本数据存档保存。可以将应用分发的历史版本安装包、移动云盘的已删除文件以及系统升级的历史补丁,这些使用频率低的冷数据,离线存储到归档存储保存起来。
案例
云HDFS-CHDFS
产品概述
云 HDFS(Cloud HDFS,CHDFS)是腾讯云一种提供标准 HDFS 访问协议、卓越性能、分层命名空间的分布式文件系统。
CHDFS 主要解决大数据场景下海量数据存储和数据分析,能够为大数据用户在无需更改现有代码的基础上,将本地自建的 HDFS 文件系统无缝迁移至具备高可用性、高扩展性、低成本、可靠和安全的 CHDFS 上。
通过在腾讯云平台创建 CHDFS,即可在腾讯云多个 CVM、CPM 2.0或者容器等计算资源内通过 HDFS 协议接口访问 CHDFS,从而实现文件的访问及共享。
产品优势
易于使用
通过使用 CHDFS,可以极大降低维护本地 HDFS 成本,同时应用程序无需任何更改,仅仅通过修改相关配置项即可无缝迁移上云。
CHDFS SDK 可以在所有 Apache Hadoop 2.x 环境中使用,同时也支持在腾讯云大数据套件 EMR 产品中使用。
无限容量
CHDFS 存储空间无上限,满足客户海量大数据存储与分析,同时可以进行存储容量的动态扩缩容。
卓越性能
通过提供原子目录操作的分层命名空间,实现海量大数据处理时优异的存储性能。
多维度安全
CHDFS 提供多维度安全机制来保障数据安全:
通过权限 ACL,实现授权地址和访问类型控制。
通过 VPC 方式,实现网络访问隔离。
接入 CAM,实现不同账号授权,满足客户安全且精细化的管理需求。
应用场景
-
CHDFS 主要适用于大数据分析及机器学习这类高数据吞吐量要求的业务场景。
-
针对大数据分析及机器学习场景,CHDFS 提供了高吞吐数据访问能力,通过计算与存储分离方式,可以极大的发挥计算资源的灵活性,同时实现存储数据永久保存,降低客户大数据分析及机器学习的资源成本。
-
所有通过自建 HDFS 存储服务的业务
数据加速器 GooseFS
数据加速器(Data Accelerator Goose FileSystem,GooseFS)是由腾讯云推出的多协议、高性能、大吞吐的数据加速服务。GooseFS 可以为上层计算应用提供统一的命名空间和访问协议,方便用户在不同的存储系统管理和流转数据。依托对象存储作为数据存储底座的海量存储、低成本优势,GooseFS 不仅可以加速海量数据分析、机器学习、人工智能等业务访问存储的性能,还可以帮助业务实现冷热数据自动分层,平衡业务架构的性能表现和成本支出。
产品功能
数据加速器有两个子产品:GooseFS 和 GooseFSx。
数据加速器 GooseFS
GooseFS 旨在提供一站式的缓存解决方案,在利用数据本地性和高速缓存,统一存储访问语义等方面具有天然的优势;GooseFS 在腾讯云数据湖生态中扮演着“上承计算,下启存储”的核心角色,如下图所示。
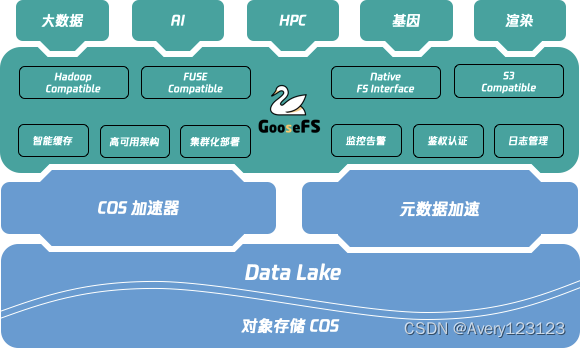
GooseFS 提供了以下功能:
- 缓存加速和数据本地化(Locality):GooseFS 可以与计算节点混合部署提高数据本地性,利用高速缓存功能解决存储性能问题,提高写入对象存储 COS 的带宽。
- 融合存储语义:GooseFS 提供 UFS(Unified FileSystem)的语义,可以支持 COS、Hadoop、S3、K8S CSI、 FUSE 等多个存储语义,使用于多种生态和应用场景。
- 统一的腾讯云相关生态服务:包括日志、鉴权、监控,实现了与 COS 操作统一。
- 提供 Namespace 管理能力,针对不同业务、不同的Under File System,提供不同的读写缓存策略以及生命周期(TTL)管理。
- 感知 Table 元数据功能:对于大数据场景下数据 Table,提供 GooseFS Catalog 用于感知元数据 Table ,提供 Table 级别的 Cache 预热。
产品优势
数据加速器(Data Accelerator Goose FileSystem,GooseFS)在数据湖场景中具有如下几点明显的优势:
数据 I/O 性能
GooseFS 部署提供近计算端的分布式共享缓存,上层计算应用可以透明地、高效地从远端存储将需要频繁访问的热数据缓存到近计算端,加速数据 I/O 性能。GooseFS 提供了元数据缓存功能,可以加速大数据场景下查询文件数据以及列出文件列表等元数据操作的性能。配合大数据存储桶使用,还可进一步加速重命名文件的操作性能。此外,业务可以按需选择 MEM、SSD、NVME 以及 HDD 盘等不同的存储介质,平衡业务成本和数据访问性能。
存储一体化
GooseFS 提供了统一的命名空间,不仅支持了对象存储 COS 存储语义,也支持 HDFS、K8S CSI 以及 FUSE 等语义,为上层业务提供了一体化的融合存储方案,简化业务侧运维配置。存储一体化能够打通不同数据底座的壁垒,方便上层应用管理和流转数据,提升数据利用的效率。
生态亲和性
GooseFS 全兼容腾讯云大数据平台框架,也支持客户侧自定义的本地部署,具备优秀的生态亲和性。业务侧不仅可以在腾讯云弹性 MapReduce 产品中使用 GooseFS 加速大数据业务,也可以便捷地将 GooseFS 本地化部署在公有云 CVM 或者自建 IDC 内。此外,GooseFS 支持透明加速能力,对于已经使用腾讯云 COSN 和 CHDFS 的用户,只需做简单的配置修改,即可实现不修改任何业务代码和访问路径的前提下,自动使用GooseFS 加速 COSN 和 CHDFS 的业务访问。
应用场景
开源生态数据湖
客户基于开源 Hadoop 生态构建大数据处理与分析,会面临计算资源与存储资源扩容速度不匹配、存储系统需对接多数据源的问题。
推荐产品
推荐数据加速器 GooseFS。
主要能力
- 计算存储分离
通过计算与存储分离,实现计算资源弹性伸缩,满足客户对计算资源的灵活调度。 - 多数据源支持
可对接多种数据源,允许存储任意规模的结构化、半结构化、非结构化数据。 - 高性能业务架构
通过数据加速器(Data Accelerator Goose FileSystem,GooseFS)、元数据加速器、AZ 加速器等多级加速服务,提升计算业务访问性能。
交互式查询数据湖
客户在对象存储(Cloud Object Storage,COS)中存储了多种数据源数据,包括实时计算数据,需要对其中的数据进行 OLAP 分析并进行数据可视化展示。
主要能力
- 多数据源支持
可对接多种数据源,允许存储任意规模的结构化、半结构化、非结构化数据。 - 性能加速
通过数据加速器、元数据加速器、AZ 加速器等多级加速服务,实现超越本地 HDFS 的性能。
机器学习数据湖
在经典机器学习场景中,训练数据量大,同时要求很大的内网带宽。
主要能力
- 超大带宽
可以提供超大的内网带宽,满足机器学习场景大带宽需求。 - 多数据源支持
可对接多种数据源,允许存储任意规模的结构化、半结构化、非结构化数据。 - 性能加速
通过数据加速器、元数据加速器、AZ 加速器等多级加速服务,实现超越本地 HDFS 的性能。
云原生数据湖
通过容器服务,结合 Flink、TensorFlow 等开源应用,搭建云原生数据 ETL 集群和分析集群,实现计算资源的弹性化;通过数据加速器、元数据加速器、AZ 加速器等多级加速服务,提升计算业务访问性能;通过对象存储服务作为数据湖存储底座,实现海量异构数据的低成本存储。
主要能力
- 计算存储分离
通过计算与存储分离,实现计算资源弹性伸缩,满足客户对计算资源的灵活调度。 - 高性能业务架构
通过数据加速器、元数据加速器、AZ 加速器等多级加速服务,提升计算业务访问性能。 - 丰富生态支持
可存储 Parquet、ORC 多种格式数据源,支持 Spark、Presto、Flink 等多种大数据插件。
存储数据服务
日志服务
产品概述
日志服务(Cloud Log Service,CLS)提供云上的日志采集和检索的解决方案。可采集多渠道、多平台、不同数据源的日志数据,五分钟快速便捷接入,产品具备日志采集、检索分析、仪表盘、告警等功能,全面提升您的问题定位、指标监控的效率,大大降低日志运维门槛。同时,您也可以对日志数据进行 ETL、计算分析、并将结果投递或消费到您的业务平台中。
功能概览
日志服务主要提供以下功能:
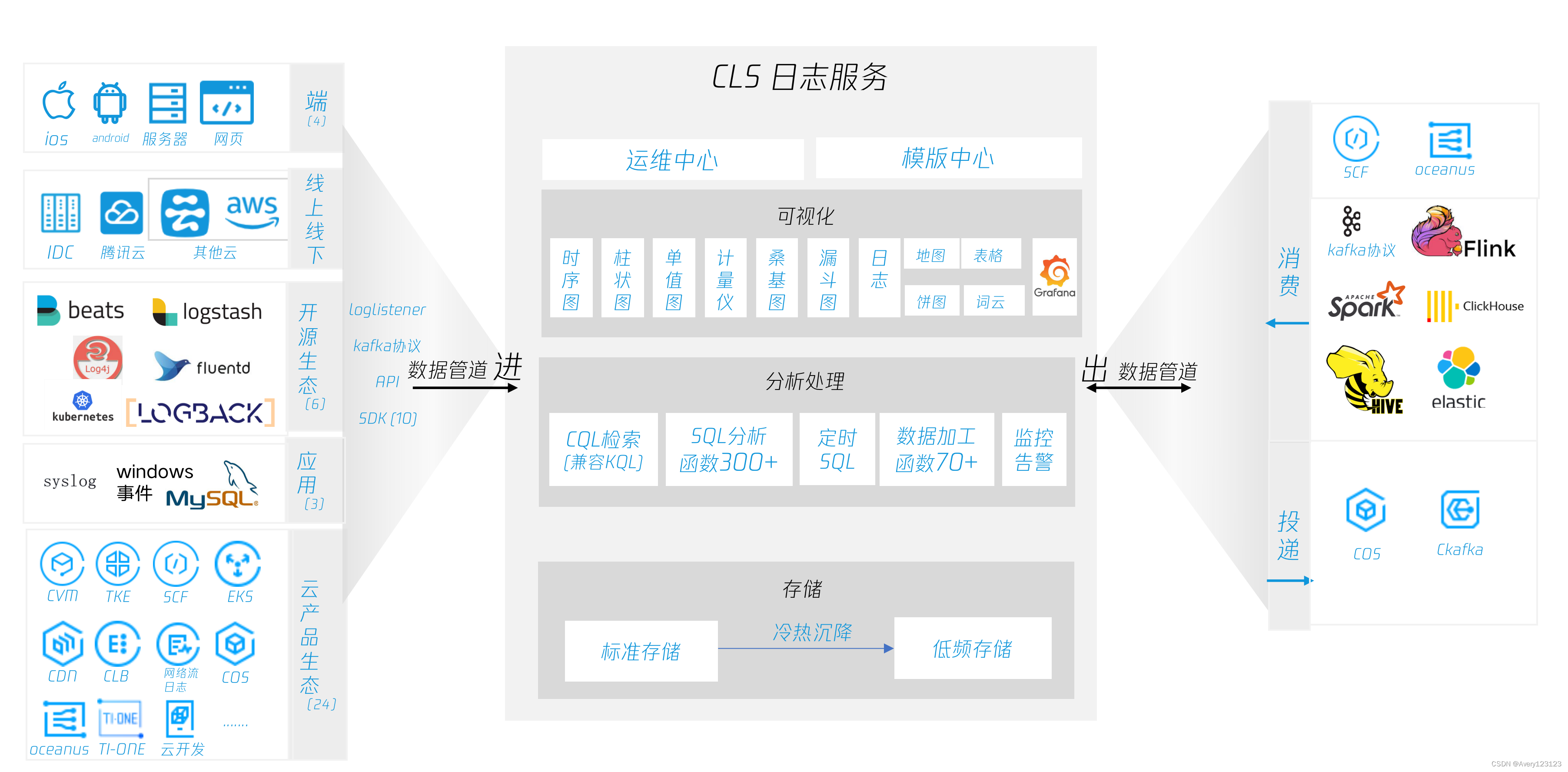
日志采集
日志服务目前支持 LogListener 、API、Kafka 协议、对象存储(Cloud Object Storage,COS)导入等多种采集方式:
- Loglistener 实时采集:使用腾讯云 LogListener 采集日志,便捷安装,服务稳定可靠安全、支持大部分主流 Linux 操作系统,兼顾高性能与低资源占用。
- 通过 API:无需安装 LogListener,直接调用 API 上传日志,支持多种语言。
- Kafka 协议:支持使用 Kafka Producer SDK 上传日志到 CLS。
- COS 导入:将腾讯云对象存储中的数据导入到日志服务。
日志存储
根据用户对日志不同的检索时延性及日志处理能力需求,提供两种存储:
- 实时存储:适用于用户对日志有统计分析的需求,提供日志的秒级检索,实时统计分析,实时监控,流式消费等应用能力。
- 低频存储:适用于访问频率较低且无统计分析需求的日志,如审计归档日志。低频存储提供全文检索日志的能力,满足用户对历史日志的回溯检索,归档存储等诉求。长期存储下,整体使用成本相比实时存储降低80%。
日志检索分析
针对存储在 CLS 的日志进行实时检索分析,帮助用户快速定位异常日志、统计系统及业务指标。
日志检索:使用关键词按全文或字段检索日志。
统计分析:使用 SQL 灵活统计日志内的系统及业务指标并通过图表进行展示,兼容 SQL 92标准,支持200+ SQL 函数。例如按省份统计业务请求数,按时间查询请求错误率变化趋势。
性能优异:秒级返回查询结果,支持亿级别日志检索分析。
仪表盘
仪表盘提供数据分析全局视图,您可以在仪表盘查看多个基于查询与分析结果的统计图表。
- 仪表盘:仪表盘支持保存多个基于查询与分析结果的统计图表,构成场景化的分析大盘。
- 预置仪表盘:面向 CLB、TKE、COS 等腾讯云生态产品,CLS 提供预置仪表盘,实现常见监控能力的开箱即用。
- 模板变量:模板变量支持数据源变量与快速过滤,实现仪表盘图表统计分析对象与维度的快速切换,千变万化支持更复杂的业务场景。
告警
日志内出现较多错误日志或系统及业务指标超出阈值时秒级告警,主动发现系统及业务异常问题。
- 通知渠道:支持电话、短信、邮件、微信、企业微信和自定义接口回调(可对接钉钉及飞书)。
- 多维分析:触发告警时可针对原始日志进行额外的检索分析,将结果附加在告警通知中,辅助定位告警原因。
日志数据处理
- 日志过滤清洗:脏数据清洗,按条件过滤日志。
- 日志结构化:将非结构化的日志处理成结构化数据,方便您后续使用 SQL 来计算分析日志。
- 日志计算分析:使用定时 SQL 任务,对日志进行计算,如日志聚合。
- 日志分发:按照一定的规则,将日志分发到不同的目标日志主题中。
日志投递与消费
您可以将日志投递至腾讯云产品中,如对象存储 COS、消息中间件 Ckafka,也可以将 CLS 日志消费到其它大数据组件。
- 日志投递至 COS:用于日志归档、日志的离线计算。
- 日志投递至 Ckafka:适用于日志的实时处理和计算。
- 日志实时消费:消费日志数据到大数据组件,例如 Flink、Logstash、Flume
功能优势
功能丰富
- 提供采集、存储、检索、转存投递等功能一站式日志服务。
- 采集客户端 LogListener 提供单行/多行全文、分隔符、JSON、正则等日志结构化解析方式。
- 提供多种数据接入方式,用户可根据业务情况选择适合的接入方式,详情请参见 采集概述。
- 提供丰富的检索语法,方便用户进行关键词查询、模糊查询、范围查询等日志查询操作。
稳定可靠
- 日志服务采用高可扩展性的分布式存储架构,支持横向水平扩容,服务弹性伸缩,轻松存储管理海量日志数据。
- 日志服务后端存储采用多副本机制管理存储日志数据,为数据安全提供可靠性保障。
简单高效
- 采集端 LogListener 提供界面式的配置方式,配置简单直观,使用 LogListener 可快速接入日志服务。
- 数据写入 CLS 即可被消费,亿级数据查询支持秒级返回结果。
- 服务按实际用量收费,无需单独搭建和运维日志系统,避免了资源闲置浪费问题。
生态扩展
- 部分云产品日志已接入 CLS,详情请参见 接入列表。
- 日志数据投递 COS,满足对日志数据长时间归档存储的需求。
- 日志数据投递 Ckafka,满足对日志数据实时消费的需求,便于进一步处理分析。
智能媒资托管
产品概述
企业网盘是由智能媒资托管(Smart Media Hosting,SMH)推出的一款基于云端存储、围绕非结构化数据管理的企业级办公产品,企业网盘可为企业用户提供文件存储、权限管理、在线协作、文档收集与分发等服务,助力企业提升数据管理效率,更大化地挖掘数据的业务价值,打通从业务到数据再到商业价值变现的整条链路。
产品功能
文件归档备份
云上数据自动备份,本地数据一键归档,多端实时更新,为企业数字资产保驾护航。
多级权限管控
高灵活度、高精度权限管控,支持文件级别权限管控,实现人员与文件精细化管理。
文件协作与版本管理
支持多人在线协同编辑,历史版本自动生成,支持任意版本回滚。
文件分发与汇总
支持文件/文件夹一键外链分享,多级参数配置实现文件安全快速分发与汇总。
应用场景
协同办公、版本控制
支持对系统用户或群组发起协作邀请;多个用户可对协同文件进行在线编辑,实时同步其他用户编辑该文件的结果信息;系统可自动生成多个历史版本,用户可按需预览、下载、恢复任何一个历史版本。
支持文档、图片、音频等常见文件的在线预览,支持自定义水印规则,实现办公类文件加载动态水印预览。
移动办公实时高效
支持 Windows、Mac、 多种操作系统平台,确保用户可以随时随地在任何设备上访问需要的文件并进行协作,取代传统的 FTP 等文件管理系统。
可使用移动客户端随时拍摄工程图纸、照片、合同等,手机端上传,现场情况实时同步云端,确保项目团队及时获得最新资料。
海量数据集中管理
可将各部门的业务文件通过多级文件夹进行分类归档存放,网盘也支持高级搜索能力,快速定位到业务文件。
企业员工在各自的办公电脑可安装网盘客户端,将本地文件夹与云端文件夹建立同步,存储在本地的文件自动上传,实现自动化备份。
超大文件传输
使用企业网盘外链功能,文件上传者将文件上传网盘后一键生成外链,下载者只需在浏览器打开外链 URL 即可下载文件。下载速度稳定有保障。
企业向各合作伙伴、分支机构、客户分发业务资料,面对众多的人员和庞大的数据资料,企业网盘强大的权限功能体系支持管理员做好文件分发过程中的权限管控。
支持私有化部署
除了公有云交付方式,企业网盘还支持私有化部署,满足您对于企业网盘的个性化需求,可直接部署于您的自有机房或公有云服务器,最大限度保障您的服务稳定性、数据安全性和产品可控性。
数据万象
产品概述
腾讯云数据万象(Cloud Infinite,简称CI)专注于数据处理服务,能够实现对云上各类型数据的处理,提供图片处理、媒体处理、内容审核、文件处理、AI 内容识别、文档服务等全品类多媒体数据的处理能力,为您提供专业一体化的数据处理解决方案,满足多种场景维度的需求。
数据万象(Cloud Infinite,CI)与对象存储(Cloud Object Storage,COS)深度集成,为 COS 提供丰富的数据处理服务。给 COS Bucket 绑定数据万象服务后,您可通过 COS 控制台、API 和 SDK 快速调用数据万象的功能。
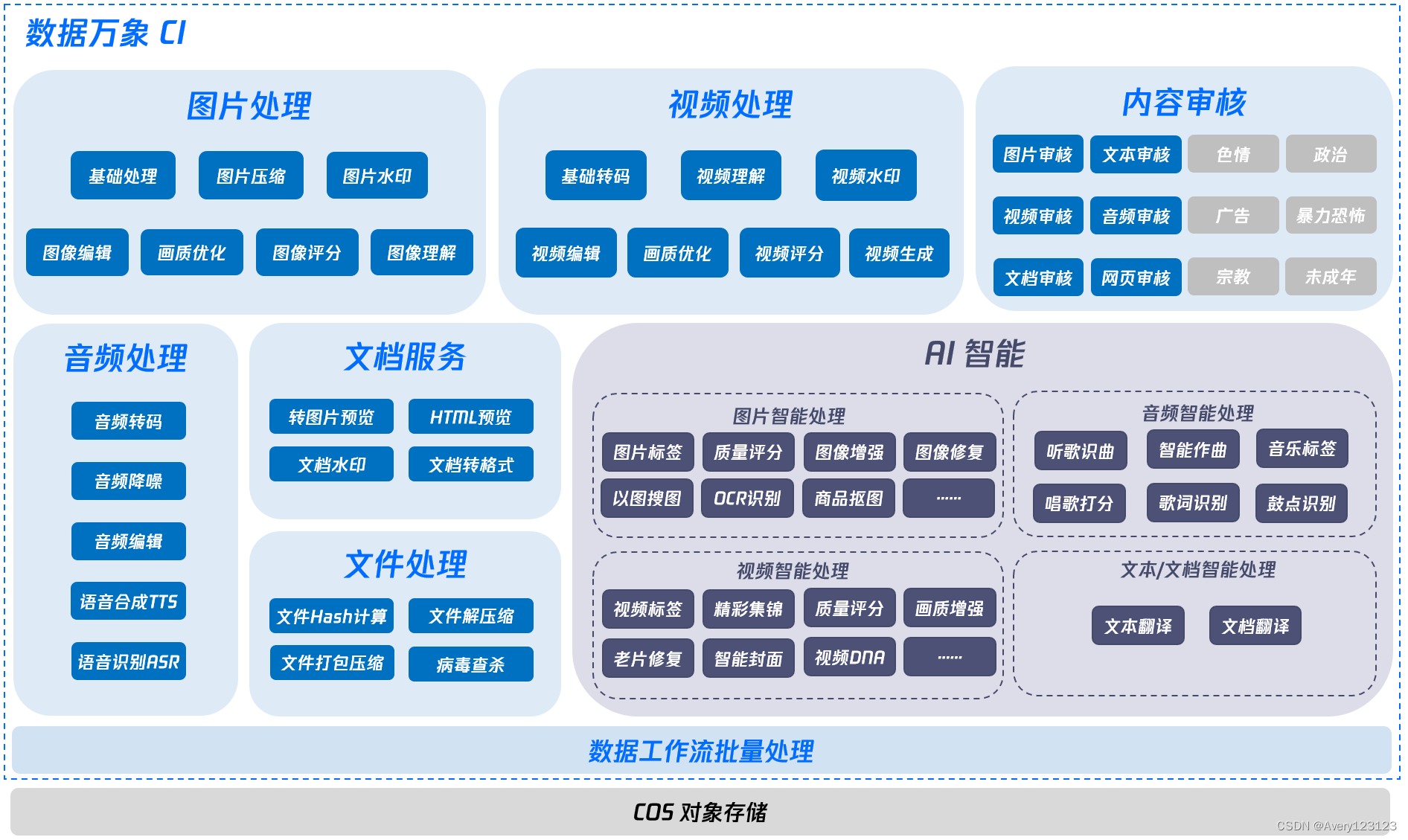
图片处理
数据万象 CI 为用户提供全面、高效、低成本的图片处理能力,从基础的图片裁剪、旋转、缩放等处理,到基于前沿算法的图片压缩、盲水印、图片标签、图像修复、商品抠图等智能 AI 能力,作为数据万象中最核心的服务,拥有在 QQ 空间相册积累的十多年图片服务经验,多年来不断完善,解决了各行各业用户图片处理场景下的需求。
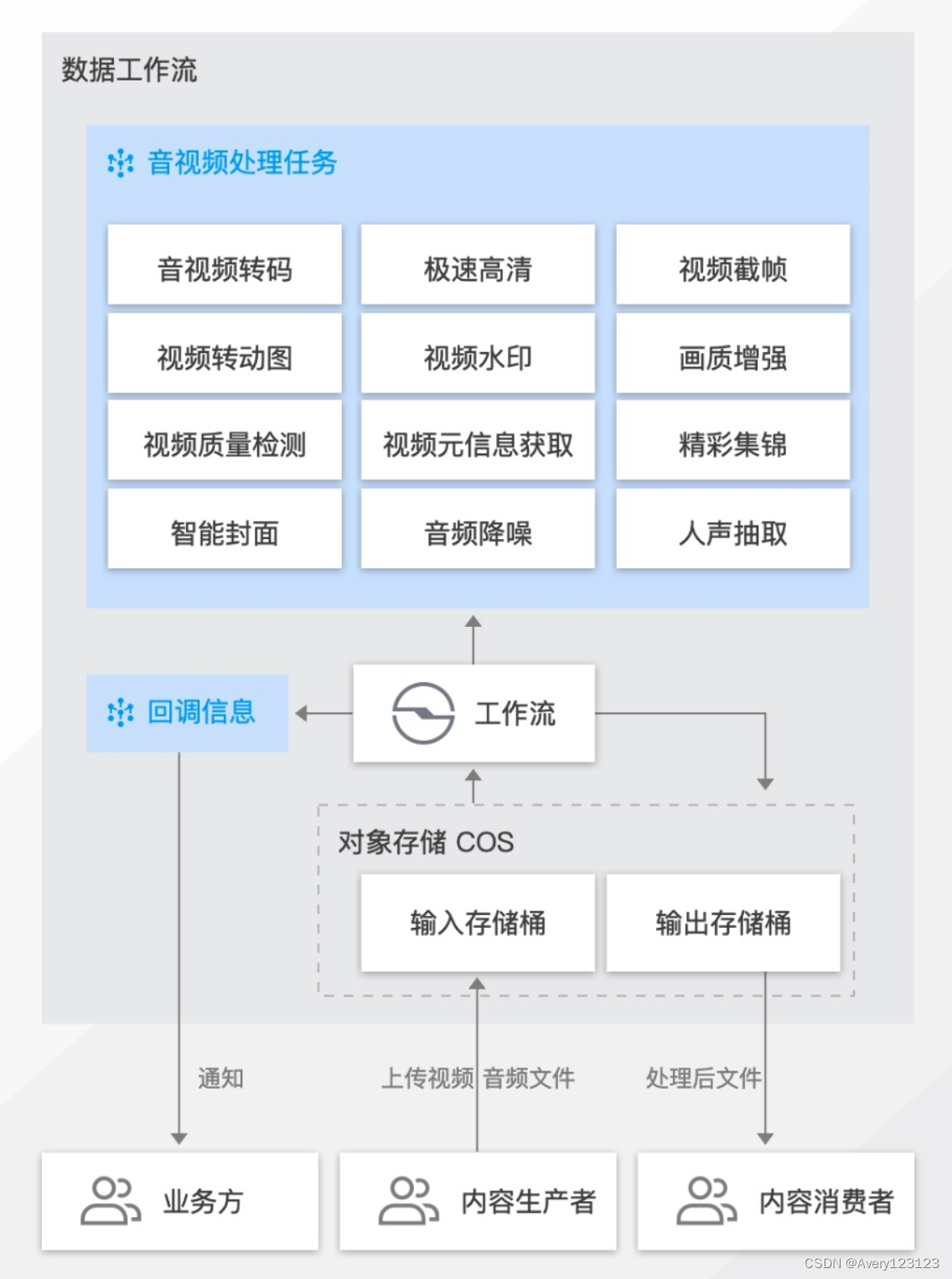
媒体处理
数据万象 CI 为用户提供音视频转码、超分辨率、老片修复、智能封面、音频降噪、语音合成、视频标签、数字水印等各类型存储云原生音视频处理能力,通过数据工作流的衔接,满足对象存储 COS 上数据的多媒体内容处理需求,有力覆盖音视频内容生产中编辑、转码、质量检测、画质优化各业务环节,适配传媒、教育、电商等各行业音视频场景。
内容审核
数据万象 CI 为用户低延时、准确、标签丰富的内容审核服务,采用前沿的识别算法,结合海量的违规数据进行训练建模,对用户业务中的图片、音视频、文本、文档、网页进行敏感内容审核,过滤场景包括色情性感、违法违规、广告宣传等多个场景下的数百个标签,能够做到识别准确率高、召回率高,多维度覆盖对内容审核的要求,并实时跟进监管要求,不停地更新审核服务的识别标准和能力。
内容识别
数据万象 CI 集成腾讯云 AI 的多种强大功能,基于深度学习等人工智能技术,提供综合性的 AI 智能识别服务,包含图像理解(解析视频、图像中的场景、物品、动物等)、图像处理(一键抠图、图像修复)、图像质量评估(分析图像视觉质量)、图像搜索(在指定图库中搜索出相同或相似的图片)、人脸识别、文字识别、车辆识别、语音识别、视频分析等多维度能力。
文档处理
数据万象 CI 为用户提供哈希值计算、文件解压、多文件打包压缩等文件处理功能,满足用户文件一致性校验、上传文件自动打包或解压的需求,帮助用户进行线上文件处理。
文件处理
针对存储在 COS 上的所有文件,提供哈希值计算、文件解压、多文件打包压缩等文件处理功能。
智能语音
数据万象 CI 通过先进的深度学习技术为用户提供高效、便捷的智能语音服务,涵盖语音合成、语音降噪、音伴分离等处理能力,满足对音频文件的多类型处理需求,适用于通勤导航、智能家居、网络k歌、虚拟社交等场景。
使用方式
数据万象提供如下方式进行数据处理的配置和管理:
控制台:登录 CI 控制台,通过几个简单步骤,可快速灵活配置,精准打造任务工作流,提升处理效率。
API:腾讯云也提供了 API 接口方便您进行数据万象能力配置。请参考 API 概览。
SDK:您可以使用 SDK 进行数据万象能力配置与管理。
您也可以通过 COS 使用数据万象:
控制台:登录 COS 控制台,选择您需要使用万象的存储桶,在存储桶管理页可使用万象的全量处理能力。
API:使用 数据处理 API 可直接在 COS 处使用数据万象能力。
SDK:对象存储还提供了丰富多样的 SDK 供开发者使用万象能力,具体操作请见 SDK 概览。
产品优势
数据万象(Cloud Infinite)覆盖全类型的数据处理能力,支持处理对象存储 COS 源以及第三方源中的图片、音视频、文本等多种类型文本文件。提供贴近应用的 AI 能力,提升业务效率,作为业务工具百宝箱围绕海量数据,打造场景化一站式解决方案。
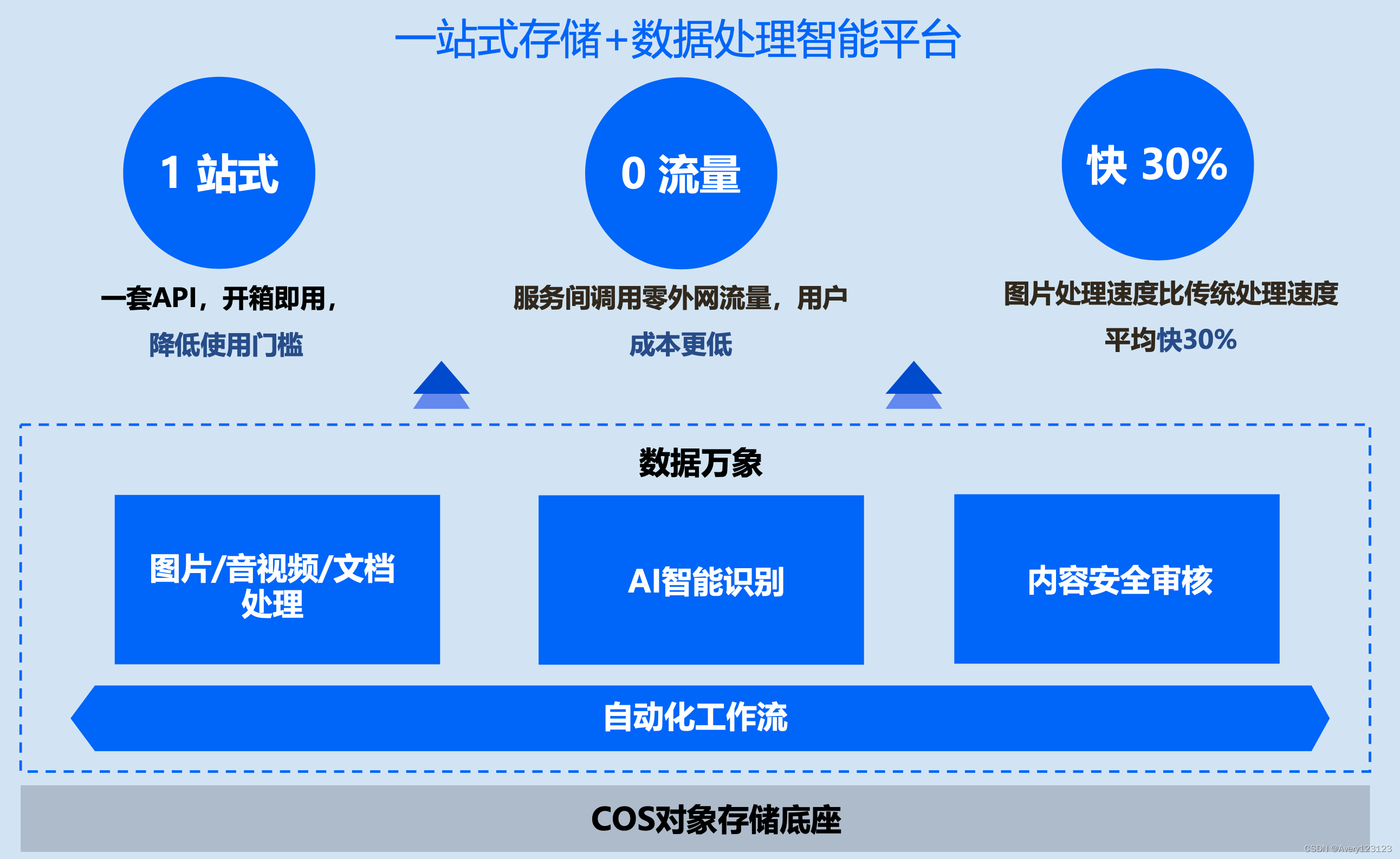
提高效能
为用户提供开箱即用的数据处理和 saas 能力,如内容审核、AI 识别、音视频转码、图片处理等,一站式数据处理,提高数据处理效率,让数据在您的业务体系中释放更大的价值。
降低成本
与对象存储 COS 底层深度集成,提供专业一体化存储+处理的智能存储解决方案,近存储侧的数据处理能力对比第三方服务,减少数据流转中产生的各项服务费用,0 流量的成本极大的降低业务使用 COS 成本。
直接使用COS链接进行下载时处理;
上传时处理集成至 COS SDK,方便易用;
通过控制台开启自动触发数据工作流,无需调用 API 接口,使用更为便捷;
弹性灵活
提供 Serverless 自动扩容弹性资源,无需关注底层。各项能力均支持在控制台进行可视化组装,指定模板,批量生产,帮助用户将各项业务处理链接在一起。
可通过控制台配置实现数据上传时自动触发工作流;
自由组装丰富的任务节点,同时支持自定义处理逻辑;
自主选择业务回调,连接您的业务;
能力丰富
整合腾讯前沿实验室技术能力与腾讯行业领先业务最佳实践,为用户提供丰富的功能支持。
图片处理:压缩、裁剪、格式转换、图像增强、智能抠图、图像修复、图片版权保护(明水印、盲水印)等。
音视频处理:转码、精彩集锦、极速高清、智能封面、音视频版权保护(视频 DNA、视频数字水印)等。
内容审核:内容审核、病毒检测,图片、音视频、文本、文档、网页等格式均支持等。
文件处理:文件 Hash 计算、文件解压缩、文件打包压缩等。
内容识别:OCR 识别、图像标签、以图搜图 等 AI 能力等。
文档处理:文档在线预览、格式转换、文档水印等。
应用场景
电商场景
电商行业每天都需要处理来自不同终端、不同诉求用户(商家&买家)、不同类型数据(图片、视频、文字、语音)的海量处理需求,使用数据万象以下能力,能帮助用户减少人工处理流程,提升性能与安全保障,有效降低成本。
图片基础处理
一份原图,多份展示,满足客户多种业务场景下的图片需求。
图片压缩
极致的图片压缩效果满足低成本客户图片分发的需求。
-
图片/文本审核
帮助用户有效识别头像、商品图片、评论中的违禁内容,检测场景包括鉴黄、违法违规检测、广告检测。目前支持机器自动审核和专业团队人工复审,全方位保障平台的内容安全。 -
商品抠图
利用腾讯云强大的 AI 能力,支持识别出图像中的商品主体,并对背景信息予以去除,生成透明背景的商品图片素材,适用于电商海报智能生成、深色模式适配等功能。 -
以图搜图
可对图片库内的图片进行特征提取、对比和搜索。
虚拟社交场景
数据万象(Cloud Infinite)提供丰富的音频+视频AI能力,以音视频载体为纽带帮助用户构筑各类虚拟形象进行虚拟社交,帮助用户以更简便的方式打破地域与时间限制进行交流。
-
语音/文本审核
帮助用户有效识别语聊房中音频、文本的违禁内容,检测场景包括鉴黄、违法违规检测、广告检测。目前支持机器自动审核和专业团队人工复审,全方位保障平台的内容安全。 -
语音合成
通过先进的深度学习技术,将文本转换成自然流畅的语音。目前有多种音色可供选择,并提供调节语速、语调、音量等功能。适用于智能客服、语音交互、文学有声阅读和无障碍播报等场景,支持输出 PCM、WAV 和 MP3 编码格式数据。 -
语音识别
对录音文件进行识别,异步返回识别文本,目前支持语言类型包括中文普通话、英语和粤语。同时,数据万象支持对识别结果进行处理,包括脏词屏蔽、语气词过滤、阿拉伯数字智能转换等,满足多种语音识别需求。 -
视频抠图
自动识别视频中的人像,对视频内容进行综合分析后输出人像区域结果视频。
直播场景
各行各业都在投入视频直播、实时音视频等相关业务,企业、平台在布局直播业务时,使用数据万象提供的音视频实时审核,支持以下能力实现
-
音视频转码
提供音频、视频等媒体类文件的转码能力,是文件码流转换成另一个码流的过程。通过转码,可以改变原始码流的编码格式、分辨率和码率等参数,从而适应不同终端和网络环境的播放,并且能减小文件体积,从而减少卡顿并节省存储空间和流量费用。 -
视频水印
数据万象支持同步为媒体资源添加多个水印,提升品牌影响力的同时,减少媒体文件被盗可能性;同时支持静态动态图片、文字等多种水印格式,满足您多场景下的水印需求。 -
视频审核
帮助用户有效识别视频画面中的违禁内容,检测场景包括鉴黄、违法违规检测、广告检测。目前支持机器自动审核和专业团队人工复审,全方位保障平台的安全。 -
视频抠图
对视频内容进行综合分析后输出人像区域结果视频,使用户在弹幕刷屏的情况下,人物画面不受遮挡提升视觉观感。
万象提供的音视频流实时审核方案可为您带来以下优势:
TRTC转推云直播无额外费用
相比于从TRTC直接拉流,通过云直播播放域名拉流产生的出流量费用更低
音视频流自定义保存至COS,轻松应对监管备份要求
支持配置自动审核,无需手动发起。
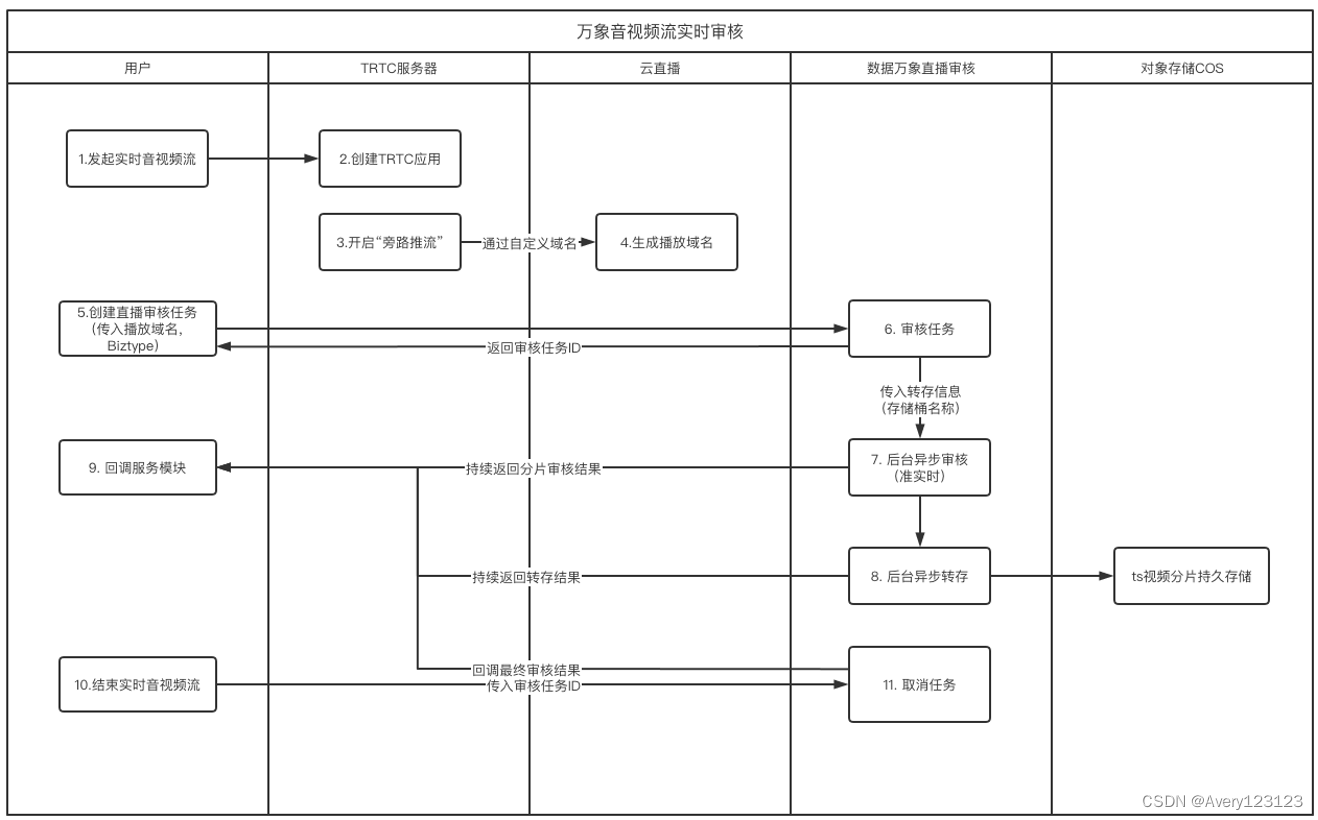
文档在线管理场景
网盘、在线课堂、网站转码等业务都需要满足 PC、App 等多个用户端的文档在线浏览需求,使用数据万象提供的文档处理能力,可快速实现:
-
文档预览
支持近30多种类型文件以图片或 html 格式的预览,最大程度保留在线浏览时源文档样式,解决不同终端对某些文档类型不支持的问题,满足不同终端的文档在线浏览需求。 -
隐私合规保护
提供文本隐私筛查服务,可对文本文件中身份证号、纳税人识别号、工商注册号、军官证、电子邮箱、车牌号、手机号类型的隐私数据进行筛查,防止信息泄露。同时根据涉敏数据类型、数量进行敏感级别的判断(低、中、高),提供文件涉嫌违规的法律法规名称作为参考,满足数据可用性和隐私保护的各种要求。
数据迁移
迁移服务平台
产品概述
迁移服务平台( Migration Service Platform )是腾讯云提供的迁移工具整合以及监控平台。本服务提供腾讯云官方迁移工具,并集成官方认证的第三方迁移工具,帮助用户方便快捷的将系统迁移上云,同时用户可以清晰掌握迁移进度。
统一监控
在 MSP 中统一监控所有的迁移任务,并按照迁移类型聚合展示,帮助用户不会在大规模的复杂迁移过程中被繁杂的迁移数据所淹没。
可视化操作
所有迁移任务状态都可以通过可视化图表进行查看,友好的人机交互界面从不同维度对迁移信息清晰展示,帮助用户对迁移情况一目了然。
简单管理
在 MSP 中,迁移任务可以按项目分组管理。无论是跨时间段分批次迁移,或完整系统一次性大规模迁移,监控同样井井有条。
广泛支持
在腾讯官方迁移方案和工具之外,集成了众多的合作伙伴,为用户提供丰富的迁移选择,无论官方还是第三方,都可无缝连接。
可靠性认证
腾讯云对第三方迁移工具的能力和迁移经验进行严格的评估和认证,确保用户所选方案和工具皆安全可靠,业务迁移万无一失。
应用场景
腾讯官方迁移工具
腾讯官方迁移工具与迁移服务平台无缝集成,用户在任何官方迁移工具中创建的迁移任务,无需任何操作,可直接在迁移服务平台中看到迁移信息和状态。
合作伙伴迁移工具
为应对用户复杂的迁移需求,腾讯云评估并认证了一批能够提供迁移方案和迁移工具的合作伙伴。用户可以采用合作伙伴量身定制的迁移方案或仅使用合作伙伴所提供的第三方工具。
所有经过认证的合作伙伴,所提供的工具均与迁移服务平台 MSP 进行了集成,用户的任何迁移任务均可在迁移服务平台中看到迁移信息和状态。
自行开发迁移工具
迁移服务平台 MSP 的集成标准和 SDK,计划向用户开放,届时所有用户自行开发的迁移工具,只需遵循标准调用 SDK,即可通过迁移服务平台 MSP 进行统一的监控和管理。
云数据迁移
产品概述
云数据迁移(Cloud Data Migration,简称 CDM)是腾讯云提供的 TB - PB 级别的数据迁移上云服务。CDM 使用专用迁移设备将数据从您的数据中心快速高效地迁移上云,并且采用 RAID、加密等多种方式对迁移过程的数据进行安全保障, 最大程度降低数据损坏和泄露的风险。
腾讯云 CDM 的使用方式非常简单。首先,您需要在 CDM 控制台创建并提交一个迁移任务,然后腾讯云会将专用迁移设备邮寄给您。当您收到设备之后,需要将其加入到您的本地网络环境中,与您的数据中心建立连接。接通后您就可以进行数据拷贝操作,在拷贝数据的过程中,迁移设备会对数据进行自动加密和校验。当您拷贝完所有的数据,只需在控制台上对当前任务提交回寄申请,腾讯云会负责把设备回收并将您的数据上传云端。在整个迁移过程中,您都可以随时在 CDM 控制台跟踪查看任务状态。
产品功能
高效传输
迁移设备采用万兆网卡进行网络连接,并且针对小文件传输进行了优化处理,以最大程度缩短数据传输的时间。当您有1PB数据量需要迁移时,1Gbps的网络带宽环境下迁移需要近4个月时间,若使用多台迁移设备同时工作仅需数天就能完成,大大缩短了迁移耗时。
安全保护
迁移设备会对拷贝的数据进行自动加密处理,密钥不会发送到设备或存储在设备上,保证数据不会被其他人获取。同时还会采用 RAID5 磁盘阵列保护数据完整性,防止因磁盘遗失损坏而造成数据丢失。所有数据上传至云端后,腾讯云会对设备里的数据进行彻底擦除,解除您对迁移中数据安全的烦恼。
状态跟踪
腾讯云会实时记录迁移任务的最新状态,并且会通过邮件、短信的方式通知您的任务状态更新,您也可以在 CDM 控制台随时查看任务的当前状态。
应用场景
海量数据备份归档
根据数据使用频率的不同,可以将数据划分为热点数据,低频数据以及归档数据。而企业在考虑成本和风险的时候,通常会将关键数据进行异地容灾,将低频和归档数据备份至云端,在有效控制风险的同时降低存储成本。您可以将关键数据迁移至腾讯云 对象存储(Cloud Object Storage,COS),而云数据迁移(Cloud Data Migration,CDM)可以帮助您在节省迁移成本的同时快速有效地完成海量数据的备份归档。
云端数据分析处理
海量数据通常蕴含着巨大的商业价值,您可以利用腾讯云数据迁移将本地数据快速安全地迁移至腾讯云对象存储中,配合使用腾讯云提供的批量计算、离线计算等计算服务,为您的存储数据挖掘潜在的价值。
弱网环境迁移数据
许多行业数据(例如地理数据、环境数据等)所处地域环境网络信号较差,在上传数据的过程中通常面临着成本高、速度慢的障碍。此时,腾讯云数据迁移 CDM 绝对是一个得力助手,可以协助您快速高效地搬迁数
混合云存储
存储网关
产品概述
什么是存储网关
存储网关(Cloud Storage Gateway,CSG)是腾讯云提供的混合云存储服务。您可以通过 CSG 使用标准文件共享协议访问位于 对象存储(Cloud Object Storage,COS) 中的数据,无缝接入公有云,实现数据的实时共享和冷热分层。腾讯云 CSG 可以根据您的业务需求灵活地部署在云上或者本地,让您更轻松地进行数据的云上处理、备份归档以及灾难恢复。腾讯云 CSG 旨在让您更加专注于自有业务的发展,而不受存储技术门槛以及成本的困扰。
网关类型
文件网关
在客户本地网络环境中或公有云环境中部署文件网关后,可以将 COS 存储桶以网络文件系统挂载到多个服务器上,用户可以使用 POSIX 文件协议读写 COS 上的对象,同时,通过网关上传到 COS 的数据可以使用由腾讯云提供的诸如 CDN 加速、CI 多媒体处理、CHDFS 大数据处理等服务。
产品功能
协议转换
支持将 RESTful API 的公有云存储作为 NFS 文件系统直接挂载到本地网络中,即装即用。对于已经部署基础设施的企业来说,接入公有云不再需要改变现有网络结构,也无需开发对齐网络程序的接口,使用 CSG 即可接入公有云,享受海量云端存储的低价及弹性。
访问加速
CSG 通过缓存优化算法,将经常访问的热数据存储到本地,而全量数据则保存在公有云 COS 中。相比直接使用 COS,您可以更迅速地获取常用数据,同时,本地仅需提供缓存所需存储空间,您可以更有效地节省在基础设施和运营维护上投入的成本。
灾难恢复
CSG 采取无状态设计,不持久存储任何数据,当某地业务及网关机器因故障受损时,您可以再部署一个新的网关来恢复已存储至 COS 存储桶中数据的目录结构,并重新挂载到其他业务机器上,保障您自有业务的高可用性。
网络资源调配
CSG 支持限制自定义时间段的上传/下载速率,实现数据的定时上传,帮助您更充分地利用出口带宽资源,节约数据传输成本。
产品优势
即装即用
对象存储使用 HTTP RESTful 接口,而企业的应用程序或存储系统通常采用传统协议,因此无法直接访问公有云对象存储服务。而使用存储网关 CSG,您无需二次开发,也无需新增机架空间、供电或冷却等设备,即可将公有云对象存储以 NFS 的形式挂载在本地系统中。
海量存储
存储网关(Cloud Storage Gateway,CSG)能够配合公有云对象存储(Cloud Object Storage,COS)提供海量的数据存储,单个文件系统最大支持1PB。同时,通过缓存机制,实现冷热数据分离,将经常读取的热数据缓存在本地,而较冷数据则保存至云端,这样,您既可以享受本地磁盘带来的访问性能,又可以同时拥有云端近乎无限的存储能力。
经济高效
您无需为硬件设施及日常运维付费,COS 根据实际使用量收取费用,没有最低使用限制,可根据您的业务需求实时扩容。
安全持久
COS 作为 CSG 后端的公有云存储,采用多种备份策略,综合持久性最高可达99.9999999999%(12个9),保护所有数据的稳定和安全。
使用场景
存储资源分配
拓展本地 NAS 和 SAN 存储阵列不光需要耗费硬件成本和人力部署成本,对存储架构设计本身也是挑战。而使用存储网关(Cloud Storage Gateway,CSG)将公有云存储接入到本地存储系统架构后,当面临数据迁移、大数据分析等需求或业务数据激增时,混合云存储架构可以让您轻松协调工作负载。
冷热数据分离
业务数据均存储在本地设备上不仅费用较高,而且维护繁琐。CSG 的缓存功能,会自动将对访问性能要求较高的热数据缓存到本地、将延迟不敏感的冷数据上传到云端保存,实现数据的冷热分层。同时,冷、热数据比例变化时,亦可随时按需扩展或调整本地缓存区与云端存储的比例,降低使用成本。
备份及归档
数据上传到公有云对象存储(Cloud Object Storage,COS)后,COS 会以多种备份策略对数据进行存储以保持其持久性。同时,您可通过版本控制等功能实现多版本数据的备份及归档。
灾难恢复
CSG 采取无状态设计,不持久存储任何数据,当某地业务及网关机器因故障受损时,您可以再部署一个新的网关来恢复已存储至 COS 存储桶中数据的目录结构,并重新挂载到其他业务机器上,保障您自有业务的高可用性;同时,您也可以利用 COS 提供的跨地域复制能力,将存储桶中数据备份到不同地域下,进一步提高容灾能力。
数据处理及分发
通过 CSG 上传到 COS 中的文件,支持与其他腾讯云产品联动,包括 CDN 、CI、CHDFS 等,提供「存储 + 处理」一体化解决方案。
智能存储
智能视图计算平台
产品概述
智能视图计算平台(Intelligent Viewdata Computing)是腾讯云面向视图数据所提供的边缘接入治理、云存储及 AI 多模态分析一体化产品。依托腾讯云遍布全球的边缘视图节点和领先的 AI 分析能力,可实现终端设备从云下到云上全链路的接入管理、数据治理、数据存储、AI 智能分析等服务。
产品架构图

产品优势
融合架构、联网共享
采用云-边-端混合云架构,提供公有云/私有云/混合云产品部署方式,满足城市级大规模终端接入能力,并支持平台间数据级联共享,同时提供高稳定性高可用的平台服务。
数据可靠、安全防护
数据存储于腾讯云对象存储 COS(Cloud Object Storage),提供异地容灾和资源隔离机制,保证业界领先的数据持久性。同时提供防盗链及数据 SSL 加密传输服务,确保数据安全不丢失。
多类场景、智能原生
具备多类别 AI 算法能力,如目标识别、车辆车牌识别、人体识别、精彩集锦等,同时提供 AI 智能化应用和场景化算法定制服务,可针对性地帮助客户解决不同场景的业务需求。
超低成本、灵活易用
支持 GB/T28181、RTMP 等多种视图接入协议并兼容主流厂商私有协议,实现设备零改造接入;北向 OpenAPI 完全开放便于集成或二次开发;同时提供一站式视频闭环服务,可享受低延时的视频播放体验。
应用场景
智慧门店
可将连锁门店分散的摄像头统一接入云端,进行设备集中管理、视频集中调阅和数据分层存储。
同时结合客流统计、目标识别等算法分析,促进门店智能化升级,助力业务降本增效。
智慧家居
针对家庭监控、智能猫眼、视频门铃等设备,支持设备按需拉流上云,同时也支持将视频告警片段实时上传,极大降低了上云成本。
同时结合宠物识别、目标识别、精彩集锦等算法,助力提升家居场景内容生产力。
园区工地
企业园区、建筑工地等场景下的摄像头多为物联网摄像头且多处于户外,支持设备分时段拉流上云及存储,进一步节省网络消耗。
同时设备可进行 PTZ 转动控制、变倍变焦等操作,以及移动端调阅查看,极大推动安全生产全流程监管。
明厨亮灶
将厨房场景下的摄像头统一接入,支持数据共享和本地多端实时播放,既满足监管部门的要求,又满足了顾客的食品安全心理。
同时结合口罩识别、厨师帽识别、厨师服识别、接打电话识别、吸烟检测等算法,进一步保障食品安全操作规范。
数据库
关系型数据库
TDSQL-C MySQL 版
TDSQL-C MySQL 版(TDSQL-C for MySQL)是腾讯云自研的新一代云原生关系型数据库。融合了传统数据库、云计算与新硬件技术的优势,为用户提供具备极致弹性、高性能、海量存储、安全可靠的数据库服务。TDSQL-C MySQL 版100%兼容 MySQL 5.7、8.0。实现超百万级 QPS 的高吞吐,最高 PB 级智能存储,保障数据安全可靠。
产品概述
TDSQL-C MySQL 版采用存储和计算分离的架构,所有计算节点共享一份数据,提供秒级的配置升降级、秒级的故障恢复,单节点可支持百万级 QPS,自动维护数据和备份,最高以GB/秒的速度并行回档。
TDSQL-C MySQL 版既融合了商业数据库稳定可靠、高性能、可扩展的特征,又具有开源云数据库简单开放、高效迭代的优势。TDSQL-C MySQL 版引擎完全兼容原生 MySQL,您可以在不修改应用程序任何代码和配置的情况下,将 MySQL 数据库迁移至 TDSQL-C MySQL 版引擎。
核心设计理念
Cloud Native 应 “ 云 ” 而生 —— 云原生数据库面向服务架构
TDSQL-C MySQL 版数据库是搭建在腾讯云现有的高效稳定的云服务之上,能快速地搭建出高性能、高可用、高可靠的一套云数据库。
Creative “ 分 ” 而 治之 —— 计算与存储分离,日志即数据库
TDSQL-C MySQL 版实现了“日志即数据库”的架构,将计算(CPU、内存)与存储分离,通过对 MySQL 内核的深度改造,卸载了不必要的功能模块,实现了无状态的计算节点,使得计算资源可以在秒级的时间内完成弹性扩展和故障恢复,并将其构建在腾讯云分布式云存储之上实现了存储资源的池化。
Comprehensive “ 兼 ” 容并包 —— 全面兼容新版开源数据库
100%兼容开源数据库引擎 MySQL,还会定期实现对新版本的支持,几乎无需改动代码,即可完成现有数据库的查询、应用和工具平滑迁移,为用户大大降低数据迁移的成本和风险。
Cohesive 相 “ 辅 ” 相成 —— 极简的软件优化释放硬件红利
TDSQL-C MySQL 版通过数据库内核、系统架构等软件优化,有效提升了数据库性能和稳定性,较传统架构的数据库产品有了大幅提升。在相同硬件条件下性能更为出众,即先释放硬件红利,并完美适配新硬件的发展趋势,最大程度上提升数据库服务效能。
Cost Effective 事半功 “ 倍 ” —— 性能成倍提升,按量计费
我们需要一个在性能上能超过传统数据库的云数据库,并且可以给用户减少成本压力,因为云计算的本身其实是要给客户一个很实惠的服务,所以 TDSQL-C MySQL 版,可实现真正的按量计费和弹性的扩缩容。
产品优势
完全兼容
TDSQL-C MySQL 版将开源数据库的计算和存储分离,存储构建在腾讯云分布式云存储服务之上,计算层全面兼容开源数据库引擎 MySQL 5.7、8.0,业务无需改造即可平滑迁移。
超高性能
单节点百万 QPS 的超高性能,可以满足高并发高性能的场景,保证关键业务的连续性,并可进一步提供读写分离以及读写扩展性。
海量存储
最高支持 PB 级的海量存储,为客户免去面对海量的数据时频繁分库分表的繁琐操作,同时支持数据压缩,在海量数据检索和写入性能上进行了大量优化。
秒级故障恢复
计算节点实现了无状态,支持秒级的故障切换和恢复,即便计算节点所在的物理机宕机也可以在一分钟之内恢复。
数据高可靠
集群支持安全组和 VPC 网络隔离。自动维护数据和备份的多个副本,保障数据安全可靠,可靠性达99.9999999%。
弹性扩展
计算节点可根据业务需要快速升降配,秒级完成扩容,结合弹性存储,实现计算资源的成本最优。
快速只读扩展
计算节点可根据业务需要快速添加只读节点,一个集群支持秒级添加或删除1个 - 15个只读节点,快速应对业务峰值和变化场景。
快照备份回档
基于数据多版本的秒级快照备份对用户的数据进行连续备份保护,免去主从架构备份回档数据的同步和搬迁,最高以GB/秒的速度极速并行回档,保证业务数据迅速恢复。
Serverless 架构
Serverless 是腾讯自研云原生数据库 TDSQL-C MySQL 版的无服务器架构版,自动扩缩容,仅按照实际使用量计费,不用不计费,轻松应对业务数据量动态变化和持续增长。
应用场景
TDSQL-C MySQL 版为用户提供具备超高弹性、高性能、海量存储、安全可靠的数据库服务,可帮助企业轻松应对诸如商品订单等高频交易、伴随流量洪峰的快速增长业务、游戏业务、历史订单等大数据量低频查询、金融数据安全相关、开发测试、成本敏感等的业务场景。以下为您从互联网移动 APP、游戏应用、电商直播教育行业、金融保险企业来介绍 TDSQL-C MySQL 版能够应对这些业务场景的条件和优势。
互联网移动 App
- 商用数据库级别的高性能、高可靠,定制开发的多项内核优化以及企业级特性保障业务平稳高效的运行,让研发人员专注于业务逻辑的开发,无后顾之忧。
- 解决了传统主备架构弹性能力差,业务压力大时的同步效率低,主备切换时间不可控等问题,在提供高性能的同时保证了系统的高可用性和业务的连续性。极大的减轻了运营和运维人员的工作量。
- 全面兼容开源数据库 MySQL,原有业务应用几乎不用更改即可接入 TDSQL-C MySQL 版,助力企业平滑上云。
- 自带高可用架构,自动维护数据多副本,自动进行数据的校验和修复,减少人工干预,数据可靠性达99.9999999%。
-
游戏应用
- 敏捷灵活的弹性扩展,无需预先购买存储,可根据业务需要快速升降级,快速扩容,轻松应对业务峰值。
- 最高 PB 级海量存储,按存储量计费,自动扩容,免去合区合服的繁琐操作,实现资源和成本的最优配置。
- 秒级的快照备份和快速回档能力,在多副本的基础上对用户的数据进行连续保护,是互联网和游戏行业的最佳选择。
电商直播教育行业
- 支持秒级的升配,最多可扩展至15个节点,快速弹升 QPS 的能力。解决传统数据库的升配时间会随着存储量的大小、宿主机资源的情况而不断上升的问题。
- 通过引擎的优化 IOPS 能力的提升,提供高并发状态下优秀的数据写入能力,轻松应对业务峰值。
- 读写节点和只读节点之间采用物理复制的方式,只读节点与读写节点延迟大大降低,满足电商场景中买家卖家数据一致性读取需求。
金融保险企业
- 多可用区架构,在多个可用区内都有数据备份,为数据库提供容灾和备份。
- 采用白名单、VPC 网络等全方位的手段,对数据库数据访问、存储、管理等各个环节提供安全保障。
- 采用共享分布式存储的设计,彻底解决了主从(Master-Slave)异步复制所带来的备库数据非强一致性的问题。
产品架构
TDSQL-C MySQL 版基于 Cloud Native 设计理念,既融合了商业数据库稳定可靠、高性能、可扩展的特征,又具有开源云数据库简单开放、高效迭代的优势。本文将介绍 TDSQL-C MySQL 版的产品架构及特点。
架构图
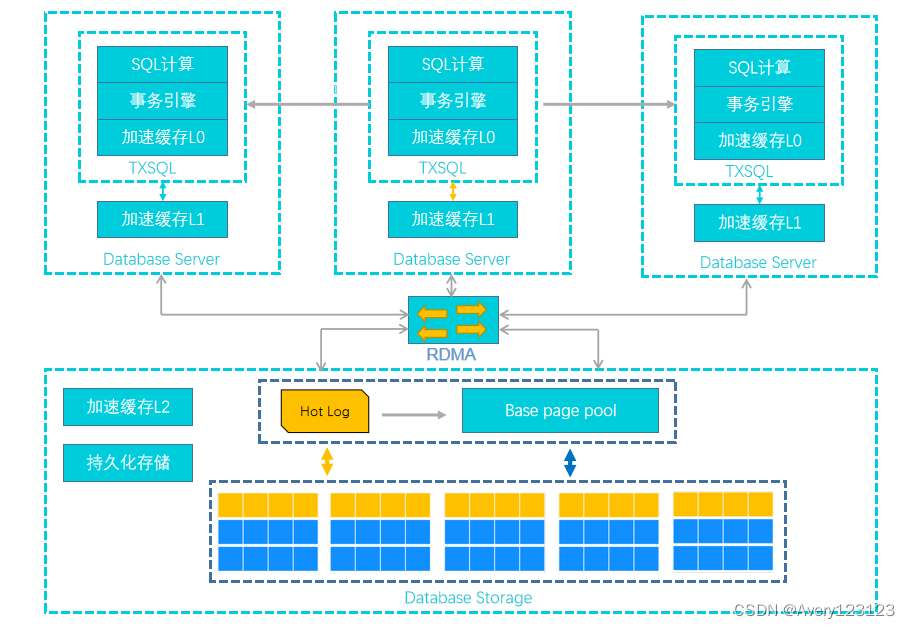
一写多读
TDSQL-C MySQL 版,一个集群中包含一个主节点和最多15个只读节点。主节点处理读写请求,只读节点仅处理读请求。
计算与存储分离
TDSQL-C MySQL 版采用计算与存储分离的设计理念,满足公共云计算环境下根据业务发展弹性扩展集群的刚性需求。数据库的计算节点(Database Engine Server)仅存储元数据,而将数据文件、Redo Log 等存储于远端的存储节点(Database Storage Server)。各计算节点之间仅需同步 Redo Log 相关的元数据信息,极大降低了主节点和只读节点间的复制延迟,而且在主节点故障时,可快速拉起新节点实现平滑替换。
自动读写分离
自动读写分离是 TDSQL-C MySQL 版提供的一个透明、高可用、自适应的负载均衡能力。通过配置数据库代理地址,SQL 请求自动转发到 TDSQL-C MySQL 版的各个节点,提供聚合、高吞吐的并发 SQL 处理能力。
高速链路互联
支持全链路 RDMA(Remote Direct Memory Access)传输,即将数据直接从一台计算机的内存传输到另一台计算机,无需双方操作系统的介入,进一步优化了关键路径的系统性能,降低请求延迟,使 I/O 性能不再成为瓶颈,存储的多个副本之间也采用 RDMA 网络。
共享分布式存储
多个计算节点共享一份数据,而不是每个计算节点都存储一份数据,极大降低了用户的存储成本。基于全新打造的分布式块存储和文件系统,存储容量可以在线平滑扩展,不会受到单个数据库服务器的存储容量限制,可承载 PB 级别的数据规模。
数据多副本强一致
数据库存储节点的数据采用多副本形式,确保数据的可靠性,并通过多副本强一致策略保证数据的一致性。数据文件采用三副本强一致,保证数据可靠性,计费仅按照“单副本”数据量统计。
TDSQL-C PostgreSQL版
产品概述
TDSQL-C PostgreSQL 版(TDSQL-C for PostgreSQL)是腾讯云自研的新一代高性能高可用的云原生数据库,其融合了传统数据库、云计算与新硬件技术的优势,100% 兼容 PostgreSQL。
TDSQL-C PostgreSQL 版采用存储和计算分离的架构,所有计算节点共享一份数据,提供秒级的配置升降级、秒级的故障恢复、以及优异的数据备份性能。整体实现超百万级 QPS 的高吞吐,海量分布式智能存储,并在此能满足秒级的数据库扩缩容能力,从容的协助业务应对流量突增的数据库瓶颈问题。
产品优势
完全兼容
基于开源 PostgreSQL 进行改造而来,完全兼容 PostgreSQL 优秀特性,对于 kv、json、xml 等多种数据类型;复杂 SQL 查询性能;高并发事务处理等企业级业务都能完美支撑。
超高性能
基于日志即数据库理念,计算节点仅写日志,数据操作下沉至存储。极大减少中间 IO 消耗,提升数据库性能,相较于开源数据库性能提升300%。
海量存储
底层存储分布式实现可支持存储动态透明扩展,存储的扩容与缩容,对业务完全无感。并且无需数据搬迁,可支持秒级数据可用容量的弹性能力。
秒级故障恢复
计算节点实现了无状态,支持秒级的故障切换和恢复,即便计算节点所在的物理机宕机也可以在一分钟之内恢复。
快速弹性变配
得益于云原生存算分离的实现,可支持秒级的计算节点横向和纵向扩容,以满足快速变化的业务需求。通过定义相关策略,您可以确保所使用的数据库在需求高峰期无缝扩展,保证程序的可用性。在业务平稳后自动回落。
快速只读扩展
计算节点可根据业务需要快速添加只读节点,一个集群支持秒级添加删除1个 - 3个只读节点,快速应对业务峰值和变化场景。
快照备份回档
基于数据多版本的秒级快照备份对用户的数据进行连续备份保护,免去主从架构备份回档数据的同步和搬迁,最高以GB/秒的速度极速并行回档,保证业务数据迅速恢复。
更高可用
云原生数据库基于自研分布式存储,多计算节点共享存储。当计算节点出现故障,可快速基于存储启动新计算节点,保证业务访问连续性,计算节点可达到99.95%。存储为 RAFT 多副本,数据写入存储,必须保证两节点以上写入成功。
灵活成本
基于云端数据存储,极大节省了您搭建高可用数据库的基础设施成本和后期的运维成本。并且极致的弹性体验使得计算资源可灵活调配,当业务高峰时扩容,低峰时缩容。最大程度节省成本。
应用场景
高性能高可用企业应用
- 商用数据库级别的高性能、高可靠, 1/15的成本使得 TDSQL-C PostgreSQL 版成为企业关键业务(Mission Critical)的最佳选择。定制开发的多项内核优化以及企业级特性保障业务平稳高效的运行,让研发人员专注于业务逻辑的开发,无后顾之忧。
- 解决了传统主备架构弹性能力差,业务压力大时的同步效率低,主备切换时间不可控等问题,在提供高性能同时保证了系统的高可用性和业务的连续性。极大的减轻了运营和运维人员的工作量。
- 全面兼容开源数据库 PostgreSQL,并且在开源基础上不断优化,原有业务应用几乎不用更改即可接入 TDSQL-C PostgreSQL 版,助力企业平滑上云。
- 自带高可用架构,自动维护数据多副本,自动进行数据的校验和修复,减少人工干预,数据可靠性达99.9999999%。
互联网和游戏业务 - 敏捷灵活的弹性扩展,无需预先购买存储,可根据业务需要快速升降级,快速扩容,轻松应对业务峰值。
- 50TiB海量存储,按存储量计费,自动扩容,免去合区合服的繁琐操作,实现资源和成本的最优配置。
- 秒级的快照备份和快速回档能力,在多副本的基础上对用户的数据进行连续保护,是互联网和游戏行业的最佳选择。
归档存储业务场景
- 随着业务不断发展伴随着历史数据的飞速增长,数据库容量越来越大,经常超过10T、几十T级别。TDSQL-C PostgreSQL 版底层分布式存储的实现,可完美支持归档数据存储场景。
HTAP 业务场景
- TDSQL-C PostgreSQL 版采用计算和存储分离架构,支持数据库服务器的 CPU、内存能够快速扩容。并且 PostgreSQL 原生支持并行查询,可充分利用数据库资源,使查询耗时指数级下降,并且可解决计算量较大的查询、多表连接查询、日常报表查询等轻分析类业务需求。
云数据库 MySQL
产品概述
云数据库 MySQL(TencentDB for MySQL)是腾讯云基于开源数据库 MySQL 专业打造的高性能企业级数据库服务,让用户能够在云中更轻松地设置、操作和扩展关系数据库。
云数据库 MySQL 主要特点如下:
- 云存储服务,是腾讯云平台提供的面向互联网应用的数据存储服务。
- 完全兼容 MySQL 协议,适用于面向表结构的场景;适用 MySQL 的地方都可以使用云数据库。
- 提供高性能、高可靠、易用、便捷的 MySQL 集群服务,数据可靠性能够达到99.9999999%。
- 整合了备份、扩容、迁移等功能,同时提供新一代数据库工具 DMC ,用户可以方便地进行数据库的管理。
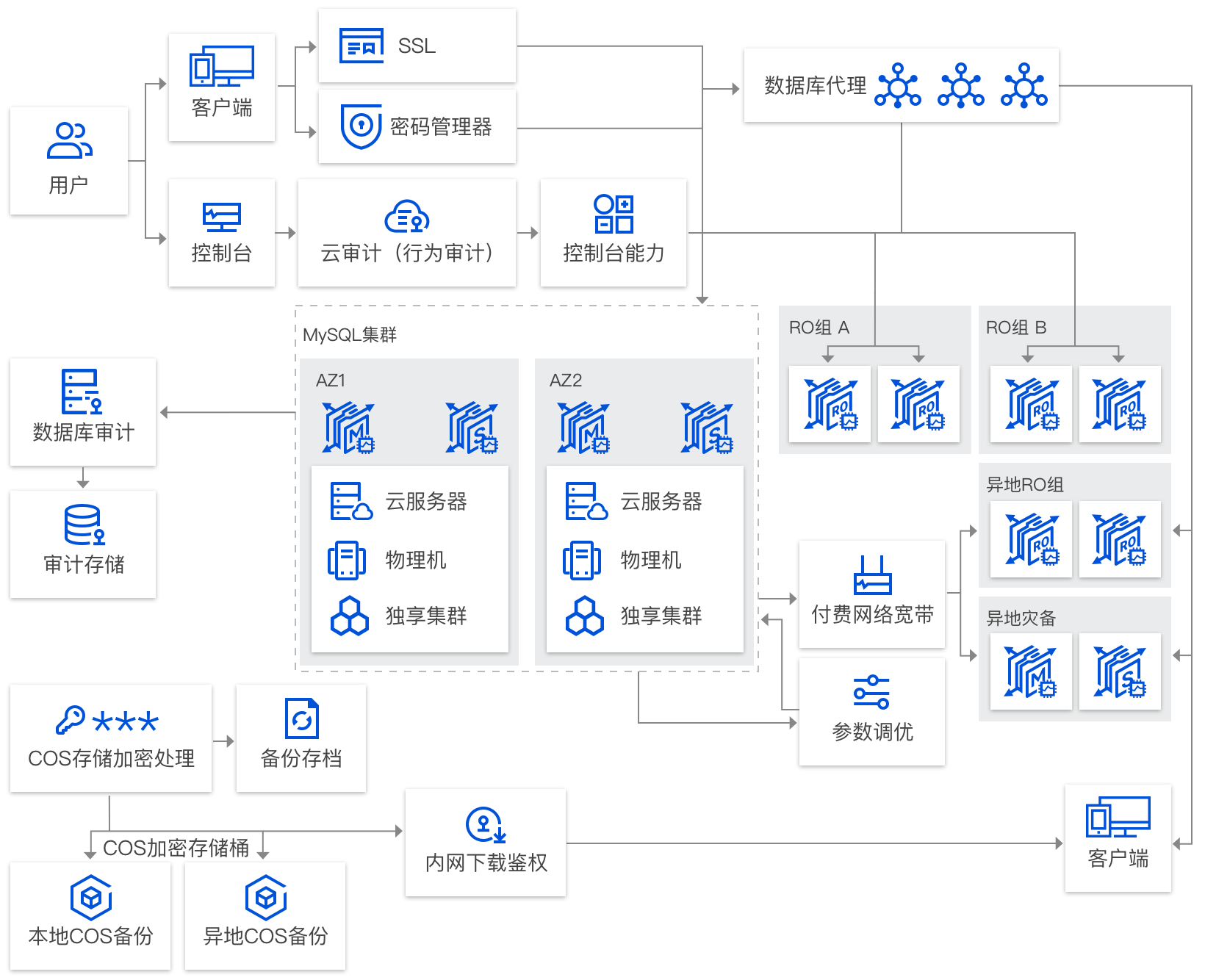
产品架构
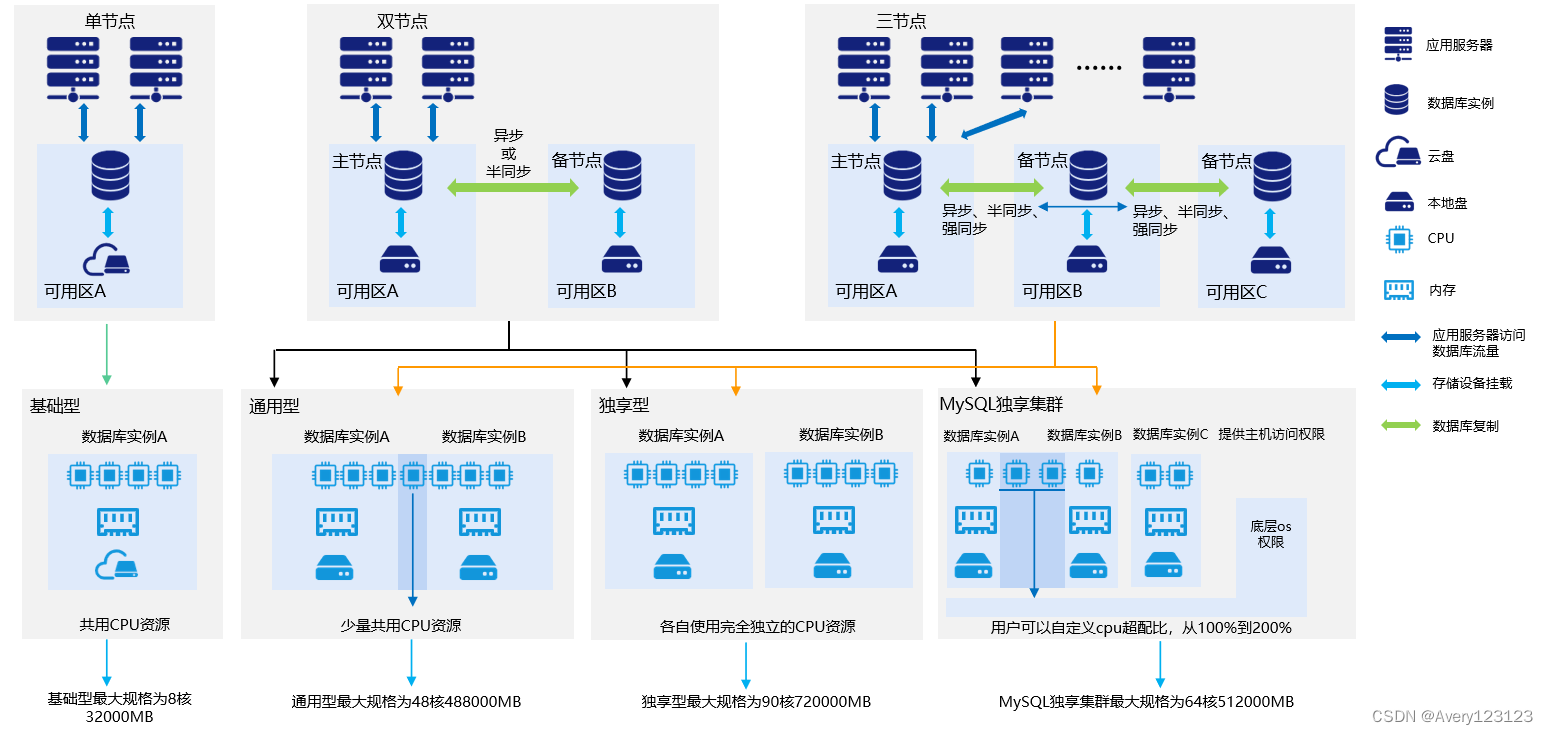
- 实例:腾讯云上的 MySQL 数据库资源。
- 实例类型:MySQL 实例在节点数量、读写能力与地域部署上不同的搭配。
- 只读实例:仅提供读功能的 MySQL 实例。
- RO 组:提供给用户管理一个或多个只读实例的逻辑工具,可满足读写分离场景下负载均衡,并显著提高用户数据库的读负载能力。
- 灾备实例:提供跨可用区、跨地域灾备能力的 MySQL 实例。
- 私有网络:自定义的虚拟网络空间,与其他资源逻辑隔离。
- 安全组:对 MySQL 实例进行安全的访问控制,指定进入实例的 IP、协议及端口规则。
- 地域和可用区:MySQL 实例和其他资源的物理位置。
- 腾讯云控制台:基于 Web 的用户界面。
- 数据库代理:位于云数据库服务和应用服务之间的网络代理服务,用于代理应用服务访问数据库时的所有请求。
产品优势
云数据库 MySQL 的优势
腾讯云数据库 MySQL 为用户提供更轻松地云上设置、操作和扩展数据库服务,具备灵活易用、高可用、高数据安全可靠性等优势,以下从不同的实例架构为您介绍产品优势。
云数据库 MySQL 与自建 MySQL 对比优势
针对传统自建 MySQL 在使用过程中经常出现的性能瓶颈、运维困难、数据可靠性和可用性难题,云数据库 MySQL 都做了专项优化,更容易部署、管理和扩展。
相比于自建数据库,云数据库 MySQL 提供命令行和 Web 两种方式管理云数据库,并支持批量数据库的管理、权限设置和 SQL 导入,实现轻松管理海量数据库;提供多种数据导入途径完成初始化,每日自动备份数据,可根据备份文件提供备份保留期内任意时间点回档;提供多维度监控,自定义资源阈值告警,支持慢查询分析报告和 SQL 完整运行报告下载;支持外网访问和 VPC 网络,可通过这些接入方式将云数据库与 IDC、私有云或其他计算资源互联,轻松应用于混合云环境。
应用场景
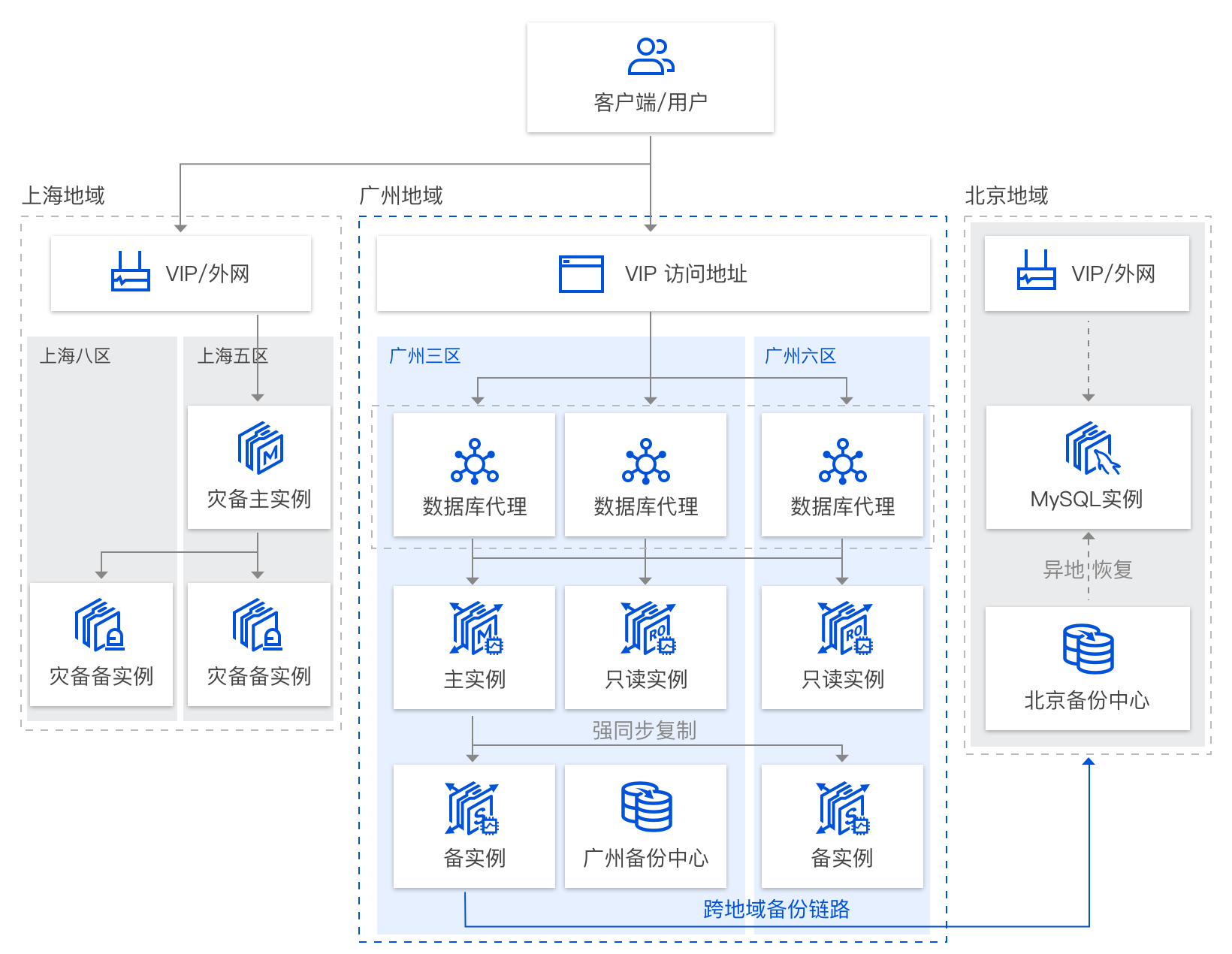
全场景高可用性架构
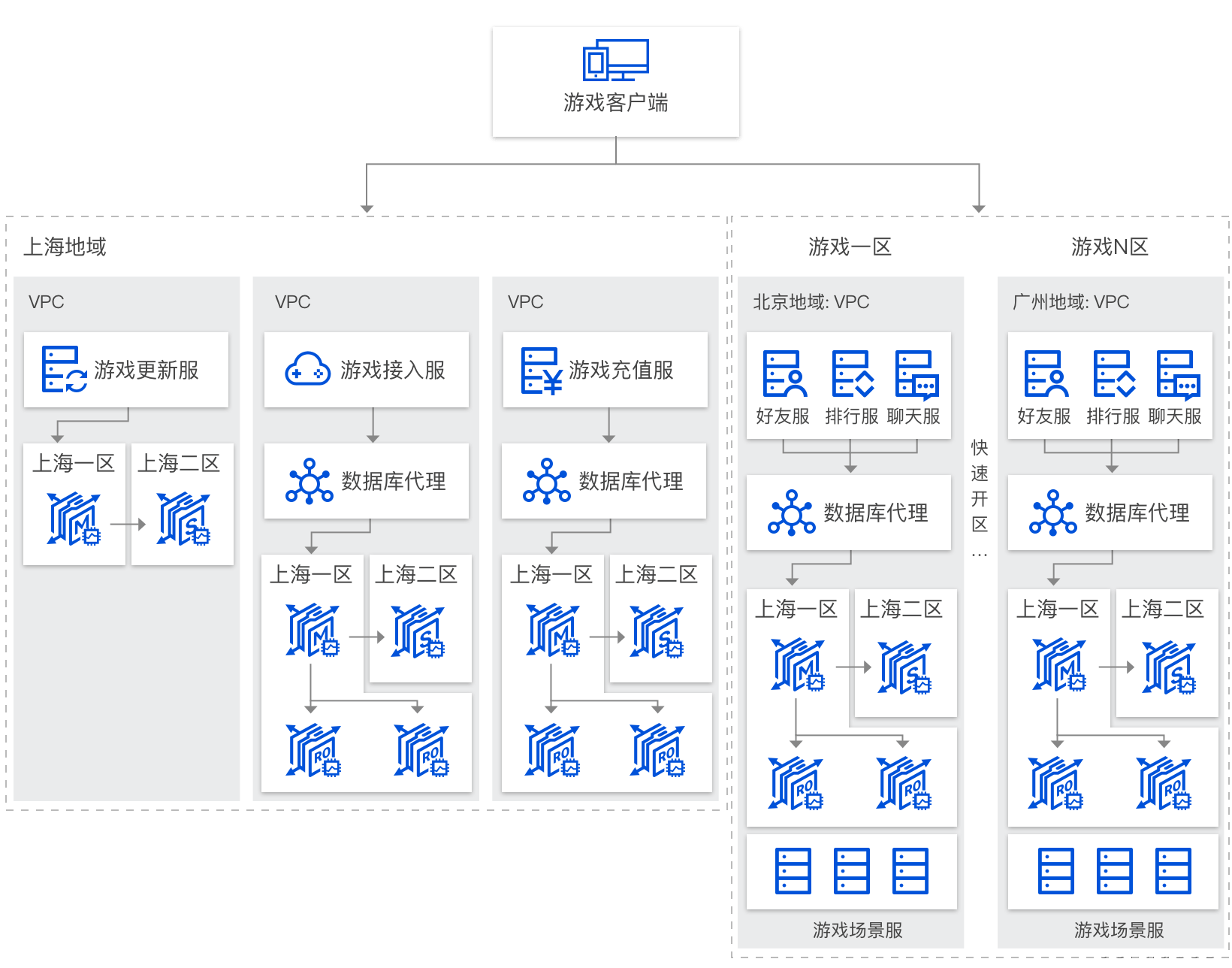
游戏场景
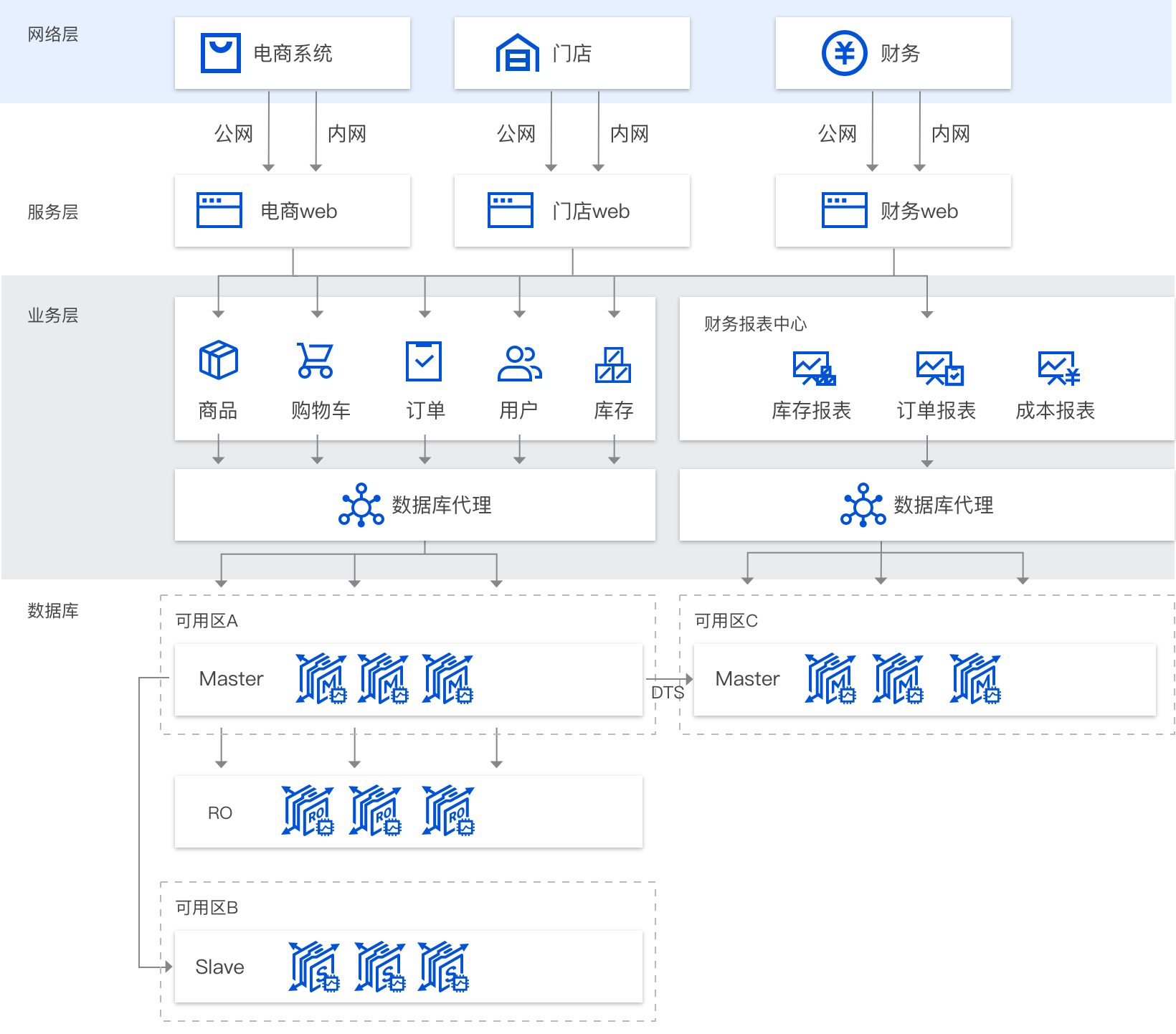
电商场景

金融场景

网站/SaaS 场景
数据库架构
云数据库 MySQL 支持三种架构:单节点(云盘版)、双节点(原高可用版)、三节点(原金融版)
说明
单节点(云盘版)架构目前支持的地域为上海、北京、广州、成都、中国香港、新加坡、法兰克福地域,其他地域后续陆续开放。
双节点(原高可用版)采用一主一备模式,仅主库提供访问服务,备库只提供容灾,不提供访问。
三节点(原金融版)采用一主两备模式,仅主库提供访问服务,两个备库只提供容灾,不提供访问。
云数据库 MariaDB
产品概述
云数据库 MariaDB(TencentDB for MariaDB)是应用于 OLTP 场景下的高安全性的企业级云数据库,一直应用于腾讯计费业务,MariaDB 兼容 MySQL 语法,不仅拥有诸如线程池、审计、异地容灾等高级功能,同时具有云数据库的易扩展性、简单性和高性价比。
相关概念
- 实例:腾讯云上的 MariaDB 数据库资源。
- 实例类型:MariaDB 实例在节点数量、读写能力与地域部署上不同的搭配。
- 只读实例:仅提供读功能的 MariaDB 实例。
- 灾备实例:提供跨可用区、跨地域灾备能力的 MariaDB 实例。
- 私有网络:自定义的虚拟网络空间,与其他资源逻辑隔离。
- 安全组:对 MariaDB 实例进行安全的访问控制,指定进入实例的 IP、协议及端口规则。
- 地域和可用区:MariaDB 实例和其他资源的物理位置。
- 腾讯云控制台:基于 Web 的用户界面。
产品优势
数据强一致性
支持配置强同步复制,在主备架构下,强同步确保主备数据强一致,避免您的数据库在主备切换时丢失数据。当然,您也可以通过修改配置,关闭强同步功能以提高性能。
高安全性
- 防 DDos 攻击:当用户使用外网连接和访问 MariaDB 实例时,可能会遭受 DDoS 攻击。当 MariaDB 安全体系认为用户实例正在遭受 DDoS 攻击时,会自动启动流量清洗功能。
- 系统安全:即使在内网,MariaDB 也处于多层防火墙的保护之下,可以有力地抗击各种恶意攻击,保证数据的安全。另外,物理服务器不允许直接登录,只开放特定的数据库服务所需要的端口,有效隔离具有风险的操作。
- VPC 网络隔离:支持 VPC 网络,以安全隔离内网其他设备的访问。
- 内网风控:腾讯云数据库团队无法直接访问到 MariaDB 物理机或数据库实例,必须通过腾讯云运维管理平台访问,即使是排查问题也必须在安全设备上,且通过内部风控系统的严格管理。
- 对象粒度的权限管控:用户可定义到表级的权限,并允许配置访问 MariaDB 的 IP 地址,指定之外的 IP 地址将被拒绝访问。
- 数据库审计:支持配置数据库审计,记录管理员或用户的操作历史,用于出现风险后的管控。
- 操作日志:系统记录用户访问腾讯云 Web 管理中心操作 MariaDB 的全部记录,常用于事后追溯。
高可用特性
MariaDB 的设计旨在提供高于99.99%的可用性,提供双机热备,或一主两备,两个备机用于透明的故障转移,还提供故障节点自动修复、自动备份、回档等功能,帮助业务更稳定、安全地运行。
-
物理高可用
根据您购买实例配置不同,MariaDB 通常采用一主一备双节点、或一主两备三节点架构。每个节点安装在独立跨机架部署的物理机上,确保不会因为单一设备、机架网络故障或断电影响数据库服务。 -
网络高可用
MariaDB 的每个节点物理机均采用双网卡双连交换机配置,物理网络安全可靠。在实际使用时,TProxy 对接腾讯云网关 TGW;主节点出现故障后,TProxy 最快200ms内切换 DB 路由;若 TProxy 故障,TGW 在1s内负载到其他存活的 TProxy;切换不改变访问 VIP(虚拟 IP),以便屏蔽物理服务器变化带来的影响。 -
备份恢复服务
备份服务:备份模块负责定时对 MariaDB 进行(物理)备份和二进制文件(Binlog)保存,备份文件将上传到安全等级更高的分布式文件集群中(HDFS)中,通常情况下,备份总是在备节点上面发起,以避免对主节点提供的服务带来冲击。
恢复服务:恢复服务又名回档恢复,由恢复模块负责将 HDFS 上面的备份文件恢复到临时实例上,以便用户检查或调整而不影响主实例的运行。
备份下载:您可以将备份文件转储和下载到指定位置,如价格更低的腾讯云 COS。 -
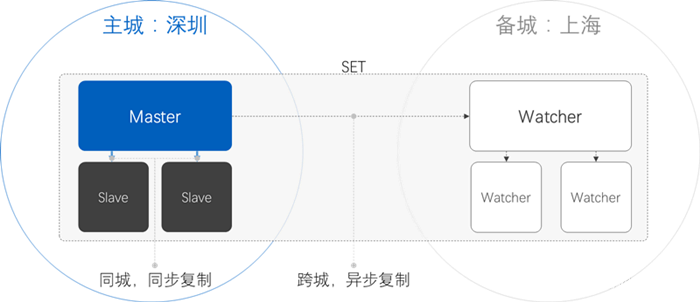
两地三中心
MariaDB 两地三中心部署架构:同城节点直线距离大于10KM,异地节点直线距离大于100km,使用腾讯自主研发的高可用调度方案(High Availability,HA)实现。示意图如下:
高性能
基于 PCI-E SSD,强大 IO 性能保障数据库的访问能力,存储固件采用 NVMe 协议,专门针对 PCI-E SSD 设计,更能发挥出性能优势,高 IO 型单实例最大可支持6TB容量、480GB内存和22万以上 QPS (每秒访问次数),性能优势让您以较少的数据库实例支撑更高的业务并发。
所有 MariaDB 实例内核都非原版 MariaDB 内核,而是经过腾讯数据库研发基于实际需求修改。而且默认参数都是经过多年的生产实践优化而得,并由专业 DBA 持续对其进行优化,确保 MariaDB 一直基于最佳实践在运行。
功能强大
- 支持多源复制(Multi-source Replication):为复杂的企业级业务(例如保险的前台、中台、后台、数据仓库)提供有力支持。
- 支持 XtraDB、TokuDB 等更高级的存储引擎,引入 group commit for the binary log 等技术,有效提高业务性能并减少存储量。
- 支持线程池(Thread pool)、审计日志等功能。
时钟精确到微秒级别,可用于对时间要求精确度较高的金融交易类业务。 - 提供虚拟列(函数索引),可有效提供数据库分析统计运算性能。
兼容 MySQL
MariaDB 使用 InnoDB 存储引擎,并与 MySQL 5.5、5.6 兼容。意味着:已用于 MySQL 数据库的代码、应用程序、驱动程序和工具,您只需对其进行少量更改甚至无需更改,即可与 MariaDB 配合使用。
便宜易用
- 支持即开即用:您可以通过腾讯云官网 MariaDB 规格定制,下发订单后自动生成 MariaDB 实例。将 MariaDB 配合云服务器 CVM 一起使用,在降低应用响应时间的同时还可以节省公网流量费用。
- 按需升级:在业务初期,您可以购买小规格的 MariaDB 实例来应对业务压力。随着数据库压力和数据存储量的变化,您可以灵活调整实例规格。
- 管理便捷:腾讯云负责 MariaDB 的日常维护和管理,包括但不限于软硬件故障处理、数据库补丁更新等工作,保障 MariaDB 运转正常。您也可自行通过腾讯云控制台完成数据库的增加、删除、重启、备份、恢复等管理操作。
应用场景
数据云灾备(异地灾备)
数据是企业运营的重要组成,信息化带来便利的同时,电子数据、存储信息极易毁损、丢失的特点也暴露了出来。而在自然灾害、系统故障、员工误操作和病毒感染面前,任意一次事故就有可能导致企业的运营完全中断,甚至灾难性损失。因此,确保数据的安全完整性,特别是核心数据库的安全和完整性是每个企业必须考虑的。
而企业自建异地数据灾备中心通常耗资巨大,通常包括一笔开支巨大的机房硬件,软件成本,还包括每年运营费用的持续维护投入。而为了小概率事件买单,往往与企业的财务需求不符。
因此,利用云数据库和云接入产品,可以直接建立云上的一套数据灾备中心,将主数据中心的数据,通过安全专网,实时同步到云上的异地备份中心。不仅解决海量数据的运营管理的问题,而且性价比高。
业务系统上云
如果您的业务系统还未上云,可能会遇到如下情况:
- 业务发展非常快,每年若按峰值准备服务器,其增长规模都是非常大的一笔开销。
- 新业务部门为了时效性,经常需要快速上线新业务,如果每次都要做准备和采购势必影响效率。
- 几乎每个业务系统都遭遇过访问量激增,再创历史新高,后端资源无法支撑的情况。
- 不少企业领导认为 IT 部门就是成本中心,每天关心的核心问题不是推进业务,而是一直在解决问题,例如,系统不稳定或性能不足。
面对如上一系列挑战,腾讯云云数据库通过多年的积累,能够为用户提供:
- 安全、开放的数据库解决方案。
- 高可用的方案,采用强同步复制技术和高可用(HA)架构实现高容灾。
- 支持弹性伸缩。
混合云
云数据库 MariaDB 支持专有云部署方案,可以部署在用户自建机房。业务系统和数据通过专线(或 VPN)进行安全同步,构建易扩展的混合云架构。
读写分离
云数据库所有实例的备机均默认支持读写分离策略,即支持备机开放只读:
- 支持通过 SQL 语法或只读账号实现只读。
- 如果您选择的配置有多个备机,将自动负载只读策略。
- 可通过升级配置,增加更多备机。
开发测试
您可能需要维护多个软件版本环境进行测试,甚至需要大量资源进行压力测试。
传统方案是自建服务器和数据库来支撑该需求,然而这样就会浪费大量的硬件资源,因为开发人员不会时刻的使用测试资源,因此测试资源往往是闲置的,而利用云服务器、云数据库的弹性伸缩,可以有效的解决基于测试资源不足或测试资源浪费的问题。
系统架构
高可用架构
在生产系统中,通常都需要用高可用方案来保证系统不间断运行,数据库作为系统数据存储和服务的核心能力,其可用要求高于计算服务资源。目前,数据库的高可用方案通常是让多个数据库服务协同工作,当一台数据库故障,余下的立即顶替上去工作,这样就可做到不中断服务或只中断很短时间;或者是让多台数据库同时提供服务,用户可以访问任意一台数据库,当其中一台数据库故障,立即更换访问另外数据库即可。
由于数据库中记录了数据,想要在多台数据库中切换,数据必须是同步的,所以数据同步技术是数据库高可用方案的基础。当前,数据复制有以下三种方式:
- 异步复制:应用发起更新(含增加、删除、修改操作)请求,Master 完成相应操作后立即响应应用,Master 向 Slave 异步复制数据。因此异步复制方式下,Slave 不可用不影响主库上的操作,而 Master 不可用有概率会引起数据不一致。
- 强同步复制:应用发起更新请求,Master 完成操作后向 Slave 复制数据,Slave 接收到数据后向 Master 返回成功信息,Master 接到 Slave 的反馈后再应答给应用。Master 向 Slave 复制数据是同步进行的,因此 Slave 不可用会影响 Master 上的操作,而 Master 不可用不会引起数据不一致。
注意
使用“强同步”复制时,如果主库与备库之间网络中断或备库出现问题,主库也会被锁住(hang),而此时如果只有一个主库或一个备库,那么是无法做高可用方案的。因为单一服务器服务,如果故障会直接导致部分数据完全丢失,不符合金融级数据安全要求。
- 半同步复制:半同步复制是 google 提出的一种同步方案,其原理是正常情况下数据复制方式采用强同步复制方式,当 Master 向 Slave 复制数据出现异常的时候(Slave 不可用或者双节点间的网络异常)退化成异步复制。当异常恢复后,异步复制会恢复成强同步复制。半同步复制意味着 Master 不可用会有较小概率引起数据不一致。
常见高可用架构
- 共享存储方案:使用共享存储,如 SAN 存储。SAN 的原理是多台数据库服务器共享同一个存储区域,这样多台数据库都可以“读写”同一份数据。当主库发生故障时,第三方高可用软件把文件系统在备库上挂起,然后在备库上启动数据库即完成切换。
- 日志同步或流复制同步:数据库最常见复制模式,如 MySQL 数据库。每当写入数据,MySQL Master Server 将自己的 Binary Log 通过复制线程传输给 Slave,Slave 接收到 Binary Log 以后,依照 Binary Log 内容,写入相同数据到文件系统。目前 MySQL 已经提供:
- 异步复制:异步复制可以确保得到快速的响应结构,但是不能确保二进制日志确实到达了 Slave 上,即无法保障数据一致性。
- 半同步复制:(由 google 提供的同步插件)半同步复制对于客户的请求响应稍微慢点,在超时等情况下,会退化为异步,即基本保障数据一致性,但无法保证数据完全一致性。
- 基于触发器的同步:使用触发器记录数据变化,然后同步到另一台数据库上。
- 基于中间件的同步:系统不直接连接到底层数据库,而是连接到一个中间件,中间件把数据库变更发送到底层多台数据库上,从而完成数据同步。早几年,由于业务需求,数据库性能、同步机制等问题,某些软件开发商通常采用类似架构。
MariaDB 架构简介
异步多线程强同步复制技术
同步技术发展过程中,提供了异步复制、半同步等同步技术,这两种技术面向普通用户群体,在用户要求不高、网络条件较好、性能压力不大的情况下,能够基本保障数据同步;但通常情况下,采用异步复制、半同步机制容易经常出现数据不一致问题,直接影响系统可靠性,甚至出现丢失交易数据,带来直接或间接经济损失。
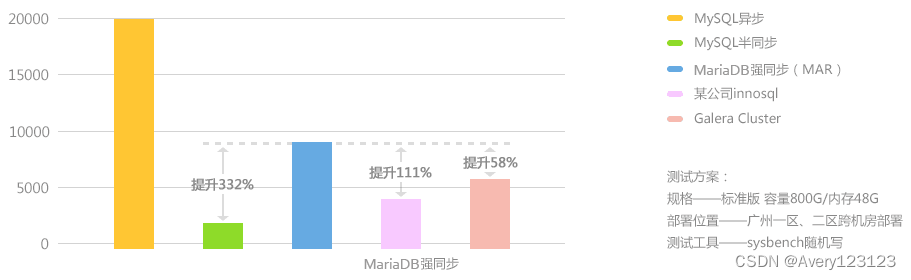
腾讯云业务经过多年积累,自主研发出数据库异步多线程强同步复制方案(Multi-thread Asynchronous Replication,MAR),相比于 Oracle 的 NDB 引擎、Percona XtraDB Cluster 和 MariaDB Galera Cluster,其性能、效率和适用性更具优势。MAR 强同步方案特点如下:
- 一致性的同步复制,保证节点间数据强一致性。
- 对业务层面完全透明,业务层面无需做读写分离或同步强化工作。
- 将串行同步线程异步化,引入线程池能力,大幅度提高性能。
- 支持集群架构。
- 支持自动成员控制,故障节点自动从集群中移除。
- 支持自动节点加入,无需人工干预。
- 每个节点都包含完整的数据副本,可以随时切换。
- 无需共享存储设备。
腾讯 MAR 方案强同步技术,只有当备机数据同步后,才由主机向应用返回事务应答,示意图如下:
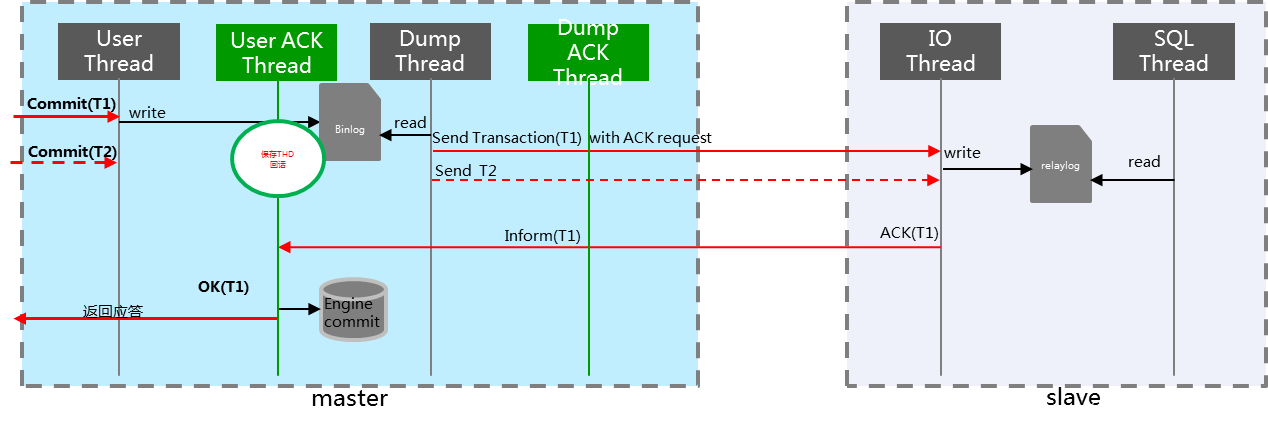
集群架构
MariaDB 采用集群架构,一套独立 MariaDB 系统至少需要十余个系统或组件组成,架构简图如下:
其中,MariaDB 最核心的三个主要模块是:决策调度集群(Tschedule)、数据库节点组(SET)和接入网关集群(TProxy),三个模块的交互都是通过配置集群(TzooKeeper)完成。
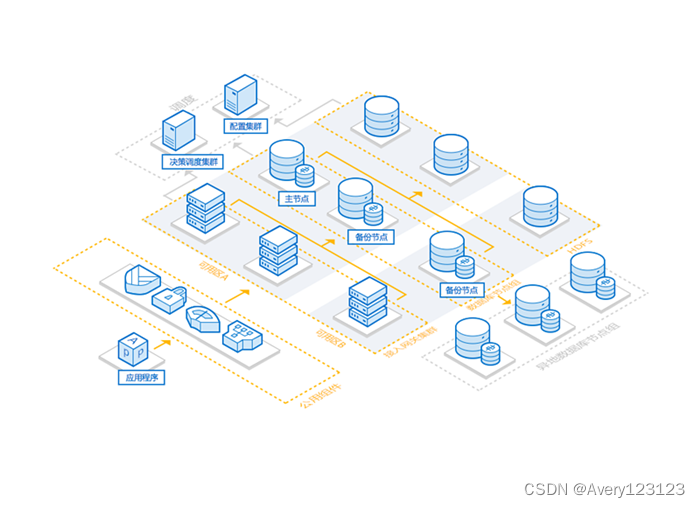
- 数据库节点组(SET):由兼容 MySQL 数据库的引擎、监控和信息采集(Tagent)组成, 其架构有“一个主节点(Master)、若干备节点(Slave_n)、若干异地备份节点(Watcher_m)”,通常情况下:
部署在跨机架、跨机房的服务器中。
通过心跳监控和信息采集模块(Tagent)监控,确保集群的健壮性。
分布式架构下,基于水平拆分,若干个分片(数据库节点组)提供一个“逻辑统一,物理分散”分布式的数据库实例。 - 决策调度集群(Tschedule):作为集群的管理调度中心,主要管理 SET 的正常运行,记录并分发数据库全局配置,其包括:
- 调度作业集群(MariaDB Scheduler):帮助数据库管理员或者数据库用户自动调度和运行各种类型的作业,例如数据库备份、收集监控、生成各种报表或者执行业务流程等,MariaDB 把 Schedule、zookeeper、OSS(运营支撑系统)结合起来通过时间窗口激活指定的资源计划,完成数据库在资源管理和作业调度上的各种复杂需求,Oracle 也用 DBMS_SCHEDULER 支持类似的能力。
- 程序协调与配置集群(TzooKeeper):它为 MariaDB 提供配置维护、选举决策、路由同步等,并能支撑数据库节点组(分片)的创建、删除、替换等工作,并统一下发和调度所有 DDL(数据库模式定义语言)操作,TzooKeeper 部署数量需大于等于三台。
- 运维支撑系统(OSS):基于 MariaDB 定制开发的一套综合的业务运营和管理平台,同时也是真正融合了数据库管理特点,将网络管理、系统管理、监控服务有机整合在一起。
决策调度集群独立部署在腾讯云全国三大机房中(跨机房部署,异地容灾)。 - 接入网关集群(TProxy):在网络层连接管理 SQL 解析、分配路由(TProxy 非腾讯云网关 TGW)。
与数据库引擎部署数量相同,分担负载并实现容灾。
从配置集群(TzooKeeper)拉取数据库节点(分片)状态,提供分片路由,实现透明读写。
记录并监控 SQL 执行信息,分析 SQL 执行效率,记录并监控用户接入信息,进行安全性鉴权,阻断风险操作。
TProxy 前端部署为腾讯网关系统 TGW,对用户提供唯一一个虚拟 IP 服务。
这种集群架构极大简化了各个节点之间的通信机制,也简化了对于硬件的需求,这就意味着即使是简单的 x86 服务器,也可以搭建出类似于小型机、共享存储等一样稳定可靠的数据库。
云数据库 SQL Server
产品概述
云数据库 SQL Server(TencentDB for SQL Server)具有微软正版授权,可持续为用户提供最新的功能,避免未授权使用软件的风险。具有即开即用、稳定可靠、安全运行、弹性扩缩容等特点,同时也具备高可用架构、数据安全保障和故障秒级恢复功能,让您能专注于应用程序的开发。
部署架构
云数据库 SQL Server 支持2种部署架构:
- 单节点(原基础版)
计算和存储分离,基于高性能云盘,采用单个节点部署。 - 双节点(原高可用版/集群版)
SQL Server 2008 R2,2012、2014、2016 Enterprise/Standard 版主备双节点架构由一主一镜像(Mirror)的 SQL Server 数据库组成,跨机架/跨可用区部署。
SQLServer 2017、2019、Enterprise/Standard,2022 Enterprise 版主备双节点架构采用 always on 架构,默认跨机架/跨可用区进行一主一备的集群架构部署。
隔离策略
- 云数据库 SQL Server 单节点(云盘版)及云数据库 SQL Server 双节点(云盘版)基于云服务器 CVM 部署,每个实例独占一台 CVM,独享 CPU、内存、磁盘,不同实例之间完全隔离。
- 云数据库 SQL Server 双节点(本地盘版)基于本地物理机部署,每台物理机上部署了多个实例,通过隔离策略,保证了不同实例间完全隔离,独享 CPU、内存、磁盘。
此外云数据库 SQL Server 也在账号、地域、可用区、网络等多维度,均作了相应的数据隔
云数据库 PostgreSQL
PostgreSQL 简介
PostgreSQL 是全球强大的开源数据库,支持主流开发语言,包括 C,C++,Perl,Python,Java,Tcl 以及 PHP 等,能够对 SQL 规范的完整实现,以及丰富多样的数据类型支持,包括 JSON 数据、IP 数据和几何数据等,而这些能力大部分商业数据库都无法全面支持。在过去的若干年间,PostgreSQL 正在以飞快的速度发展,目前已经广泛用在包括地球空间、移动应用、数据分析等各个行业,已成为众多企业开发人员和创新公司的首选。
腾讯云云数据库 PostgreSQL 简介
云数据库 PostgreSQL 能够让您在云端轻松设置、操作和扩展目前功能最强大的开源数据库 PostgreSQL,腾讯云将负责绝大部分处理复杂而耗时的管理工作,如 PostgreSQL 软件安装、存储管理、高可用复制、以及为灾难恢复而进行的数据备份,让您更专注于业务程序开发。
目前,腾讯云已经提供 PostgreSQL 10、11、12、13、14 、15版本。
企业级分布式数据库
TDSQL MySQL版
产品概述
TDSQL MySQL版(TDSQL for MySQL)是部署在腾讯云上的一种支持自动水平拆分、Shared Nothing 架构的分布式数据库。TDSQL MySQL版 即业务获取的是完整的逻辑库表,而后端会将库表均匀的拆分到多个物理分片节点。
TDSQL MySQL版 默认部署主备架构,提供容灾、备份、恢复、监控、迁移等全套解决方案,适用于 TB 或 PB 级的海量数据库场景。
TDSQL MySQL版 提供不同的引擎供用户选择,两者均兼容 MySQL 标准协议:
- InnoDB 版采用 InnoDB 作为数据存储引擎,是 MySQL 的默认存储引擎。
- TDStore 版采用腾讯云自研的新敏态引擎 TDstore 作为数据存储引擎,该引擎可以有效解决客户业务发展过程中业务形态、业务量的不可预知性,适配金融敏态业务。
解决问题
1、单机数据库瓶颈
面对互联网类业务百万级以上的用户量,单机数据库由于硬件和软件的限制,数据库在数据存储容量、访问容量、容灾等方面都会随着业务的增长而到达瓶颈。
TDSQL MySQL版 目前单分片最大可支持6TB存储,如果性能或容量不足以支撑业务发展时,在控制台自动升级扩容。升级过程中,您无需关心分布式系统内的数据迁移,均衡和路由切换。升级完成后访问 IP 不变,仅在自动切换时存在秒级闪断,您仅需确保有重连机制即可。
2、应用层分片开发工作量大
应用层分片将业务逻辑和数据库逻辑高度耦合,给当前业务快速迭代带来极大的开发工作量。
基于 TDSQL MySQL版 透明自动拆分的方案,开发者只需要在第一次接入时修改代码,后续迭代无需过多关注数据库逻辑,可以极大减少开发工作量。
3、开源方案或 NoSQL 难题
选择开源或 NoSQL 产品也能够解决数据库瓶颈,这些产品免费或者费用相对较低,但可能有如下问题:
- 产品 bug 修复取决于社区进度。
- 您的团队是否有能持续维护该产品的人,且不会因为人事变动而影响项目。
- 关联系统是否做好准备。
- 您的业务重心是什么,投入资源来保障开源产品的资源管控和生命周期管理、分布式逻辑、高可用部署和切换、容灾备份、自助运维、疑难排查等是否是您的业务指标。
TDSQL MySQL版 支持 Web 控制台,提供完善的数据备份、容灾、一键升级等功能,完善的监控和报警体系,大部分故障都通过自动化程序处理恢复。
产品优势
超高性能
- 单分片最大性能可达超24万 QPS,整个实例性能随着分片数量增加线性扩展。
- 计算/存储资源均可独立对业务全透明地弹性扩缩容,单实例支持 EB 级海量存储。
- 计算层每个节点均可读写,单实例轻松支撑千万级 QPS 流量。
- 支持超高压缩比存储,最高可达20倍压缩率,尤其适合大批量写入、写多读少的业务场景。
专业可靠
- 经过腾讯各类核心业务10余年大规模产品的验证,包括社交、电商、支付、音视频等。
- 提供完善的数据备份、容灾、一键升级等功能。
- 完善的监控和报警体系,大部分故障都通过自动化程序处理恢复。
- 提供数据加密能力,支持 AES 算法和国密 SM4 算法,可满足静态- - 数据加密的合规性要求。
- 支持分布式数据库领域领先功能,如分布式多表 JOIN、小表广播、分布式事务、SQL 透传等。
- 数据库实例可用性可达到99.95%;数据的可靠性可达到99.99999%。
简单易用
- 除少量语法与原生 MySQL、MariaDB 不同外,使用起来如使用单机数据库,分片过程对业务透明且无需干预。
- 兼容 MySQL 协议(支持 MySQL、MariaDB 等内核)。
- 支持 Web 控制台,读写分离能力、专有运维管理指令等。
应用场景
大型应用(超高并发实时交易场景)
电商、金融、O2O、社交应用、零售、SaaS 服务提供商,普遍存在用户基数大(百万级或以上)、营销活动频繁、核心交易系统数据库响应日益变慢的问题,制约业务发展。
TDSQL MySQL版 提供线性水平扩展能力,能够实时提升数据库处理能力,提高访问效率,峰值 QPS 达1500万+,轻松应对高并发的实时交易场景。微信支付、财付通、腾讯充值等都是使用的 TDSQL MySQL版 架构的数据库。
物联网数据(PB 级数据存储访问场景)
在工业监控和远程控制、智慧城市的延展、智能家居、车联网等物联网场景下,传感监控设备多、采样率高、数据规模大。通常存储一年的数据就可以达到 PB 级甚至 EB,而传统基于 x86 服务器架构和开源数据库的方案根本无法存储和使用如此大的数据量。
TDSQL MySQL版 提供的容量水平扩展能力,可以有效的帮助用户以低成本(相对于共享存储方案)存储海量数据。
文件索引(万亿行数据毫秒级存取)
一般来说,作为云服务平台,存在大量的图片、文档、视频数据,数据量都在亿级 - 万亿级,服务平台通常需要将这些文件的索引存入数据库,并在索引层面提供实时的新增、修改、读取、删除操作。
由于服务平台承载着其他客户的访问,服务质量和性能要求极高。传统数据库无法支撑如此规模的访问和使用,TDSQL MySQL版 超高性能和扩展能力并配合强同步能力,有效的保证平台服务质量和数据一致性。
高性价比商业数据库解决方案
大型企业、银行等行业为了支持大规模数据存储和高并发数据库访问,对小型机和高端存储依赖极强。而互联网企业通过低成本 x86 服务器和开源软件即可达到与商业数据库相同甚至更高的能力。
TDSQL MySQL版 适用于诸如国家级或省级业务系统汇聚、大型企业电商和渠道平台、银行的互联网业务和交易系统等场景。
基本原理
水平分表
水平拆分方案是 TDSQL MySQL版 的基础原理,它的每个节点都参与计算和数据存储,且每个节点都仅计算和存储一部分数据。因此,无论业务的规模如何增长,我们仅需要在分布式集群中不断的添加设备,用新设备去应对增长的计算和存储需要即可。
水平切分
-水平切分(分表):是按照某种规则,将一个表的数据分散到多个物理独立的数据库服务器中,形成“独立”的数据库“分片”。多个分片共同组成一个逻辑完整的数据库实例。
-
常规的单机数据库中,一张完整的表仅在一个物理存储设备上读写。
-
-
分布式数据库中,根据在建表时设定的分表键,系统将根据不同分表键自动分布数据到不同的物理分片中,但逻辑上仍然是一张完整的表。
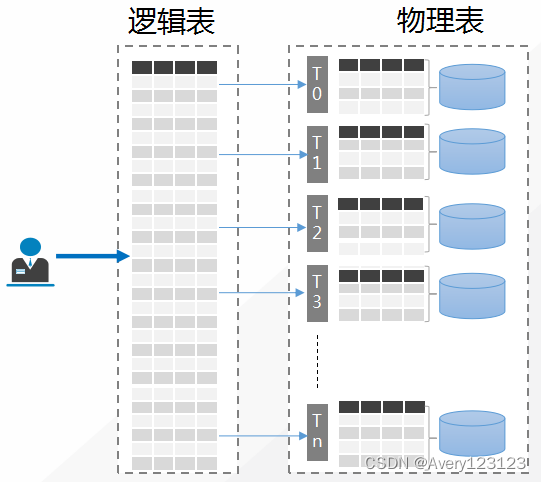
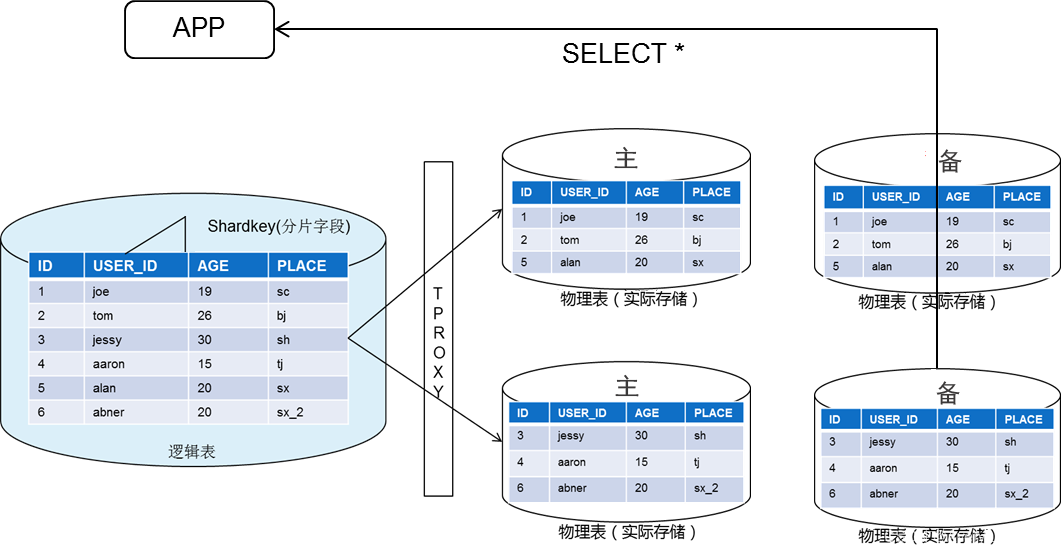
-
在 TDSQL MySQL版 中,数据的切分通常就需要找到一个分表键(shardkey)以确定拆分维度,再采用某个字段求模(HASH)的方案进行分表,而计算 HASH 的某个字段就是 shardkey。 HASH 算法能够基本保证数据相对均匀地分散在不同的物理设备中。
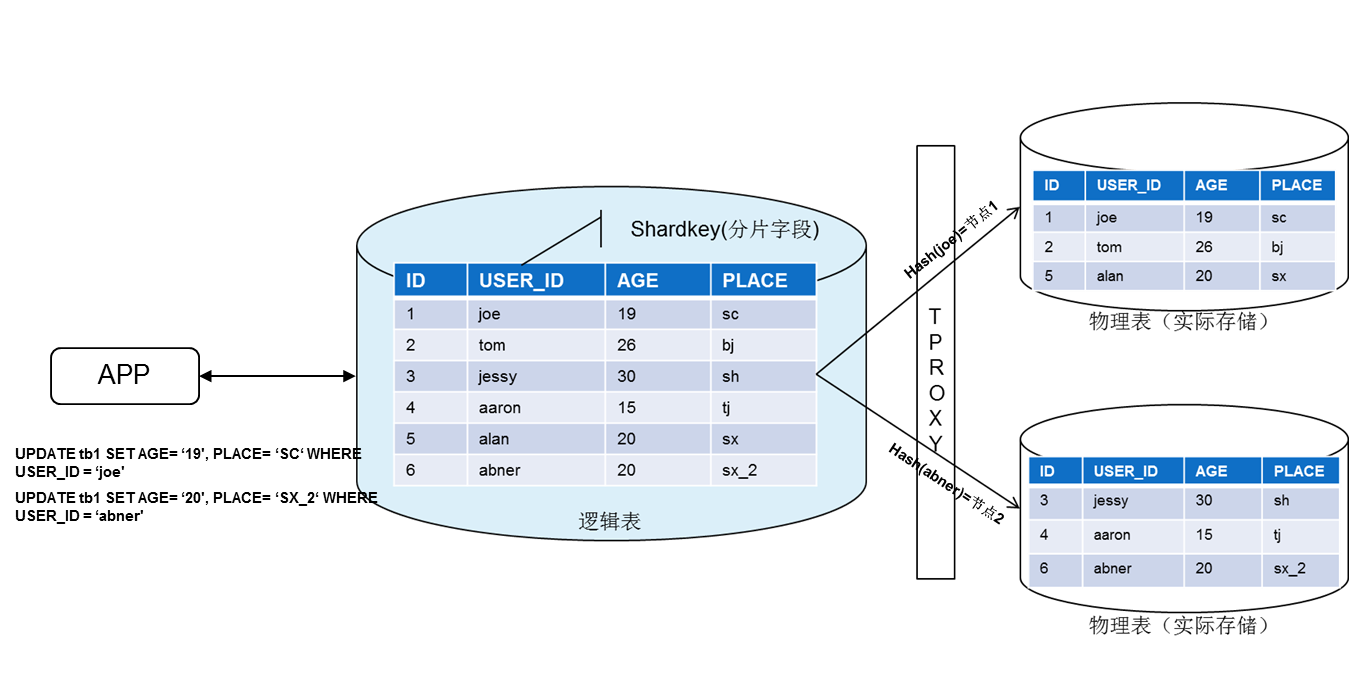
写入数据( SQL 语句含有 shardkey )
- 业务写入一行数据。
- 网关对 shardkey 进行 hash,得出 shardkey 的 hash 值。
- 不同的 hash 值范围对应不同的分片(调度系统预先分片的算法决定)。
- 数据根据分片算法,将数据存入实际对应的分片中
数据聚合
数据聚合:如果一个查询 SQL 语句的数据涉及到多个分表,此时 SQL 会被路由到多个分表执行,TDSQL MySQL版 会将各个分表返回的数据按照原始 SQL 语义进行合并,并将最终结果返回给用户。
注意
执行 SELECT 语句时,建议您在 where 条件带上 shardKey 字段,否则会导致数据需要全表扫描然后网关才对执行结果进行聚合。全表扫描响应较慢,对性能影响很大。
读取数据(有明确 shardkey 值)
- 业务发送 select 请求中含有 shardkey 时,网关通过对 shardkey 进行 hash。
- 不同的 hash 值范围对应不同的分片。
- 数据根据分片算法,将数据从对应的分片中取出。
读取数据(无明确 shardkey 值)
- 业务发送 select 请求没有 shardkey 时,将请求发往所有分片。
- 各个分片查询自身内容,发回 Proxy 。
- Proxy 根据 SQL 规则,对数据进行聚合,再答复给网关。
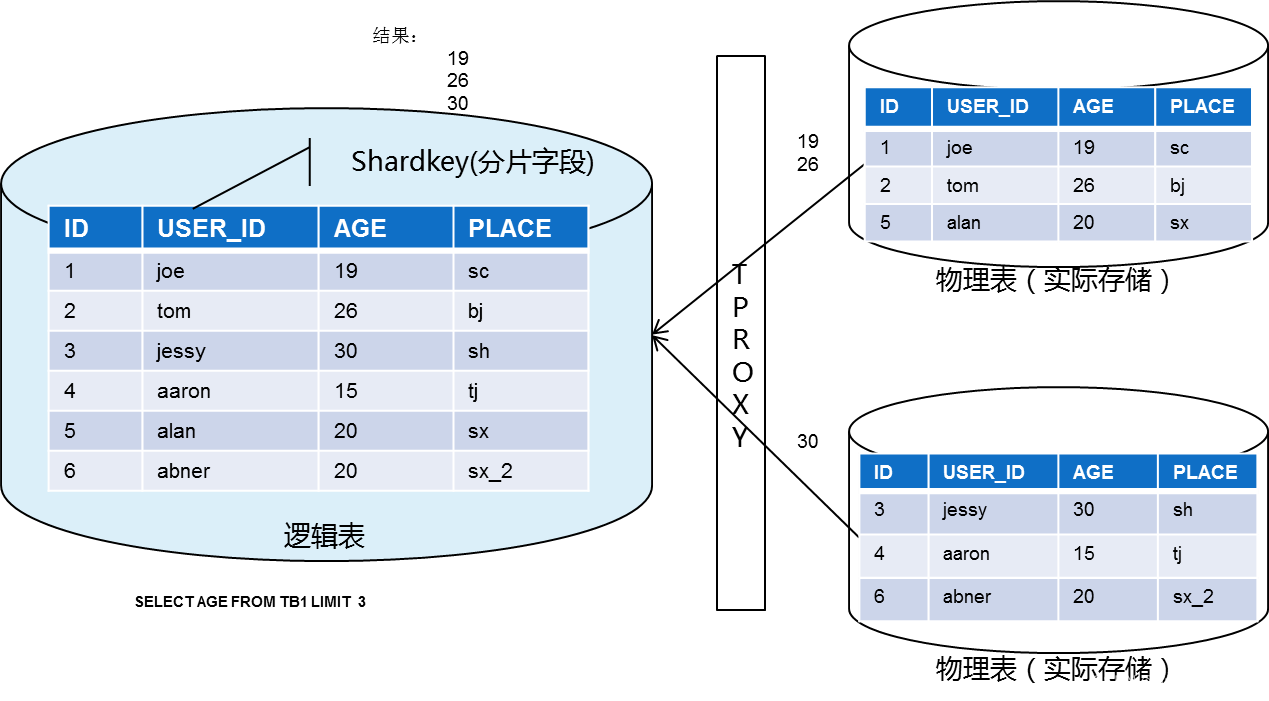
读写分离
功能简介
当处理大数据量读请求的压力大、要求高时,可以通过读写分离功能将读的压力分布到各个从节点上。
TDSQL MySQL版 默认支持读写分离功能,架构中的每个从机都能支持只读能力,如果配置有多个从机,将由网关集群(TProxy)自动分配到低负载从机上,以支撑大型应用程序的读取流量。
基本原理
读写分离基本的原理是让主节点(Master)处理事务性增、改、删操作(INSERT、UPDATE、DELETE),让从节点(Slave)处理查询操作(SELECT)。
只读账号
说明
若您的实例架构为一主一从,只读分离功能仅可用作低负载只读任务,请避免大事务等较高负载任务,影响从机备份任务及可用性。
只读账号是一类仅有读权限的账号,默认从数据库集群中的从机(或只读实例)中读取数据。
通过只读账号,对读请求自动发送到备机,并返回结果。
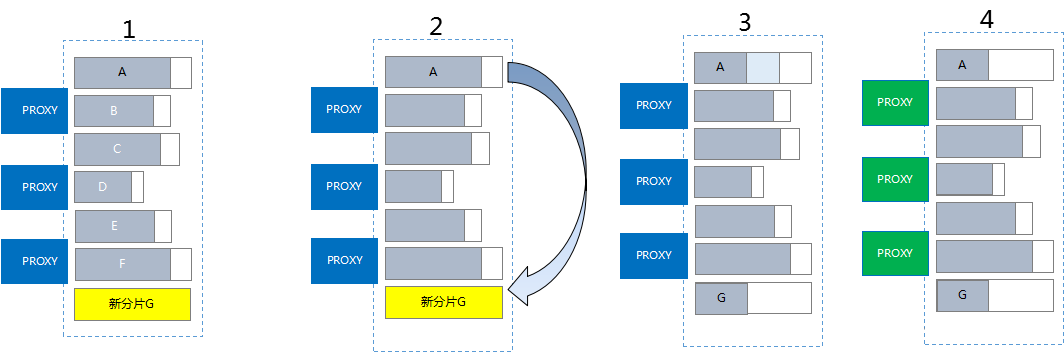
弹性扩展
概述
TDSQL MySQL版 支持在线实时扩容,扩容方式分为新增分片和现有分片扩容两种方式,整个扩容过程对业务完全透明,无需业务停机。扩容时仅部分分片存在秒级的只读或中断,整个集群不会受影响。
扩容过程
TDSQL MySQL版 主要是采用自研的自动再均衡技术保证自动化的扩容和稳定。
新增分片扩容
- 在 TDSQL MySQL版控制台 对需要扩容的 A 节点进行扩容操作。
- 根据新加 G 节点配置,将 A 节点部分数据搬迁(从备机)到 G 节点。
- 数据完全同步后,A、G 节点校验数据库,存在一至几十秒的只读,但整个服务不会停止。
- 调度通知 proxy 切换路由。
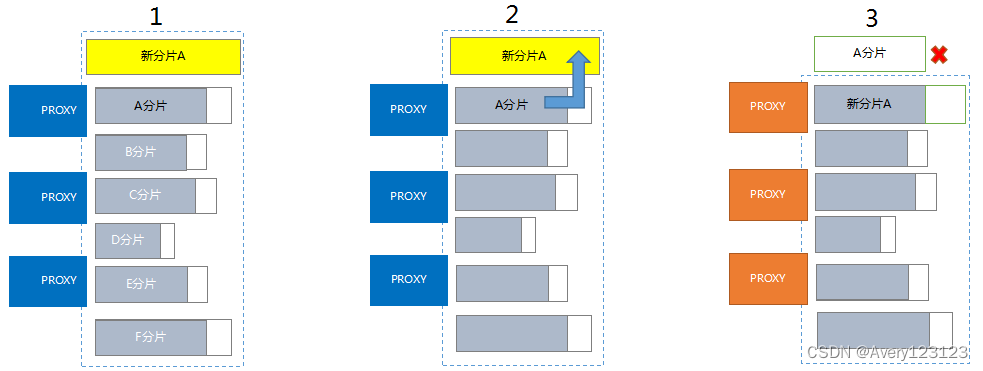
现有分片扩容
基于现有分片的扩容相当于更换了一块更大容量的物理分片。
说明
基于现有分片的扩容没有增加分片,不会改变划分分片的逻辑规则和分片数量。
- 按需要升级的配置分配一个新的物理分片(以下简称新分片)。
- 将需要升级的物理分片(以下简称老分片)的数据、配置等同步数据到新分片中。
- 同步数据完成后,在腾讯云网关做路由切换,切换到新分片继续使用。
强同步
背景
传统数据复制方式有如下三种:
- 异步复制:应用发起更新请求,主节点(Master) 完成相应操作后立即响应应用,Master 向从节点(Slave)异步复制数据。
- 强同步复制:应用发起更新请求,Master 完成操作后向 Slave 复制数据,Slave 接收到数据后向 Master 返回成功信息,Master 接到 Slave 的反馈后再应答给应用。Master 向 Slave 复制数据是同步进行的。
- 半同步复制:应用发起更新请求,Master 在执行完更新操作后立即向 Slave 复制数据,Slave 接收到数据并写到 relay log 中(无需执行) 后才向 Master 返回成功信息,Master 必须在接受到 Slave 的成功信息后再向应用程序返回响应。
存在问题
当 Master 或 Slave 不可用时,以上三种传统数据复制方式均有几率引起数据不一致。
数据库作为系统数据存储和服务的核心能力,其可用性要求非常高。在生产系统中,通常都需要用高可用方案来保证系统不间断运行,而数据同步技术是数据库高可用方案的基础。
解决方案
MAR 强同步复制方案是腾讯自主研发的基于 MySQL 协议的并行多线程强同步复制方案,只有当备机数据完全同步(日志)后,才由主机给予应用事务应答,保障数据正确安全。
原理示意图如下:
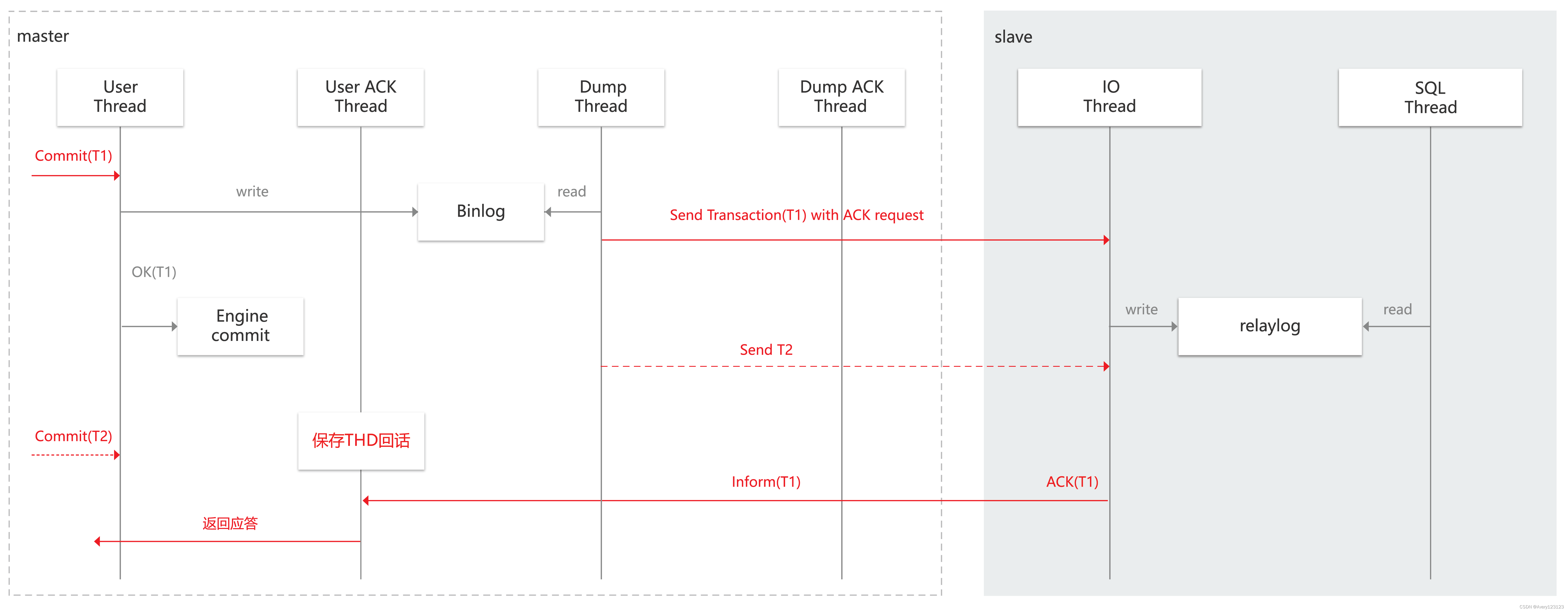
在应用层发起请求时,只有当从节点(Slave)返回信息成功后,主节点(Master)才向应用层应答请求成功,以确保主从节点数据完全一致。
MAR 强同步方案在性能上优于其他主流同步方案,具体数据详情可参见 强同步性能对比数据。主要特点如下:
- 一致性的同步复制,保证节点间数据强一致性。
- 对业务层面完全透明,业务层面无需做读写分离或同步强化工作。
- 将串行同步线程异步化,引入线程池能力,大幅度提高性能。
- 支持集群架构。
- 支持自动成员控制,故障节点自动从集群中移除。
- 支持自动节点加入,无需人工干预。
- 每个节点都包含完整的数据副本,可以随时切换。
- 无需共享存储设备。
实例架构
InnoDB引擎

TDStore 引擎
TDStore 实例分为集群版和基础版两种:
- 集群版:由多个(≥3个)节点构成,以三副本 Raft 集群的形态提供高性能可用的数据库服务,适用于企业生产环境。
- 基础版:由单个节点构成,以较低的成本提供完整的数据库功能,适用于个人用户。
说明
基础版实例创建后可以通过控制台升级为集群版实例;集群版实例创建后不可以降级为基础版实例。
TDStore 实例内的节点分为对等架构和分离架构两种:
- 对等架构:计算层 SQL Engine 与数据层 TDStore 合并在一个物理节点中,减少硬件节点数量和跨节点通信,从而降低成本并提高性能。
- 分离架构:计算层 SQL Engine 与数据层 TDStore 分别在不同的物理节点中。
TDStore 引擎介绍
TDStore 是腾讯云全自研的金融级新敏态引擎,该引擎可以有效解决对于客户业务发展过程中业务形态、业务量的不可预知性,适配金融敏态业务。
TDStore 引擎特性
高度兼容 MySQL 语法
TDSQL TDStore 引擎版计算节点基于 MySQL 8.0 实现,除个别受限的系统操作,TDStore 可以100%兼容原生 MySQL 语法。单机 MySQL 的业务可以无损迁移到 TDStore 上,真正实现对业务应用无入侵。
存储计算分离/独立弹性伸缩
TDStore 采用计算和存储分离的原生分布式的架构设计,计算层和存储层的节点均可根据业务需求独立弹性扩缩容,而且无须额外的人工运维干预,实现扩缩容过程对业务零感知。
- 计算层采用多主架构,而且每个计算节点均可读写,用户可以随着业务量的增长而弹性扩展计算节点,单实例可支撑千万级 QPS 流量,帮助用户轻松应对突如其来的业务峰值压力。
- 对于存储层资源,用户也可以随着业务数据量的增长而弹性扩展存储节点。数据在不同节点之间的迁移、均衡、路由变更等操作均由 TDStore 实例内部自洽完成。
云原生的管控系统
TDStore 的管控部分采用了云原生的方式,借助云原生的能力,能够快速且方便地管理 TDStore 实例,免除了繁琐的物理机上架,配置等资源管理运维操作,同时也无需关心资源的使用率情况,即买即用,支持高效弹性扩缩容。
原生 Online DDL 支持
TDStore 支持原生 Online DDL 操作,用户在业务运行过程中,有动态更改表结构的需求时,无须依赖如 pt 或 ghost 等外部工具组件,直接使用原生 MySQL DDL 语句便可完成。
TDStore 覆盖 MySQL 原生可支持的 instant 类型 DDL 操作,并且对于大部分类型(除涉及主键外的)DDL,均能以不阻塞业务的正常 DML 请求下完成。同时,TDStore 的 Online DDL 可以在多个计算节点之间保持一致性,不同表对象的 Online DDL 可以并行执行。
完整分布式事务支持
TDStore 以原生分布式的架构完整支持事务 ACID 特性,默认的事务隔离级别为快照隔离级别(Snapshot Isolation),支持全局一致性读特性,整体事务并发控制框架基于 MVCC + Time-Ordering 的方式实现。
分布式事务协调者由分布式存储层节点担任,而当存储节点在线扩容遇到数据分裂或切主等状态变更的场景时,TDStore 均可实现不中断事务,将底层数据状态的变更对事务请求的影响降到最低,从而做到无感知的集群扩缩容。
低成本海量存储
TDStore 存储层基于 LSM-Tree + SSTable 结构存放和管理数据,具有较高的压缩率,能有效降低海量数据规模下的存储成本。对于一些数据行重复度较大的业务场景,对比 InnoDB 存储引擎,TDStore 版最高可实现高达20倍的压缩率,单实例可支撑 EB 级别的存储量。
TDStore 引擎架构
计算节点 SQLEngine
SQLEngine 是计算节点,负责接收和响应客户端的 SQL 请求。SQLEngine 基于 MySQL 8.0 实现,完全兼容原生 MySQL 语法,从原生 MySQL 迁移过来的业务在使用时无须对业务语句进行任何改造。
SQLEngine 采用无状态化的设计方式,节点本身不保存任何用户数据,并将多线程框架替换为协程框架,与集群内的 TDStore 节点进行交互。
一个实例内可以包含多个 SQLEngine 节点,节点之间彼此独立,均可读写。
存储节点 TDStore
TDStore 是存储节点,负责用户数据的存储。它是一个基于 Multi-Raft 协议实现的分布式存储集群。
Region 是 TDStore 存储和管理数据的最小单位,以及 TDStore 节点之间进行数据复制同步的单位,一个 Region 代表一段左闭右开的数据区间,每个 Region 包含一主 N 备的多个副本,不同副本分散在不同的 TDStore 节点上。客户端对某一行数据的访问,在经过 SQLEngine 编码后,会将请求发送到对应的 TDStore 上对应的 Region 上。
在分布式事务中,TDStore 承担协调者的角色,由 Region 的 Leader 副本进行响应。
管控节点 TDMC
TDMC 为管控节点集群,负责实例内部的资源管控调度,以及全局唯一性的数据资源的管理。
在资源调度方面,TDMC 主要负责根据 TDStore 心跳上报的信息,对 Region 下发进行分裂、切主、合并、迁移等任务,同时向 SQLEngine 提供最新的全局的 Region 路由信息。
在数据管理方面,TDMC 主要负责向计算和存储节点提供全局唯一且严格递增的事务时间戳,用以实现数据多版本管理以及可见性的判断。另外,MC 还负责管理 MDL 锁、系统变量参数等等。
TDSQL PostgreSQL版
TDSQL PostgreSQL版(TDSQL for PostgreSQL)是腾讯自主研发的分布式数据库系统。TDSQL PostgreSQL版 集高扩展性、SQL 高兼容度、完整的分布式事务支持、多级容灾及多维度资源隔离等功能于一身,采用无共享的集群架构,提供容灾、备份、恢复、监控、安全、审计等全套解决方案,适用于GB级 - PB级的海量 HTAP 场景。
产品概述
高度兼容 PostgreSQL 和 Oracle
TDSQL PostgreSQL版 完全兼容 PostgreSQL。同时,TDSQL PostgreSQL版 正式孵化出 Oracle 兼容版,即 TDSQL PostgreSQL版(Oracle 兼容版),该版本高度兼容 Oracle 语法,包含数据类型与运算符、分区表、系统内置包、系统视图、函数、存储过程、PL/SQL 等语法的兼容。
具体的 Oracle 兼容性说明请参见 Oracle 兼容语法。
原生分布式架构
TDSQL PostgreSQL版 以及 TDSQL PostgreSQL版(Oracle 兼容版)都采用原生分布式架构,应用可以像使用集中式数据库一样使用本数据库产品。本数据库产品引入全局事务管理节点(Global Transaction Manager,GTM)来专门处理分布式事务一致性,同时提供了分布式事务可靠性保证机制来避免资源阻塞、数据不一致和协调节点宕机等问题。
HTAP 事务和分析双引擎
事务和分析混合处理技术(Hybrid Transactional/Analytical Processing,HTAP)要求事务型和分析型业务处理在同一个数据库实例中完成处理。传统的数据库因各方面的限制,偏向于 OLTP 或 OLAP 的场景,两者很难兼得。TDSQL PostgreSQL版 及 TDSQL PostgreSQL版(Oracle 兼容版)经过专门的设计能很好的支持 HTAP,同时具备高效的 OLTP 处理能力和专业的 OLAP 能力,降低业务复杂度和成本。
多周边生态支持
TDSQL PostgreSQL版 及 TDSQL PostgreSQL版(Oracle 兼容版)具有丰富的周边生态:
- 支持强大的地理信息系统(GIS)。通过集群化的 PostGis 插件,支持存储空间地理数据,使 TDSQL PostgreSQL版 及 TDSQL PostgreSQL版(Oracle 兼容版)成为一个空间数据库,能够通过 SQL 语言高效的进行空间数据管理、数量测量和几何拓扑分析。
- TDSQL PostgreSQL版 及 TDSQL PostgreSQL版(Oracle 兼容版)不仅是一个分布式关系型数据库系统,同时还支持非关系数据类型 JSON。
TDSQL PostgreSQL版(Oracle 兼容版)支持集中式版本,该版本只包含数据节点 DN,高度兼容 Oracle 语法,包含数据类型与运算符、分区表、系统内置包、系统视图、函数、存储过程、PL/SQL 等多个模块。
产品功能
高效分布式 JOIN 计算
业务分析场景,通常会有2个或多个表关联(JOIN)的逻辑,此逻辑在单机模式中是一个简单的操作,但在集群模式下,由于数据分布在1个或多个物理节点中,处理会相对复杂。在很多分布式解决方案中,JOIN 会把数据拉取到一个节点,进行关联计算,不仅耗费了大量网络资源,且语句的执行耗时会很高。
TDSQL PostgreSQL版 通过如下方式对分布式 JOIN 进行高效计算,基于高效的全局查询计划和数据重分布的技术支撑,TDSQL PostgreSQL版 能轻易发挥并行计算的优势,高效完成 JOIN 过程。
- 在执行方式上,协调节点接收到用户的 SQL 请求,根据收集的集群统计信息,生成最优的集群级分布式查询计划,并下发到参与计算的数据节点上进行执行,即协调节点下发的是执行计划,数据节点负责执行该计划。
- 在数据交互上,数据节点之间建立了高效数据交换通道,可以高效的交换数据,数据交换的过程在 TDSQL PostgreSQL版 里称之数据重分布(Data Redistribution)。
多核并行计算
TDSQL PostgreSQL版 在节点内部采用了并行计算,同时启动多个进程来协同完成一个查询,可充分利用服务器的多核处理能力来快速、高效地完成查询。通常情况下,TDSQL PostgreSQL版 会启动多个进程来完成查询,查询时间会大大缩短,如果有更多的资源可供使用,查询时间则会呈线性优化。
TDSQL PostgreSQL版 会根据查询表大小来决定是否进行并行查询,表的数据量超过阈值后,才会采用并行计算,当需要并行计算时,会根据表大小得出并行度,即需要的进程个数。
分布式数据库故障定位工具
为增加分布式数据库系统的易用性,TDSQL PostgreSQL版 提供分布式的全局实时会话分析和锁分析功能,该功能展示当前分布式数据库系统中实时会话详情,包含后端 PID、SQL 文本、客户端 IP、状态、运行时长等关键字段,帮助用户准确判断系统当前的运行状态。同时,提供 kill 会话的功能,用户能基于业务运行状态分析并自助完成 kill。
TDSQL PostgreSQL版 同时支持锁分析功能,展示当前数据库系统中被阻塞的会话的详情,用户可以基于系统运行情况完成自助终止操作。
另外,TDSQL PostgreSQL版 支持数据库系统慢日志的查询和下载,以便用户能定位出当前数据库的性能阻塞点。
多级容灾功能
TDSQL PostgreSQL版 在多个维度保证集群的容灾能力:
强同步复制
TDSQL PostgreSQL版 支持强同步复制,在节点级保证每个节点的主从数据完全一致,是整个容灾体系的基础,当主节点(Master)发生故障时,数据库可切换到从节点(Slave)提供服务且无任何数据丢失。强同步机制要求用户请求发生并且从节点写入日志成功后,才给用户返回成功信息,保证主从节点的数据时刻一致。
主从高可用
TDSQL PostgreSQL版 主从高可用方案主要通过每组节点的多副本冗余,来实现服务不中断或很短时间的中断,当一组节点的主节点出现故障不可恢复,将自动从对应的备节点中选出新的主节点工作。在主从高可用基础上 TDSQL PostgreSQL版 支持:
- 故障自动转移:集群中主节点故障时,系统自动从对应的从节点中选出新的主节点,故障节点自动被集群隔离,基于强同步复制策略,主从切换保证主从数据完全一致,可满足金融级数据一致性要求。
- 故障恢复:备节点因磁盘故障导致数据丢失时,数据库管理员(DBA)可以通过重做备机来恢复备机,可选择在新的物理节点上添加备机来恢复主从备份关系,保证系统可靠性。
- 副本切换:每组主从节点(可以是1主 N 从)的每个节点都包含完整的数据副本,DBA 可根据需求进行切换。
- 设置禁止切换:即可设置在某一特殊时期,不处理故障转移。
- 跨可用区部署:主节点和从节点分处于不同机房,通过专线网络进行实时的数据复制。本地为主节点,远程为从节点,首先访问本地节点,若本地主节点发生故障或访问不可达,则远程的从节点升为主节点提供服务。
TDSQL PostgreSQL版 支持基于强同步的高可用方案,主节点故障时将自动选出最优从节点立即顶替工作,切换过程对用户透明,且不改变访问 IP。TDSQL PostgreSQL版 对系统组件支持7 * 24小时持续监控,发生故障时,TDSQL PostgreSQL版 将自动重启节点或者隔离节点,从节点选出新主节点提供服务。
基于时间点的恢复功能
TDSQL PostgreSQL版 支持基于备份在事务一致性的时间点恢复数据,防止误操作带来的数据丢失。备份分为全量备份(冷备)和增量备份(xlog 备份):
- 全量备份:指备份数据库的全部数据(除了运行日志和 xlog 之外),全量备份通常是周期性,如一天、一周或 N 天。
- 增量备份:指增量数据的备份,一般通过 xlog 文件实现,当数据库系统产生新的 xlog 文件后,系统将 xlog 文件备份到备份服务器上,增量备份通常是实时行为。
当发生事故或灾难后,用户可以利用备份数据来恢复系统。TDSQL PostgreSQL版 是一个全局分布式事务的数据库系统,各节点之间数据是关联的,因此恢复系统需要通过一个全局时间点来恢复。
产品优势
分布式事务全局一致性
TDSQL PostgreSQL版 引入全局事务管理节点(Global Transaction Manager,GTM)来专门处理分布式事务一致性,通过拥有自主专利的分布式事务一致性技术,即两阶段提交(Two Phase Commit)和全局时钟(Global Timestamp)策略来保证在全分布式环境下的事务一致性。同时 TDSQL PostgreSQL版 提供了分布式事务可靠性保证机制来避免资源阻塞、数据不一致和协调节点宕机等问题。
SQL 高兼容度
TDSQL PostgreSQL版 在 SQL 兼容性上具备很大优势,兼容绝大多数的 PostgreSQL 语法,包括复杂查询、外键、触发器、视图、存储过程等,可满足大部分企业用户的需求。同时 TDSQL PostgreSQL版 还高度兼容大部分的 Oracle 数据类型、函数、PL/SQL 特性。
HTAP 融合性数据库
TDSQL PostgreSQL版 经过专门设计充分的支持 HTAP,同时具备高效的 OLTP 处理能力和一定规模的 OLAP 能力,降低业务复杂度和成本。
应用场景
HTAP 业务需求系统
数据库系统应用中,OLTP 场景涉及数据量小,但要求实时返回,OLAP 类场景数据量和计算量大,但对实时性要求较低。通用方案是业务将 OLAP 和 OLTP 场景分别用对应的系统来支撑,虽解决了性能问题,但给业务带来了存储成本的上升以及业务高昂的改造成本,同时系统间数据同步容易造成数据出错等问题。
TDSQL PostgreSQL版 经过专门设计能很好的支持 HTAP,同时具备高效的 OLTP 处理能力和海量的 OLAP 能力,降低业务复杂度和业务成本。
物联网地理信息系统
随着物联网的到来,很多的传感器接入数据,如热点 Wi-Fi 数据、车辆行驶数轨迹数据等,都包含一些经纬度定位信息,结合这些位置信息和我们已有的地理信息进行关联分析,依托 TDSQL PostgreSQL版 先进的开源地理信息引擎 PostGIS,可以提供丰富高效的地理信息处理能力。
7 * 24高并发事务系统
随着互联网、移动互联网、电商等业务的蓬勃发展,用户不断增长,给企业的 IT 系统带来了严峻的挑战,如何利用技术手段使得系统可以并行处理更多的请求,降低延迟和响应时间,提高性能和用户体验,成为各大企业必须解决的难题。
面对流量高峰,TDSQL PostgreSQL版 借助 share nothing 架构,可在线线性平滑地扩展集群规模,从容应对高并发场景,同时 TDSQL PostgreSQL版 支持全局事务一致性,保证在高并发场景下的事务一致性。
海量存储计算需求
互联网化的用户激增,伴随着系统的长期运行,数据累积越来越多,给部分行业(如支付业务,因为监管要求,数据必须永久保存)带来的存储成本,以及大数据量场景的性能问题等亟待解决。
TDSQL PostgreSQL版 的在线线性扩容能力,能够按需扩充集群,保证集群可以支撑到 PB 级别的存储,同时结合业务历史数据不常被访问的特点,可将历史数据自动转移到廉价存储设备上,兼顾性能和成本。
多点汇聚业务系统
银行、大型国企的组织架构通常采用总部-分部-分支的架构,其某些核心 IT 系统建设也采用总部-分部-分支模式,且各个分支采用的数据库不同,随着业务互通、人员互通、信息互通等需求越来越强烈,业务逐渐向总部聚合,因此能否高效的进行数据汇聚,是系统一个很重要的考量指标。
TDSQL PostgreSQL版 具备高效的异构数据库复制能力,让数据能够很好的在多个数据库中实现共享。
Oracle 数据库应用迁移
TDSQL PostgreSQL版(Oracle 兼容版)提供高度的 Oracle 语法兼容能力,方便客户便捷地将客户原先运行在 Oracle 的应用系统迁移到本产品上来。应用无须进行过多的应用改造。
数据库架构
TDSQL PostgreSQL版 采用无共享 share nothing 架构。数据库实例分为三种节点:
- 协调节点(Coordinator,CN):是数据库服务的对外入口,负责数据的分发和查询规划,多个节点位置对等。
- 数据节点(Datanode,DN):负责执行协调节点分发的执行请求,实际存储业务数据。
- 全局事务管理器(GlobalTransactionManager,GTM):负责全局事务管理。
TDSQL PostgreSQL版 数据节点部署在强大硬件之上,底层存储使用本地 NVMe SSD 硬盘,提供强大的 IO 性能。
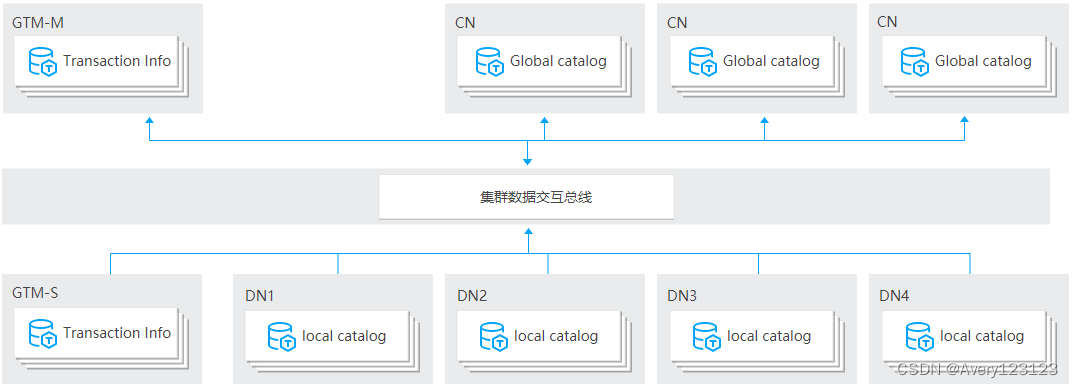
TDSQL PostgreSQL版 提供的 Oracle 兼容版的分布式版本与上述架构完全一致,同时 TDSQL PostgreSQL版 提供的 Oracle 兼容版的集中式版本只有一组 DN 节点。
TDSQL-H LibraDB
产品概述
TDSQL-H LibraDB 是腾讯云自主研发的分布式 HTAP 数据库。其基于 TxLightning 架构设计,由 LibraDB 分析引擎、CDC 数据同步组件、可插拔式 OLTP 引擎,三大主要功能模块构成。
TDSQL-H LibraDB 基于可插拔式的引擎设计、强大的数据融合能力和云原生系统架构,为用户提供一体化产品体验。支持海量数据处理,无论是高并发、高负载事务处理能力,还是复杂数据查询,数据实时/离线分析,均能出色完成。
高速分析引擎 LibraDB
LibraDB 引擎高度兼容 ClickHouse,能以非常低的延迟,从 PB 级数据中完成复杂查询分析。让您的业务系统从海量数据中,及时获取有用信息,使您的客户得到一流体验。
针对 ClickHouse 不足,LibraDB 引擎研发了新特性和增强能力,例如,支持 update/delete 实时一致性、提供会话管理、提升 final 性能等。
可插拔式 OLTP 引擎
采用可插拔式设计,无需将现有的业务数据库中数据重新迁移,即可使您已有的 OLTP(On-Line Transaction Processing)无缝加入 TDSQL-H,赋予 HTAP(Hybrid Transaction Analytical Process)能力。
灵活组合所需的 OLTP 引擎与分析引擎,满足业务需要,一个分析引擎可绑定多个 OLTP,并能按需解除绑定,满足数据多合一的需求,充分发挥分析引擎对海量数据的支持能力。
已支持多种源类型的 MySQL,如腾讯云数据库 MySQL、阿里 RDS MySQL、PolarDB for MySQL、AWS Aurora Mysql、AWS RDS MySQL、IDC 自建 MySQL 等。后续会陆续支持 TDSQL-C、TDSQL MySQL 版。
高效的 CDC 融合能力
通过 CDC(Change Data Capture)高速链路,数据在 OLTP 与分析引擎间稳定、安全、高效地保持实时同步。这样既能保留 OLTP 功能、优势能力与业务使用习惯,也能充分利用分析引擎极致性能。
应用场景
实时数据分析加速
业务数据变更频繁、瞬息万变,历史数据又浩如烟海,如何迅速捕获到其中关键信息,又能应对海量并发和吞吐。TDSQL-H LibraDB 深度融合前端交易事务数据库以支撑在线业务,并且通过 CDC 的快速数据同步能力,将数据同步至 LibraDB 分析引擎中。通过 LibraDB 的高性能分析能力,您既可以轻松应对纷繁业务,也可通过 BI 等数据分析方法,直观迅速地过滤出关键信息,辅助决策。
用户行为分析
随着互联网业务的扩大,整体获客成本的提高,用户更加成熟,使得业务团队需要进行更加精细化的市场营销,提供更高品质的产品。TDSQL-H LibraDB 拥有对 PB 级数据的在线查询能力,可以支撑多种用户分析场景。例如,漏斗分析,留存分析,路径分析等等,形成用户画像。实现业务的精细化运营,助力产品在激烈竞争中脱颖而出。如游戏玩家留存、金融用户画像等。
商业智能报表
支持海量数据实时入库计算,高性能数据查询,方便自由灵活的快速构建报表。支持兼容各类可视化BI工具,使用简单易上手,降低数据可视化系统建设门槛。
数据归档查询
部分业务基于时间进行数据存储,为降低存储成本,需要将一定时间范围前的“冷数据”进行低成本存储,在某些特殊场景下,还需要进行查询分析。TDSQL-H LibraDB 的冷热数据分层功能可帮助到用户降低存储成本,提升数据归档便捷度。
TDSQL-A ClickHouse 版
产品概述
TDSQL-A ClickHouse 版(TDSQL-A for ClickHouse,TDACH)是腾讯云数据库团队在 ClickHouse 社区版基础上,适配腾讯定制化数据库专用硬件,进行了功能增强和性能提升,并且完善了高可用能力而形成的一套分析型数据库产品。
- TDACH 高度兼容社区版,面向腾讯云数据库专用硬件优化,增加了完善的高可用和云上托管能力。
- TDACH 结合 数据传输服务 DTS,将 ClickHouse 强大分析型能力赋能于用户已有的事务数据库,来完成数据分析、报表生成、辅助决策,从而为用户提供一站式数据分析解决方案。
产品功能
即开即用
TDACH 基于腾讯云数据库管控系统,您只需简单几步,即可拥有生产级的 TDACH 实例。无需操心安装、部署、运维等,让您能释放更多精力专注于业务。
弹性伸缩
TDACH 海量数据均以列式压缩存储,大幅降低了整体存储成本。TDACH 良好的分布式架构支持灵活的横向或垂直升降级,智能的数据均衡能力,确保升降级后也能保持集群健康的性能状态。
全面监控
TDACH 支持全面的指标监控,除基础指标外,精心筛选出引擎层指标,让您迅速通过关键指标,了解实例健康情况,为业务系统的使用提供有效的优化指引。您还可以自定义阈值告警,提前防范可能出现的异常。
数据同步
TDACH 借助数据传输服务 DTS,支持将不同部署方式的源端数据同步至 TDACH,包括腾讯云数据库,自建数据库以及其他云数据库,支持同地域、同可用区、跨地域的同步,同步功能稳定,性能优异,让您轻松获得一体化数据体验。
产品优势
完善的云上托管
TDACH 基于腾讯云数据库管控系统,您只需几步简单操作,即可拥有生产级的 TDACH 实例。无需操心安装、部署、运维等,让您能释放更多精力专注于业务。
全面的监控能力
TDACH 支持全面的指标监控,除基础指标外,精心筛选出引擎层指标,让您迅速通过关键指标,了解实例健康情况,为业务系统的使用提供有效的优化指引。您还可以自定义阈值告警,提前防范可能出现的异常。
轻松同步数据
TDACH 借助数据传输服务 DTS,支持将不同部署方式的源端数据同步至 TDACH,包括腾讯云数据库,自建数据库以及其他云数据库,支持同地域、同可用区、跨地域的同步,同步功能稳定,性能优异,让您轻松获得一体化数据体验。
高效的查询引擎
TDACH 能以非常低的延迟,从 PB 级数据表中完成查询。让您的业务系统,从海量数据中及时获取有用信息,使您的客户得到一流体验,在瞬息万变的数据中,助您迅速捕获商业机会。
安全可靠的网络
依托腾讯云强大的安全和网络基础设施,您的实例运行在逻辑隔离的私有网络中,通过网络 ACL 和安全组,能让您享有安全便捷的同时,也能灵活配置出强大的网络策略。
应用场景
决策支持场景
企业经营通常会产生大量数据,如何在海量数据中,迅速捕获到关键信息,是正确决策的关键。TDACH 将数据流打通到业务数据库内,通过强大查询能力,可助您迅速过滤出关键信息,通过配置可视化报表直观展示业务状况。
用户分析场景
通过对海量数据的实时提取,可以支撑多种用户分析场景,例如,漏斗分析、留存分析、路径分析等,从而形成用户画像。TDACH 可助产品实现业务的精细化运营,助力产品在激烈竞争中脱颖而出。
NoSQL数据库
云数据库 Redis
云数据库 MongoDB
云数据库 Memcached
数据库软硬一体
数据库一体机 TData
云数据库独享集群
数据库SaaS服务
略
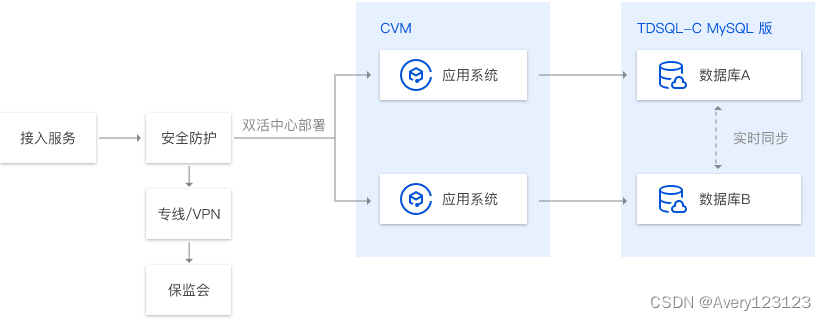
数据库分布式云
数据库分布式云中心
数据库分布式云中心(Database Distributed Cloud Center,DDCC)是基于多云多集群的数据资产管理平台,提供云原生化的数据库服务,支持云数据库本地化部署及多云合一统一管理,覆盖数据容灾备份、异地多活场景,通过异常发现、诊断优化为数据安全护航。
数据库分布式云中心将本地、边缘云、中心云连接起来,支持用户对不同云的实例通过数据库分布式云中心进行统一管理。
- 本地部署的开源数据库实例:用户在本地机房自己搭建的数据库实例,可以通过添加实例,在数据库分布式云中心进行实例管理,构建多云的数据库架构。
- 边缘云部署的腾讯云数据库实例:用户在本地机房或者其他云的服务器中,远程部署腾讯云的数据库实例,在数据库分布式云中心进行实例管理,构建灾备、多活等架构。
- 中心云管理的腾讯云数据库实例:用户购买的腾讯云数据库实例,可以通过添加实例,在数据库分布式云中心进行跨云的、统一的实例管理。
除了多云实例的统一管理外,数据库分布式云中心还提供了实时灾备、异地多活等服务,帮助用户快速搭建安全、可靠的数据架构。
产品优势
离线自治
支持云数据库本地化部署,保证数据合规性及安全要求,提供与公有云一致体验。
支持将云数据库远程部署到用户本地机房中,并且通过统一的实例管理平台,实现实例的安装、升级;将公有云的服务体验延伸到用户本地部署的云服务中。
数据互通
支持本地与中心云数据库打通,实现多云、多集群间的数据流转。
支持将本地、中心云和边缘云的实例通过数据链路进行连通,实现不同云之间的数据迁移、同步,实现多云、多地域之间的数据流转。
成本优化
充分利用本地资源的同时,使用云上服务免搭建、免运维,节省成本。
在数据库分布式云中心中,中心云及边缘云的服务质量由数据库分布式云中心保障,可在数据库分布式云中心控制台实现云数据库安装到用户本地,充分利用本地基础资源,同时可以进行服务远程升级,实现服务更新迭代。
弹性伸缩
根据业务需求,在云上横向扩展获取更多数据库副本,满足弹性资源要求。
在数据库分布式云中心中,通过构建本地与中心云的混合云数据架构,利用中心云海量的资源,快速横向扩展数据库资源,轻松应对业务洪峰。
服务升级
轻松满足数据备份容灾、异地多活的需求,提供数据库异常发现、诊断优化的能力,全方位保
应用场景
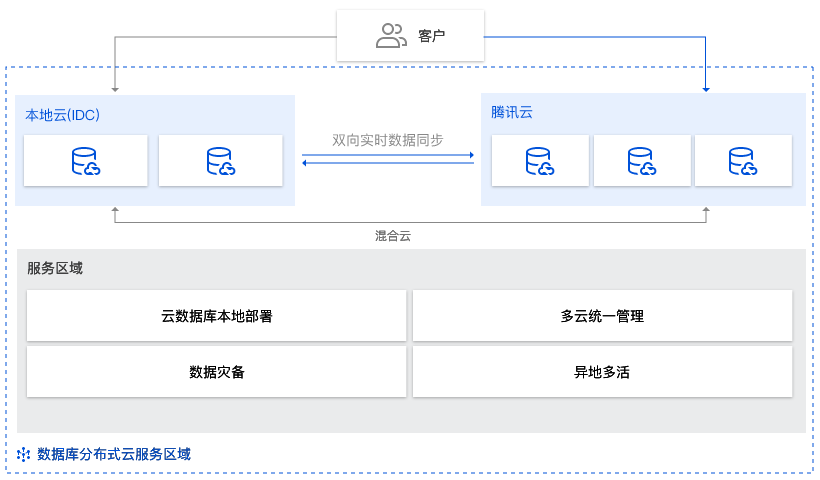
场景1:构建数据库混合云
场景描述
很多用户希望在业务发展中,既保留原有本地部署的优势,也可以享受公有云弹性扩缩容的资源。
应用建议
数据库分布式云中心支持在保留云下本地环境的情况下,充分利用云上弹性资源,在业务高峰期,在云端快速扩展数据库,把部分业务流量引到云端。
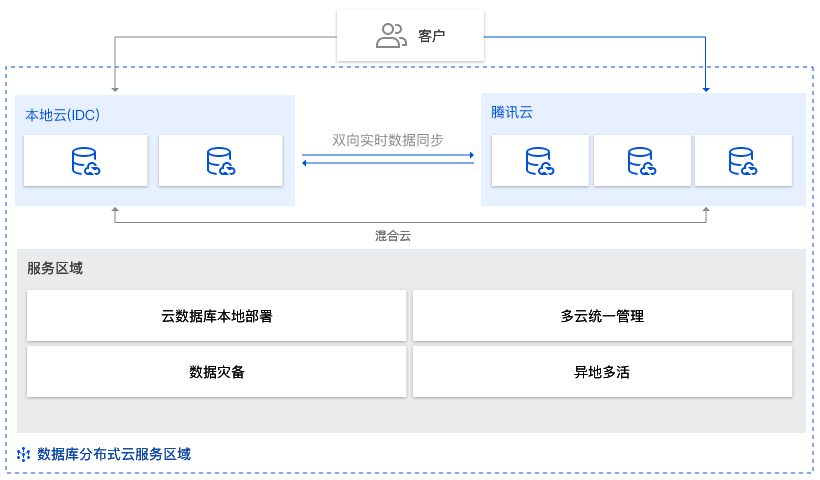
场景2:多云数据库管理
场景描述
用户的全球业务高速发展,用户希望在业务上云过程中,本地基础设施和中心云可以部署相同的云数据库,方便统一管理。
应用建议
数据库分布式云中心支持在本地或边缘节点部署云上经过验证的数据库服务,既满足数据合规性要求,又拥有与云上一致的数据库管理体验。
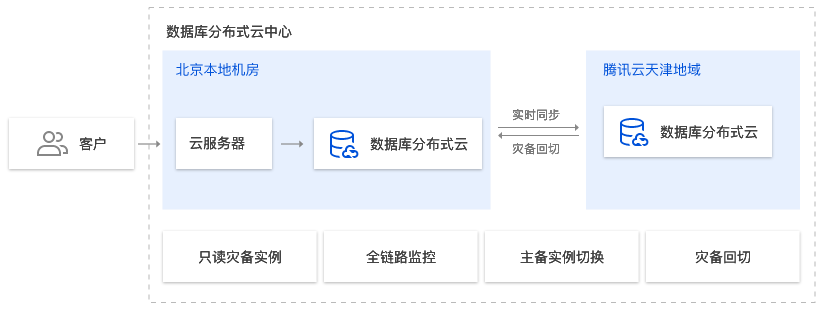
场景3:备份容灾
场景描述
用户希望可以快速构建本地和中心云的跨云灾备任务,实现业务数据容灾需求。
应用建议
提供跨地域的数据库容灾备份服务,支持备份策略和恢复策略。持续容灾备份到云端,提高数据安全性,满足合规要求。
场景4:异地多活
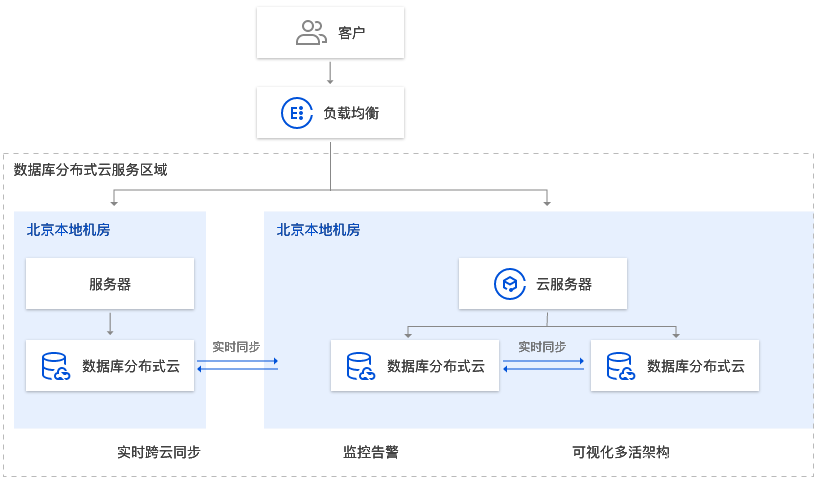
场景描述
为保证业务数据的高可用性,用户希望可以构建跨城多活的架构,就近提供服务。
应用建议
数据库分布式云中心提供快速构建跨地域多活的服务,实现数据链路的互通,保证数据库实例之间的数据一致性,帮助用户快速搭建高可用数据库系统。